目录
- 前言
- 总体设计
- 系统整体结构图
- 系统流程图
- 运行环境
- Python 环境
- OpenCV环境
- Android环境
- 1. 开发软件和开发包
- 2. JDK设置
- 3. NDK设置
- 模块实现
- 1. 数据预处理
- 2. 模型训练
- 1)训练级联分类器
- 2)训练无分割车牌字符识别模型
- 3. APP构建
- 1)导入OpenCV库
- 2)导入动态链接库so文件
- 3)引入C++support、用CMake生成链接库
- 4. 导入训练好的模型
- 5.注册内容提供器、声明SD卡访问权限
- 6.配置Lite Pal数据库
- 系统测试
- 1. 训练分数和损失可视化
- 2. APP测试结果
- 工程源代码下载
- 其它资料下载
前言
本项目基于CCPD数据集和LPR(License Plate Recognition,车牌识别)模型,结合深度学习和目标检测等先进技术,构建了一个全面的车牌识别系统,实现了从车牌检测到字符识别的端到端解决方案。
首先,我们利用CCPD数据集,其中包含大量的中文车牌图像,用于模型的训练和验证。这个数据集的丰富性有助于模型更好地理解不同场景下的车牌特征。
接着,我们引入LPR模型,这是一种专门设计用于车牌识别的模型。通过深度学习技术,LPR模型可以学习和识别不同类型的车牌,无论是小轿车、卡车还是摩托车。
在模型设计中,我们使用目标检测技术,让模型能够自动定位和框选出图像中的车牌区域。这样,系统可以在不同图像中准确地找到车牌,并且不受不同角度、光照等因素的影响。
通过将车牌区域提取出来,我们将其输入到LPR模型中,进行字符识别。模型将车牌上的字符识别出来,从而实现了完整的车牌识别功能。
综合上述技术,本项目实现了一个端到端的车牌识别系统,能够高效准确地检测和识别车牌,无论是在不同的场景还是在各种环境下。这种系统在交通管理、安防监控等领域具有重要的应用价值。
总体设计
本部分包括系统整体结构图和系统流程图。
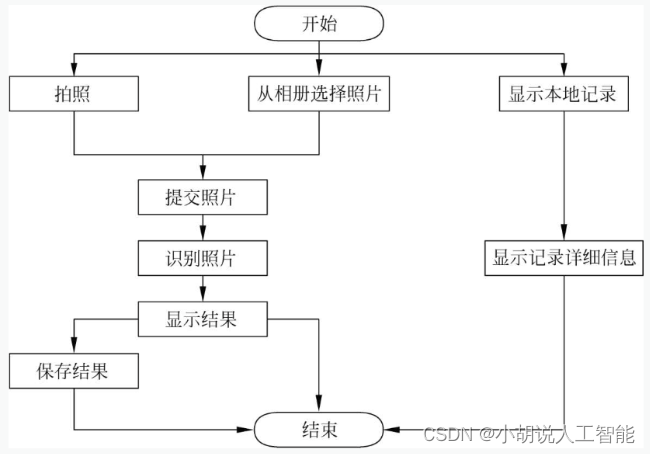
系统整体结构图
系统整体结构如图所示。

系统流程图
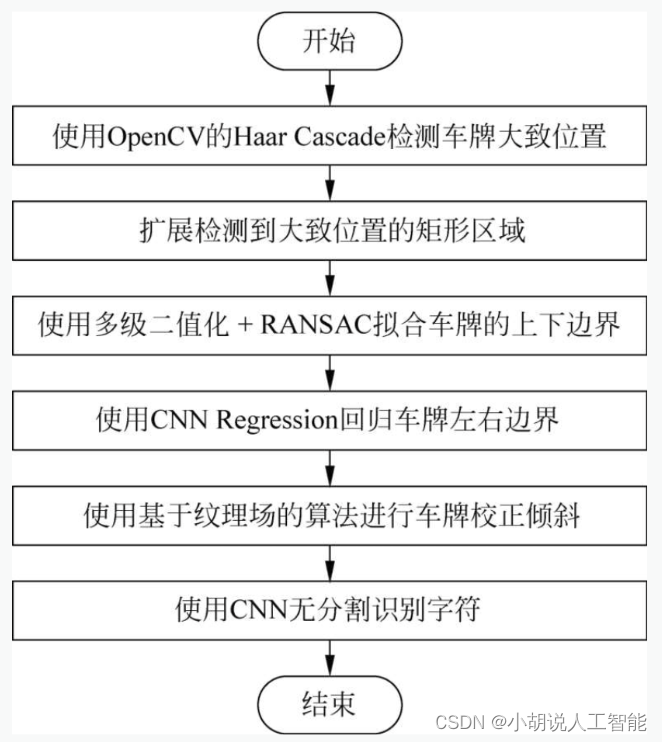
系统流程如图所示。
APP中应用的算法流程包括车牌粗定位、车牌精定位、快速倾斜矫正和无分割端到端字符识别的算法描述及流程,如下图所示。
运行环境
本部分包括 Python 环境、OpenCV 环境和 Andriod 环境。
Python 环境
在清华TUNA开源镜像站https://mirrors.tuna.tsinghua.edu.cn/下载Miniconda 3.4.7.12版本,根据自己的操作系统选择相应的版本。
在开始菜单中打开Anaconda Prompt ( miniconda3),进入命令行终端,并输入以下命令:
conda create -n tensorflow python=3.7#创建虛拟环境
conda install tensorflow-gpu #若没有独立GPU,可以选择安装CPU版本,去掉参数即可
conda install opencv-python=3.4.6
conda install pandas
#conda默认安装TensorFlow的2.1.0 stable版本
#其他常见的数据科学库如numpy在创建虚拟环境时或者安装TensorFlow
#若未安装,可以自行用conda或pip命令安装
OpenCV环境
进入OpenCV官网的release页面https://opencv.org/releases/中下载OpenCV 3.4.6 版本的Windows和Android两个包,并解压。
Android环境
安装相应版本的开发软件操作如下:
1. 开发软件和开发包
下载地址为https://developer.android.google.cn/studio/,APP开发使用Android Studio3.5.3版本。
创建NewProject,选择EmptyActivity->next,在Name输入框输入项目名称,Package name输入框中命名项目中java文件包名,Save location中指定项目存储路径,Language (语言)选择]ava,MinimumAPllevel指定项目兼容的最低API版本,设置后单击Finish按钮完成创建。
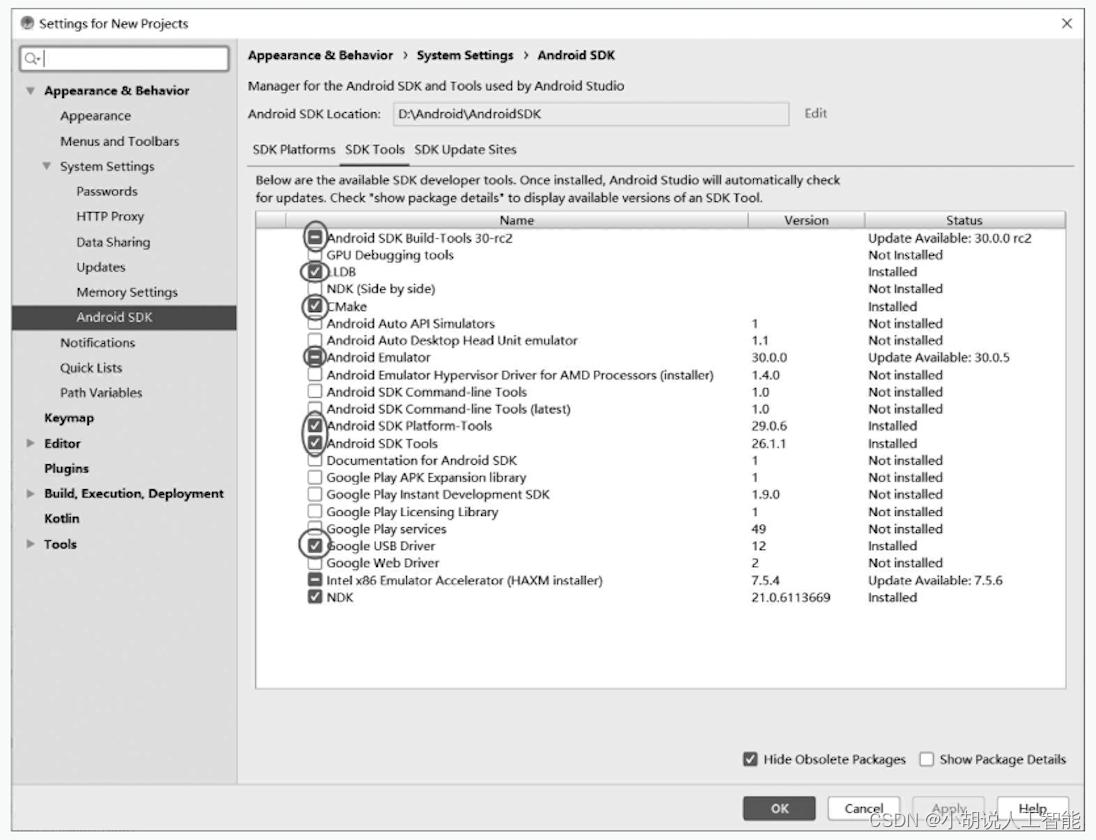
本项目的Package name命名为com.pcr.lpr。创建Project后,需安装SDK Platforms和SDKTools。单击窗口右上方右起第2个图标安装。
SDK Platforms只选中Android 9.0 (Pie) ,切换到SDK Tools选项卡,选中下图中画圈选项即可。
2. JDK设置
若系统中未安装JDK,可前往https://www.oracle.com/java/technologies/javase-downloads.html下载,单击Android Studio,单击下图界面右上方方框中的图标,打开Project Structure,并在JDK Location中填入JDK解压的文件夹路径。
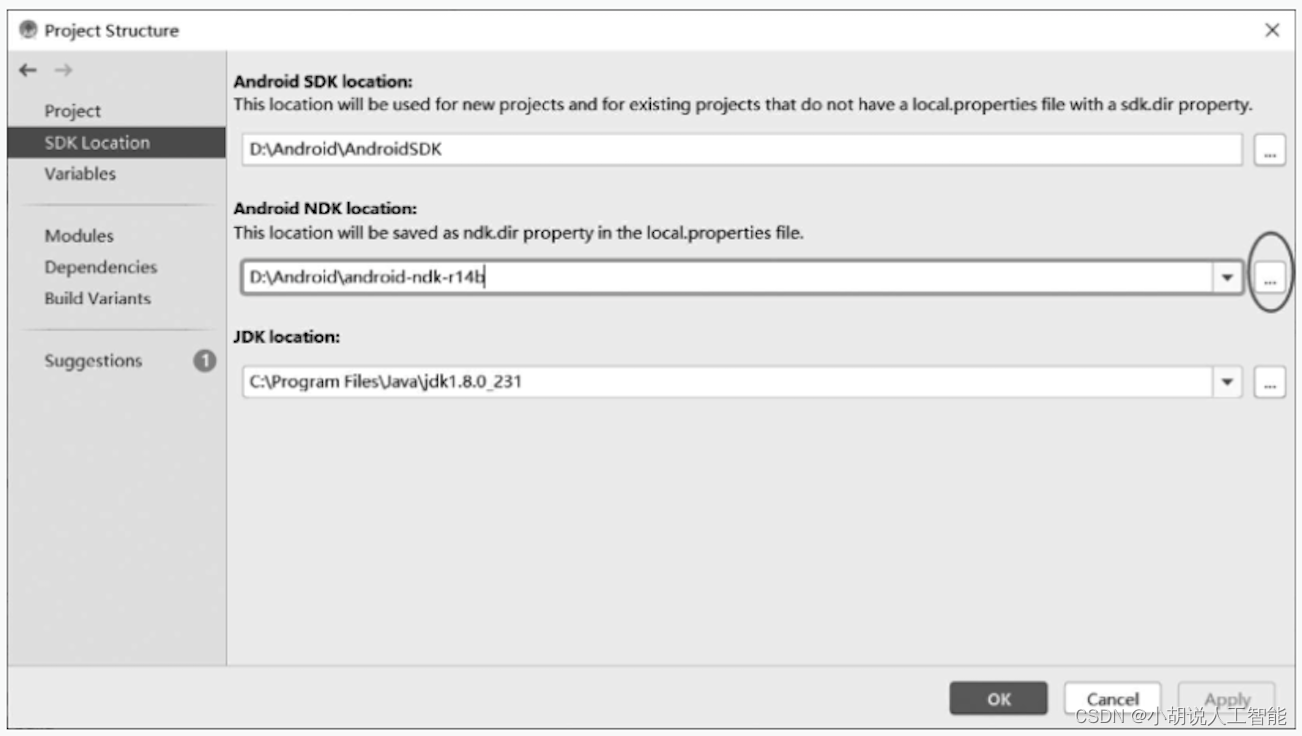
3. NDK设置
在https://developer.android.google.cn/ndk/downloads/older_releases.html中下载Android-ndk-r14b版本NDK并解压。
打开Project Structure,在弹出的窗口中设置NDK路径,如图17-6所示。
模块实现
本项目包括3个模块:数据预处理、模型训练、APP构建,下面分别介绍各模块的功能及相关代码。
1. 数据预处理
从CCPD页面https://github.com/detectRecog/CCPD中下载数据集,解压得到图片数据如图所示。

获取数据集之后,进行预处理。依据数据集图片名称提供的信息对车牌进行裁剪,文件名依据“_”进行分割,第4组数据是图片中车牌的4个角点坐标,第5组数据是7位车牌信息,依据这两组数据可以得到分割后的车牌图片和车牌标签。
正样本和负样本的大小均为150X40,用于Cascade级联分类器训练。负样本可以随意裁剪,图片中没有车牌;正样本用于训练无分割车牌字符识别。相关代码如下:
#裁剪车牌
import cv2
import hashlib
import os, sys
import pandas as pd
import numpy as np
if not os.path.exists("output"):
os.mkdir("output")
h = 40
w = 150
path = r"E:\ccpd_dataset\ccpd_base" #数据集所在路径
filenames = os.listdir(path)
fp = open("pos_image.txt", "w", encoding="utf-8")
fn = open("neg_image.txt", "w", encoding="utf-8")
#用于存储图片的每一位车牌信息
df = pd.DataFrame(columns=('pic_name', '0', '1', '2', '3', '4', '5', '6'))
#正样本分割图片中的车牌
count = 0
#for img_name in filenames[0:40000]:
#为保证省份全覆盖,采用全部数据,而不是40000张
for img_name in filenames:
#读取图片的完整名字
image_path = os.path.join(path, img_name)
image = cv2.imread(image_path
#以“-”为分隔符,将图片名切分,其中iname[4]为车牌字符,iname[2]为车牌坐标
iname = img_name.rsplit('/', 1)[-1].rsplit('.', 1)[0].split('-')
plateChar = iname[4].split("_")
#将文件名,七位车牌写入dataframe中
new_line = [
new_name, plateChar[0], plateChar[1], plateChar[2], plateChar[3],
plateChar[4], plateChar[5], plateChar[6]
]
df.loc[count, :] = new_line
#crop车牌的左上角和右下角坐标
[leftUp, rightDown] = [[int(eel) for eel in el.split('&')]
for el in iname[2].split('_')]
#crop图片
img = image[leftUp[1]:rightDown[1], leftUp[0]:rightDown[0]]
height, width, depth = img.shape
#将图片压缩成40*150,计算压缩比
imgScale = h / height
#(目标宽-实际宽)/2,分别向左、右拓宽,所有除以2
deltaD = int((w / imgScale - width) / 2)
#切割宽度向左平移,保证补够250
leftUp[0] = leftUp[0] - deltaD
#切割宽度向右平移,保证补够250
rightDown[0] = rightDown[0] + deltaD
#如果向左平移为负,坐标为0
if (leftUp[0] < 0):
rightDown[0] = rightDown[0] - leftUp[0]
leftUp[0] = 0
#按照高/宽 =40/150的比例切割,注意切割的结果不是40和250
img = image[leftUp[1]:rightDown[1], leftUp[0]:rightDown[0]]
newimg = cv2.resize(img, (w, h)) #resize成40*250
new_name = 'pic' + str(count + 1).rjust(6, '0')
cv2.imwrite("../output/pos/" + new_name + '.jpg', newimg)
#将图片信息写入.txt文件中
fp.write('pos/'+new_name +'.jpg'+'1 0 0 150 40' + plateChar + '\n')
count += 1
df.to_csv('./pos.csv')
fp.close()
#负样本图片中没有车牌
count = 0
for img_name in filenames[400000:80000]:
#补充完整图片路径
image_path = os.path.join(path, img_name)
image = cv2.imread(image_path)
#裁剪不含车牌的区域
new_img = image[0:40, 0:150]
new_name = 'pic' + str(count + 40001).rjust(6, '0')
cv2.imwrite("../output/neg/" + new_name + '.jpg', new_img)
#将图片信息写入.txt文件中
fn.write('neg/' + new_name + '.jpg' '\n')
count += 1
fn.close()
裁剪得到的正样本,如下图所示。

裁剪得到的负样本,如下图所示。

2. 模型训练
级联分类器和无分割车牌字符的卷积神经网络模型的训练,具体过程如下。
1)训练级联分类器
得到正样本和负样本后,在终端中切换到之前下载OpenCV的解压目录中\build\x64\vc15\bin\的目录。以D:\opencv\为例:
cd D:\opencv\build\x64\vc15\bin\
在终端中执行如下命令,其中-info填入正样本.txt文件的路径;-bg填入负样本.txt文件的路径;-num根据上一步分割得到的正样本数量修改;-W、-h分别为样本图片的宽和高,所有样本图片的宽高必须一致,故此处填入上一步裁剪车牌设置的样本宽高。
opencv_createsamples.exe -vec pos.vec -info pos_image.txt -bg neg_image.txt -w 150 -h 40 -num 40000
执行完毕后生成pos.vec文件,接着在终端中执行如下命令:
opencv_traincascade.exe -data xml -vec pos.vec -bg neg_image.txt -numPos 40000 -numNeg 80000 -numStages 15 -precalcValBufSize 5000 -precalcIdxBufSize 5000 -w 150 -h 40 -maxWeakCount 200 -mode ALL -minHitRate 0.990 -maxFalseAlarmRate 0.20
其中-vec填入上一步生成的pos.vec文件路径,-bg填入负样本.txt文件路径,-numPos和 -numNeg根据上一步分割得到的正样本数量修改,其他参数按命令提供的参数即可。
上述命令执行完毕后,会在样本目录下得到训练好的cascade.xml的级联分类器文件。
2)训练无分割车牌字符识别模型
无分割车牌字符识别使用卷积神经网络实现,相关代码如下:
import numpy as np
import pandas as pd
import pickle
import tensorflow as tf
from tensorflow.keras.layers import Dense, Conv2D, Flatten, MaxPooling2D
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras.callbacks import TensorBoard
BATCH_SIZE = 64
def process_info(img_info):
#处理每条csv中的信息,返回图片名称和one-hot后的标签
img_path = img_info[0]
label = np.zeros([238]) #7*34
for i in range(7):
index = int(img_info[i + 1])
label[i * 34 + index] = float(1)
return (img_path, label)
def parse_function(filename, label):
#返回归一化后的解码图片矩阵和标签矩阵
#读取文件
image_string = tf.io.read_file(filename)
#解码
image_decoded = tf.image.decode_jpeg(image_string, channels=3)
#变型
image_resized = tf.image.resize(image_decoded, [150, 40])
#归一化
image_normalized = image_resized / 255.0
return image_normalized, label
def create_dataset(filenames, labels):
#创建数据集管道
#补充完整的图片路径
filenames = "D:/DL & ML/output/pos/" + filenames
#从张量切片创建自定义数据集
dataset = tf.data.Dataset.from_tensor_slices((filenames, labels))
#并行处理
dataset = dataset.map(parse_function,
num_parallel_calls=tf.data.experimental.AUTOTUNE)
#数据集分批
dataset = dataset.batch(BATCH_SIZE)
#在训练时预先加载数据
dataset = dataset.prefetch(buffer_size=tf.data.experimental.AUTOTUNE)
return dataset
def macro_f1(y, y_hat, thresh=0.5):
#计算一个批次的宏f1分数,返回宏f1分数
y_pred = tf.cast(tf.greater(y_hat, thresh), tf.float32)
tp = tf.cast(tf.math.count_nonzero(y_pred * y, axis=0), tf.float32)
fp = tf.cast(tf.math.count_nonzero(y_pred * (1 - y), axis=0), tf.float32)
fn = tf.cast(tf.math.count_nonzero((1 - y_pred) * y, axis=0), tf.float32)
f1 = 2 * tp / (2 * tp + fn + fp + 1e-16)
macro_f1 = tf.reduce_mean(f1)
return macro_f1
def myModel():
#自定义模型
model = Sequential()
#两层卷积一层池化
model.add(Conv2D(64,(3,3),padding='same', activation='relu',input_shape=[150, 40, 3]))
model.add(Conv2D(64, (3, 3), padding='same', activation='relu'))
model.add(MaxPooling2D())
#两层卷积一层池化
model.add(Conv2D(128, (3, 3), padding='same', activation='relu'))
model.add(Conv2D(128, (3, 3), padding='same', activation='relu'))
model.add(MaxPooling2D())
#两层卷积一层池化
model.add(Conv2D(256, (3, 3), padding='same', activation='relu'))
model.add(Conv2D(256, (3, 3), padding='same', activation='relu'))
model.add(Conv2D(256, (3, 3), padding='same', activation='relu'))
model.add(MaxPooling2D())
#全连接层
model.add(Flatten())
model.add(Dense(1024, activation='relu'))
model.add(Dense(512, activation='relu'))
model.add(Dense(238, activation='sigmoid'))
return model
if __name__ == "__main__":
#读取数据以及预处理
img_info = pd.read_csv(r"D:\DL & ML\output\pos.csv")
train_pic_name = img_info.pic_name
train_label = np.zeros([len(img_info), 238])
for i in range(len(img_info)):
_, train_label[i, ] = process_info(img_info.loc[i])
#创建网络
model = myModel()
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=[macro_f1])
train_ds = create_dataset(train_pic_name, train_label)
#调用tensorboard
tb=TensorBoard(log_dir='logs')
#训练网络
model.fit(train_ds, epochs=30, callbacks=[tb])
#保存模型
model.save("segmention_free.h5")
训练完成后,在代码文件所在目录下得到segmention_free.h5模型文件。
3. APP构建
APP构建相关步骤如下。
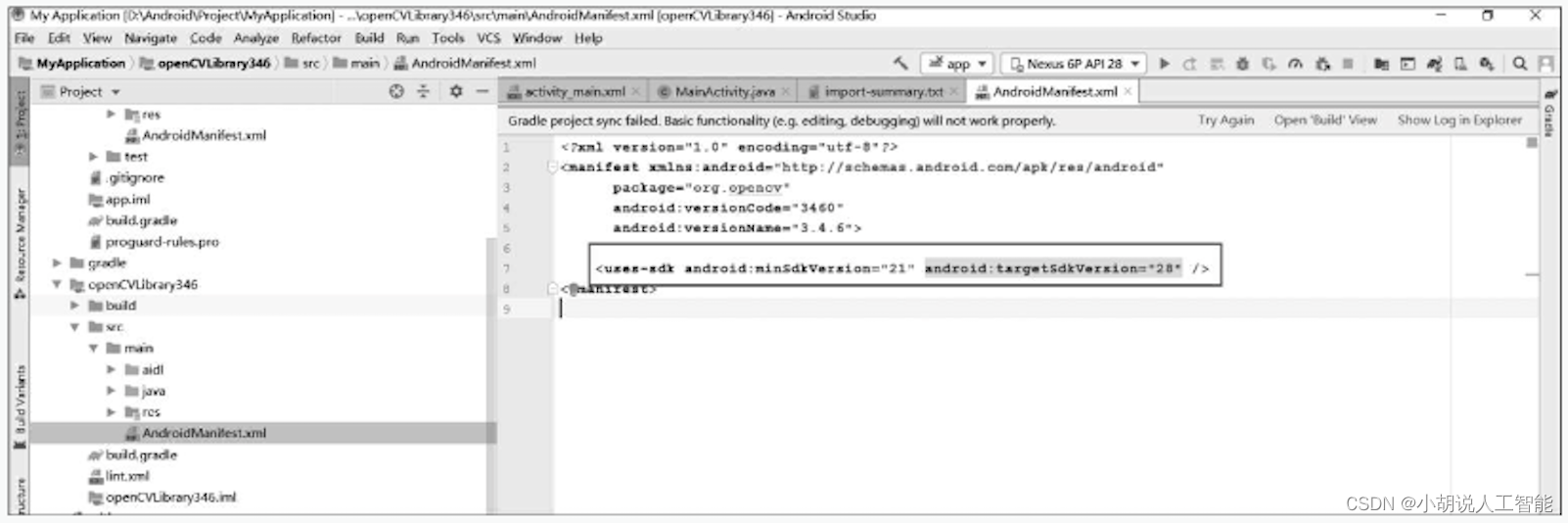
1)导入OpenCV库
在Android Studiot左侧Project栏 , myApplicationk处右击→New→Module,创建新模块。单击ImportEclipseADTProject,选择sdk/java目录,单击next按钮完成导入。在界面左侧Project区打开openCVLibrary346\src\main\AndroidManifest.xml,删除下图方框中的文字。
在左侧Project区打开新引入的Module\build.gradle,修改compileSdkVersion和targetSdkVersion为28, 修改minSdkVersion为19。
在左侧Project区打开app\build.gradle , 在dependencies中添加下列语句:
implementation project(path:':openCVLibrary346')
2)导入动态链接库so文件
在app\build.gradle的android{defaultConfig{}}中添加下列语句:
ndk {
abiFilters 'armeabi -v7a'
}
创建 app\src\main\jniLibs目录, 将OpenCV-android-sdk-3.4.6\sdk\native\libs下的armeabi-v7复制到jniLibs中。
3)引入C++support、用CMake生成链接库
在app\build.gradle的android{defaultConfig{}}中添加下列语句:
externalNativeBuild{
cmake{
cppFlags " - std=gnu++11"
}
}
创建app\src\main\jniLibs目录。在jniLibs下创建javaWrapper.cpp,引入jni.h和string.h,所有用native声明的java本地函数将在该文件中用C++实现。
创建app\src\main\jniLibs\include目录,所有.h文件包含在该目录下。创建app\src\main\jniLibs\src目录,除javaWrapper.cpp外,所有.cpp文件都包含在该目录下。在APP目录下新建File命名为CMakeLists.txt,添加如下代码:
cmake_minimum_required(VERSION 3.4.1)
include_directories(src/main/jni/include)
include_directories(src/main/jni)
aux_source_directory(src/main/jni SOURCE_FILES)
aux_source_directory(src/main/jni/src SOURCE_FILES_CORE)
list(APPEND SOURCE_FILES ${SOURCE_FILES_CORE})
#修改为自己的opencv-android-sdk的jni路径
set(OpenCV_DIR D:\\Android\\OpenCV-android-sdk-3.4.6\\sdk\\native\\jni)
#查找包
find_package(OpenCV REQUIRED)
#添加库
add_library( #设置库的名称
lpr
SHARED
${SOURCE_FILES})
find_library( #设置变量路径名称
log-lib
log)
#将找到的库链接给lpr库
target_link_libraries( #指定目标库
lpr
${OpenCV_LIBS}
#将目标库链接到NDK中包含的日志库
${log-lib})
#在app\build.gradle的android{ }中添加下列代码
externalNativeBuild {
cmake {
path "CMakeLists.txt"
}
}
4. 导入训练好的模型
创建目录app\src\main\assets\lpr,将训练好的模型复制到目录下。
5.注册内容提供器、声明SD卡访问权限
打开app\src\AndroidManifest.xml在<application> </application>内添加下列代码:
<provider
android:name="androidx.core.content.FileProvider"
android:authorities="com.example.cameraalbumtest.fileprovider"
android:exported="false"
android:grantUriPermissions="true">
<meta-data
android:name="android.support.FILE_PROVIDER_PATHS"
android:resource="@xml/file_paths" />
</provider>
在app\src\res下创建目录xml,xml中创建file_paths.xml并修改代码:
<?xml version="1.0" encoding="utf-8"?>
<paths xmlns:android="http://schemas.android.com/apk/res/android">
<external-path
name="my_images"
path=""/>
</paths>
Name属性可以随意设置,path为空表示将整个SD卡进行共享,也可修改为使用provider的文件地址。
打开app\src\AndroidManifest.xml在<application> </application>外添加下列代码:
<uses-permission android:name="android.permission.WRITE_EXTERNAL_STORAGE" />
6.配置Lite Pal数据库
打开app\build.gradle,在dependencies内添加代码:
implementation "org.litepal.android:core:2.0.0"
在app\src\main\assets内创建Android Resource File(安卓资源文件),修改代码为:
<?xml version="1.0" encoding="utf-8"?>
<litepal>
<dbname value="CarStore"></dbname>
<version value="1"></version>
<list>
<mapping class="com.pcl.lpr.Cars"/>
</list>
</litepal>
系统测试
本部分包含训练分数和损失可视化、APP测试结果。
1. 训练分数和损失可视化
无分割车牌字符识别模型训练完成后,在终端中输入以下命令:
tensorboard --logdir logs # 其中--logdir填写logs目录的路径
loss和macro_ f1score的曲线中,横轴是训练迭代次数,如图1和图2所示。
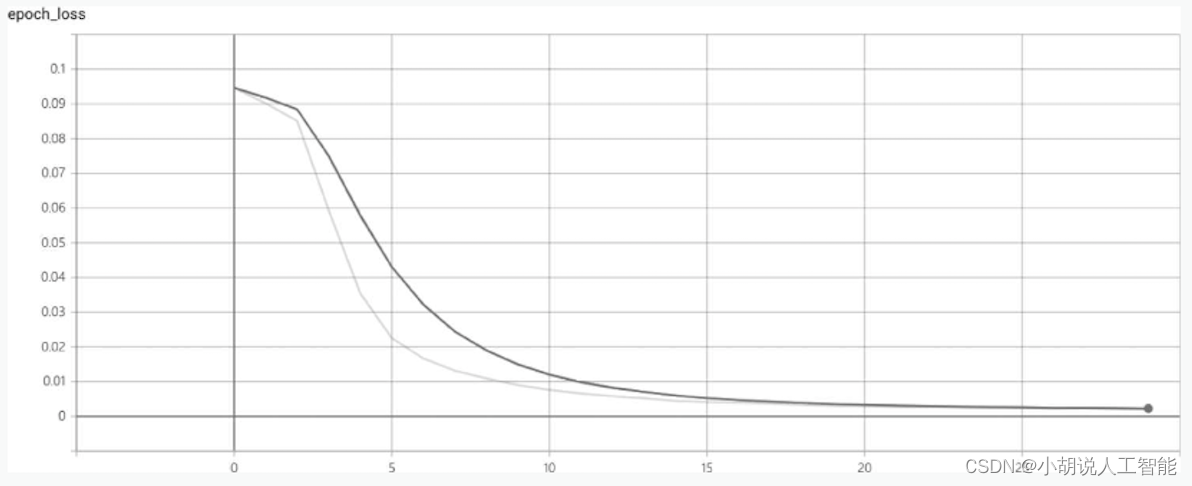
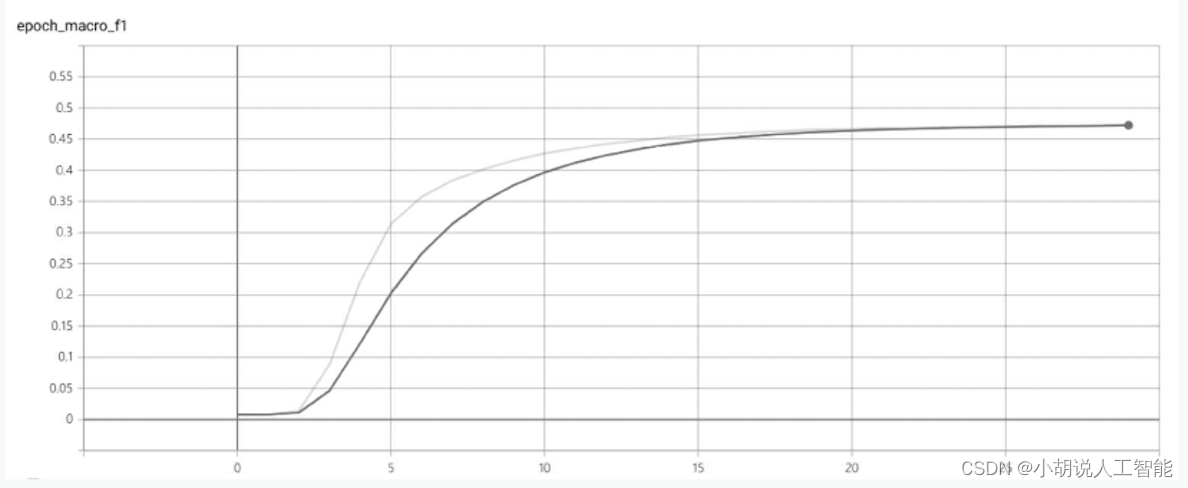
采用HyperLPR提供训练好的模型,识别准确率为95%~97%,下载地址为https://github.com/zeusees/HyperLPR/tree/master。
2. APP测试结果
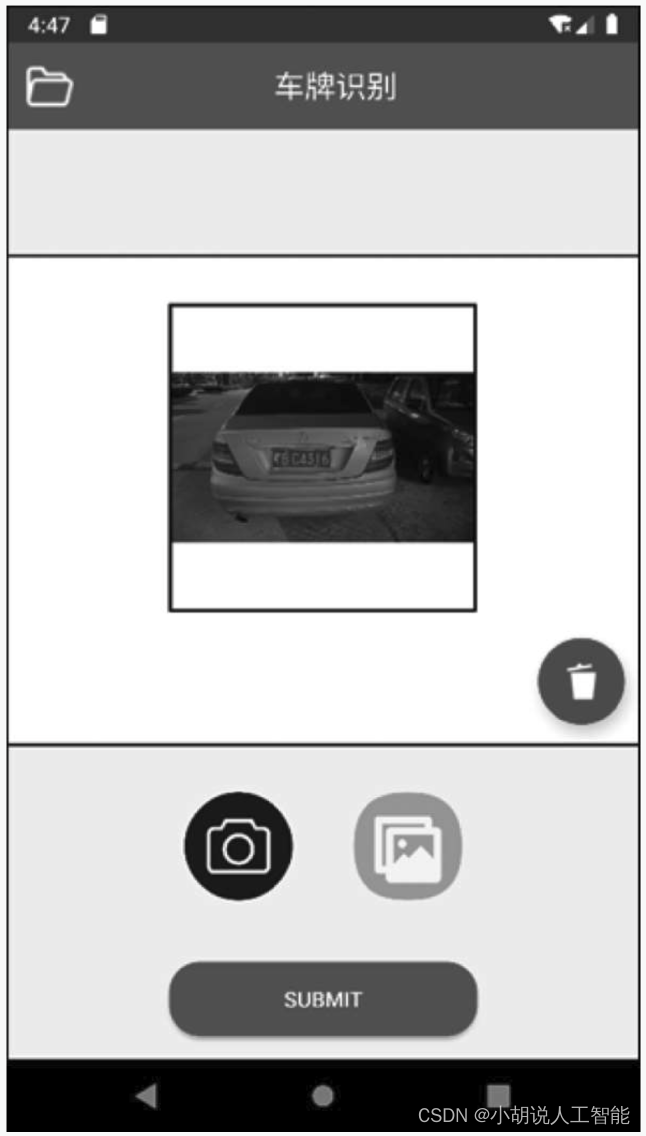
APP界面如下图所示。

单击主界面中的相机图标进入相机界面拍摄带车牌图片,或单击主界面中的图片图标进入选择带车牌图片。单击右上方垃圾桶图标可删除已导入的图片,单击SUBMIT按钮提交检测,如下图所示。
图片识别结果如下图所示。

单击“结果”页面右上方图标可保存识别结果。保存的记录可单击“车牌识别”页面左上角图标查看,如下图所示。
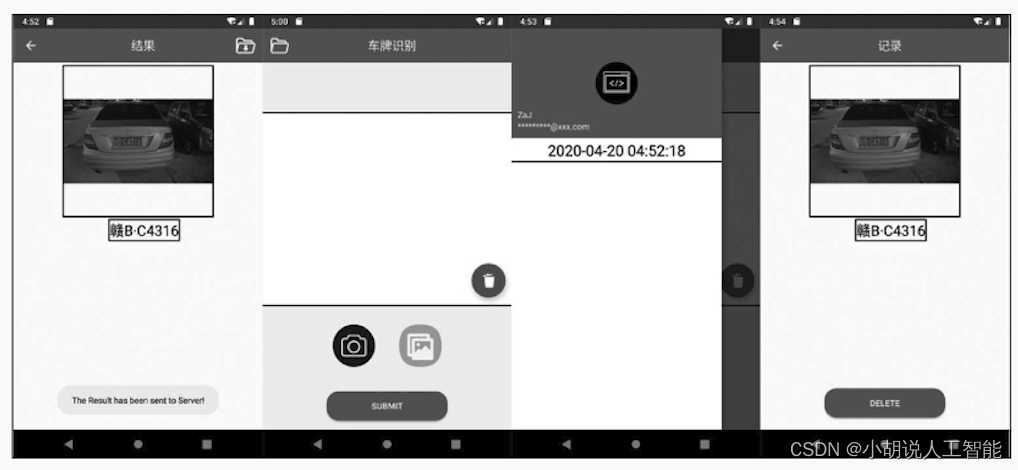
测试示例如图所示。

工程源代码下载
详见本人博客资源下载页
其它资料下载
如果大家想继续了解人工智能相关学习路线和知识体系,欢迎大家翻阅我的另外一篇博客《重磅 | 完备的人工智能AI 学习——基础知识学习路线,所有资料免关注免套路直接网盘下载》
这篇博客参考了Github知名开源平台,AI技术平台以及相关领域专家:Datawhale,ApacheCN,AI有道和黄海广博士等约有近100G相关资料,希望能帮助到所有小伙伴们。




![[C/C++]指针详讲-让你不在害怕指针](https://img-blog.csdnimg.cn/79e2f0cd769945f5b326f0c2dcb85c74.jpeg)