推理模型部署(一):ONNX runtime 实践
VSCode配置之OnnxRuntime(CPU) && YOLOv7验证
简单来说,对于机器学习模型过程可分为训练迭代和部署上线两个方面:
- 训练迭代,即通过特定的数据集、模型结构、损失函数和评价指标的确定,到模型参数的训练,以尽可能达到SOTA(State of the Art)的结果。
- 部署上线,即指让训练好的模型在特定环境中运行的过程,更多关注于部署场景、部署方式、吞吐率和延迟。
在实际场景中,深度学习模型通常通过PyTorch、TensorFlow等框架来完成,直接通过这些模型来进行推理效率并不高,特别是对延时要求严格的线上场景。由此,经过工业界和学术界数年的探索,模型部署有了一条流行的流水线:
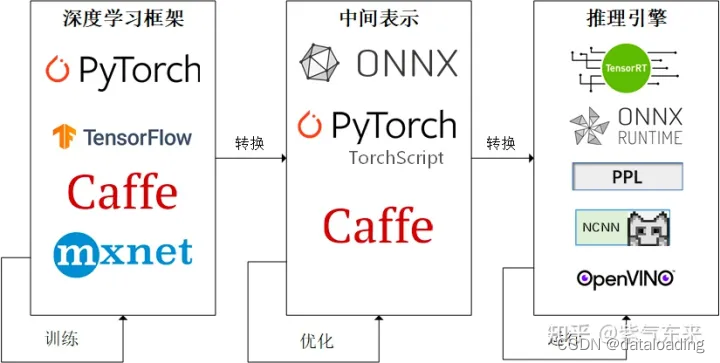
这一条流水线解决了模型部署中的两大问题:使用对接深度学习框架和推理引擎的中间表示,开发者不必担心如何在新环境中运行各个复杂的框架;通过中间表示的网络结构优化和推理引擎对运算的底层优化,模型的运算效率大幅提升。
接下来,我们将通过一步步的实践来体验模型部署的过程。
1. ONNX 面面观
ONNX (Open Neural Network Exchange)是 Facebook 和微软在2017年共同发布的,用于标准描述计算图的一种格式。ONNX 已经对接了多种深度学习框架(如Tensorflow, PyTorch, Scikit-learn, MXNet等)和多种推理引擎。因此,ONNX 被当成了深度学习框架到推理引擎的桥梁,就像编译器的中间语言一样。由于各框架兼容性不一,我们通常只用 ONNX 表示更容易部署的静态图。