1、什么是ETL?
答:ETL(Extract-Transform-Load的缩写,即数据抽取、转换、装载的过程),对于企业或行业应用来说,我们经常会遇到各种数据的处理,转换,迁移,所以了解并掌握一种etl工具的使用,必不可少,这里我要学习的ETL工具是Kettle!
2、什么是Kettle?
答:Kettle是一款国外开源的ETL工具,纯java编写,可以在Window、Linux、Unix上运行,绿色无需安装,数据抽取高效稳定。
Kettle 中文名称叫水壶,该项目的主程序员MATT 希望把各种数据放到一个壶里,然后以一种指定的格式流出。
Kettle这个ETL工具集,它允许你管理来自不同数据库的数据,通过提供一个图形化的用户环境来描述你想做什么,而不是你想怎么做。
Kettle中有两种脚本文件,transformation和job,transformation完成针对数据的基础转换,job则完成整个工作流的控制。
Kettle(现在已经更名为PDI,Pentaho Data Integration-Pentaho数据集成)。
3、Kettle的结构。
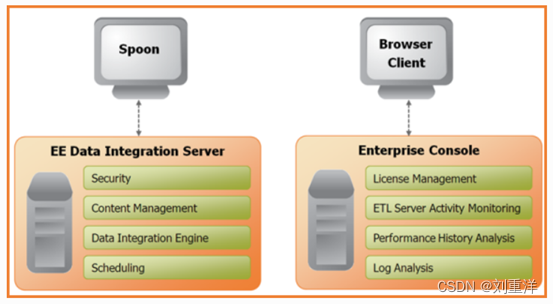
4、Kettle的结构-Spoon和Data Integration Server。
答:Spoon是构建ETL Jobs和Transformations的工具。Spoon以拖拽的方式图形化设计,能够通过spoon调用专用的数据集成引擎或者集群。
Data Integration Server是一个专用的ETL Server,它的主要功能有:

5、Kettle的结构-Enterprise Console。
答:Enterprise Console(企业控制台)提供了一个小型的客户端,用于管理Pentaho Data Integration企业版的部署。包括企业版本的证书管理、监控和控制远程Pentaho Data Integration服务器上的活动、分析已登记的作业和转换的动态绩效。
6、kettle的核心组件。

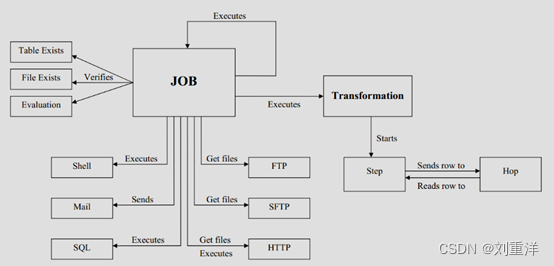
7、Kettle概念模型。Kettle的执行分为两个层次:Job(作业)和Transformation(转换)。
8、Kettle的下载。
Kettle官方网址:https://community.hitachivantara.com/s/article/data-integration-kettle,不建议官网下载,贼慢,压缩包一个G左右的。
Kettle的百度网盘地址(个人分享):
7.1
链接:https://pan.baidu.com/s/1Q7lCE-xbljl-afc0zb9V8Q?pwd=k9yo
提取码:k9yo
8.0
链接:https://pan.baidu.com/s/10QU6b4pVkVEskIKSVfhcyw?pwd=slsp
提取码:slsp
8.3
链接:https://pan.baidu.com/s/1r0gvuFJme5jKxwNQ3FWynA?pwd=3yoo
提取码:3yoo
8.2
链接:https://pan.baidu.com/s/1XArURfTi6eRU1t4FH2wyPg?pwd=234a
提取码:234a
9.1
链接:https://pan.baidu.com/s/1ipOlSex94jYLWrPDNCZ3Ow?pwd=5iku
提取码:5iku
9、 Kettle的压缩包下载完毕,解压缩即可。Kettle的目录文件,如下所示:



10、 Kettle的部署,Kettle下载以后需要配置一下环境变量,因为Kettle是纯Java开发的哦!
由于Kettle是Java语言开发的,该软件的允许需要Java运行环境的依赖。需要先安装JDK,准备好Java软件的运行环境。安装jdk1.8版本即可,配置环境变量,这些自己百度一下就行了,不啰嗦了。在Window10环境下,双击Spoon.bat即可运行了。
11、Kettle界面简介。
12、Kettle实现,把数据从CSV文件复制到Excel文件。
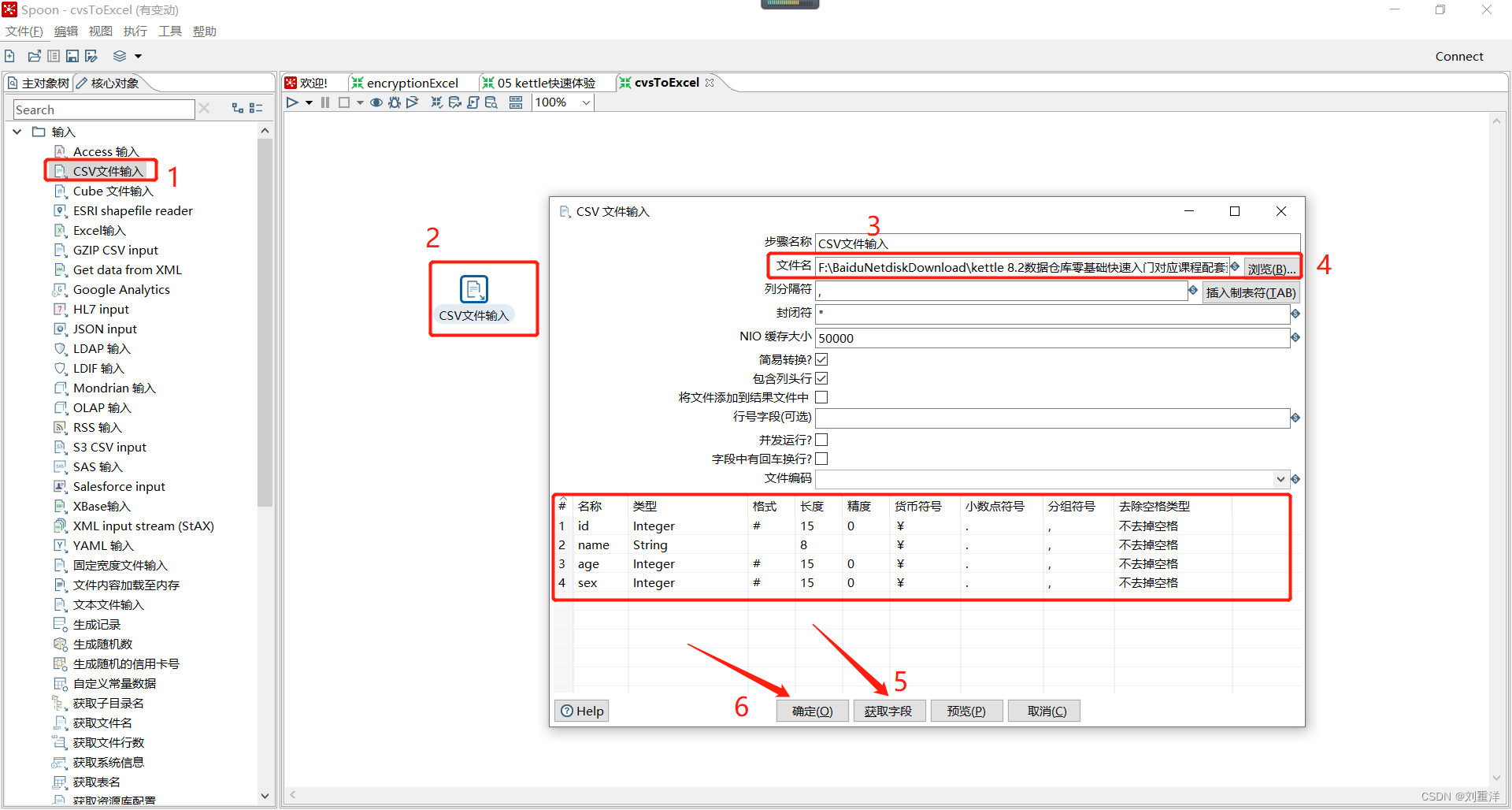
首先,创建一个转换,找到核心对象,找到输入里面的CVS文件输入图元,拖拽到工作区域,双击CVS文件输入。
可以修改步骤的名称,点击浏览,选择到CVS文件,其他参数可以默认,点击获取字段,最后点击确定。
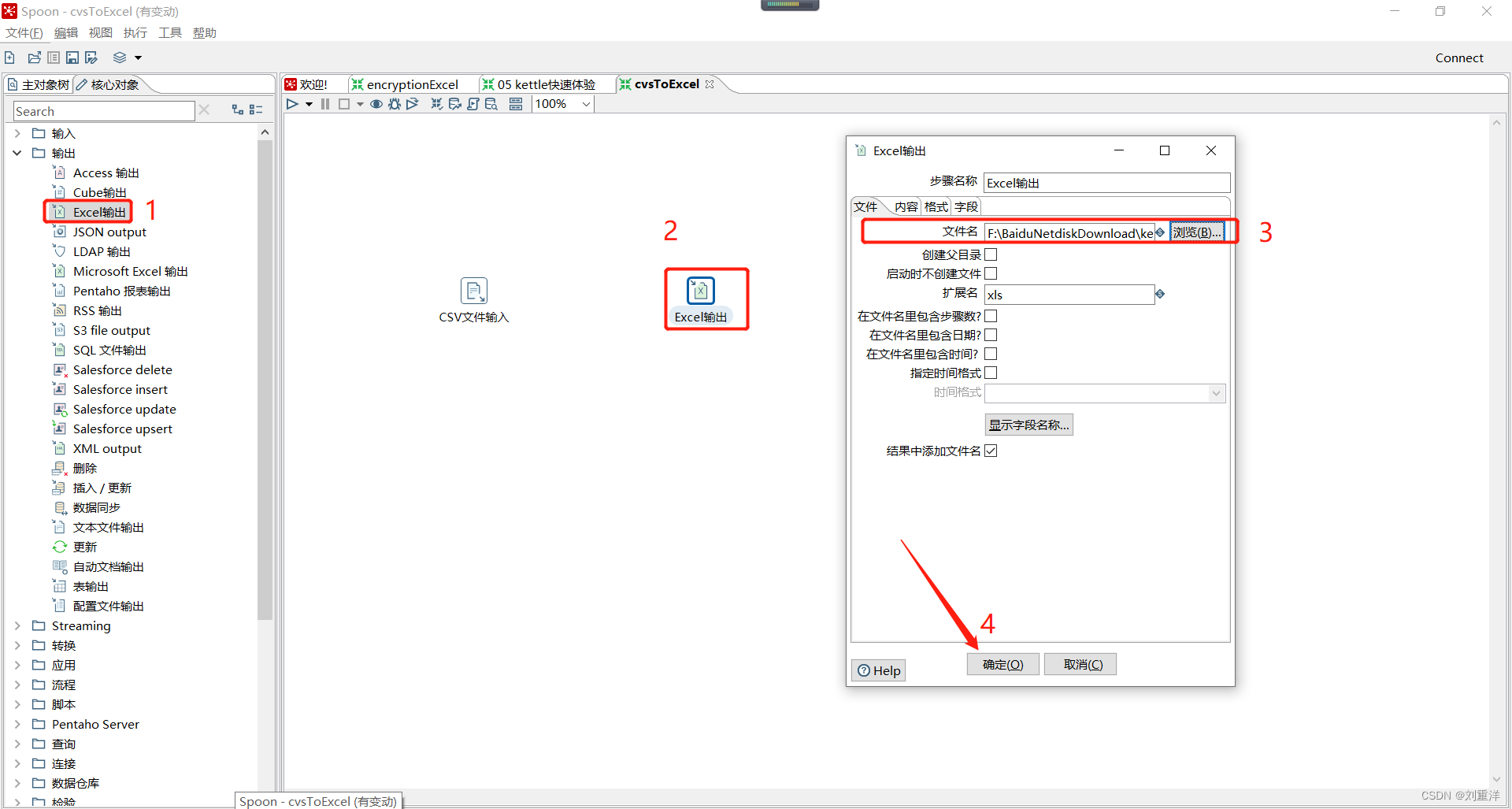
CVS文件输入配置完毕以后,可以配置Excel输出,如下所示:
此时,可以 按住shift拖动鼠标,划线,将CVS文件输入和Excel输出连到一起。
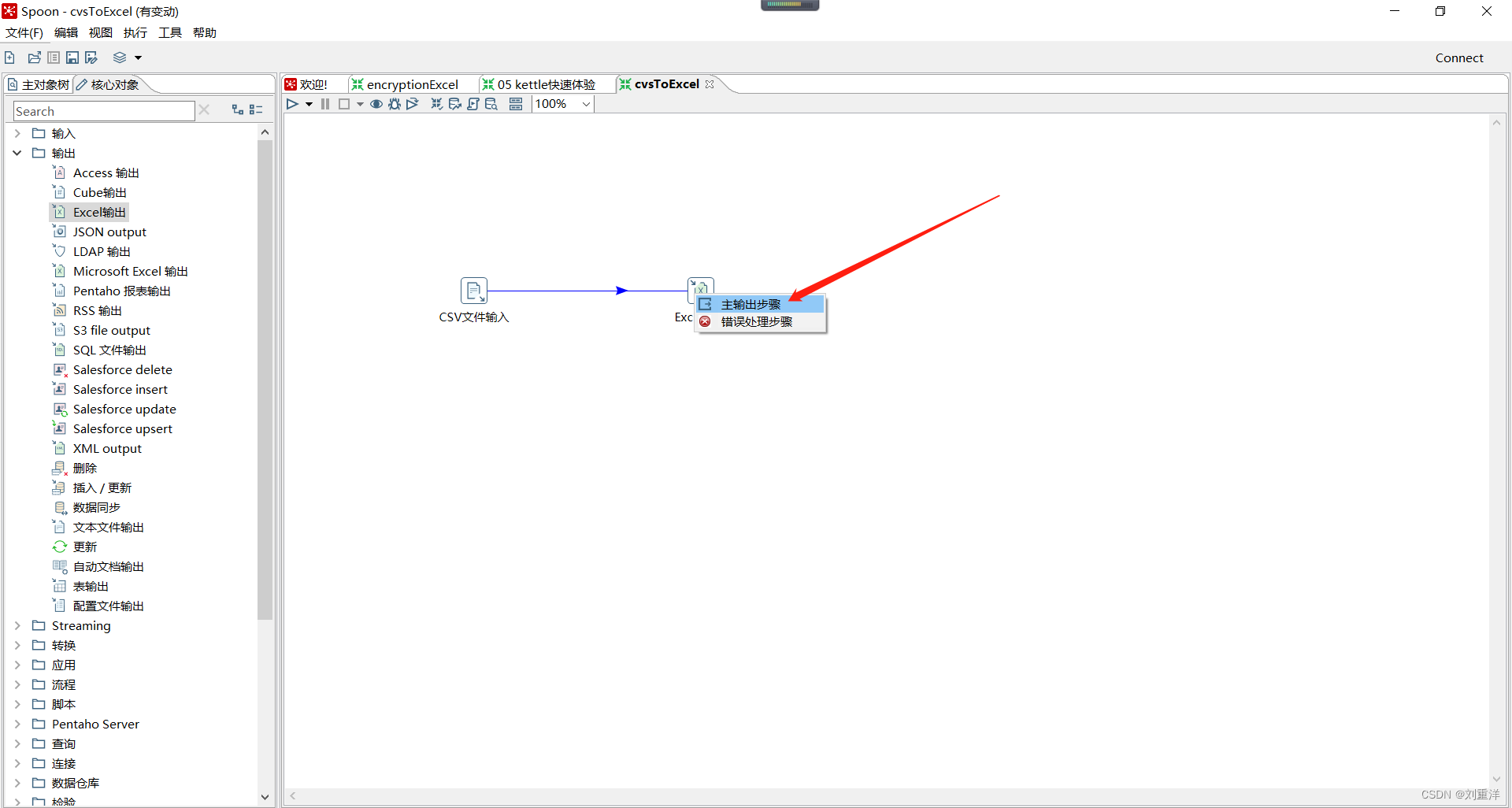
最后,点击Excel输出,选择字段,点击获取字段,将输出到Excel的字段进行映射,最后点击确定即可。
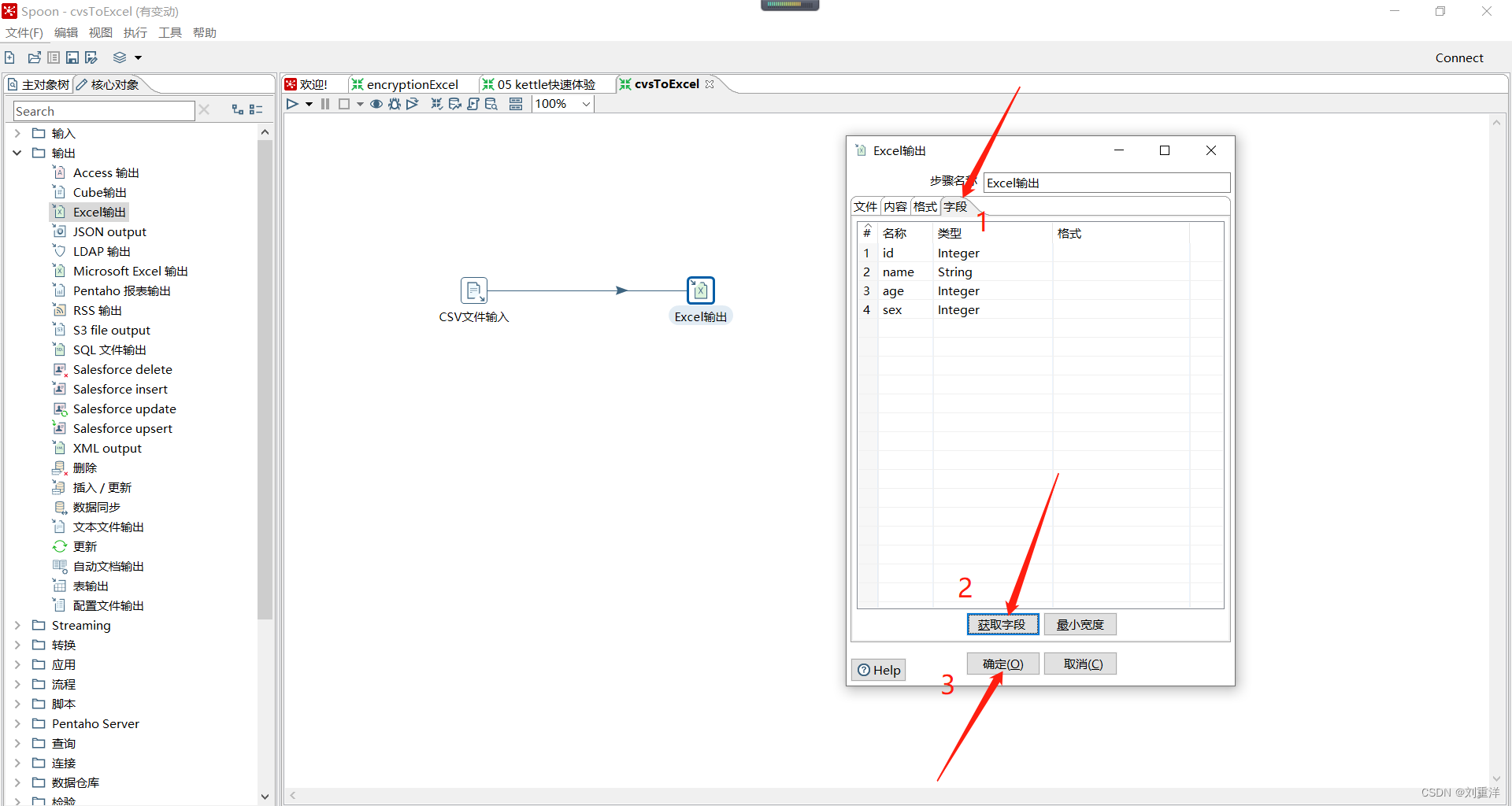
点击ctrl + s保存,然后点击启动按钮即可。
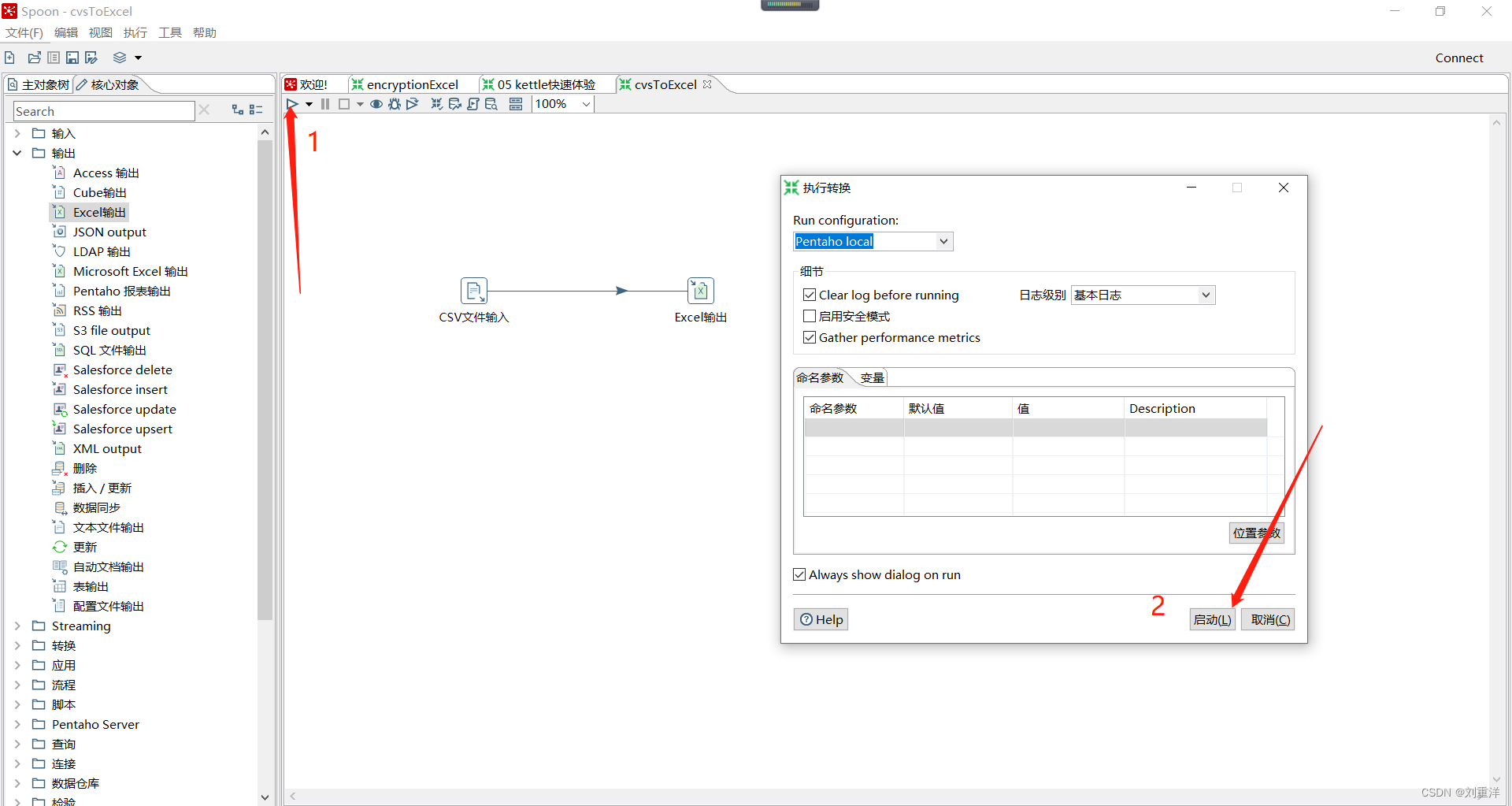
13 、Kettle的执行结果。
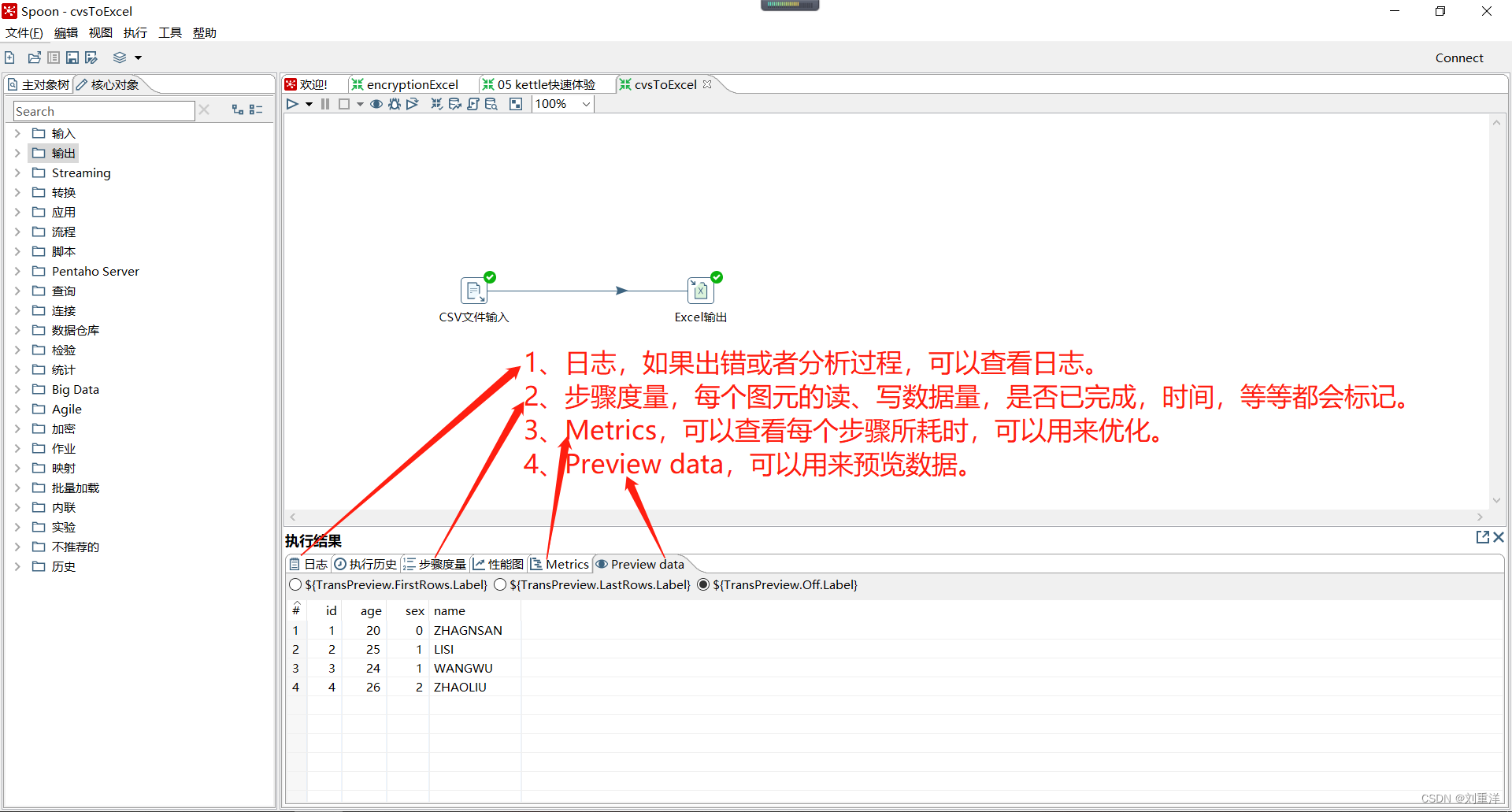
14、Kettle,可以被称为可视化编程。
1)、Kettle可以被归类为可视化编程语言(Visula Programming Languages,VPL),因为Kettle可以使用图形化的方式定义复杂的ETL程序和工作流。
2)、Kettle里的图就是转换和作业。
3)、可视化编程一直是Kettle里的核心概念,它可以让你快速构建复杂的ETL作业和减低维护工作量。它通过隐藏很多技术细节,使IT领域更贴近于商务领域。
15、Kettle里面的转换。
1)、转换(transaformation)是ETL解决方案中最主要的部分,它处理抽取、转换、加载各种对数据行的操作。
2)、转换包含一个或多个步骤(step),如读取文件、过滤数据行、数据清洗或将数据加载到数据库。
3)、转换里的步骤通过跳(hop)来连接,跳定义一个单向通道,允许数据从一个步骤向另一个步骤流动。
4)、在Kettle里,数据的单位是行,数据流就是数据行从一个步骤到另一个步骤的移动。
5)、数据流有的时候也被称之为记录流。
16、Kettle里面的,Step步骤(控件)是转换里的基本的组成部分。
一个步骤有如下几个关键特性:
1)、步骤需要有一个名字,这个名字在转换范围内唯一。
2)、每个步骤都会读、写数据行(唯一例外是"生成记录"步骤,该步骤只写数据)。
3)、步骤将数据写到与之相连的一个或多个输出跳,再传送到跳的另一端的步骤。
4)、大多数的步骤都可以有多个输出跳。一个步骤的数据发送可以被被设置为分发和复制,分发是目标步骤轮流接收记录,复制是所有的记录被同时发送到所有的目标步骤。
17、Kettle里面的,Hop跳(即图元之间的连线)。
1)、跳就是步骤之间带箭头的连线,跳定义了步骤之间的数据通路。
2)、跳实际上是两个步骤之间的被称之为行集的数据行缓存(行集的大小可以在转换的设置里定义)。
3)、当行集满了,向行集写数据的步骤将停止写入,直到行集里又有了空间。
4)、当行集空了,从行集读取数据的步骤停止读取,直到行集里又有可读的数据行。
18、Kettle里面的,数据行-数据类型。
数据以数据行的形式沿着步骤移动。一个数据行是零到多个字段的集合,字段包含下面几种数据类型。
1)、String:字符类型数据
2)、Number:双精度浮点数。
3)、Integer:带符号长整型(64位)。
4)、BigNumber:任意精度数据。
5)、Date:带毫秒精度的日期时间值。
6)、Boolean:取值为true和false的布尔值。
7)、Binary:二进制字段可以包含图像、声音、视频及其他类型的二进制数据。
19、Kettle里面的,数据行-元数据。
每个步骤在输出数据行时都有对字段的描述,这种描述就是数据行的元数据。通常包含下面一些信息。
1)、名称:行里的字段名应用是唯一的。
2)、数据类型:字段的数据类型。
3)、格式:数据显示的方式,如Integer的#、0.00。
4)、长度:字符串的长度或者BigNumber类型的长度。
5)、精度:BigNumber数据类型的十进制精度。
6)、货币符号:¥。
7)、小数点符号:十进制数据的小数点格式。不同文化背景下小数点符号是不同的,一般是点(.)或逗号(,)。
8)、分组符号:数值类型数据的分组符号,不同文化背景下数字里的分组符号也是不同的,一般是点(.)或逗号(,)或单引号(’)。
20、Kettle里面的,并行概念。
跳的这种基于行集缓存的规则允许每个步骤都是由一个独立的线程运行,这样并发程度最高。这一规则也允许数据以最小消耗内存的数据流的方式来处理。在数据仓库里,我们经常要处理大量数据,所以这种并发低消耗内存的方式也是ETL工具的核心需求。
对于kettle的转换,不可能定义一个执行顺序,因为所有步骤都以并发方式执行:当转换启动后,所有步骤都同时启动,从它们的输入跳中读取数据,并把处理过的数据写到输入跳,直到输入跳里不再有数据,就中止步骤的运行。当所有的步骤都中止了,整个转换就中止了。 (要与数据流向区分开)
如果你想要一个任务沿着指定的顺序执行,那么就要使用后面所讲的"作业"!