文章目录
- 网络通信过程
- NAT穿透
- python高级
- GIL锁
- 深拷贝与浅拷贝
- 私有化
- import导入模块
- 工厂模式
- 多继承以及 MRO 顺序
- 烧脑题
- property属性
- property装饰器
- property类属性
- 魔法属性
- \_\_doc\_\_
- \_\_module\_\_ 和 \_\_class\_\_
- \_\_init\_\_
- \_\_del\_\_
- \_\_call\_\_
- \_\_dict\_\_
- \_\_str\_\_
- \_\_getitem\_\_、\_\_setitem\_\_、\_\_delitem\_\_
- with和“上下文管理器”
网络通信过程
基础部分略,实际上就是计网的知识
NAT穿透
NAT穿透(Network Address Translation traversal,简称NAT穿透)是一种通过网络地址转换(NAT)设备或防火墙的障碍,使外部网络能够访问位于NAT后面的内部网络设备的技术。
NAT穿透的原理是通过一系列的技术手段,使得外部网络能够直接与内部网络中的设备进行通信,而无需修改NAT设备的配置或绕过防火墙的限制。NAT穿透技术可以应用于各种场景,如远程桌面、文件共享、视频会议等。
这边介绍一种微信视频聊天 和 百度网盘所使用的NAT穿透(移动电信深痛恶绝doge)
首先介绍一下我们通信的流程:

实际上就是服务器先接收到两个想要连接的用户ip地址,然后吧用户2的ip传递给用户1 用户1的传递给用户2 然后他们俩进行自己聊天,不需要经由服务器的沟通。
这边给一个简单的代码,仅供参考:
服务器代码:
#!/usr/bin/python
# coding=utf-8
from socket import *
#建链
# 1. 创建套接字
udp_socket = socket(AF_INET, SOCK_DGRAM)
# 2. 绑定本地的相关信息,需要使用阿里云的内网地址
local_addr = ('183.129.206.230', 8000) # ip地址和端口号,ip一般不用写,表示本机的任何一个ip
udp_socket.bind(local_addr)
# 3. 等待接收对方发送的数据
recv_boy_data = udp_socket.recvfrom(1024) # 1024表示本次接收的最大字节数
# 4. 显示接收到的数据
print(recv_boy_data[0].decode('utf-8')) #数据
print(recv_boy_data[1]) #男方IP地址和端口
# # 这是你女朋友发过来的请求
recv_girl_data = udp_socket.recvfrom(1024) # 1024表示本次接收的最大字节数
print(recv_girl_data[0].decode('utf-8'))
print(recv_girl_data[1]) #女方IP地址和端口
# 给你女朋友发你的ip地址和端口
udp_socket.sendto((recv_boy_data[1][0] + " " + str(recv_boy_data[1][1])).encode('utf-8'), recv_girl_data[1])
# 给boy发他女朋友的ip地址和端口
udp_socket.sendto((recv_girl_data[1][0] + " " + str(recv_girl_data[1][1])).encode('utf-8'), recv_boy_data[1])
udp_socket.close()
用户A:
#!/usr/bin/python
# coding=utf-8
from socket import *
import select
import sys
# 1. 创建套接字
udp_socket = socket(AF_INET, SOCK_DGRAM)
# 注意 是元组,ip是字符串,端口是数字
# 2.这里是服务器的IP地址和端口
dest_addr = ('47.115.45.50', 8000)
# 3. 从键盘获取数据
send_data = input("请输入要发送的数据:")
# 4. 发送数据到指定的电脑上的指定程序中
udp_socket.sendto(send_data.encode('utf-8'), dest_addr)
recv_data = udp_socket.recvfrom(1000)
print(recv_data[0].decode('utf-8'))
# 5. 关闭套接字
ip_port = recv_data[0].decode('utf-8').split()
ip_port[1] = int(ip_port[1])
print(ip_port)
epoll = select.epoll()
# select.EPOLLIN如果缓冲区里有数据,就可读
epoll.register(udp_socket.fileno(), select.EPOLLIN)
epoll.register(sys.stdin.fileno(), select.EPOLLIN)
while True:
epoll_list = epoll.poll()
# print(epoll_list)
for fd, event in epoll_list:
if fd == sys.stdin.fileno():
try:
input_data = input()
except:
print('I want go')
exit(0)
udp_socket.sendto(input_data.encode('utf-8'), ip_port)
if fd == udp_socket.fileno():
recv_data = udp_socket.recvfrom(1024)
print(recv_data[0].decode('utf-8'))
udp_socket.close()
用户B:
#!/usr/bin/python
# coding=utf-8
from socket import *
import select
import sys
#男生
# 1. 创建套接字
udp_socket = socket(AF_INET, SOCK_DGRAM)
# 注意 是元组,ip是字符串,端口是数字
# 2.这里是服务器的IP地址和端口
dest_addr = ('183.129.206.230', 8000)
# 3. 从键盘获取数据
send_data = input("请输入要发送的数据:")
# 4. 发送数据到指定的电脑上的指定程序中
udp_socket.sendto(send_data.encode('utf-8'), dest_addr)
#从百度服务器接数据
recv_data = udp_socket.recvfrom(1000)
print(recv_data[0].decode('utf-8'))
# 5. 关闭套接字
#收到ip和端口后,进行分割
ip_port = recv_data[0].decode('utf-8').split()
ip_port[1] = int(ip_port[1])
ip_port=tuple(ip_port)
print(ip_port)
#给女方发一个world
udp_socket.sendto('I am boy'.encode('utf-8'), ip_port)
recv_data=udp_socket.recvfrom(1024)
print(recv_data[0].decode('utf-8'))
#男方先说话
while True:
input_data = input('请输入数据')
udp_socket.sendto(input_data.encode('utf-8'), ip_port)
recv_data = udp_socket.recvfrom(1024)
print(recv_data[0].decode('utf-8'))
udp_socket.close()
python高级
GIL锁
实际上就是python内置的一个锁,每个线程在执行的过程都需要先获取 GIL,保证同一时刻只有一个线程可以执行代码,这也就导致了python的多线程效果很不好。
深拷贝与浅拷贝
浅拷贝是对于一个对象的顶层拷贝,通俗的理解是:拷贝了引用,并没有拷贝内容
深拷贝是对于一个对象所有层次的拷贝(递归)
这边给一个浅拷贝的例子:

深拷贝例子:
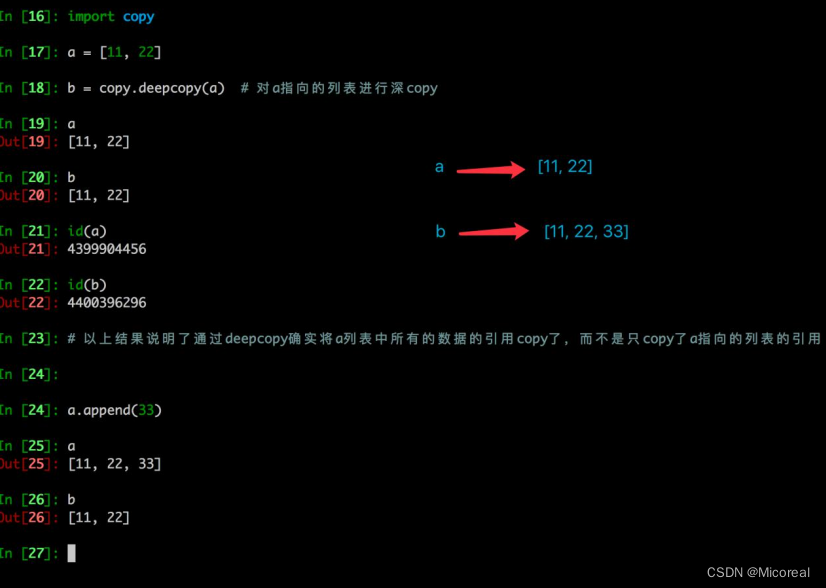
总结就是:
a=[1,2]
b=[3,4]
c=[a,b]
浅拷贝
d=copy.copy(c)
实际上做到的只有第一层次的拷贝,也就是d=[a,b],d内部元素仍然是a的引用 b的引用
深拷贝
e=copy.deepcopy(c)
此时e当中的元素就不再是a的引用,而是一个完全新的不过值相等的值
私有化
- xx: 公有变量
- _x: 单前置下划线,私有化属性或方法,from somemodule import *禁止导入,类对象和子类可以访问
- __xx:双前置下划线,避免与子类中的属性命名冲突,无法在外部直接访问(名字重整所以访问不到)
- __xx__:双前后下划线,用户名字空间的魔法对象或属性。例如:__init__ , 不要自己发明这样的名字
- xx_:单后置下划线,用于避免与 Python 关键词的冲突
class Person(object):
def __init__(self, name, age, taste):
self.name = name
self._age = age
self.__taste = taste
def showperson(self):
print(self.name)
print(self._age)
print(self.__taste)
def dowork(self):
self._work()
self.__away()
def _work(self):
print('my _work')
def __away(self):
print('my __away')
class Student(Person):
def construction(self, name, age, taste):
self.name = name
self._age = age
self.__taste = taste
def showstudent(self):
print(self.name)
print(self._age)
print(self.__taste)
@staticmethod
def testbug():
_Bug.showbug()
# 模块内可以访问,当from cur_module import *时,不导入
class _Bug(object):
@staticmethod
def showbug():
print("showbug")
s1 = Student('jack', 25, 'football')
s1.showperson()
print('*'*20)
# 无法访问__taste,导致报错
# s1.showstudent()
s1.construction('rose', 30, 'basketball')
s1.showperson()
print('*'*20)
s1.showstudent()
print('*'*20)
Student.testbug()
总结一下
父亲拥有 p _pp __ppp三种属性,以及一个显示三种属性的方法show_parent
孩子拥有 p _pp __ppp三种属性,以及一个显示三种属性的方法show_children
那么此时定义一个孩子对象(孩子继承父亲)c,那这个c构造的过程就是先去寻找孩子的init,如果没有就去找父亲的init进行构造
那如果孩子没有init的话,那么我们构造的这些属性实际上是在父亲init下构造的属性,我们使用show_children实际上访问不到那些属性,除非我们把这些属性再次定义到孩子当中
所以我们一定脑中要有两个空间这种想法,即使是继承的属性,来源都是不同的,就比如说俩个__ppp属性,我们访问孩子的这个属性和父亲的这个属性是完全不一样的,两个空格隔开,只有公有属性是存储在相同空间的
import导入模块
common文件
HHH = False
from common import HHH
import common
用上面两种形式进行导入参数有什么区别呢?
不仅仅是使用上的区别:
对于from导入的,实际上是新的HHH,他和原本common文件的HHH是不一致的,他实际上是一个新id的复制过来的值,二使用import的才是一致的,所以对于可变数据类型,尽量避免使用全局变量,如果使用,一定要区分好上文两种情况,而且使用也尽量只采用可读的形式,不要进行修改值的操作。
工厂模式
class animal():
def eat(self):
pass
def voice(self):
pass
class dog(animal):
def eat(self):
print ('狗吃骨头')
def voice(self):
print ('狗叫汪汪')
class cat(animal):
def eat(self):
print ('猫吃鱼')
def voice(self):
print ('猫叫喵喵')
class factoryAni:
def __init__(self):
self.d = {'dog':dog,'cat':cat}
def createAni(self,aniType):
return d[aniType]()
fa = factoryAni()
d = fa.createAni('dog')
d.eat()
d.voice()
上面这种形式实际上就是为了满足生产过程中,往往都是前端点击某个控件,然后前端传回数据给后端,然后后端根据那个数据来进行创建相对应的类对象,这就是多态。
多继承以及 MRO 顺序
# 1.使用super
# 2.要使用*args,**kwargs
class Parent(object):
def __init__(self, name, *args, **kwargs): # 为避免多继承报错,使用不定长参数,接受参数
print('parent的init开始被调用')
self.name = name
print('parent的init结束被调用')
class Son1(Parent):
def __init__(self, name, age, *args, **kwargs): # 为避免多继承报错,使用不定长参数,接受参数
print('Son1的init开始被调用')
self.age = age
super().__init__(name, *args, **kwargs) # 为避免多继承报错,使用不定长参数,接受参数
print('Son1的init结束被调用')
class Son2(Parent):
def __init__(self, name, gender, *args, **kwargs): # 为避免多继承报错,使用不定长参数,接受参数
print('Son2的init开始被调用')
self.gender = gender
super().__init__(name, *args, **kwargs) # 为避免多继承报错,使用不定长参数,接受参数
print('Son2的init结束被调用')
class Grandson(Son1, Son2):
def __init__(self, name, age, gender):
print('Grandson的init开始被调用')
# 多继承时,相对于使用类名.__init__方法,要把每个父类全部写一遍
# 而super只用一句话,执行了全部父类的方法,这也是为何多继承需要全部传参的一个原因
# super(Grandson, self).__init__(name, age, gender)
super().__init__(name, age, gender)
print('Grandson的init结束被调用')
print(Grandson.__mro__) #打印出来顺序是谁,将来调用的就是谁
gs = Grandson('grandson', 12, '男')
print('姓名:', gs.name)
print('年龄:', gs.age)
print('性别:', gs.gender)
输出:
(<class '__main__.Grandson'>, <class '__main__.Son1'>, <class '__main__.Son2'>, <class '__main__.Parent'>, <class 'object'>)
Grandson的init开始被调用
Son1的init开始被调用
Son2的init开始被调用
parent的init开始被调用
parent的init结束被调用
Son2的init结束被调用
Son1的init结束被调用
Grandson的init结束被调用
姓名: grandson
年龄: 12
性别: 男
ORM执行顺序实际上是先按照继承顺序,先继承son1,然后2,然后son1的父亲。 类似一个吃豆豆的过程,资源在一次次继承中,被吃掉
烧脑题
# 作者: 王道 龙哥
# 2022年03月22日09时50分20秒
class Parent(object):
x = 1
class Child1(Parent):
pass
class Child2(Parent):
pass
print(Parent.x, Child1.x, Child2.x) # 1 1 1
Child1.x = 2 #对child1增加了类属性
print(Parent.x, Child1.x, Child2.x) # 1 2 1
Parent.x = 3
print(Parent.x, Child1.x, Child2.x) # 3 2 3
c1=Child1()
c2=Child2()
p=Parent()
print(c1.x,c2.x,p.x) # 2 3 3
c1.x=4
print(c1.x,c2.x,p.x) # 4 3 3
print(Child1.x, Child2.x,Parent.x) # 2 3 3
p.x=5
print(c1.x,c2.x,p.x) # 4 3 5
上面的情况实际上值得分析一波:
首先先区分好类属性和对象属性两种概念,然后就是关于上面三中的 定义,我们只对parent定义了类属性1,然后打印第一次的
print(Parent.x, Child1.x, Child2.x) # 1 1 1
实际上打印的是parent的类属性x,然后child1没找到他的类属性,所以打印parent的类属性x 也是1 ,child2同理。
然后就是:
Child1.x = 2
实际上做的事情就是在child1上添加了x的类属性2
自然打印出来就是1 2 1
后面的 3 2 3也不难理解
紧接着创建了三个对象,但此时注意三个对象都是没有对象x的属性的,只有类属性
print(c1.x,c2.x,p.x) # 2 3 3
此时这句话实际上由于都没有对象x属性,所以三者调用的都是其类属性
c1.x=4
然后这句话是将c1的对象x属性新增成4,所以就有后续的4 3 3
那么最后一个4 3 5就交给大家自己分析。
property属性
使用property 有两种方式:
- 装饰器 即:在方法上应用装饰器
- 类属性 即:在类中定义值为 property 对象的类属性 (但是进行调用的时候仍然是要使用obj进行调用 ,他只是声明的形式像类属性)
property装饰器
给一个简单的例子:
class Foo:
def func(self):
pass
# 定义 property 属性
@property
def prop(self):
return ```
然后如果是正常我们想要调用prop属性,我们需要foo_obj.prop(),但是在@property的修饰下,我们调用这个直接使用foo_obj.prop即可
然后就是使用property的时候需要注意:
- 定义时,在实例方法的基础上添加 @property 装饰器
- 仅有一个 self 参数
- 调用时,无需括号
- 一定需要有一个返回值,因为你调用的时候实际上都是将之当作一个需要临时读取某些条件,然后进行计算出的属性
扩展
属性有三种访问方式:
| 方式 | 说明 |
|---|---|
| @property | 获取的时候的方法 不能有self之外的参数 |
| @方法名.setter | 修改的时候调用的方法 需要有一个赋值的参数 |
| @方法名.deleter | 删除的时候调用的方法,不需要除了self外的参数 |
例子:
class Goods:
@property
def price(self):
print('@property')
@price.setter
def price(self, value):
print(value)
print('@price.setter')
@price.deleter
def price(self):
print('@price.deleter')
# ############### 调用 ###############
obj = Goods()
obj.price # 自动执行 @property 修饰的 price 方法,并获取方法的返回值
obj.price = 123 # 自动执行 @price.setter 修饰的 price 方法,并将 123 赋值给方法的参数
del obj.price # 自动执行 @price.deleter 修饰的 price 方法
property类属性
当使用类属性的方式创建 property 属性时,经典类和新式类没有区别,使用也是一样的。
property 方法中有个四个参数:
- 第一个参数是方法名,调用 对象.属性 时自动触发执行方法
- 第二个参数是方法名,调用 对象.属性 = XXX 时自动触发执行方法
- 第三个参数是方法名,调用 del 对象.属性 时自动触发执行方法
- 第四个参数是字符串,调用 类名.属性__doc__ ,此参数是该属性的描述信息
例子:
class Goods(object):
def __init__(self):
# 原价
self.original_price = 100
# 折扣
self.discount = 0.8
def get_price(self):
# 实际价格 = 原价 * 折扣
new_price = self.original_price * self.discount
return new_price
def set_price(self, value):
self.original_price = value
def del_price(self):
del self.original_price
PRICE = property(get_price, set_price,del_price,"description")
obj = Goods()
print(obj.PRICE) # 获取商品价格\
print(Goods.PRICE.__doc__) #打印描述,要用类名.property属性
obj.PRICE = 200 # 修改商品原价
print(obj.PRICE)
del obj.PRICE # 删除商品原价
魔法属性
__doc__
表示类的描述信息
class Foo:
""" 111 """
def func(self)->int:
"""
222
"""
pass
print(Foo.__doc__)
print(Foo.func.__doc__)
输出结果:
111
222
__module__ 和 __class__
- __module__ 表示当前操作的对象在那个模块
- __class__ 表示当前操作的对象的类是什么
# test.py
class Person(object):
def __init__(self):
self.name = 'laowang'
# main.py
from test import Person
obj = Person()
print(obj.__module__) # 输出 test 即:输出模块
print(obj.__class__) # 输出 test.Person 即:输
__init__
初始化方法,通过类创建对象时,自动触发执行
__del__
当对象在内存中被释放时,自动触发执行。
注:此方法一般无须定义,因为 Python 是一门高级语言,程序员在使用时无需关心内存的分配和释放,因为此工作都是交给 Python 解释器来执行。
__call__
对象后面加括号,触发执行
class Foo:
def __init__(self,*args):
print(args)
def __call__(self, *args, **kwargs):
print(args)
print('__call__')
obj = Foo('init参数') # 执行 __init__
obj('haha') # 执行__call__
__dict__
类或对象中的所有属性
如果是类名.__dict__输出的是类的所有属性,包括函数
如果是对象.__dict__输出的就是对象的所有属性,即self.name之类的属性
__str__
如果一个类中定义了__str__方法,那么在打印 对象 时,默认输出该方法的返
回值。
__getitem__、__setitem__、__delitem__
class Foo(object):
def __getitem__(self, key):
print('__getitem__', key)
def __setitem__(self, key, value):
print('__setitem__', key, value)
def __delitem__(self, key):
print('__delitem__', key)
obj = Foo()
obj['k1'] # 自动触发执行 __getitem__
obj['k2'] = 'laowang' # 自动触发执行 __setitem__
del obj['k1'] # 自动触发执行 __delitem__
with和“上下文管理器”
with open("output.txt", "r") as f:
f.write("Python 之禅")
的原理:
__enter__() 方法返回资源对象,这里就是你将要打开的那个文件对象,__exit__()方法处理一些清除工作。
class File():
def __init__(self, filename, mode):
self.filename = filename
self.mode = mode
def __enter__(self):
print("entering")
self.f = open(self.filename, self.mode)
return self.f
def __exit__(self, *args):
print("will exit")
self.f.close()