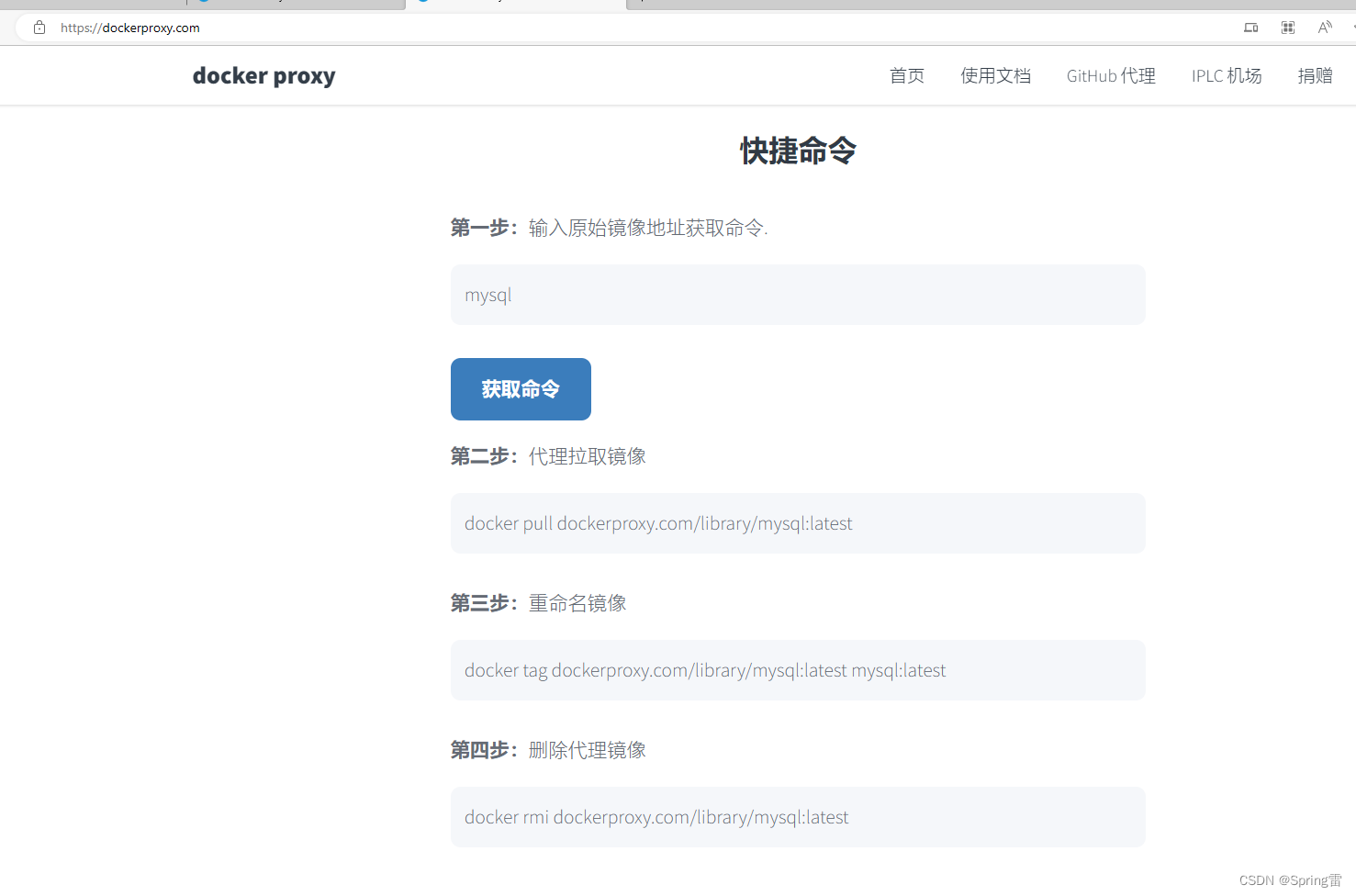
函数
Go 函数与函数声明
- 在 Go 语言中,函数是唯一一种基于特定输入,实现特定任务并可返回任务执行结果的代码块(Go 语言中的方法本质上也是函数)。
- 在 Go 中,我们定义一个函数的最常用方式就是使用函数声明。

- 第一部分是关键字 func,Go 函数声明必须以关键字 func 开始。
- 第二部分是函数名。
- 函数名是指代函数定义的标识符,函数声明后,我们会通过函数名这个标识符来使用这个函数。
- 在同一个 Go 包中,函数名应该是唯一的。
- 首字母大写的函数名指代的函数是可以在包外使用的,小写的就只在包内可见。
- 第三部分是参数列表。
- 参数列表中声明了我们将要在函数体中使用的各个参数。
- 参数列表紧接在函数名的后面,并用一个括号包裹。
- 它使用逗号作为参数间的分隔符,而且每个参数的参数名在前,参数类型在后,这和变量声明中变量名与类型的排列方式是一致的。
- Go 函数支持变长参数,也就是一个形式参数可以对应数量不定的实际参数。
- 第四部分是返回值列表。
- 返回值承载了函数执行后要返回给调用者的结果,返回值列表声明了这些返回值的类型,返回值列表的位置紧接在参数列表后面,两者之间用一个空格隔开。
- Fprintf 函数的返回值列表不仅声明了返回值的类型,还声明了返回值的名称,这种返回值被称为具名返回值。
- 多数情况下,我们不需要这么做,只需声明返回值的类型即可。
- 最后,放在一对大括号内的是函数体,函数的具体实现都放在这里。
- 不过,函数声明中的函数体是可选的。
- 如果没有函数体,说明这个函数可能是在 Go 语言之外实现的,比如使用汇编语言实现,然后通过链接器将实现与声明中的函数名链接到一起。
- 函数声明中的函数名其实就是变量名,函数声明中的 func 关键字、参数列表和返回值列表共同构成了函数类型。而参数列表与返回值列表的组合也被称为函数签名,它是决定两个函数类型是否相同的决定因素。因此,函数类型也可以看成是由 func 关键字与函数签名组合而成的。
- 通常,在表述函数类型时,我们会省略函数签名参数列表中的参数名,以及返回值列表中的返回值变量名。
func(io.Writer, string, ...interface{}) (int, error) - 如果两个函数类型的函数签名是相同的,即便参数列表中的参数名,以及返回值列表中的返回值变量名都是不同的,那么这两个函数类型也是相同类型。
- 每个函数声明所定义的函数,仅仅是对应的函数类型的一个实例。
- 函数字面值由函数类型与函数体组成,它特别像一个没有函数名的函数声明,因此我们也叫它匿名函数。
- 通常,在表述函数类型时,我们会省略函数签名参数列表中的参数名,以及返回值列表中的返回值变量名。
函数参数的那些事儿
- 函数参数列表中的参数,是函数声明的、用于函数体实现的局部变量。
- 由于函数分为声明与使用两个阶段,在不同阶段,参数的称谓也有不同。
- 在函数声明阶段,我们把参数列表中的参数叫做形式参数(Parameter,简称形参),在函数体中,我们使用的都是形参;
- 而在函数实际调用时传入的参数被称为实际参数(Argument,简称实参)。

- Go 语言中,函数参数传递采用是值传递的方式。
- 所谓“值传递”,就是将实际参数在内存中的表示逐位拷贝(Bitwise Copy)到形式参数中。
- 对于像整型、数组、结构体这类类型,它们的内存表示就是它们自身的数据内容,因此当这些类型作为实参类型时,值传递拷贝的就是它们自身,传递的开销也与它们自身的大小成正比。
- 但是像 string、切片、map 这些类型就不是了,它们的内存表示对应的是它们数据内容的“描述符”。当这些类型作为实参类型时,值传递拷贝的也是它们数据内容的“描述符”,不包括数据内容本身,所以这些类型传递的开销是固定的,与数据内容大小无关。这种只拷贝“描述符”,不拷贝实际数据内容的拷贝过程,也被称为“浅拷贝”。
- 不过函数参数的传递也有两个例外,当函数的形参为接口类型,或者形参是变长参数时,简单的值传递就不能满足要求了,这时 Go 编译器会介入:对于类型为接口类型的形参,Go 编译器会把传递的实参赋值给对应的接口类型形参;对于为变长参数的形参,Go 编译器会将零个或多个实参按一定形式转换为对应的变长形参。
- 在 Go 中,变长参数实际上是通过切片来实现的。所以,我们在函数体中,就可以使用切片支持的所有操作来操作变长参数,这会大大简化了变长参数的使用复杂度。
函数支持多返回值
- **和其他主流静态类型语言,比如 C、C++ 和 Java 不同,Go 函数支持多返回值。**多返回值可以让函数将更多结果信息返回给它的调用者,Go 语言的错误处理机制很大程度就是建立在多返回值的机制之上的。
- 函数返回值列表从形式上看主要有三种:
func foo() // 无返回值 func foo() error // 仅有一个返回值 func foo() (int, string, error) // 有2或2个以上返回值- 如果一个函数没有显式返回值,那么我们可以像第一种情况那样,在函数声明中省略返回值列表。
- 而且,如果一个函数仅有一个返回值,那么通常我们在函数声明中,就不需要将返回值用括号括起来,如果是 2 个或 2 个以上的返回值,那我们还是需要用括号括起来的。
- Go 标准库以及大多数项目代码中的函数,都选择了使用普通的非具名返回值形式。但在一些特定场景下,具名返回值也会得到应用。比如,当函数使用 defer,而且还在 defer 函数中修改外部函数返回值时,具名返回值可以让代码显得更优雅清晰。
函数是“一等公民”
- 函数在 Go 语言中属于“一等公民(First-Class Citizen)”。
- 特征一:Go 函数可以存储在变量中。
- 特征二:支持在函数内创建并通过返回值返回。
- Go 函数不仅可以在函数外创建,还可以在函数内创建。
- 而且由于函数可以存储在变量中,所以函数也可以在创建后,作为函数返回值返回。
- 闭包本质上就是一个匿名函数或叫函数字面值,它们可以引用它的包裹函数,也就是创建它们的函数中定义的变量。然后,这些变量在包裹函数和匿名函数之间共享,只要闭包可以被访问,这些共享的变量就会继续存在。
- 特征三:作为参数传入函数。
- 特征四:拥有自己的类型。
// $GOROOT/src/net/http/server.go type HandlerFunc func(ResponseWriter, *Request) // $GOROOT/src/sort/genzfunc.go type visitFunc func(ast.Node) ast.Visitor
Go 语言是如何进行错误处理的?
- Go 函数增加了多返回值机制,来支持错误状态与返回信息的分离,并建议开发者把要返回给调用者的信息和错误状态标识,分别放在不同的返回值中。
- 虽然,在 Go 语言中,我们依然可以像传统的 C 语言那样,用一个整型值来表示错误状态,但 Go 语言惯用法,是使用 error 这个接口类型表示错误,并且按惯例,我们通常将 error 类型返回值放在返回值列表的末尾。
error 类型与错误值构造
- error 接口是 Go 原生内置的类型,它的定义如下:
// $GOROOT/src/builtin/builtin.go type interface error { Error() string }- 任何实现了 error 的 Error 方法的类型的实例,都可以作为错误值赋值给 error 接口变量。
- 那这里,问题就来了:难道为了构造一个错误值,我们还需要自定义一个新类型来实现 error 接口吗?
- Go 语言的设计者显然也想到了这一点,他们在标准库中提供了两种方便 Go 开发者构造错误值的方法: errors.New 和 fmt.Errorf。
err := errors.New("your first demo error") errWithCtx = fmt.Errorf("index %d is out of bounds", i) - 这两种方法实际上返回的是同一个实现了 error 接口的类型的实例,这个未导出的类型就是 errors.errorString,它的定义是这样的:
// $GOROOT/src/errors/errors.go type errorString struct { s string } func (e *errorString) Error() string { return e.s } - 大多数情况下,使用这两种方法构建的错误值就可以满足我们的需求了。虽然这两种构建错误值的方法很方便,但它们给错误处理者提供的错误上下文(Error Context)只限于以字符串形式呈现的信息,也就是 Error 方法返回的信息。
- 但在一些场景下,错误处理者需要从错误值中提取出更多信息,帮助他选择错误处理路径,显然这两种方法就不能满足了。这个时候,我们可以自定义错误类型来满足这一需求。
// $GOROOT/src/net/net.go type OpError struct { Op string Net string Source Addr Addr Addr Err error }
Go 语言的几种错误处理的惯用策略
- 策略一:透明错误处理策略
- Go 语言中的错误处理,就是根据函数 / 方法返回的 error 类型变量中携带的错误值信息做决策,并选择后续代码执行路径的过程。
- 最简单的错误策略莫过于完全不关心返回错误值携带的具体上下文信息,只要发生错误就进入唯一的错误处理执行路径:
err := doSomething() if err != nil { // 不关心err变量底层错误值所携带的具体上下文信息 // 执行简单错误处理逻辑并返回 ... ... return err } - 这也是 Go 语言中最常见的错误处理策略,80% 以上的 Go 错误处理情形都可以归类到这种策略下。
- 策略二:“哨兵”错误处理策略
- 当错误处理方不能只根据“透明的错误值”就做出错误处理路径选取的情况下,错误处理方会尝试对返回的错误值进行检视,于是就有可能出现下面代码中的反模式:
data, err := b.Peek(1) if err != nil { switch err.Error() { case "bufio: negative count": // ... ... return case "bufio: buffer full": // ... ... return case "bufio: invalid use of UnreadByte": // ... ... return default: // ... ... return } } - 反模式就是,错误处理方以透明错误值所能提供的唯一上下文信息(描述错误的字符串),作为错误处理路径选择的依据。但这种“反模式”会造成严重的隐式耦合。这也就意味着,错误值构造方不经意间的一次错误描述字符串的改动,都会造成错误处理方处理行为的变化,并且这种通过字符串比较的方式,对错误值进行检视的性能也很差。
- Go 标准库采用了定义导出的(Exported)“哨兵”错误值的方式,来辅助错误处理方检视(inspect)错误值并做出错误处理分支的决策。
// $GOROOT/src/bufio/bufio.go var ( ErrInvalidUnreadByte = errors.New("bufio: invalid use of UnreadByte") ErrInvalidUnreadRune = errors.New("bufio: invalid use of UnreadRune") ErrBufferFull = errors.New("bufio: buffer full") ErrNegativeCount = errors.New("bufio: negative count") ) data, err := b.Peek(1) if err != nil { switch err { case bufio.ErrNegativeCount: // ... ... return case bufio.ErrBufferFull: // ... ... return case bufio.ErrInvalidUnreadByte: // ... ... return default: // ... ... return } }
- 当错误处理方不能只根据“透明的错误值”就做出错误处理路径选取的情况下,错误处理方会尝试对返回的错误值进行检视,于是就有可能出现下面代码中的反模式:
- 策略三:错误值类型检视策略
- 由于错误值都通过 error 接口变量统一呈现,要得到底层错误类型携带的错误上下文信息,错误处理方需要使用 Go 提供的类型断言机制(Type Assertion)或类型选择机制(Type Switch),这种错误处理方式,称之为错误值类型检视策略。
- 一般自定义导出的错误类型以XXXError的形式命名。和“哨兵”错误处理策略一样,错误值类型检视策略,由于暴露了自定义的错误类型给错误处理方,因此这些错误类型也和包的公共函数 / 方法一起,成为了 API 的一部分。
- 一旦发布出去,开发者就要对它们进行很好的维护。而它们也让使用这些类型进行检视的错误处理方对其产生了依赖。
- 标准库 errors 包提供了As函数给错误处理方检视错误值。As函数类似于通过类型断言判断一个 error 类型变量是否为特定的自定义错误类型。
- 策略四:错误行为特征检视策略
- 在 Go 标准库中,我们发现了这样一种错误处理方式:将某个包中的错误类型归类,统一提取出一些公共的错误行为特征,并将这些错误行为特征放入一个公开的接口类型中。这种方式也被叫做错误行为特征检视策略。
- 错误处理方只需要依赖这个公共接口,就可以检视具体错误值的错误行为特征信息,并根据这些信息做出后续错误处理分支选择的决策。
怎么让函数更简洁健壮?
- 健壮性的“三不要”原则
- 原则一:不要相信任何外部输入的参数。
- 为了保证函数的健壮性,函数需要对所有输入的参数进行合法性的检查。
- 一旦发现问题,立即终止函数的执行,返回预设的错误值。
- 原则二:不要忽略任何一个错误。
- 在我们的函数实现中,也会调用标准库或第三方包提供的函数或方法。
- 对于这些调用,我们不能假定它一定会成功,我们一定要显式地检查这些调用返回的错误值。
- 一旦发现错误,要及时终止函数执行,防止错误继续传播。
- 原则三:不要假定异常不会发生。
- 异常不是错误。错误是可预期的,也是经常会发生的,我们有对应的公开错误码和错误处理预案,但异常却是少见的、意料之外的。
- 虽然异常发生是“小众事件”,但是我们不能假定异常不会发生。所以,函数设计时,我们就需要根据函数的角色和使用场景,考虑是否要在函数内设置异常捕捉和恢复的环节。
- 原则一:不要相信任何外部输入的参数。
Go 函数的异常处理设计
- 在 Go 语言中,异常这个概念由 panic 表示。
- panic 指的是 Go 程序在运行时出现的一个异常情况。
- 如果异常出现了,但没有被捕获并恢复,Go 程序的执行就会被终止,即便出现异常的位置不在主 Goroutine 中也会这样。
- 在 Go 中,panic 主要有两类来源,一类是来自 Go 运行时,另一类则是 Go 开发人员通过 panic 函数主动触发的。
- 无论是哪种,一旦 panic 被触发,后续 Go 程序的执行过程都是一样的,这个过程被 Go 语言称为 panicking。
- 当函数 F 调用 panic 函数时,函数 F 的执行将停止。不过,函数 F 中已进行求值的 deferred 函数都会得到正常执行,执行完这些 deferred 函数后,函数 F 才会把控制权返还给其调用者。
- 对于函数 F 的调用者而言,函数 F 之后的行为就如同调用者调用的函数是 panic 一样,该 panicking过程将继续在栈上进行下去,直到当前 Goroutine 中的所有函数都返回为止,然后 Go 程序将崩溃退出。
- Go 也提供了捕捉 panic 并恢复程序正常执行秩序的方法,我们可以通过 recover 函数来实现这一点。
func bar() { defer func() { if e := recover(); e != nil { fmt.Println("recover the panic:", e) } }() println("call bar") panic("panic occurs in bar") zoo() println("exit bar") }- 我们在一个 defer 匿名函数中调用 recover 函数对 panic 进行了捕捉。
- recover 是 Go 内置的专门用于恢复 panic 的函数,它必须被放在一个 defer 函数中才能生效。
- 如果 recover 捕捉到 panic,它就会返回以 panic 的具体内容为错误上下文信息的错误值。如果没有 panic 发生,那么 recover 将返回 nil。而且,如果 panic 被 recover 捕捉到,panic 引发的 panicking 过程就会停止。
使用 defer 简化函数实现
- defer 是 Go 语言提供的一种延迟调用机制,defer 的运作离不开函数。
- 在 Go 中,只有在函数(和方法)内部才能使用 defer;
- defer 关键字后面只能接函数(或方法),这些函数被称为 deferred 函数。
- defer 将它们注册到其所在 Goroutine 中,用于存放 deferred 函数的栈数据结构中,这些 deferred 函数将在执行 defer 的函数退出前,按后进先出(LIFO)的顺序被程序调度执行。
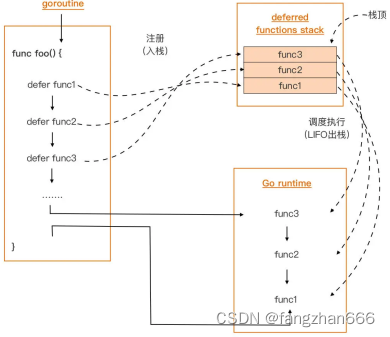
- 而且,无论是执行到函数体尾部返回,还是在某个错误处理分支显式 return,又或是出现 panic,已经存储到 deferred 函数栈中的函数,都会被调度执行。所以说,deferred 函数是一个可以在任何情况下为函数进行收尾工作的好“伙伴”。
- defer 使用的几个注意事项
- 第一点:明确哪些函数可以作为 deferred 函数
- 对于自定义的函数或方法,defer 可以给与无条件的支持,但是对于有返回值的自定义函数或方法,返回值会在 deferred 函数被调度执行的时候被自动丢弃。
- append、cap、len、make、new、imag 等内置函数都是不能直接作为 deferred 函数的,而 close、copy、delete、print、recover 等内置函数则可以直接被 defer 设置为 deferred 函数。
- 对于那些不能直接作为 deferred 函数的内置函数,我们可以使用一个包裹它的匿名函数来间接满足要求。
- 第二点:注意 defer 关键字后面表达式的求值时机
- defer 关键字后面的表达式,是在将 deferred 函数注册到 deferred 函数栈的时候进行求值的。
- 第三点:知晓 defer 带来的性能损耗
- defer 让我们进行资源释放(如文件描述符、锁)的过程变得优雅很多,也不易出错。但在性能敏感的应用中,defer 带来的性能负担也是我们必须要知晓和权衡的问题。
- 第一点:明确哪些函数可以作为 deferred 函数