目录
- C++标准模板库STL容器
- 容器分类
- 容器通用接口
- 顺序容器
- vector
- list
- deque
- 容器适配器
- queue
- stack
- priority_queue
- 关联容器:红黑树
- set
- multiset
- map
- multimap
- 关联容器:哈希表
- unordered_set和unordered_multiset
- unordered_map和unordered_multimap
- 附1:红黑树数据结构
- 附2:哈希表数据结构
- 附3:reserve和resize
C++标准模板库STL容器
容器都是类模板,它们实例化后就成为容器类。用容器类定义的对象称为容器对象。对象或变量插入容器时,实际插入的是对象或变量的一个复制品。
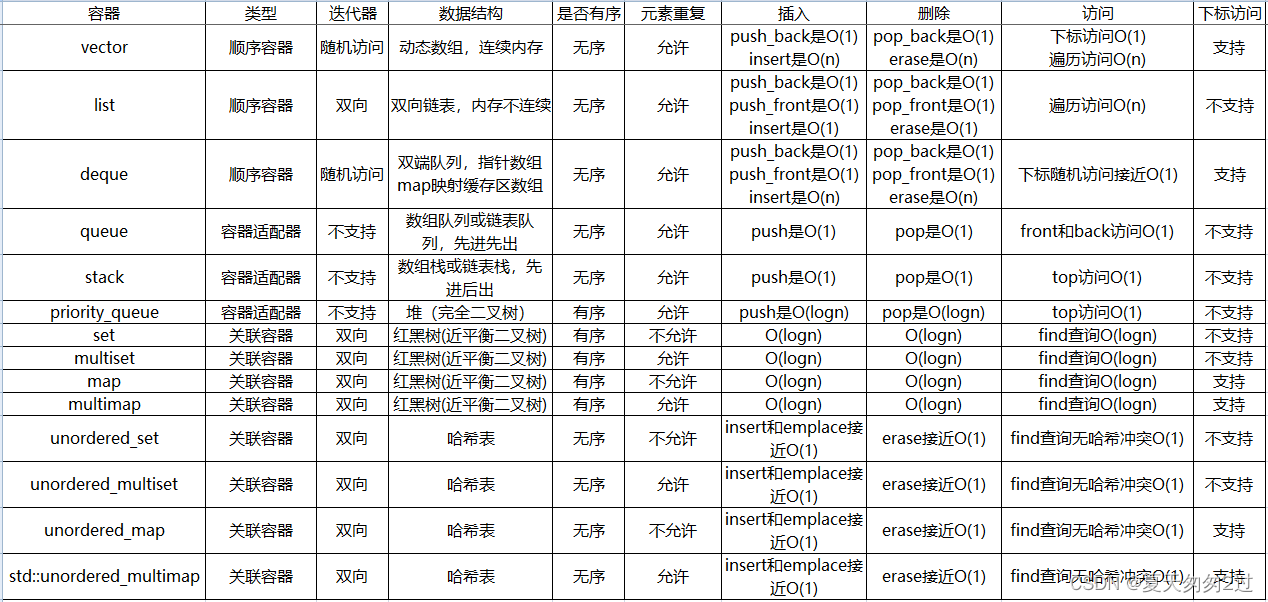
容器分类
顺序容器
1、元素在容器中的位置同元素的值无关,即容器不是排序的。
2、顺序容器包括:vector、deque、list。
关联容器
1、关联容器内的元素是有规则排列的(排序或加入哈希桶),插入元素时,容器会按一定的排序规则将元素放在适当的位置上。因为按规则排列,关联容器在查找时具有非常好的性能。
2、关联容器包括:set、multiset、map、multimap、unordered_set、unordered_multiset、unordered_map、std::unordered_multimap等。
3、不能修改关联容器中key的值,因为元素修改后容器并不会自动重新排序。正确的做法的是, 先删除该元素,再插入新元素。
容器适配器
1、STL在两类容器的基础上屏蔽一部分功能,突出或增加另一部分功能,实现了容器适配器。
2、STL中容器适配器有stack、queue、priority_queue三种,它们都是在顺序容器的基础上实现的。
容器通用接口
所有容器
int size( ) 返回容器对象中元素的个数
bool empty( ) 判断容器对象是否为空
顺序容器
front() 返回容器中第一个元素的引用
back() 返回容器中最后一个元素的引用
push_back() 在容器末尾增加新元素
pop_back() 删除容器末尾的元素
insert() 插入一个或多个元素
顺序容器和关联容器
begin( ) 返回指向容器中第一个元素的迭代器
end( ) 返回指向容器中最后一个元素后面的位置的迭代器
rbegin( ) 返回指向容器中最后一个元素的反向迭代器
rend( ) 返回指向容器中第一个元素前面的位置的反响迭代器
erase( ) 从容器中删除一个或几个元素
clear( ) 从容器中删除所有的元素
如果一个容器为空,则begin()和end()的返回值相等,rbegin()和rend()的返回值也相等
容器适配器
push:添加一个元素
top:返回顶部或对头的元素的引用
pop:删除一个元素
顺序容器
vector

1、动态数组,也叫可变长数组,在堆中分配内存,元素存放在连续的内存空间,支持下标随机访问,元素可重复,且是无序存放。
2、在头部或中间进行插入和删除操作时,会造成内存块的拷贝;对尾部进行插入和删除时一般不会拷贝内存;扩容时会内存拷贝。
扩容方式
开辟二倍的内存;旧的数据拷贝到新的内存;释放旧内存;重新指向新内存。
时间复杂度
1、[ ]或at()下标访问任意元素,时间复杂度是O(1)。
2、push_back尾部插入、pop_back尾部删除,时间复杂度O(1)。
3、insert插入、erase删除时间复杂度O(n)。
#include <vector>
std::vector<int> _v;
_v.push_back(20);//尾部添加元素
_v.push_back(10);
_v.push_back(10);//{20,10,10}
printf("_v.front=%d\n",_v.front());//队首元素,_v.front=20
printf("_v.back=%d\n",_v.back());//队尾元素,_v.back=10
_v.pop_back();//移除尾部元素,{20,10}
_v.insert(_v.begin() + 1, 30); //在指定的位置插入元素10的拷贝,{20,30,10}
_v.erase(_v.begin() + 2);//删除指定位置的元素,{20,30}
//遍历,可以使用下标遍历,也可以使用迭代器遍历
auto iter = _v.begin();
while(iter != _v.end())
{
printf("value=%d\n",*iter);
iter++;
}
printf("_v[0]=%d,_v.at(1)=%d\n",_v[0],_v.at(1));//下标访问,越界crash,at抛出异常
打印
_v.front=20
_v.back=10
value=20
value=30
_v[0]=20,_v.at(1)=30
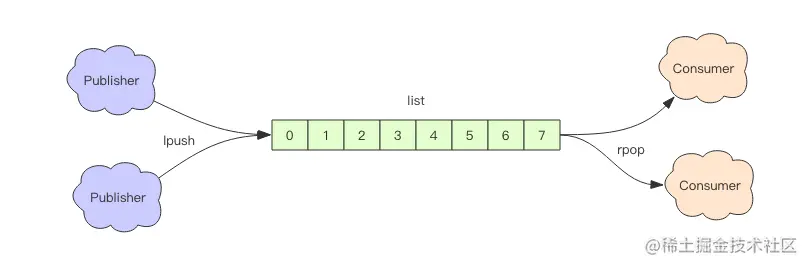
list
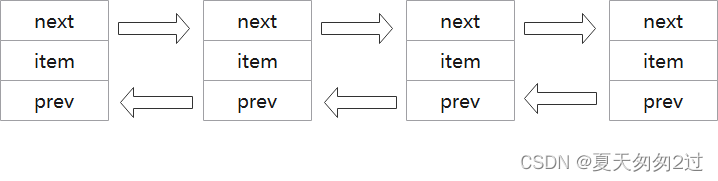
1、双向链表,存放在堆中,内存空间是不连续的,每个元素都存放在一块内存中,通过指针指向上一个元素和下一个元素。元素可重复,且是无序存放。
2、不需要扩容,添加元素时分配内存,删除元素时回收内存。
3、在任何位置添加和删除元素效率都很高,无需内存拷贝。
4、不能下标随机访问,访问任意元素效率低。
时间复杂度
1、访问首部和尾部是O(1),访问其他元素是O(n)。
2、push_back、push_front、insert插入是O(1),pop_front、pop_back、erase删除是O(1)。
#include <list>
std::list<int> _l;
_l.push_back(20);//尾部添加元素
_l.push_back(30);
_l.push_back(40);
_l.push_front(10);//头部添加元素{10,20,30,40}
printf("_l.front=%d\n",_l.front());//访问队首元素,_l.front=10
printf("_l.back=%d\n",_l.back());//访问队尾元素,_l.back=40
_l.pop_back();//移除尾部元素,{10,20,30}
_l.pop_front();//移除头部元素,{20,30}
//list迭代器只能++/--,不能+i随机访问
_l.erase(_l.begin());//删除指定位置的元素,{30}
_l.insert(++_l.begin(), 50); //在指定的位置插入元素10的拷贝,{30,50}
//使用迭代器遍历,不能使用下标访问
auto iter = _l.begin();
while(iter != _l.end())
{
printf("value=%d\n",*iter);
iter++;
}
打印
_l.front=10
_l.back=40
value=30
value=50
deque

1、双端队列,deque类似于一个二维数组,由多个连续小空间拼接而成,引入map管理分段空间;map是一块连续的空间,map的每个元素是指向缓存区buffer的指针,每个缓存区buffer存储多个元素。
2、deque底层是假象的连续空间,实际上是分段连续的,为了“整体连续”和下标随机访问,deque定义了复杂的迭代器,实现随机访问。
3、deque结合了vector和list的优缺点,在队首和队尾进行插入和删除操作时效率高,遍历和排序效率低,中间插入和删除元素仍然存在内存拷贝,随机访问时需要计算数据在哪个buffer的第几个数据,效率低于vector。
4、deque功能全面,但效率普遍较低,实际应用时很少使用,通常作为stack和queue的底层默认容器(stack和queue不需要遍历,只需要在固定的一端或者两端进行操作,且deque扩容时不需要内存拷贝)。
时间复杂度
1、访问首部和尾部是O(1),下标访问其他元素时接近O(1)。
2、push_back、push_front插入是O(1),pop_front、pop_back删除是O(1)。
3、insert插入、erase删除时间复杂度O(n)。
支持首尾添加元素/访问元素/移除元素,支持下标访问和迭代器随机访问,几乎支持vector和list的所有功能。
#include <deque>
std::deque<int> _d;
_d.push_back(20);//尾部添加元素
_d.push_back(30);
_d.push_back(40);
_d.push_front(10);//头部添加元素{10,20,30,40}
printf("_d.front=%d\n",_d.front());//访问队首元素,_d.front=10
printf("_d.back=%d\n",_d.back());//访问队尾元素,_d.back=40
_d.pop_back();//移除尾部元素,{10,20,30}
_d.pop_front();//移除头部元素,{20,30}
_d.erase(_d.begin());//删除指定位置的元素,{30}
_d.insert(_d.begin() + 1, 80); //在指定的位置插入元素,{30,80}
//使用迭代器遍历
auto iter = _d.begin();
while(iter != _d.end())
{
printf("value=%d\n",*iter);
iter++;
}
printf("_d[0]=%d,_d.at(1)=%d\n",_d[0],_d.at(1));//下标访问,越界crash,at抛出异常
打印
_d.front=10
_d.back=40
value=30
value=80
_d[0]=30,_d.at(1)=80
容器适配器
queue
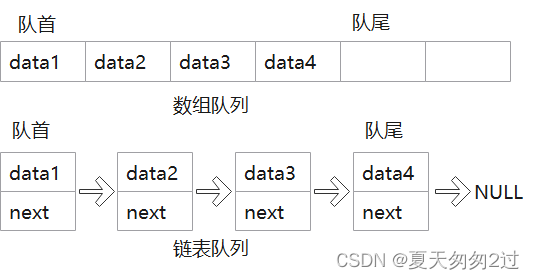
1、队列,先进先出的数据结构,只支持在队尾添加元素,在队首删除元素。
2、queue可以指定底层容器(例如std::queue<int, std::list> q1),可以是基于数组的队列,也可以是基于链表的队列,即顺序队列和链表队列。
3、queue不提供迭代器访问,不能使用下标访问。
时间复杂度
1、插入push和删除pop是O(1)。
2、front和back访问是O(1)。
#include <queue>
std::queue<int> _q;
_q.push(10);//尾部添加元素
_q.push(20);
_q.push(30);
_q.push(40);//{10,20,30,40}
printf("_q.front=%d\n",_q.front());//访问队首元素,_q.front=10
printf("_q.back=%d\n",_q.back());//访问队尾元素,_q.back=40
_q.pop();//移除队首元素,{20,30,40}
//不能使用下标和迭代器访问
打印
_q.front=10
_q.back=40
stack
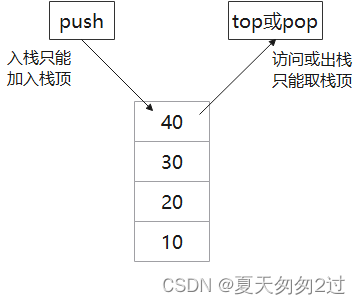
1、数据栈,先进后出的数据结构,单端口进出,数据入栈只能加入栈顶,数据出栈也只能取栈顶的元素。
2、stack和queue数据结构类似,可以指定底层容器,默认是deque,分数组栈和链表栈。
3、stack不提供迭代器访问,不能使用下标访问。
时间复杂度
1、入栈push和出栈pop是O(1)。
2、top访问是O(1)。
#include <stack>
std::stack<int> _s;
_s.push(10);//顶部添加元素
_s.push(20);
_s.push(30);
_s.push(40);//{10,20,30,40}
printf("_s.top=%d\n",_s.top());//访问顶部元素,_s.top=40
_s.pop();//移除顶部元素,{10,20,30}
priority_queue
1、优先级队列 priority_queue,常用来对数据进行优先级处理,比如优先级高的值在前面,常用堆(Heap)来实现,底层是以vector数组存储的完全二叉树。
2、优先级队列是一个拥有权值的queue,其内部元素按照元素的权值排列。权值较高者排在最前优先出队。
3、priority_queue不提供迭代器访问,不能使用下标访问。
堆是一种特殊的树,只要满足以下两个条件,就可以称这棵树为堆:
1、堆是一颗完全二叉树(完全二叉树要求,除了最后一层,其他节点个数都是满的,最后一层的节点都靠左排列)。
2、堆中的每一个节点都必须大于等于(或者小于等于)其子树中每个节点的值。
时间复杂度
1、使用vector数组构造priority_queue是O(n)。
2、插入元素push和移除堆顶pop是O(log(n))。
3、访问堆顶top是O(1)。
以下面程序举例,数据结构如下
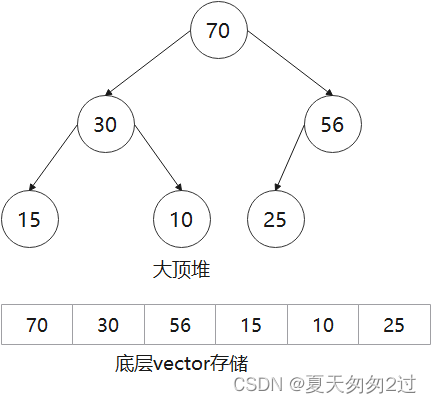
#include <queue>
std::vector<int> v{ 1,2,3,4,5,6,7,8,9,10 };
std::priority_queue<int> p1(v.begin(), v.end());//使用vector数组构造大顶堆
printf("p1.top=%d\n",p1.top());//访问顶部元素,.top=10
// std::priority_queue <int,std::vector<int>,std::greater<int> > _p2;//小顶堆
std::priority_queue<int> _p;//默认大顶堆
_p.push(56);//添加一个元素,自动排序
_p.push(15);
_p.push(70);
_p.push(30);
_p.push(10);
_p.push(25);//{70,30,56,15,10,25}
printf("_p.top=%d\n",_p.top());//访问顶部元素,_p.top=70
_p.pop();//移除顶部元素,重新排序,{56,30,25,15,10}
打印
p1.top=10
_p.top=70
关联容器:红黑树
set
1、set是排序的、不重复的数据集合。
2、set元素类型是pair,存储键值对,且key和value必须相等。
3、set中的元素不能直接改变,可以先删除再添加。
4、set底层是以红黑树数据结构实现,节点存储值key。
5、set在内存中表现为一个排序的数组。
6、不支持下标访问。
时间复杂度
1、插入、删除、查找,都是严格在O(logn)时间内完成。
#include <set>
std::set<int> s1;//定义一个空set
std::set<int>::iterator it;//s1的迭代器类型
std::pair<std::set<int>::iterator,bool> ret;//插入数据的返回值类型,first是指向插入数据的迭代器,second标识是否插入成功
// 单个数据插入
for (int i=1; i<=5; ++i)
s1.insert(i*10); // {10,20,30,40,50}
ret = s1.insert(20); // 重复插入时失败,返回的迭代器指向容器中已存在的值,bool为false
if (ret.second==false)
it=ret.first; // "it" now points to element 20
s1.erase(50);// 通过值删除元素,{10,20,30,40}
s1.insert (it,25);//通过迭代器插入,{10,20,25,30,40}
//区间插入
int myints[]= {5,10,15};
s1.insert (myints,myints+3);
//迭代器遍历访问
for (it=s1.begin(); it!=s1.end(); ++it)
printf("*it=%d ",*it);
printf("\n");
auto iter = s1.find(20);//find查询元素是否在set集合中
if(iter != s1.end())
{
printf("found 20\n");
}
打印
*it=5 *it=10 *it=15 *it=20 *it=25 *it=30 *it=40
found 20
multiset
multiset类似与set,区别在于multiset支持插入重复的元素,insert函数没有返回值,有重复元素时count函数返回值大于1。
map
1、map中存储的是键值对<key,value>,根据key有序排列,且key唯一。
2、map底层是以红黑树数据结构实现。
3、使用迭代器可以对value进行修改,但不能修改key,若要修改key,可以先删除再添加。
4、可以通过[key]或at(key)下标访问,若map中没有该key,则[ ]会向map中添加键值对,at()抛出异常或crash。
5、map在内存中表现为根据key排序的一组键值对。
时间复杂度
1、插入、删除、查找,都是严格在O(logn)时间内完成。
#include <map>
std::map<int,std::string> map1;//定义一个空map
std::map<int,std::string>::iterator it;//map1的迭代器类型
//插入数据的返回值类型,first是指向插入数据的迭代器,second标识是否插入成功
std::pair<std::map<int,std::string>::iterator,bool> ret;
//1.通过pair<int, string>(1,"lilei") 构造pair元素
map1.insert(std::pair<int, std::string>(1,"lilei"));
//2.通过make_pair构造pair元素
map1.insert(std::make_pair(2,"hmm"));
//3.通过value_type构造pair元素
map1.insert(std::map<int, std::string>::value_type(3,"zsan"));
//4.[ ]下标插入
map1[4] = "zsi";
//5.emplace插入
map1.emplace(5,"chw");
ret = map1.emplace(2,"hmei");
if(ret.second == false)//插入失败,返回false
printf("ret.first=%s\n",ret.first->second.c_str());
bool ret2 = map1.erase(1);//通过key删除元素,成功返回true,失败返回false
printf("erase ret2=%d\n",ret2);
//find查找key
auto iter_find = map1.find(3);
if(iter_find != map1.end())
{
printf("find key=%d,value=%s\n",iter_find->first,iter_find->second.c_str());
}
//迭代器安全删除
std::map<int,std::string>::iterator ite_es = map1.begin();
while(ite_es != map1.end())
{
if(ite_es->first == 3)
{
ite_es = map1.erase(ite_es);
}
else
++ite_es;
}
//迭代器遍历
auto iter_bl = map1.begin();
while(iter_bl != map1.end())
{
printf("key=%d,value=%s\n",iter_bl->first,iter_bl->second.c_str());
++iter_bl;
}
打印
ret.first=hmm
erase ret2=1
find key=3,value=zsan
key=2,value=hmm
key=4,value=zsi
key=5,value=chw
multimap
multimap类似与map,区别在于multimap支持插入重复的元素,insert和emplace函数没有返回值,有重复元素时count函数返回值大于1。multimap不能使用[ ]下标插入。
关联容器:哈希表
unordered_set和unordered_multiset
1、这两个容器的操作集类似于set和multiset,区别在于unordered_set和unordered_multiset的底层数据结构是哈希表。
2、哈希表是通过把key进行哈希运算,分配到哈希桶,哈希桶内使用链表法解决哈希冲突。通过key就可以快速找到哈希桶的位置,因此查找效率高。
时间复杂度
1、在没有哈希冲突的情况下,查找是O(1)。
unordered_map和unordered_multimap
1、这两个容器的操作集类似于map和multimap,区别在于unordered_map和unordered_multimap的底层数据结构是哈希表。
2、哈希表是通过把key进行哈希运算,分配到哈希桶,哈希桶内使用链表法解决哈希冲突。通过key就可以快速找到哈希桶的位置,因此查找效率高。
时间复杂度
1、在没有哈希冲突的情况下,查找是O(1)。
unordered_map用法参考这里:https://blog.csdn.net/weixin_40355471/article/details/131803322?spm=1001.2014.3001.5502。
附1:红黑树数据结构
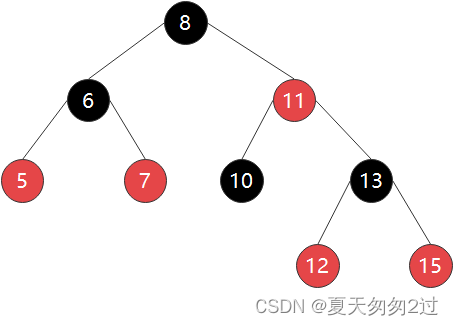
红黑树并不是严格的平衡二叉树,它要求从根到叶子的最长路径不多于最短路径的两倍长,为了满足这个特性,红黑树设置了五大规则:
1、节点是红色或者黑色
2、根节点是黑色
3、每个叶子的节点都是黑色的空节点
4、每个红色节点的两个子节点都是黑色的
5、从任意节点到其叶子节点的每条路径都包含相同个数的黑色节点
红黑树的高度近似logn,是近似平衡的二叉树,插入、删除、查找的时间复杂度都是O(logn),性能非常稳定,在实际工作中,凡是动态插入、删除、查找数据的场景都可以用它。
附2:哈希表数据结构
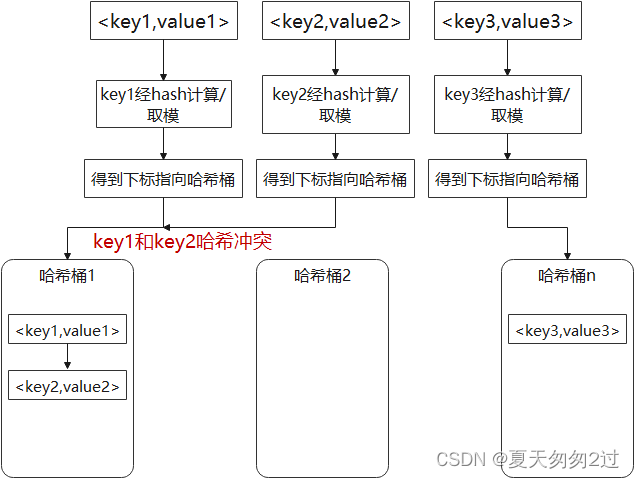
哈希表也叫散列表(Hash table),是根据关键码值(Key value)而直接进行访问的数据结构。它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
下图是一个典型应用,key经过哈希函数计算得到哈希值,哈希值对一个常数n取模得到下标,通过下标可以直接访问哈希桶,哈希桶内存放<key,value>,如果有哈希冲突,在哈希桶内使用链表存储。
附3:reserve和resize
这两个函数常用于STL容器容量操作。
1、reserve,只分配空间,不创建对象,不可访问,用于大量成员创建,一次性分配空间,push_back时就不用再分配,提高执行效率。
2、resize,分配空间的同时还创建对象,并给对象赋初始值,可访问。
std::vector<int> v1;
v1.resize(5);//分配空间并初始化对象为0,此时元素个数是5
v1.push_back(10);
for(int index=0;index<v1.size();index++)
printf("v1[%d]=%d ",index,v1[index]);
printf("\n");
std::vector<int> v2;
v2.reserve(5);//只分配空间,不创建对象,此时元素个数是0
v2.push_back(20);
for(int index=0;index<v2.size();index++)
printf("v2[%d]=%d ",index,v2[index]);
printf("\n");
打印
v1[0]=0 v1[1]=0 v1[2]=0 v1[3]=0 v1[4]=0 v1[5]=10
v2[0]=20