摘要:在视觉与语言(V&L)模型中,阅读和推理图像中的文本的能力往往是缺乏的。我们如何才能学习出强大的场景文本理解(STU)的V&L模型呢?
本文分享自华为云社区《场景文本理解预训练PreSTU》,作者: Hint 。
【论文摘要】
在视觉与语言(V&L)模型中,阅读和推理图像中的文本的能力往往是缺乏的。我们如何才能学习出强大的场景文本理解(STU)的V&L模型呢?本文提出了PreSTU,一个专门为场景文本理解而设计的简单预训练模型。PreSTU将一个简单的OCR感知预训练目标与一个具有现成OCR信号的大规模图像-文本数据集相结合。我们在TextVQA、TextCaps、ST-VQA和VizWiz-VQA上经验性地证明了这个预训练目标的优越性。我们还研究了哪些因素会影响STU的性能,其中我们强调了图像分辨率和数据集规模在预训练中的重要性。
【出发点】
在真实世界中的视觉语言任务中,有大量的图像是包含场景文本的。理解图像中的文本对于视觉语言任务来说,往往是重要的,例如发票识别整理、机器人理解环境等。而现有模型经常忽略这一信息。通过对图像OCR信号引入,可以提升视觉语言模型对图像的理解能力。论文基于大规模的图像文本数据集,设计了进行场景文本理解的预训练模型PreSTU。
【解决方案】
1. 引入一个OCR文本生成的预训练任务“SPLITOCR”:给定图像patches,随机将OCR文本分为两个部分,给定第一部分,令模型预测第二部分的OCR文本。
2. 使用Prompt learning的方式,输入各个任务所对应的提示词,使得模型能够更好地适配下游任务。论文中使用image captioning和VQA两个任务。
【总体框架】

模型结构图
如图,模型整体是一个Encoder-Decoder结构,其中视觉encoder采用ViT-B/16 (Dosovitskiy et al., 2021),语言encoder-decoder采用mT5-Base (Xue et al., 2021)。ViT是一个基于Transformer encoder的,在大规模图像分类数据集上预训练的模型。mT5是T5模型(Raffel et al., 2020)的多语言版本,在大规模多语言数据集上预训练,它对OCR识别结果当中出现的识别错误比较健壮,因为使用了wordpiece的方法。
在预训练阶段,将图像中场景文本的OCR信息与图像特征一同输入Encoder,可以使OCR文本与视觉环境更好的联系在一起。通过对余下的OCR文本的预测,模型能够学习出一定的场景文本识别能力,这使得模型同时对视觉和文本两种模态的建模能力得到提升。
【细节】
SPLITOCR任务
1. 目标:在预训练阶段使模型学习如何从图像中识别场景文本。
2. 具体步骤:
1) 首先将OCR文本按照在图中出现的位置排序(从左到右,从上到下);
2) 将OCR文本随机切分为2部分,分别作为输入和预测目标。值得注意的是,如果切分出的第1部分的长度为0,则SPLITOCR任务就退化为了一个传统的OCR任务。
3. 优势:
1) 令模型预测部分OCR文本,使得模型具备一定的完成OCR任务的能力,从而能够增强其阅读场景文本的能力;
2) 输入时引入部分OCR文本,使得输入的形式接近下游任务的形式(都是文本),更便于迁移学习;
3) 便于与其他训练目标相结合,例如image captioning。
预训练数据集
CC15M:是CC3M (Sharma et al., 2018)和CC12M (Changpinyo et al., 2021)的并集。数据集的形式是<图像, 标题>对。进行SPLITOCR目标时,采用Google Cloud OCR系统获取OCR文本的信息。
Fine-tuning阶段
所有下游任务都具有这样的形式:输入是图像+文本,输出只有文本。使用Google OCR获取图片中的场景文本。
进行image captioning任务时,输入为<图像,提示词,OCR token>,输出目标为图像标题;进行场景文本VQA任务时,输入为<图像,提示词,问题,OCR token>,输出为问题的回答。
【实验】
主要结果
实验采用4个benchmarks:TextVQA (Singh et al., 2019) 、ST-VQA (Biten et al., 2019) 、VizWiz-VQA (Gurari et al., 2018) 、TextCaps (Sidorov et al., 2020) 。实验Baseline采用去掉SPLITOCR预训练的本模型PreSTU,同时也对比了以下预训练方法:TAP (Yang et al., 2021) 、Flamingo (Alayrac et al., 2022) 、GIT (Wang et al., 2022a) 。实验结果如表所示。

主要结果
采用SPLITOCR预训练后,PreSTU在所有指标上都相对baseline有提升,这证明了SPLITOCR的有效性,能够赋予模型场景文本阅读的能力。
对比其他模型:PreSTU模型参数和数据量比TAP多,结果也更高一些,除了TextVQA略低;参数量和数据量与GITL基本一致,在所有指标高于GITL;参数量和数据量比Flamingo和GIT小,但结果上没有显著地低。
消融实验
1. 对比SPLITOCR目标与传统OCR目标(TextCaps CIDEr指标):如表,SPLITOCR比OCR预训练的模型结果高,由126.7提升到134.6;

OCR与SPLITOCR对比
2. 在Fine-tuning阶段去掉输入的OCR文本:如表,去掉OCR文本后,各模型都有下降,但baseline模型结果下降更多。OCR/SPLITOCR预训练的模型即便Finetune时不使用OCR文本,结果也比baseline高(116.6/110.4 > 99.6)。这说明SPLITOCR预训练目标能够很好的使模型获得场景文本的阅读能力。

Fine tuning时去掉OCR输入的影响
3. 预训练时的图像分辨率:如表,高分辨率的图像会获得更好的结果。

图像分辨率的影响
4. 预训练的数据规模:如表,数据规模越大,结果越好。
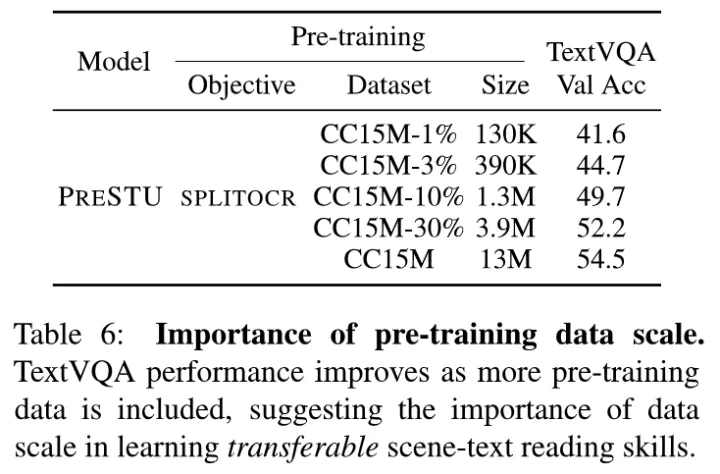
预训练数据规模的影响
【结论】
1. SPLITOCR预训练目标能够使模型的场景文本阅读能力得到提升,从而提高下游任务的结果
2. 对于PreSTU模型来说,预训练图像的分辨率以及数据量很重要。
• 论文地址:https://arxiv.org/abs/2209.05534
【参考文献】
1. Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. 2021. An image is worth 16x16 words: Transformers for image recognition at scale. In ICLR.
2. Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, and Colin Raffel. 2021. mT5: A massively multilingual pre-trained text-totext transformer. In NAACL.
3. Piyush Sharma, Nan Ding, Sebastian Goodman, and Radu Soricut. 2018. Conceptual Captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning. In ACL.
4. Soravit Changpinyo, Piyush Sharma, Nan Ding, and Radu Soricut. 2021. Conceptual 12M: Pushing web-scale imagetext pre-training to recognize long-tail visual concepts. In CVPR.
5. Amanpreet Singh, Vivek Natarajan, Meet Shah, Yu Jiang, Xinlei Chen, Dhruv Batra, Devi Parikh, and Marcus Rohrbach. 2019. Towards VQA models that can read. In CVPR.
6. Ali Furkan Biten, Ruben Tito, Andres Mafla, Lluis Gomez, Marçal Rusinol, Ernest Valveny, C.V. Jawahar, and Dimosthenis Karatzas. 2019. Scene text visual question answering. In ICCV.
7. Danna Gurari, Qing Li, Abigale J. Stangl, Anhong Guo, Chi Lin, Kristen Grauman, Jiebo Luo, and Jeffrey P. Bigham. 2018. VizWiz Grand Challenge: Answering visual questions from blind people. In CVPR.
8. Oleksii Sidorov, Ronghang Hu, Marcus Rohrbach, and Amanpreet Singh. 2020. TextCaps: a dataset for image captioning with reading comprehension. In ECCV.
9. Zhengyuan Yang, Yijuan Lu, Jianfeng Wang, Xi Yin, Dinei Florencio, Lijuan Wang, Cha Zhang, Lei Zhang, and Jiebo Luo. 2021. TAP: Text-aware pre-training for text-vqa and text-caption. In CVPR.
10. Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katie Millican, Malcolm Reynolds, et al. 2022. Flamingo: a visual language model for few-shot learning. arXiv preprint arXiv:2204.14198.
11. Jianfeng Wang, Zhengyuan Yang, Xiaowei Hu, Linjie Li, Kevin Lin, Zhe Gan, Zicheng Liu, Ce Liu, and Lijuan Wang. 2022a. GIT: A generative image-to-text transformer for vision and language. arXiv preprint arXiv:2205.14100.
点击关注,第一时间了解华为云新鲜技术~















![[C/C++/初学者]万年历(输入年份和月份,输出对应的日历表——数组)](https://img-blog.csdnimg.cn/4879cbf16c334d00a6bd9c72a8d5a000.png)