概念
何为生产消费者模型?在设计的角度上看,普通的进程间通信,可以认为发送信息与接收信息的人是同步的。
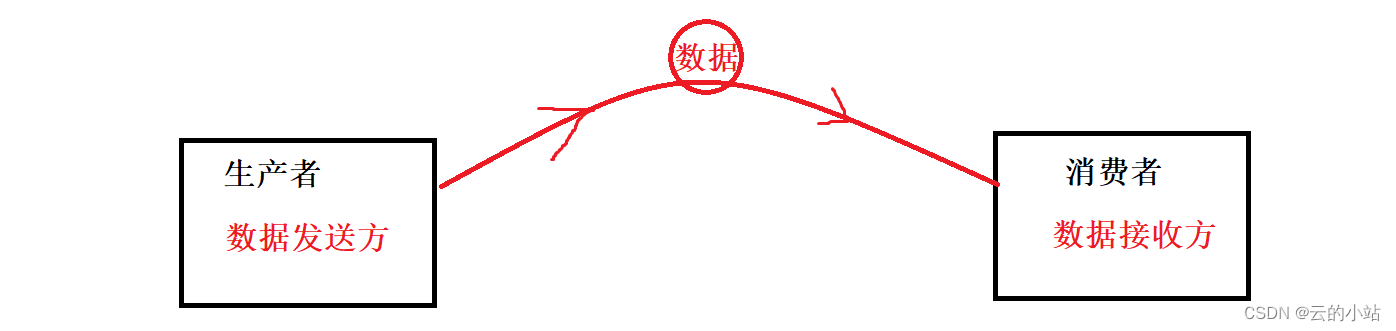
生产者发信号消费者立刻就会收到。这样的做法虽然提高了效率,但是如果生产者和消费者一旦有一方出现问题就是影响另一方
比如:
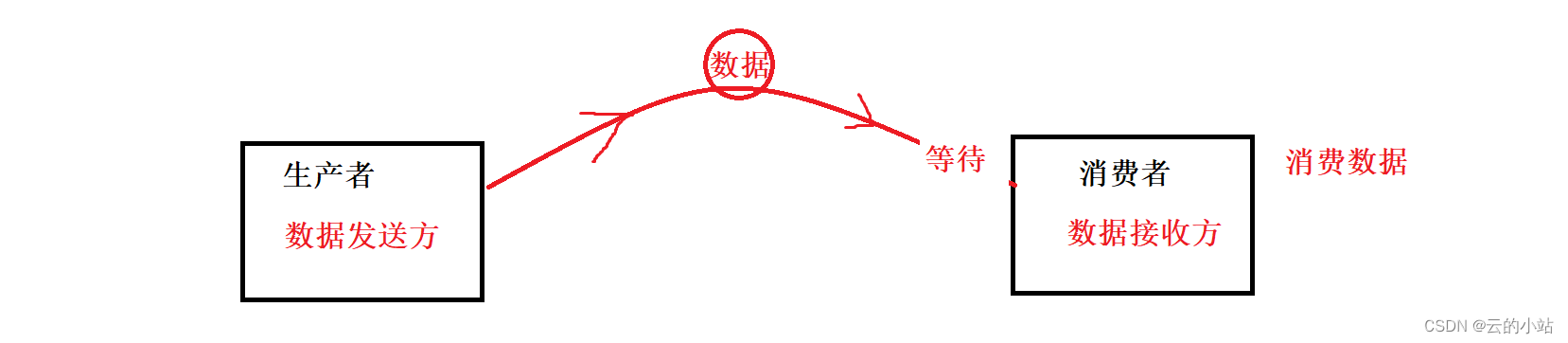
消费者消费数据,生产者也无法运行。必须等等消费者对上次数据处理完毕才并取走数据。

生产者生产数据消费者就必须等待生产者生产完毕。
所以我们需要中间临时区域。
如果生产者生产快了,就间数据放入中间缓冲区,再去运行生产者后续代码。
如果消费者快了,直接去缓冲区取数据,不用等待生产者发送数据。
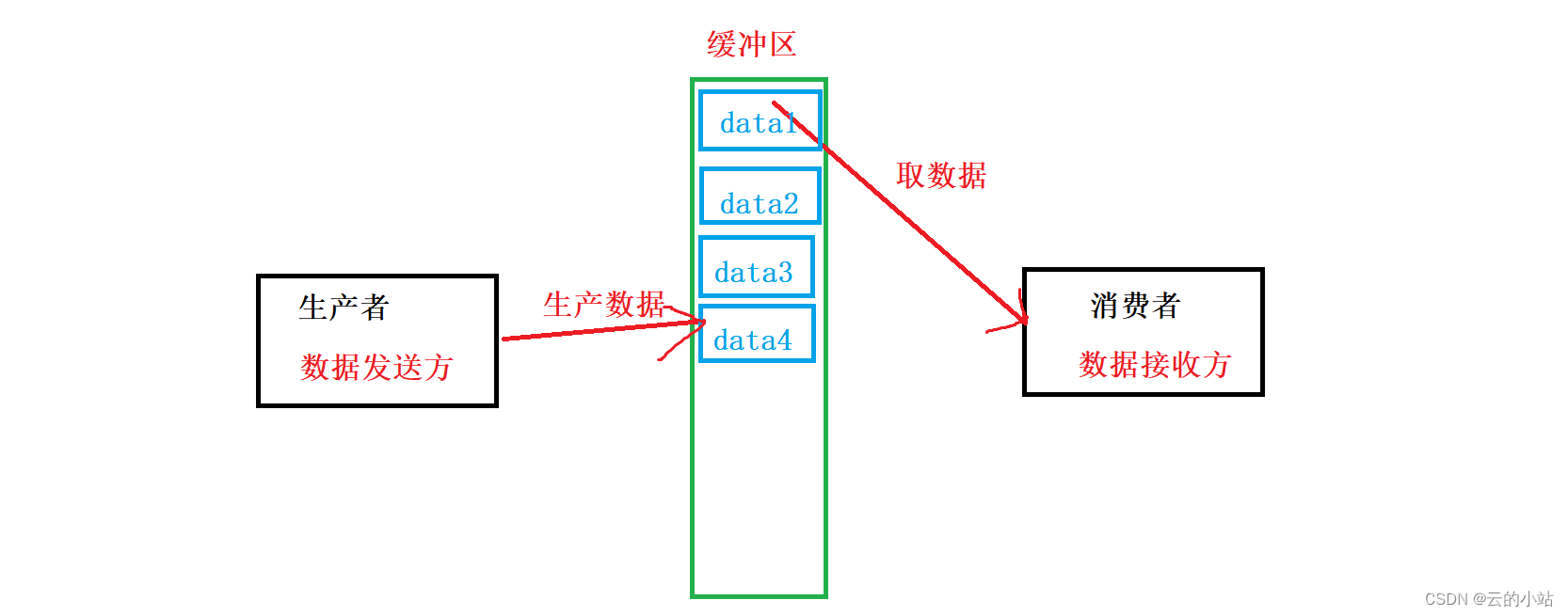
虽然多了中间层,需要数据2次转移,但是极大的好处就是,生产者不必等待消费者取数据,消费者也不必等待生产者发送数据,只有在缓冲区为空的时候消费者需要先让生产者生产数据是的串行,其他情况下都是生产者消费者是并发执行。
如果多生产者消费者的出现
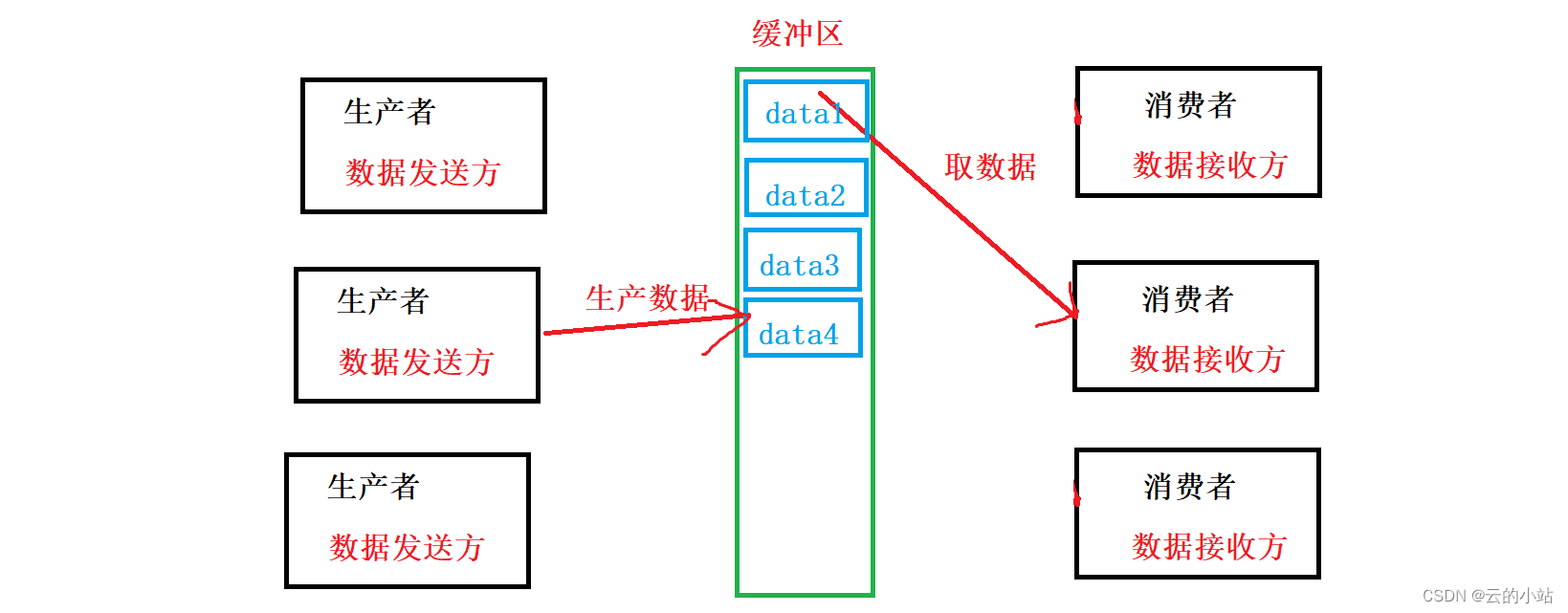
更是极大优化了程序的效率。
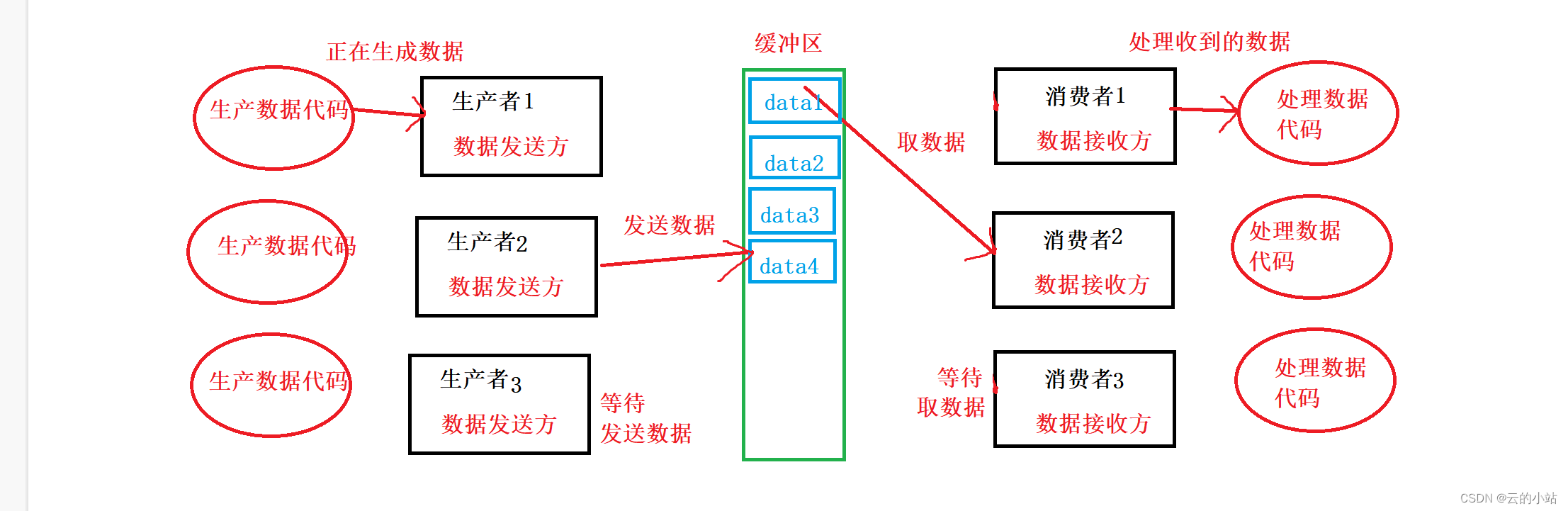
生产者1:正在执行生产数据代码
生产者2:获得“生产锁”发送数据到缓冲区
生产者3:未争夺到“生产锁”等待下次争锁,发送数据
消费者1:处理接收到的数据
消费者2:获得“消费锁”取缓冲区一份数据
消费者3:未争夺到“消费锁”等待下次争锁,发送数据
各干各的,只有在同时生产或同时取数据的过程中,同类别的角色才会发送互斥效益。
只有在数据未空或者满的情况下,生产者和消费者才会发送同步情况。
阻塞队列
阻塞队列代码:一把锁,因为他的缓冲区大小不是固定的,消费者生产数据会使得缓冲区大小减小,生产者相反,所以在阻塞队列中我们只能使用一把锁,必须也得互斥。
BlockQueue.hpp
#include <iostream>
#include <pthread.h>
#include <cstring>
#include <cstdio>
#include <unistd.h>
#include <string>
#include <signal.h>
#include <fcntl.h>
#include <queue>
using namespace std;
/
//创建自动锁->自动上锁,自动释放锁
class Auto_lock
{
public:
Auto_lock(pthread_mutex_t* reMax)
:_AMax(reMax)
{
pthread_mutex_lock(_AMax);
}
~Auto_lock()
{
pthread_mutex_unlock(_AMax);
}
private:
pthread_mutex_t* _AMax;
};
/
//设置等待与唤醒函数
void wait(pthread_cond_t*cond,pthread_mutex_t* mtx)
{
pthread_cond_wait(cond,mtx);
}
void weekup(pthread_cond_t*cond)
{
pthread_cond_signal(cond);
}
/
//建立临界资源与临界区代码
template <class Ty>
class BQueue
{
//检测bq空与满
bool empty()
{
return _bq.empty();
}
bool full()
{
return _bq.size()==_capacity;
}
public:
BQueue(size_t capacity=5)
: _capacity(capacity)
,_Full(new pthread_cond_t)
,_Empty(new pthread_cond_t)
,_mtx(new pthread_mutex_t)
{
//初始化条件变量
pthread_mutex_init(_mtx,nullptr);
pthread_cond_init(_Empty,nullptr);
pthread_cond_init(_Full,nullptr);
}
void push(const Ty&x)
{
{ //放入数据
Auto_lock am(_mtx);
while(full()) wait(_Full,_mtx);
_bq.push(x);
weekup(_Empty);
}
}
void pop(Ty*x)
{
{ //取数据
Auto_lock am(_mtx);
while(empty()) wait(_Empty,_mtx);
*x=_bq.front();
_bq.pop();
weekup(_Full);
}
}
~BQueue()
{
pthread_mutex_destroy(_mtx);
pthread_cond_destroy(_Empty);
pthread_cond_destroy(_Full);
delete _mtx;
delete _Empty;
delete _Full;
}
private:
queue<Ty> _bq;
size_t _capacity;
pthread_cond_t* _Full;
pthread_cond_t* _Empty;
pthread_mutex_t* _mtx;
pthread_mutex_t* _mtx;
};
/ConProd.cc
#include"teskblock.hpp"
#include"BlockQueue.hpp"
func_t Tesks[]={Task_1,Task_2,Task_3,Task_4};
/
//生产者线程运行
void*productor(void*ags)
{
pthread_detach(pthread_self());
BQueue<func_t>*bq=(BQueue<func_t>*)ags;
while(1)
{
bq->push(Tesks[rand()%4]);
cout<<" 生产者:"<<pthread_self()<<endl;
sleep(1);
}
}
/
//消费者线程运行
void*consumer(void*ags)
{
pthread_detach(pthread_self());
BQueue<func_t>*bq=(BQueue<func_t>*)ags;
while(1)
{
func_t ret;
bq->pop(&ret);
cout<<" 消费者:"<<pthread_self()<<" ";
ret();
}
}
/
int main()
{
srand((unsigned int)time(0));
BQueue<func_t> bq(5);
pthread_t c1,c2,p1,p2;
pthread_create(&c1,nullptr,consumer,(void*)&bq);
pthread_create(&c2,nullptr,consumer,(void*)&bq);
pthread_create(&p1,nullptr,productor,(void*)&bq);
pthread_create(&p2,nullptr,productor,(void*)&bq);
while(1);
}test.hpp是任务头文件,这个可以自己写
环形队列
概念为环形的缓冲区,生产区大小固定,消费者只需要在区域中放入数据,消费者也只是取数据,
减少的是有效数据与有效空间。
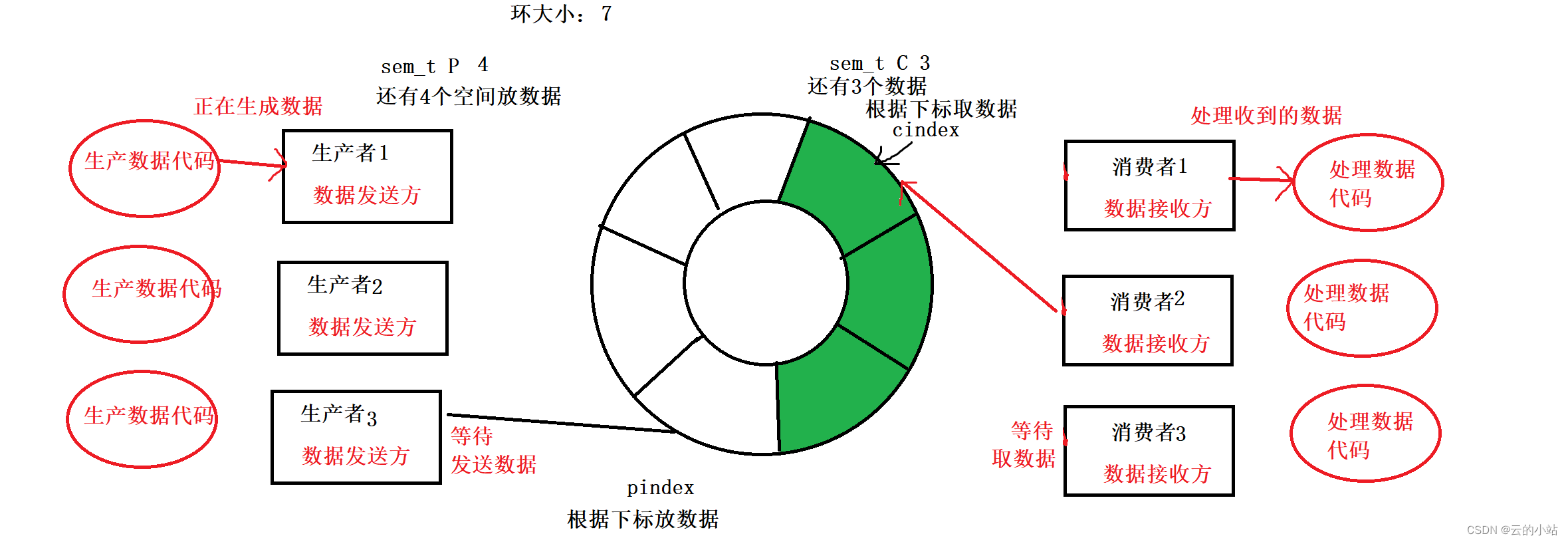
4个空间允许4个生产者线程争夺互斥锁
3个数据允许3个消费者线程争夺互斥锁
这里的生产者和消费者们争夺的都是个角色的锁,只有在空间全部放满和所有数据去完的情况下,生产者和消费者才会见面。
P信号量最多7个,C信号量最多7个,C--会让P++,P--会让C--,2种线程不会破坏环形队列的大小,保证了环形队列大小一致性,这样对生产者和消费者做了再一次的解耦操作。
RingQueue.hpp
#include <iostream>
#include <vector>
#include <pthread.h>
#include <semaphore.h>
#include <unistd.h>
using namespace std;
const int DNum=7;
class Auto_Lock
{
public:
Auto_Lock(pthread_mutex_t*lock)
:_lock(lock)
{
pthread_mutex_lock(_lock);
}
~Auto_Lock()
{
pthread_mutex_unlock(_lock);
}
private:
pthread_mutex_t*_lock;
};
class Auto_Sem
{
public:
Auto_Sem(sem_t*P,sem_t*V)
:_P(P)
,_V(V)
{
sem_wait(_P);
}
~Auto_Sem()
{
sem_post(_V);
}
private:
sem_t*_P;
sem_t*_V;
};
template<class Ty>
class RQueue
{
private:
vector<Ty> _Rq;
sem_t*_Csem;
sem_t*_Psem;
pthread_mutex_t*_Clock;
pthread_mutex_t*_Plock;
size_t _index;
size_t _outdex;
public:
RQueue(int capacity=5)
:_Rq(capacity)
,_Csem(new sem_t)
,_Psem(new sem_t)
,_Clock(new pthread_mutex_t)
,_Plock(new pthread_mutex_t)
,_index(0)
,_outdex(0)
{
cout<<"_Rq.size()"<<_Rq.size()<<endl;
pthread_mutex_init(_Plock,nullptr);
sem_init(_Csem,0,0);
sem_init(_Psem,0,capacity);
}
~RQueue()
{
pthread_mutex_destroy(_Clock);
pthread_mutex_destroy(_Plock);
sem_destroy(_Csem);
sem_destroy(_Psem);
}
void push(const Ty&indata)
{
Auto_Sem Sem(_Psem,_Csem);
{
Auto_Lock Lock(_Plock);
_Rq[_index++]=indata;
_index%=DNum;
}
}
void pop(Ty*outdata)
{
Auto_Sem Sem(_Csem,_Psem);
{
Auto_Lock Lock(_Clock);
*outdata=_Rq[_outdex++];
_outdex%=DNum;
}
}
};
ConProd.cc
#include "RingQueue.hpp"
#include "teskblock.hpp"
func_t Tasks[4]={Task_1,Task_2,Task_3,Task_4};
typedef func_t DataType;
void* consumer(void*ags)
{
RQueue<DataType>*rq=(RQueue<DataType>*)ags;
while(1)
{
DataType func;
rq->pop(&func);
cout<<"consumer:";
func();
// cout<<"consumer:"<<func<<endl;
sleep(1);
}
}
void* productor(void*ags)
{
RQueue<DataType>*rq=(RQueue<DataType>*)ags;
while(1)
{
DataType&n=Tasks[rand()%4];
rq->push(n);
cout<<"productor:";
n();
// cout<<"productor:"<<<<endl;
}
}
int main()
{
pthread_t c,p;
RQueue<DataType>*rq=new RQueue<DataType>(DNum);
pthread_create(&c,nullptr,consumer,(void*)rq);
pthread_create(&p,nullptr,productor,(void*)rq);
pthread_join(c,nullptr);
pthread_join(p,nullptr);
delete rq;
}test.hpp是任务头文件,这个可以自己写