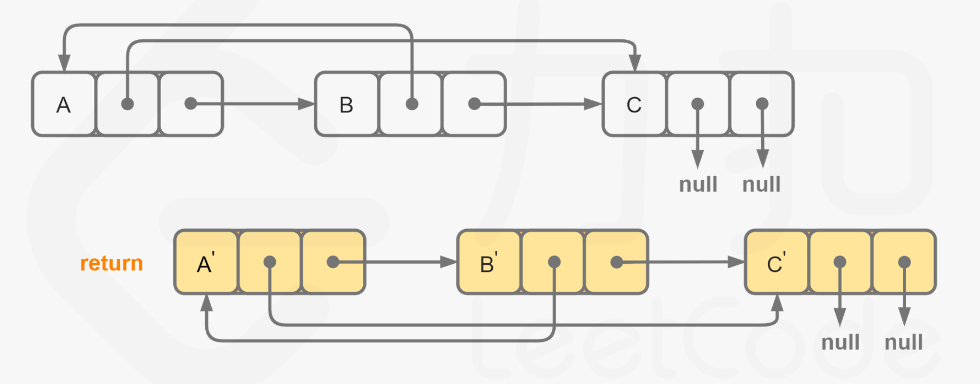
废话不多说,喊一句号子鼓励自己:程序员永不失业,程序员走向架构!本篇Blog的主题是LRU缓存结构设计,这类题目出现频率还是很高的,几乎所有大厂都常考。

当然面对这道题,首先要讲清楚LRU是干什么的
LRU定义
LRU(Least Recently Used)缓存结构是一种常见的缓存管理策略,用于在有限的缓存空间内存储最近被访问过的数据。该策略的基本思想是,当缓存空间已满并且需要插入新数据时,会优先淘汰掉最近最少被访问的数据,以便为新数据腾出空间。
LRU缓存结构的工作原理如下:
- 当某个数据被访问时,如果它已经在缓存中,那么它会被标记为最近被访问的数据,因此它会被移到缓存的队列头部(或者链表的头部)。
- 当缓存空间已满并且需要插入新数据时,会淘汰掉队列尾部(或链表末尾)的数据,因为这些数据是最近最少被访问的。
- 每次访问缓存中的数据,都会导致该数据被移到队列头部,以反映其最近被访问的状态。
实现LRU缓存结构可以使用多种数据结构,包括链表、双向链表和哈希表。链表用于维护数据访问的顺序,哈希表用于快速查找特定的数据。常见的实现方式是使用一个双向链表和一个哈希表,其中哈希表的键是数据的键,值是指向链表节点的指针。这样,可以通过哈希表快速定位数据,并通过链表维护数据的访问顺序。
总之,LRU缓存结构是一种用于管理缓存的策略,确保缓存中的数据是最近被访问过的数据,从而提高访问效率。
LRU被称为"最近最少使用"(Least Recently Used)是因为该缓存替换策略的核心思想是淘汰最近最少被使用的数据。在LRU策略中,当缓存空间已满需要淘汰数据时,系统会选择那些最近最少被访问的数据进行淘汰,以便为新的数据腾出空间。
这个名称的含义可以拆解为两个部分:
-
“最近”:这部分指的是数据的使用时间。在LRU策略中,被访问过的数据会被移动到队列的前面,即链表的头部,使其保持在最近的位置。因此,"最近"表示数据被访问的时间是近期的。
-
“最少使用”:这部分指的是数据的访问频率。在LRU中,当缓存空间已满,需要淘汰数据时,会选择那些在最近一段时间内被使用最少的数据进行淘汰。这意味着缓存系统更倾向于保留经常被访问的数据,而淘汰很少被访问的数据。
综合起来,LRU策略的名字"最近最少使用"反映了它在淘汰数据时考虑了数据的使用时间和频率,以确保缓存中保留的是最近被使用且使用频率较高的数据。
题干

输入:
["set","set","get","set","get","set","get","get","get"],[[1,1],[2,2],[1],[3,3],[2],[4,4],[1],[3],[4]],2
返回值:
["null","null","1","null","-1","null","-1","3","4"]
说明:
我们将缓存看成一个队列,最后一个参数为2代表capacity,所以
Solution s = new Solution(2);
s.set(1,1); //将(1,1)插入缓存,缓存是{"1"=1},set操作返回"null"
s.set(2,2); //将(2,2)插入缓存,缓存是{"2"=2,"1"=1},set操作返回"null"
output=s.get(1);// 因为get(1)操作,缓存更新,缓存是{"1"=1,"2"=2},get操作返回"1"
s.set(3,3); //将(3,3)插入缓存,缓存容量是2,故去掉某尾的key-value,缓存是{"3"=3,"1"=1},set操作返回"null"
output=s.get(2);// 因为get(2)操作,不存在对应的key,故get操作返回"-1"
s.set(4,4); //将(4,4)插入缓存,缓存容量是2,故去掉某尾的key-value,缓存是{"4"=4,"3"=3},set操作返回"null"
output=s.get(1);// 因为get(1)操作,不存在对应的key,故get操作返回"-1"
output=s.get(3);//因为get(3)操作,缓存更新,缓存是{"3"=3,"4"=4},get操作返回"3"
output=s.get(4);//因为get(4)操作,缓存更新,缓存是{"4"=4,"3"=3},get操作返回"4"
解题思路
使用双向链表+哈希表的方式解决该题。这是因为:于是我们可以想到数据结构的组合:
- 访问O(1)很容易想到了哈希表
- 插入O(1)的数据结构有很多,但是如果访问到了这个地方再选择插入,且超出长度要在O(1)之内删除,我们可以想到用链表,可以用哈希表的key值对应链表的节点,完成直接访问。
- 我们还需要把每次访问的key值节点加入链表头,同时删掉链表尾,所以选择双向链表,便于删除与移动。
这里顺便再补充一下哈希表和双向链表的一些背景知识。

代码实现
Java代码实现如下,分为三部分:
- 定义双向链表、虚拟头节点、虚拟尾节点、哈希表、哈希容量、LRU容量
- 初始化双向链表结构
- 编写get方法和set方法,明确需要的两个辅助函数:移动到头部【更新频率】和删除尾节点【缩小容量】、
- 编写辅助函数,明确用到的基本数据操作:插入元素到指定位置和删除元素
按照这样的方式分层的去写代码
import java.util.*;
public class Solution {
// 1 定义双向链表结构:构建一个双向链表的类,记录key值与val值,同时一前一后两个指针
static class DLinkedNode {
// 链表的data
int key;
int val;
// 前驱节点
DLinkedNode pre;
// 后继节点
DLinkedNode next;
// 初始化链表节点
public DLinkedNode () {
}
public DLinkedNode (int key, int val) {
this.key = key;
this.val = val;
}
}
// 2 定义哈希表:用哈希表存储key和链表节点,这样可以根据key在哈希表中直接锁定链表节点,从而实现链表中到O(1)时间访问链表任意节点
private Map<Integer, DLinkedNode> map = new HashMap<>();
// LRU存储元素数量
private int size;
// LRU容量
private int capacity;
// LRU虚拟头尾节点
private DLinkedNode dummyHead, dummyTail;
// 3 初始化LRU
public Solution(int capacity) {
// 设置链表虚拟头和虚拟尾
dummyHead = new DLinkedNode();
dummyTail = new DLinkedNode();
this.capacity = capacity;
size = 0;
dummyHead.next = dummyTail;
dummyTail.pre = dummyHead;
}
// 4 set方法:用到了moveToHead【更新频率】和removeTail【缩小容量】
public void set(int key, int value) {
// 1 查看hash表中是否存在
DLinkedNode node = map.get(key);
if (node == null) {
// 如果 key 不存在,创建一个新节点
DLinkedNode newNode = new DLinkedNode(key, value);
// 新节点添加进哈希表
map.put(key, newNode);
size++;
// 新节点添加至双向链表的头部
addNode(dummyHead, newNode);
if (size > capacity) {
// 如果超出容量,删除双向链表的尾部节点
DLinkedNode delNode = removeTail();
// 删除哈希表中对应的项
map.remove(delNode.key);
size--;
}
} else {
node.val = value;
moveToHead(node);
}
}
// 5 get方法: 用到了moveToHead【更新频率】
public int get(int key) {
// 1 找到节点位置
DLinkedNode node = map.get(key);
if (node == null) {
return -1;
}
// 2 移动节点到最近访问
moveToHead(node);
return node.val;
}
// 辅助方法:将某个节点移动到头节点【更新频率】
private void moveToHead(DLinkedNode node) {
removeNode(node);
addNode(this.dummyHead, node);
}
// 辅助方法: 删除尾节点,当前节点插入到虚拟头节点后边最新一位【缩小容量】
private DLinkedNode removeTail() {
// 待删除节点
DLinkedNode delNode = this.dummyTail.pre;
removeNode(delNode);
return delNode;
}
// 基本操作:插入某个节点后面
private void addNode(DLinkedNode preNode, DLinkedNode node) {
node.next = preNode.next;
node.next.pre = node;
node.pre = preNode;
preNode.next = node;
}
// 基本操作:删除任意位置节点
private void removeNode(DLinkedNode node) {
node.pre.next = node.next;
node.next.pre = node.pre;
}
}
/**
* Your Solution object will be instantiated and called as such:
* Solution solution = new Solution(capacity);
* int output = solution.get(key);
* solution.set(key,value);
*/
复杂度分析
使用双向链表和哈希表实现LRU缓存可以使查找和删除操作都在O(1)时间内完成,这是因为双向链表支持快速的插入和删除操作,而哈希表支持快速的查找操作。
空间复杂度:
- 双向链表:双向链表存储了实际的缓存数据项,因此空间复杂度是O(n),其中n是缓存的最大容量。
- 哈希表:哈希表存储了键和指向链表节点的指针,因此空间复杂度也是O(n),其中n是缓存的最大容量。
综合起来,使用双向链表和哈希表实现LRU缓存的空间复杂度为O(n)。
时间复杂度:
- 插入操作:当向LRU缓存中插入一个新的数据项时,需要在双向链表的头部插入节点,并在哈希表中插入键和指针。这两个操作的时间复杂度都是O(1)。
- 访问操作:当访问一个数据项时,需要将该节点移动到双向链表的头部,这涉及到双向链表节点的删除和插入操作,以及哈希表的更新操作,所有这些操作的时间复杂度都是O(1)。
- 删除操作:当删除最久未使用的数据项时,需要从双向链表尾部删除节点,并在哈希表中删除对应的键和指针。这两个操作的时间复杂度都是O(1)。
- 哈希表查找操作:通过哈希表查找某个键对应的链表节点的指针,时间复杂度是O(1)。
综合起来,使用双向链表和哈希表实现LRU缓存的各项操作的时间复杂度都是O(1)。
拓展:哈希表和双向链表
补充一些哈希表和双向链表知识
哈希表
哈希表(Hash Table),也被称为散列表,是一种用于存储键值对(key-value pairs)的数据结构,它允许快速插入、删除和查找操作。哈希表通过使用哈希函数将键映射到数组中的索引位置,从而实现快速的数据存取。

以下是哈希表的定义和基本特点:
-
定义: 哈希表是由一组键值对构成的数据结构,其中每个键是唯一的,而且每个键对应一个值。哈希表通过哈希函数将键转换为数组中的索引,从而将键值对存储在特定的位置上。
-
哈希函数: 哈希函数是一个将任意大小的输入(如键)映射为固定大小输出(如数组索引)的函数。好的哈希函数应该具有以下特点:快速计算、分布均匀、尽可能避免碰撞(多个键映射到同一个索引位置)。
-
数组: 哈希表的底层通常是一个数组,数组的每个位置被称为“桶”(bucket)。每个桶可以存储一个键值对,或者更复杂的情况下,它可能存储一个链表、树或其他数据结构,用于处理碰撞。
-
碰撞处理: 由于哈希函数可能会将不同的键映射到相同的索引位置,所以碰撞(collision)是不可避免的。哈希表需要一种策略来处理碰撞,常见的策略包括链地址法(使用链表解决碰撞)、开放寻址法(线性探测、二次探测等)、双散列等。
-
基本操作: 哈希表的基本操作包括插入(将键值对插入表中)、删除(从表中删除一个键值对)、查找(根据键查找对应的值)等。
哈希表的优势在于它提供了平均时间复杂度为 O(1) 的插入、删除和查找操作。因此哈希表常用来统计频率、快速检验某个元素是否出现过等
时间复杂度
哈希表的插入、删除和查找操作的平均时间复杂度通常被认为是O(1),即常数时间。但需要注意的是,这个平均情况下的时间复杂度是在哈希函数能够将键均匀地映射到桶(数组位置)的情况下成立的。以下是具体操作的时间复杂度:
-
插入操作(Average Case): 在平均情况下,插入一个键值对到哈希表中的时间复杂度是O(1)。这是因为好的哈希函数能够在常数时间内找到对应的桶,只需简单地将键值对放入桶中。
-
删除操作(Average Case): 在平均情况下,删除一个键值对的时间复杂度也是O(1)。与插入类似,哈希函数可以快速定位到键所对应的桶,然后删除相应的键值对。
-
查找操作(Average Case): 在平均情况下,查找一个键对应的值的时间复杂度也是O(1)。通过哈希函数,可以快速找到键所在的桶,并在常数时间内获取到值。
然而,需要注意以下几点:
-
最坏情况: 在一些情况下,哈希表的性能可能不如平均情况好。例如,如果哈希函数产生了大量的冲突,导致多个键映射到同一个桶,那么查找、插入和删除操作的时间复杂度可能会接近O(n),其中n是哈希表中的元素数量。
-
哈希冲突: 哈希表的性能关键在于避免哈希冲突,即多个键映射到同一个桶。不同的碰撞解决策略会影响到哈希表的性能。
-
哈希函数的选择: 好的哈希函数在尽量均匀地将键映射到桶,从而减少冲突,提高平均性能。
总结起来,哈希表的平均时间复杂度为O(1),但在特定情况下,性能可能会受到哈希冲突等因素的影响。
空间复杂度
哈希表的插入、删除和查找操作的空间复杂度通常被认为是O(n),其中n是哈希表中存储的键值对数量。然而,实际的空间复杂度可能会受到哈希函数的质量、冲突处理策略以及底层数据结构的影响。
以下是哈希表各操作的空间复杂度:
-
插入操作: 插入操作的空间复杂度是O(1),因为只需为新的键值对分配内存空间,不考虑已有的键值对数量。但是,如果哈希表中的负载因子过高,可能需要重新调整哈希表的大小(rehashing),这可能会引起更多的内存分配和复制操作。
-
删除操作: 删除操作的空间复杂度是O(1),类似于插入操作,只需释放被删除节点的内存空间。
-
查找操作: 查找操作的空间复杂度是O(1),因为在查找时不会引入新的内存分配。
然而,需要注意以下几点:
-
额外空间: 虽然单次操作的空间复杂度是O(1),但是哈希表本身需要占用一定的内存空间来存储桶(数组)、指针和元数据等。
-
负载因子: 负载因子是哈希表中实际存储的键值对数量与桶数量之间的比率。当负载因子过高时,哈希表容易发生冲突,可能需要进行调整大小。这可能会导致更多的内存分配和复制操作,增加空间复杂度。
-
调整大小: 哈希表在插入过程中可能需要动态调整大小,以保持较低的负载因子。这可能会涉及创建新的哈希表,将现有数据复制到新表中,然后释放旧表。这个过程可能导致短时间内的额外内存使用,影响空间复杂度。
综上所述,哈希表的单次插入、删除和查找操作通常具有O(1)的空间复杂度,但整体空间复杂度可能会受到负载因子、调整大小和底层数据结构等因素的影响。
双向链表
双向链表(Doubly Linked List)是一种常见的线性数据结构,它与普通链表(单向链表)不同之处在于,每个节点都包含两个指针,一个指向前一个节点,一个指向后一个节点,从而实现双向的连接。
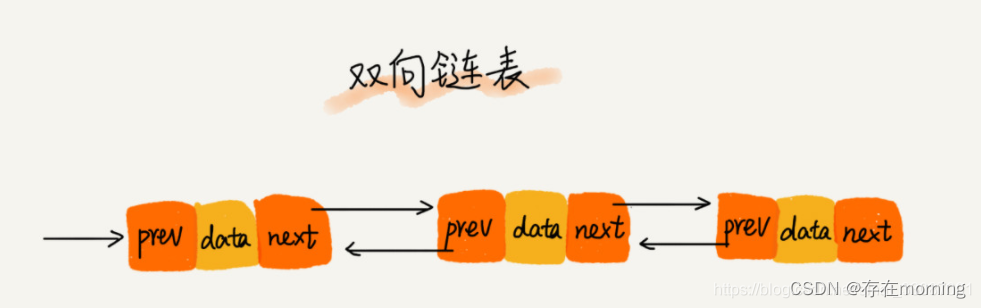
以下是双向链表的定义和特点:
-
定义: 双向链表由多个节点组成,每个节点都包含三个部分:一个数据域用于存储数据,一个指向前一个节点的指针(通常称为
prev指针或previous指针),一个指向后一个节点的指针(通常称为next指针或next域)。 -
双向连接: 每个节点都与其前一个节点和后一个节点相连接,形成一个双向链表。这使得在双向链表中,你可以从任意节点开始,向前或向后遍历链表。
-
插入和删除操作: 双向链表相对于单向链表的一个优势在于插入和删除操作的效率更高。在双向链表中,插入和删除一个节点时,只需改变相邻节点的指针,不需要像单向链表那样遍历到前一个节点。
-
操作灵活性: 由于双向链表允许双向遍历,它在某些场景下更灵活。例如,可以从链表尾部向前遍历,这在某些问题中是有用的。
-
内存消耗: 相对于单向链表,双向链表需要额外的指针来存储前后节点的引用,因此在内存上会占用更多的空间。
-
双向链表与迭代器: 双向链表的双向遍历性质使得它在实现迭代器(Iterator)等数据结构时非常有用,因为迭代器可以轻松地向前和向后移动。
总之,双向链表是一种具有双向连接能力的线性数据结构,它在插入、删除和遍历操作上有着一些优势,但也会占用更多的内存空间。它在一些特定的应用场景中非常有用。
时间复杂度
双向链表(Doubly Linked List)的插入、删除和查找操作的时间复杂度取决于操作的位置。以下是双向链表各操作的时间复杂度:
-
插入操作:
- 在链表开头插入:O(1) - 无论链表多大,只需将新节点插入到头部并更新相应的指针。
- 在链表结尾插入:O(1) - 类似于在开头插入,将新节点插入到尾部并更新指针。
- 在给定位置插入:O(n) - 如果需要插入到链表的中间位置,则需要先找到目标位置,这可能需要遍历链表。
-
删除操作:
- 删除头节点:O(1) - 直接更新头指针。
- 删除尾节点:O(1) - 直接更新尾指针。
- 删除给定位置的节点:O(n) - 需要先找到目标节点,这可能需要遍历链表。
-
查找操作:
- 根据值查找节点:O(n) - 需要遍历链表以找到匹配的节点。
- 根据索引查找节点:O(n) - 需要从链表的头部或尾部开始遍历,以找到指定索引的节点。
需要注意的是,上述时间复杂度是针对双向链表的平均和最坏情况。在特定情况下,如删除或插入开头或结尾时,双向链表的操作是高效的。但是在查找和在中间位置插入或删除时,双向链表需要遍历一部分或全部节点,因此这些操作会相对较慢。
总结起来,双向链表在插入和删除开头、结尾的情况下具有常数时间复杂度,但在查找和中间位置的插入/删除操作上具有线性时间复杂度。这使得它在一些情况下很有用,但在其他情况下可能不如其他数据结构(如哈希表或平衡树)高效。
空间复杂度
双向链表的插入、删除和查找操作的空间复杂度主要取决于链表中节点的数量,通常是O(n),其中n是链表中的节点数。以下是双向链表各操作的空间复杂度:
-
插入操作: 插入操作的空间复杂度是O(1),因为只需为新节点分配内存空间,并更新相应的指针。插入操作不涉及额外的内存分配,而是将新节点添加到链表中。
-
删除操作: 删除操作的空间复杂度也是O(1),类似于插入操作,只需释放被删除节点的内存空间,并更新相邻节点的指针。
-
查找操作: 查找操作的空间复杂度是O(1),因为在查找时不会引入新的内存分配。
需要注意以下几点:
-
额外空间: 除了节点本身所需的内存空间,双向链表需要一些额外的内存来存储指向前后节点的指针,这会占用一些额外的空间。
-
节点数量: 插入、删除和查找操作的空间复杂度不会随链表中节点数量的增加而增加。这使得双向链表在需要频繁插入和删除操作的情况下比较有优势。
-
碰撞处理: 虽然不像哈希表那样会涉及哈希函数和冲突处理,但在某些情况下,双向链表可能需要额外的内存空间来处理一些特殊情况,例如特定的节点操作或额外的指针。
总结起来,双向链表的插入、删除和查找操作通常具有O(1)的空间复杂度,但链表本身需要一些额外的内存空间来存储节点间的指针。在需要频繁插入和删除操作的情况下,双向链表可能比其他数据结构更适用。