参考资料[langchain官方文档]:
tool retrieval agent::::https://python.langchain.com/docs/modules/agents/how_to/custom_agent_with_tool_retrieval
retrieval memory:::https://python.langchain.com/docs/modules/memory/types/vectorstore_retriever_memory
conversatrionalRetrievalAgent:::https://blog.langchain.dev/conversational-retrieval-agents/
实例:https://python.langchain.com/docs/use_cases/question_answering/how_to/conversational_retrieval_agents?ref=blog.langchain.dev#the-retriever
在具有open_api_key的情况下实现
基本想法或概念:代理在对话过程中优化检索,根据过去的对话回答问题
刚开始的思路:
将memory组件retrieval化,同时将每次的聊天记录也更新到当前文档中,实现对过去的对话检索,这个方法使用vectorestoreRetrievalMemory,这个方法适用于与chain结合使用。因为不需要创建tool去进行调用,但这个方法无法上传文件用来获取之前的历史信息。
后续思路(参考了上述链接3):
ConversationalRetrievalAgent组件核心:使用OpenAIFunctionsAgent代理、tools工具,采用的是retrieval工具、新型的记忆工具AgentTokenBufferMemory
步骤:
第一步:创建检索器工具,这里使用Chroma向量库
from langchain.document_loaders import TextLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
import chromadb
from chromadb import Settings
persist_directory = os.getenv("chroma保存地址", "/chromadb保存地址")
chromadb_client = chromadb.Client(
Settings(
chroma_db_impl='*****',
chroma_server_host=os.getenv("chroma的host", "localhost"),
chroma_server_http_port=os.getenv("chroma的host", "8000"),
persist_directory=persist_directory
)
)
# Load the document, split it into chunks, embed each chunk and load it into the vector store.
raw_documents = TextLoader('../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
vectorstore = Chroma.from_documents(client=chromadb_client,documents=documents, embedding=embeddings)
retriever = vectorstore.as_retriever()
from langchain.agents.agent_toolkits import create_retriever_tool
tool = create_retriever_tool(
retriever,
name="search_state_of_union",
description="Searches and returns documents regarding the state-of-the-union."
)
第二步,创建记忆组件,这里使用AgentTokenBufferMemory,记忆ai–human的输入输出和human-ai的输入输出
from langchain.agents.openai_functions_agent.agent_token_buffer_memory import AgentTokenBufferMemory
memory = AgentTokenBufferMemory(memory_key='chat_history',llm=大模型)
第三步,定义openAIFunctionsAgent组件,
方法一:直接通过langchain封装方法直接使用,其他值为已设置好的默认值
from langchain.agents.agent_toolkits import create_conversational_retrieval_agent
agentExcutor = create_conversational_retrieval_agent(llm=llm模型,tools=[tool],memory_key='chat_history')
方法二:通过OpenaiFunction类自定义一个agent,这里return_intermediate_steps需要设置为true,用来保存聊天记录中间步骤的信息。
MEMORY_KEY = memory.memory_key
prompt = OpenAIFunctionsAgent.create_prompt(system_message=SystemMessage(content=template),extra_prompt_messages=[MessagesPlaceholder(variable_name=MEMORY_KEY)])
agent = OpenAIFunctionsAgent(
llm=llm,
tools=tools,
prompt=prompt
)
agentExecutor = AgentExecutor(agent=agent,tools=tools,memory=memory,verbose=True,return_intermediate_steps=True)
自定义方法时,会出现outputkey----[‘output’,‘intermediate_steps’]的输出错误
`run` not supported when there is not exactly one output key. Got ['output', 'intermediate_steps'].
,这是由于我们将return_intermediate_steps开关被打开,会返回两个输出key值,需要在他执行时,将return_only_outputs设置为true,该字段在链中
agentExecutor({"input" : query['question']},return_only_outputs=True)
最后,分三次询问
query={
'question':'What did the president say about Ketanji Brown Jackson'
}
resp = agentExcutor.run(query=query)
print(resp)
query={
'question':'My name is bob'
}
resp = agentExcutor.run(query=query)
print(resp)
query={
'question':'whats your name ?'
}
resp = agentExcutor.run(query=query)
print(resp)
结果:
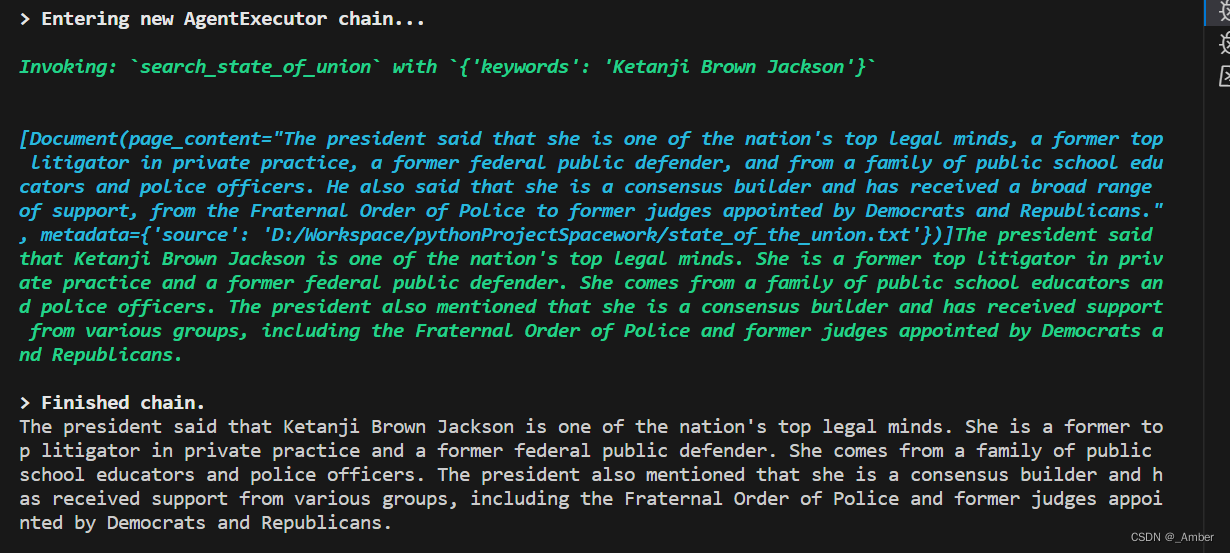
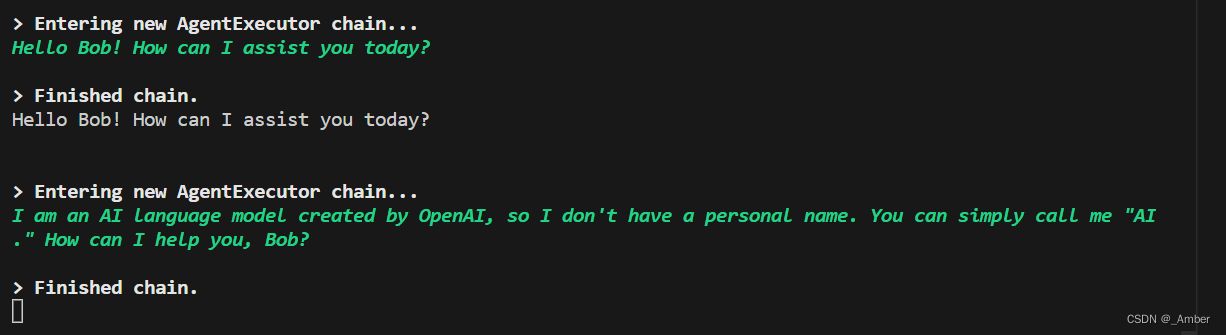
完成ConversationalRetrievalAgent的开发。
想法:最开始使用vectorstoreretrievalMemory来做记忆的保存与检索,与chain结合使用。但是这种方法首先每次检索都需要去检索库里查询,其次查询结果的分数并不一定是正确的。
而该Agent出现的好处就是在进入向量库查询之前先用agent判断是否需要进入,结果是否满足回答,从而得到更准确的回答数据,同时也能减少连接查询。