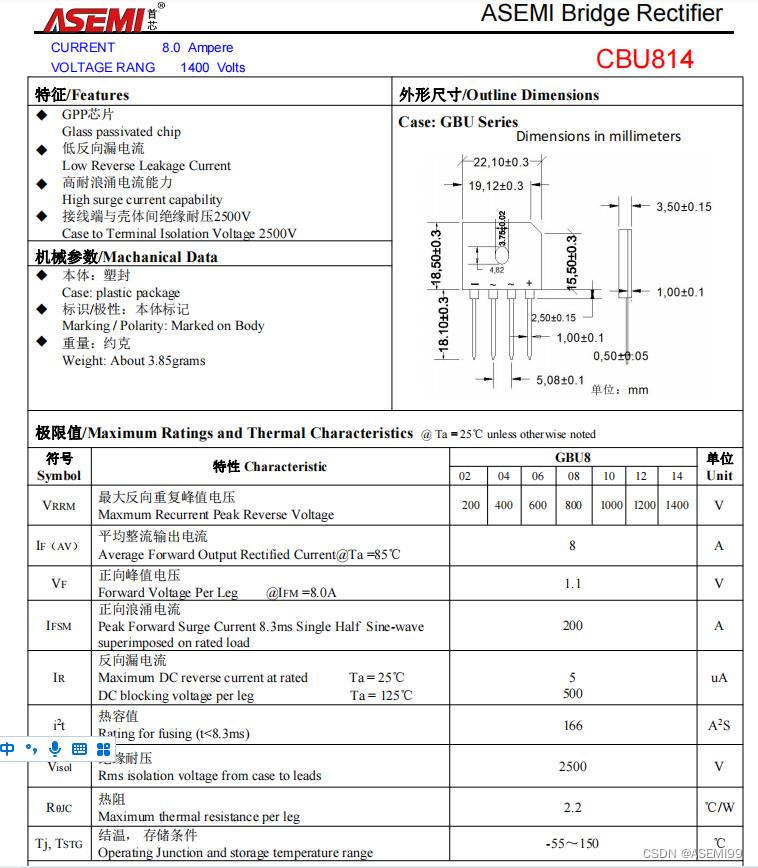
在我们以往接触到的项目或者是业务场景中,大多牵涉到生物特征识别的任务基本都是人脸识别,这也是目前我们每天都会接触到的应用,比如:上下班的打卡、支付时的刷脸等等,这也是比较成熟的一项AI应用。
这里我们简单对一些经典的人脸识别模型做一下总结和回顾,人脸识别是计算机视觉中的一个重要任务,有多种常用的模型用于人脸识别。以下是一些常见的人脸识别模型:
1、VGGFace:VGGFace是基于VGGNet架构,并在大规模人脸数据库上进行了训练的模型。它可以用于人脸识别和验证,并具有较好的性能。VGGFace模型是基于VGGNet架构的人脸识别模型,构建原理如下:
架构设计:VGGFace模型的主体结构遵循了VGGNet架构设计的思想。它由一系列卷积层和全连接层组成。卷积层用于提取图像的特征表示,而全连接层用于进行分类或验证。
卷积层组:VGGFace模型采用了多个大小为3x3的卷积核进行卷积操作,并通过非线性激活函数(如ReLU)引入非线性特征。为了增加网络的深度和非线性能力,它采用了多个相同大小的卷积层堆叠在一起。
池化层:在卷积层之后,VGGFace模型使用最大池化层,以减小特征图的尺寸,并在空间上进行下采样。最大池化操作有助于保留重要的特征并减少冗余信息。
全连接层:在卷积和池化操作之后,VGGFace模型使用全连接层将提取出的特征映射到对应的类别或验证结果。通常,最后的全连接层会经过softmax激活函数进行分类。
优点:
构建简单,易于理解和实现。
VGGFace模型具备较强的特征表达能力和模式识别能力,适合用于人脸识别和验证任务。
缺点:
模型参数量较大,导致计算复杂度较高,需要更多的计算资源。
该模型在训练和部署时可能遇到困难,由于模型结构庞大,需要更多的存储和内存。2、FaceNet:FaceNet是一个基于卷积神经网络和三元组损失函数的人脸识别模型。它能够将人脸图像嵌入到高维特征空间中,并通过欧氏距离进行人脸识别和验证。FaceNet模型是一种基于卷积神经网络和三元组损失函数的人脸识别模型,其构建原理如下:
网络架构:FaceNet模型采用了一种深度卷积神经网络架构。它通过多层卷积和池化操作,逐步提取和学习输入图像的特征表示。最后经过全连接层将特征映射到一个高维特征空间中。
三元组损失函数:FaceNet模型使用三元组损失函数来优化特征表示。对于每个训练样本,从训练集中选择三个样本:锚样本(anchor)、正样本(positive)和负样本(negative)。锚样本和正样本属于同一个人,而负样本属于不同的人。三元组损失函数的目标是使得同一人的特征距离尽量小,不同人的特征距离尽量大。
特征嵌入空间:FaceNet模型学习到的特征向量被映射到一个高维特征空间中。通过欧氏距离或余弦距离,可以衡量不同人之间的距离,以进行人脸识别和验证。
优点:
通过三元组损失函数学习到的特征具有较好的表达能力,适合用于人脸识别和验证任务。
使用三元组损失函数能够直接优化特征向量的距离度量,使得相同人的特征更加接近,不同人的特征更加分散。
缺点:
模型相对复杂,训练过程可能较为耗时。
需要大规模的训练数据和计算资源。模型的性能高度依赖于训练数据的质量和数量。
需要注意的是,FaceNet模型中还可以应用其他技术进行改进,如加权三元组损失函数、在线硬负采样和样本挖掘等。这些改进技术可以进一步提升模型性能和鲁棒性。3、DeepFace:DeepFace是Facebook提出的人脸识别模型,基于卷积神经网络和多层感知器。它可以进行人脸识别、验证和属性预测,具有较好的性能。DeepFace模型是Facebook提出的人脸识别模型,其构建原理如下:
网络架构:DeepFace模型是一个深度卷积神经网络的模型。它由多个卷积层和全连接层构成。卷积层用于提取人脸图像的特征表示,全连接层用于进行人脸识别。
人脸对齐:在DeepFace模型中,首先进行人脸对齐。通过检测人脸关键点,对输入图像进行变换,使得人脸在图像中对齐,减少变化因素的干扰。
特征提取:DeepFace模型使用多个卷积层提取输入图像的特征。通过多层卷积和池化操作,有效地捕捉不同尺度和抽象级别的特征信息。
全连接层和分类:在特征提取后,DeepFace模型通过全连接层将特征映射到人脸类别或特征向量表示。对于人脸识别,该模型可以通过训练识别出不同的人脸。
优点:
DeepFace模型具有较强的特征表达能力和模式识别能力,适合用于人脸识别任务。
通过人脸对齐技术,可以减少人脸间的姿态和尺度差异带来的影响,提高了模型的鲁棒性和准确性。
缺点:
DeepFace模型的训练和调参可能需要大量的计算资源和时间。
由于模型结构庞大,部署和推理的复杂性可能增加。
需要注意的是,DeepFace模型在提出时在LFW(Labeled Faces in the Wild)数据集上取得了很好的性能。然而,它也面临一些限制,如对于遮挡和光照变化的敏感性。为了获得更好的性能,可以结合其他的预处理方法和技术,如数据增强、特征融合等。4、ArcFace:ArcFace是一种基于角度余弦间隔的人脸识别模型,通过缩小同一人的特征向量之间的角度余弦距离,扩大不同人之间的距离,来实现更好的人脸识别性能。ArcFace模型是一种基于角度余弦间隔的人脸识别模型,其构建原理如下:
构建特征提取网络:ArcFace模型通常使用卷积神经网络(CNN)作为特征提取器。通过多层卷积和池化操作,提取人脸图像的特征表示,并通过非线性激活函数引入非线性特征。
嵌入特征映射:ArcFace模型将经过特征提取的人脸特征映射到一个高维特征空间。该特征空间的设计目的是使得同一人的特征之间的角度余弦距离尽量小,而不同人的特征之间的距离尽量大。通过引入角度余弦间隔,使得特征在嵌入特征空间上进行了偏移。
添加ArcMargin Loss:为了优化特征空间的判别性,ArcFace模型引入了ArcMargin Loss。该损失函数通过在特征空间中计算特征向量和标签向量之间的角度余弦距离,并最小化同一人的特征距离,放大不同人的特征间距。通过调整ArcMargin Loss的超参数,可以控制同一人的特征向量之间的边界。
优点:
ArcFace模型在人脸识别任务中具备较高的准确性和鲁棒性。通过引入角度余弦间隔,提高了特征的可分性。
可以通过调整ArcMargin Loss的超参数来灵活控制特征向量的边界,使得模型适应各种复杂性和类别之间的差异。
缺点:
ArcFace模型在训练过程中需要大规模和均衡的数据集,对数据质量和数量有一定的要求。
模型相对复杂,需要更多的计算资源和时间来进行训练和推理。
需要注意的是,ArcFace模型的性能还受到超参数设置的影响,如角度余弦间隔的大小和ArcMargin Loss的权重。合适的超参数设置对于获得最佳性能非常关键。5、OpenFace:OpenFace是一个用于人脸识别和验证的开源人脸识别模型。它使用深度神经网络进行人脸图像的特征提取和距离计算,具有较好的性能。OpenFace模型是一种用于人脸识别和验证的开源人脸识别模型,其构建原理如下:
人脸检测:首先,OpenFace模型使用人脸检测算法(如基于Haar级联分类器或深度学习的检测器)来在输入图像中定位和提取出人脸区域。
人脸对齐:为了减少姿态和尺度的影响,OpenFace模型通过人脸对齐操作将检测到的人脸区域进行几何变换。通常采用基于关键点(如眼睛、鼻子和嘴巴)的人脸对齐方法,使得不同人脸在特征位置上对齐。
特征提取:在人脸对齐后,OpenFace模型使用卷积神经网络(CNN)来提取人脸图像的特征表示。通过多层卷积和池化操作,高级特征被提取出来,形成一个固定大小的特征向量。
特征分类和识别:OpenFace模型通过全连接层将特征向量映射到对应的人脸类别或验证结果。可以使用softmax激活函数进行多类别分类,或使用阈值判定进行人脸验证。
优点:
OpenFace模型是开源的,提供了开源的实现代码和预训练模型,方便使用和定制。
通过人脸对齐操作,可以有效处理姿态和尺度变化带来的影响,提高了模型的准确性和鲁棒性。
模型具备一定的通用性,适用于不同的人脸识别和验证任务。
缺点:
OpenFace模型在大规模和复杂数据集上的性能可能有所限制。
模型在性能和速度方面可能不如某些专门优化的商业人脸识别模型。
模型的准确性受人脸检测和对齐算法的质量和稳定性影响。6、SphereFace:SphereFace是一种基于球面几何的人脸识别模型,通过在特征空间中引入球面约束来提高人脸识别的性能。SphereFace模型是一种基于球面几何的人脸识别模型,其构建原理如下:
特征提取:SphereFace模型使用卷积神经网络(CNN)架构作为特征提取器。通过多层卷积和池化操作,提取人脸图像的特征表示。
特征映射:SphereFace模型将特征向量映射到球面上。这是通过在特征向量上进行归一化和投影操作实现的。归一化可以使特征向量落在单位球面上,然后通过投影操作将球面上的特征映射到一个限定范围内。
余弦角度分类器:在特征映射之后,SphereFace模型使用余弦角度分类器来进行人脸识别。该分类器通过计算特征向量与类别标签之间的角度余弦值,并将其作为分类的依据。具体而言,该模型将分类问题转化为特征向量与类别标签之间的二分类问题,通过优化角度余弦的Margin来学习特征表示。
优点:
SphereFace模型的特征映射到球面上,这利用了球面几何的特点,使特征向量具有更好的可分性。
通过优化角度余弦的Margin,该模型通过强制不同类别的特征向量之间的分离度,提高了人脸识别的准确性和稳定性。
缺点:
SphereFace模型对于面部姿态和遮挡等复杂情况的鲁棒性可能稍弱,对输入图像的质量和预处理要求较高。
由于特征映射到球面上的操作,模型的复杂度增加,可能导致训练和推理的计算开销加大。这里对已有的一些经典的人脸识别模型做了简单的回顾总结,机器学习相关的模型这里不做总结,因为本文的主要思想是想要基于深度学习领域的模型来开发实现养殖行业内牛脸识别的应用,这里也仅仅是以牛类养殖场景为例来开发项目的,对于其他领域的数据也可参考拓展尝试一下。
另外的一个想法就是应用于人脸识别领域内很成功的模型在动物身上,比如:奶牛、猪、狗等是够也能奏效呢?这是项目开发之初心里的疑问,接下来我们来看下整体的开发流程:

整体项目主要分为三大部分:
1、数据采集
这部分主要是要跟合作养殖厂进行对接,安装设备实地采集数据,我们的数据是对接到阿里云端oss的存储平台中了,这块因人而异,可以根据自己的实际需求进行处理即可,你存储在本地也都是可以的。
2、模型开发
这部分是整个项目最为核心的内容,在模型上,我前面总结对比了多款目前为止经典的人脸识别网络模型,这里最终决定选择arcFace模型来实现,在模型层面并没有去过多改造,主要是偏向数据集相关的开发适配,如果本身原生模型就能够有不错的表现那么后面的思路就拓宽了。
3、应用构建
在所有的实际项目中,模型的开发训练评估测试工作仅仅是项目的一部分而已,真正要让模型发挥出来作用的话,是需要开发构建应用也就是实现业务逻辑部分才行的,在这里主要是能要对外部输入图像进行响应处理返回正确结果。
第一部分不是本文的重点,因为这个比较看实际场景情况,本文的内容则是从第二部分开始。考虑到真实数据有相关协议的限制,这里直接使用已有的数据集来开发整套项目。
先来看下整体数据集的情况,如下所示:

一共有20头实验牛的数据,每个子目录下存储对应牛的图像数据即可。
前面讲过这里模型选择的是arcFace模型,直接开源仓库里面搜搜arcface即可,如下所示:

因人而异,选择适合自己的一个项目即可。按照对应项目的README操作即可,这里我就不再赘述了。
接下来看数据集处理,核心代码实现如下所示:
# 加载解析创建数据集
train_ratio = 0.90
if not os.path.exists("dataset.json"):
train_datasets = []
test_datasets = []
all_dataset = []
classes_list = os.listdir(datasetDir)
classes_list.sort()
print("classes_list: ", classes_list)
for one_label in os.listdir(datasetDir):
oneDir = datasetDir + one_label + "/"
for one_pic in os.listdir(oneDir):
one_path = oneDir + one_pic
try:
one_ind = classes_list.index(one_label)
all_dataset.append([one_ind, one_path])
except:
pass
train_num = int(train_ratio * len(all_dataset))
all_inds = list(range(len(all_dataset)))
train_inds = random.sample(all_inds, train_num)
test_inds = [one for one in all_inds if one not in train_inds]
for one_ind in train_inds:
train_datasets.append(all_dataset[one_ind])
for one_ind in test_inds:
test_datasets.append(all_dataset[one_ind])
dataset = {}
dataset["train"] = train_datasets
dataset["test"] = test_datasets
with open("dataset.json", "w") as f:
f.write(json.dumps(dataset))
else:
with open("dataset.json") as f:
dataset = json.load(f)
train_datasets = dataset["train"]
test_datasets = dataset["test"]
print("train_dataset_size: ", len(train_datasets))
print("test_dataset_size: ", len(test_datasets))
train_size = len(train_datasets)
test_size = len(test_datasets)
np.random.seed(10101)
np.random.shuffle(train_datasets)
np.random.seed(10101)
np.random.shuffle(test_datasets)这里我自动加载本地图像数据集,之后按照预设的比例,随机划分训练集-测试集,最终将划分好的数据集存储在json文件中,我个人是比较习惯使用json来进行数据的存储和加载操作,感觉比其他文件格式比如txt、excel更加便利,当然了这里也是因人而异,完全可以选择其他的格式,自行实现即可。
全部配置处理之后就可以启动训练了,如下所示:

这里默认设定了100次epoch的迭代计算,存储记录对应的训练loss和验证loss,如下所示:
22.745543765482928 21.606719970703125
14.758126706053309 16.807703018188477
9.504694906331725 13.123318672180176
7.453128774287337 12.55220890045166
5.927459520135222 5.858639240264893
5.23428454372169 5.896636962890625
4.8976211035992465 4.700520038604736
4.650835441330732 5.099088191986084
4.465787421512065 4.574463844299316
4.300679909980904 4.397739410400391
4.120349603857698 4.18416690826416
3.989299631388174 4.004440784454346
3.8523387706885903 4.027411937713623
3.723243522105244 4.153083801269531
3.6287372947412697 3.6166114807128906
3.491580704511222 3.66166090965271
3.3658991573894093 3.304938316345215
3.252041830181402 3.2633960247039795
3.1512346995078913 3.2415919303894043
3.053000786883683 3.010913610458374
2.953976687738451 2.916686534881592
2.8652365679121288 3.298731803894043
2.787449834036962 2.851003408432007
2.7114209563045177 2.7361371517181396
2.6354110011946683 2.9512929916381836
2.5727186283822787 2.859736680984497
2.5280504415264238 2.9009780883789062
2.4653763892286915 2.498457193374634
2.3739257680494235 2.3249146938323975
2.3193125347633146 2.4180026054382324
2.247198110246389 2.234053373336792
2.18049676674234 2.1507980823516846
2.123612438891567 2.0953879356384277
2.068750347794786 2.042877435684204
2.0179045604447188 1.9936681985855103
1.9697309793052027 1.946508765220642
1.9239117291014074 1.9020377397537231
1.8803742780523784 1.8593367338180542
1.8390125575038674 1.819227933883667
1.7997437816555217 1.78080153465271
1.7624684255675407 1.7446209192276
1.7271117072994426 1.7100780010223389
1.6935991668431771 1.677516222000122
1.6618467064227087 1.646558403968811
1.6317870253223483 1.6173909902572632
1.6033474826543344 1.5896658897399902
1.5764587558595473 1.5635625123977661
1.551061329195055 1.5388692617416382
1.5270934239619196 1.515649676322937
1.5044939107140578 1.4936461448669434
1.483204865186228 1.4730159044265747
1.4631764747328677 1.4536327123641968
1.4443537165216134 1.4353770017623901
1.4266855447305797 1.4182852506637573
1.4101261324801688 1.4022464752197266
1.394628361793561 1.3873016834259033
1.3801460434487984 1.3732649087905884
1.366639313724755 1.3602677583694458
1.3540622305735357 1.3481229543685913
1.342376768925769 1.3369195461273193
1.331543677944248 1.3264280557632446
1.3215244247414972 1.3168425559997559
1.3122825662968522 1.3079594373703003
1.303780262079616 1.2998871803283691
1.2959860078359053 1.2923485040664673
1.2888601695076893 1.285646915435791
1.282373276807494 1.279362440109253
1.276487888589417 1.2738797664642334
1.271176505223506 1.268733024597168
1.2664028197358557 1.2643548250198364
1.2621352093367926 1.2601855993270874
1.2583426055261644 1.2567025423049927
1.254992994211488 1.2535039186477661
1.252055929205512 1.2509020566940308
1.2494973105899359 1.2483779191970825
1.2472913036238675 1.2464599609375
1.245400376912564 1.2446092367172241
1.2437968126124581 1.2432475090026855
1.242448725942838 1.2419146299362183
1.2413240280528526 1.2410238981246948
1.2403917265477153 1.2400213479995728
1.2396162451997315 1.239435076713562
1.2389752400123466 1.238748550415039
1.2384316954909071 1.2384374141693115
1.2379537484066634 1.237793207168579
1.2375068913745342 1.2375221252441406
1.2370710184345137 1.2369189262390137
1.2366336510006317 1.2365871667861938
1.2361970500083967 1.2360291481018066
1.23576018365763 1.2357386350631714
1.2353251532646223 1.2351943254470825
1.234887668641947 1.234852910041809
1.234453465978978 1.2342981100082397
1.2340160742991388 1.234020709991455
1.2335804768201322 1.2334349155426025
1.2331441135729773 1.2331453561782837
1.2327107359460518 1.232540249824524
1.2322731105621252 1.2322278022766113
1.2318401787914126 1.2316826581954956
1.231404577271413 1.2314034700393677为了直观进行分析,这里对其进行可视化处理,代码实现如下所示:
plt.clf()
plt.figure(figsize=(10,6))
plt.plot(train,label="Train Loss Cruve", color='g')
plt.plot(test,label="Test Loss Cruve", color='b')
plt.legend(ncol=1)
plt.title("Model Loss Cruve")
plt.savefig("loss.png")结果如下所示:

从训练loss曲线来看效果还不错。
借助于可视化工具可以查看模型的详细结构参数信息,如下所示:

到这里,模型的开发训练部分就基本结束了。
接下来就是需要借助于faiss来进行向量化特征数据库创建处理了。简单对faiss总结回顾一下:
faiss是Facebook AI Research开源的一款用于高效相似性搜索和聚类的库。它特别擅长处理大规模向量数据,并提供了一系列高性能的算法和数据结构。下面是对faiss的详细介绍及其对应的优点和缺点:
算法支持:faiss提供多种高效的相似性搜索算法,包括基于倒排索引(inverted file)的算法、基于k-means的聚类算法、局部敏感哈希(LSH)算法等。这些算法具有广泛的适用性,能够满足不同的搜索和聚类需求。
高性能:faiss在设计上针对性能进行了优化,具备高度并行化和高效利用硬件的特点。它支持使用GPU进行计算加速,能够快速处理大规模向量数据,实现高速的相似性搜索和聚类。
易于使用:faiss提供了简单易用的API接口,方便用户进行向量索引、查询和聚类操作。它具备友好的Python和C++接口,还支持主流的机器学习框架,如PyTorch和TensorFlow。
可扩展性:faiss支持在线学习和增量索引的功能。它允许用户动态添加和删除向量数据,而无需重新构建索引结构,从而提供了较强的可扩展性和灵活性。
内存优化:faiss针对大规模向量数据的特点,提供了各种内存优化的技术。例如,faiss可以将数据划分为多个索引分片,以减少内存使用量;还可以对索引结构进行精细的参数调优,以平衡性能和内存占用。
优点:
faiss具备高性能和高效率的特点,能够快速处理大规模向量数据的相似性搜索和聚类任务。
提供了多种高性能的相似性搜索算法和数据结构,满足不同的搜索需求。
具有较好的可扩展性,支持在线学习和增量索引的功能。
提供了友好的API接口和多语言支持,使得使用和集成相对简单。
缺点:
faiss的主要应用场景是相似性搜索和聚类,不适用于其他更复杂的数据分析任务。
部署和使用faiss可能需要一定的技术背景和理解。
其实在我之前的一些博文里面已经比较详细地介绍过faiss这一向量化检索工具了,感兴趣的话可以自行移步阅读即可,这里就不再展开了:
《人脸识别场景下Faiss大规模向量检测性能测试评估分析》
《基于arcFace+faiss开发构建人脸识别系统》
《基于facenet+faiss开发构建人脸识别系统》
《大规模向量检索库Faiss学习总结记录》
《基于text2vec和faiss开发实现文档查询系统初体验》
还算是比较详细的了,感兴趣的话可以回过头去看下即可。这部分的检索应用实现跟前面的逻辑是完全一致的,就不再再次阐述了。
特征数据库创建核心代码实现如下所示:
def batch2Vec(picDir="datasets/", saveDir="DB/", save_path="cowDB.json"):
"""
批量数据向量化处理
"""
if not os.path.exists(saveDir):
os.makedirs(saveDir)
feature=[]
cows={}
count=0
for one_cow in os.listdir(picDir):
oneDir=picDir+one_cow+"/"
print("one_cow: ", one_cow, ", one_num: ", len(os.listdir(oneDir)), ", count: ", count)
for one_pic in os.listdir(oneDir):
one_path=oneDir+one_pic
one_vec=sinleImg2Vec(pic_path=one_path)
if one_cow in cows:
cows[one_cow].append([one_pic, one_vec])
else:
cows[one_cow]=[[one_pic, one_vec]]
feature.append([one_path, one_vec])
count+=1
print("feature_length: ", len(feature))
with open(saveDir+save_path, "w") as f:
f.write(json.dumps(feature))
with open(saveDir+"cow.json", "w") as f:
f.write(json.dumps(cows))结果输出如下所示:

到这里特征数据库就构建完成了,接下来就可以检索了,相关的实现在前文中都有这里就不再赘述了,直接看下实例:
【图像输入】

【检索输出】
top5的结果:

top15的结果:

【图像输入】

【检索输出】
top5的结果:

top15的结果:

【图像输入】

【检索输出】
top5的结果:

top15的结果:

为了整体集成整套计算流程这里开发了专用的可视化系统界面,来帮助操作者便捷地使用整套项目,实例效果如下所示:
到这里基本的开发实践就结束了,后面实际应用之前还是需要对模型进行测试优化,另外考虑实际算力的限制可能还需要对推理逻辑进行优化。




![[CKA]考试注意事项及作者考试结果](https://img-blog.csdnimg.cn/3a62132fc67b41c288920d03e3a2fbc7.png)