嗨,亲爱的爬虫开发者们!在当今的数据驱动时代,大规模数据的爬取对于许多领域的研究和应用至关重要在本文中,我将与你分享大规模数据爬取的实战经验,重点介绍增量和分布式爬虫架构的应用,帮助你高效地处理海量数据。
1.增量爬虫
增量爬虫是指只爬取新增或更新的数据,而不是重新爬取整个网站的所有数据。这种方式可以大大提高爬虫的效率和性能。
实现方法:
-记录数据状态:对已经爬取的数据进行标记或记录,例如使用数据库或缓存来保存已经访问的URL和相关数据的状态。
-定期检查更新:定期运行增量爬虫,通过比对已有数据和目标网站的差异来确定新增或更新的内容。
-增量数据处理:对新增或更新的数据进行处理,例如存储到数据库、更新索引或进行进一步的分析。
2.分布式爬虫架构
分布式爬虫架构是指将爬虫任务分解为多个子任务,并在多台机器上并行执行,以提高爬取效率和处理能力。
实现方法:
-任务分配和调度:使用任务调度器将爬虫任务分配给不同的爬虫节点,确保任务的均衡分布和高效执行。
-数据通信和同步:爬虫节点之间需要进行数据通信和同步,例如使用消息队列或分布式存储系统来传递任务和数据。
-分布式数据处理:将爬取的数据分布式存储,例如使用分布式数据库或文件系统来存储和管理海量数据。
应用场景:
-搜索引擎索引:分布式爬虫架构可用于搜索引擎的网页抓取和索引构建,以提供准确和及时的搜索结果。
-大数据分析:大规模数据爬取和增量更新可用于大数据分析和机器学习任务,帮助挖掘有价值的信息和模式。
-商业情报收集:分布式爬虫可以帮助企业收集竞争对手的信息、市场趋势和用户反馈,支持决策和战略规划。
下面提供两组对应的爬虫示例代码:
pytho import requests from bs4 import BeautifulSoup #增量爬虫示例 def incremental_crawler(): #获取已爬取的URL列表 crawled_urls=get_crawled_urls_from_database()#从数据库中获取已爬取的URL列表 #获取目标网站的最新数据 url='https://www.example.com'#替换为目标网站的URL response=requests.get(url) if response.status_code==200: soup=BeautifulSoup(response.text,'html.parser') links=soup.find_all('a')#根据实际网页结构修改选择器 for link in links: href=link.get('href') if href not in crawled_urls: #处理新增的链接 process_link(href) #将已爬取的URL保存到数据库 save_crawled_url_to_database(href) else: print('Failed to retrieve data from the website.') #分布式爬虫架构示例 def distributed_crawler(): #任务分配和调度代码 #爬虫节点代码 def crawler(url): response=requests.get(url) if response.status_code==200: #数据处理代码 process_data(response.text) else: print('Failed to retrieve data from',url) #数据通信和同步代码 #分布式数据处理代码 def process_data(data): #数据存储或进一步处理的代码 #主程序 if __name__=='__main__': #获取待爬取的URL列表 urls=get_urls_to_crawl_from_queue()#从任务队列中获取待爬取的URL列表 #并行执行爬虫任务 for url in urls: crawler(url) #运行示例代码 if __name__=='__main__': incremental_crawler() print('---') ditributed_crawler()
请注意,以上示例代码只提供了一个基本的框架,具体的实现方式需要根据实际需求和系统架构进行调整。同时,在进行大规模数据爬取时,需要遵守相关的法律法规和网站的使用条款,确保合法合规地进行数据爬取和处理。
大规模数据爬取是一个复杂而挑战性的任务,但通过使用增量和分布式爬虫架构,我们可以提高爬虫的效率和性能,更好地处理海量数据。希望以上实战经验对你在大规模数据爬取的旅程中有所帮助!如果你有任何问题或想法,请在评论区分享!让我们一起探索大数据爬取的精彩世界!
希望以上示例代码和实战经验对你在大规模数据爬取的实践中有所帮助!如果您有更多的见解,欢迎评论区留言讨论
大规模数据爬取 - 增量和分布式爬虫架构实战
news2026/3/27 15:10:02
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/939441.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章
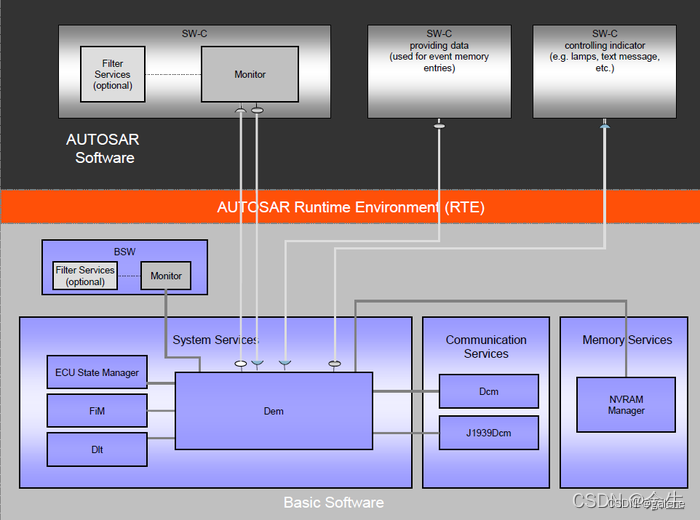
AUTOSAR DEM (一):简介
AUTOSAR DEM (一):简介 故障事件触发故障信息上报故障信息处理故障事件存储DEM与其他模块的联系 缩略词说明
abbreviationdescriptionDEMDiagnostic event managerDTCDiagnostic Trouble CodeBSWBasic softwareSWCSoftware componenECUMECU state manag…
Java 大厂面试 —— 常见集合篇 List HashMap 红黑树
23Java面试专题 八股文面试全套真题(含大厂高频面试真题)多线程_软工菜鸡的博客-CSDN博客
常见集合篇-01-集合面试题-课程介绍 02-算法复杂度分析 2 List相关面试题
2.1 数组
2.1.1 数组概述
数组(Array)是一种用连续的内存空…
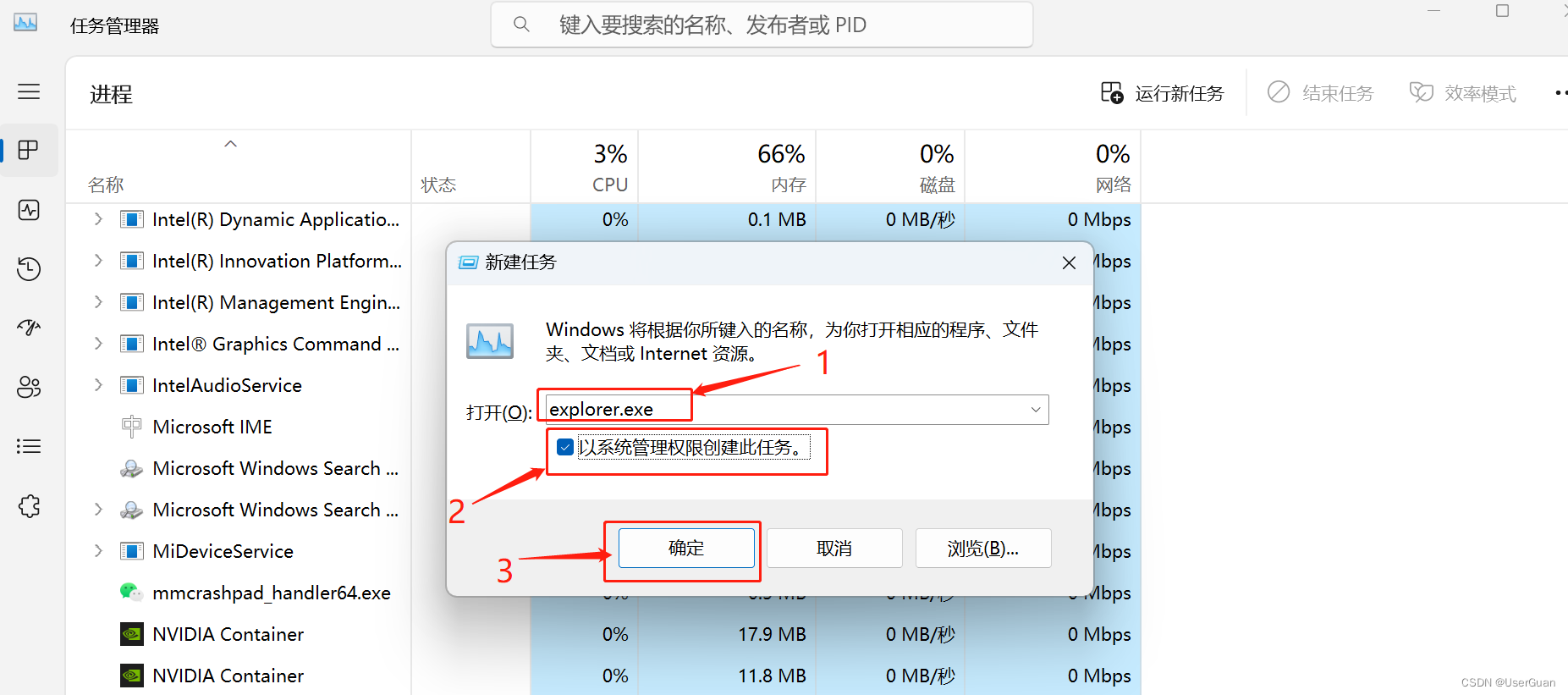
Win11 重启资源管理器的方法
方法一:按【Ctrl Alt Del】组合键后,调出锁定界面,然后点击【任务管理器】即可 方法二:按【Ctrl Shift ESC】组合键后,会直接调出任务管理器
1、在任务管理器窗口中,找到名称为【Windows 资源管理器】…

使用synchronized关键字同步类方法
要想解决“脏数据”的问题,最简单的方法就是使用synchronized关键字来使run方法同步,代码如下: public synchronized void run() { } 从上面的代码可以看出,只要在void和public之间加上synchronized关键字,就可以…
![[CKA]考试注意事项及作者考试结果](https://img-blog.csdnimg.cn/3a62132fc67b41c288920d03e3a2fbc7.png)
[CKA]考试注意事项及作者考试结果
在CKA考试的时候,注意目前可以使用中文名进行注册,最后证书上的名字也是中文名
考试前准备:
1、身份证
2、桌面除了电脑鼠标其他物品都收好
3、房间就自己一个人,不允许房间有其他人
4、网速要快,博主特意升级了自…
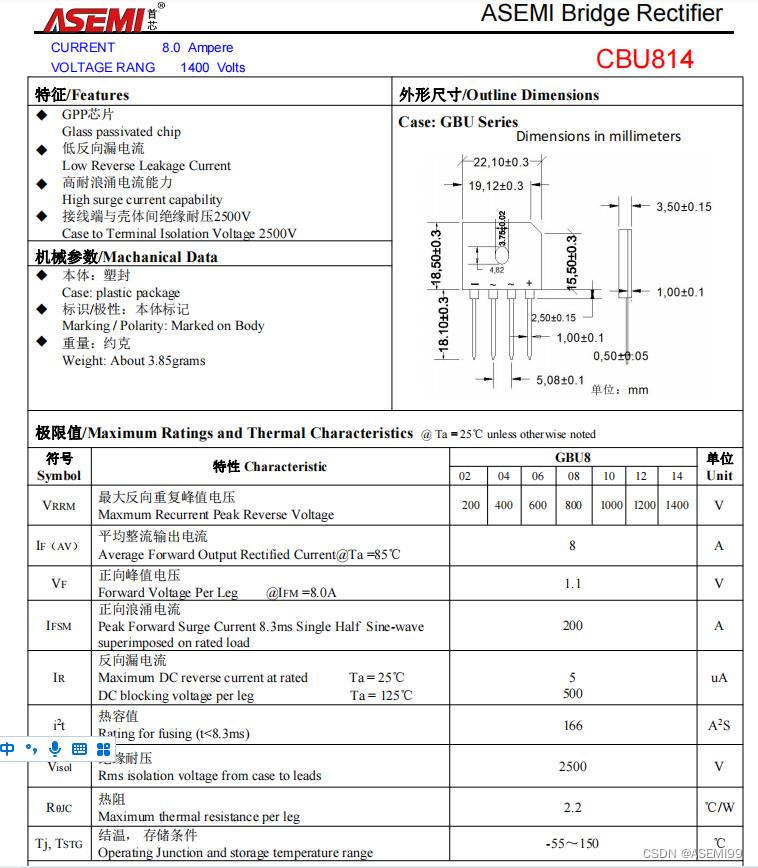
GBU814-ASEMI功率整流器件GBU814
编辑:ll
GBU814-ASEMI功率整流器件GBU814
型号:GBU814
品牌:ASEMI
封装:GBU-4
恢复时间:>50ns
正向电流:8A
反向耐压:1400V
芯片个数:4
引脚数量:4 …
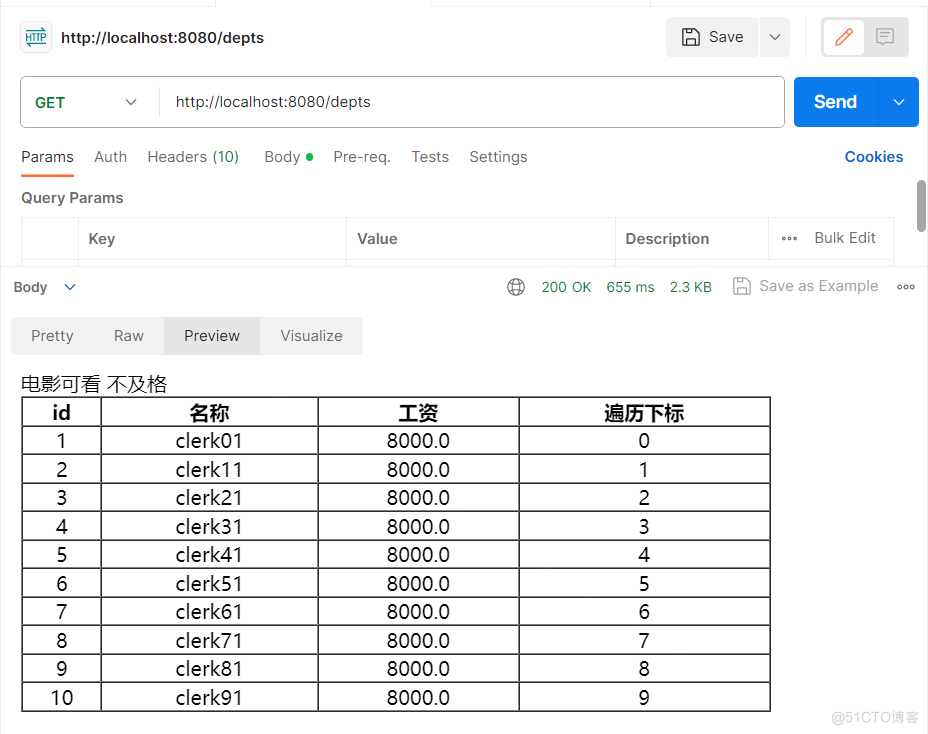
CGLIB代理,jsp,EL表达式,JSTL标准标签库
1、CGLIB代理 有一个类没有实现接口,想要对这个类实现增强,就需要使用CGLIB代理 导入CGLIB的包 <dependency><groupId>cglib</groupId><artifactId>cglib</artifactId><version>3.3.0</version>
</depende…
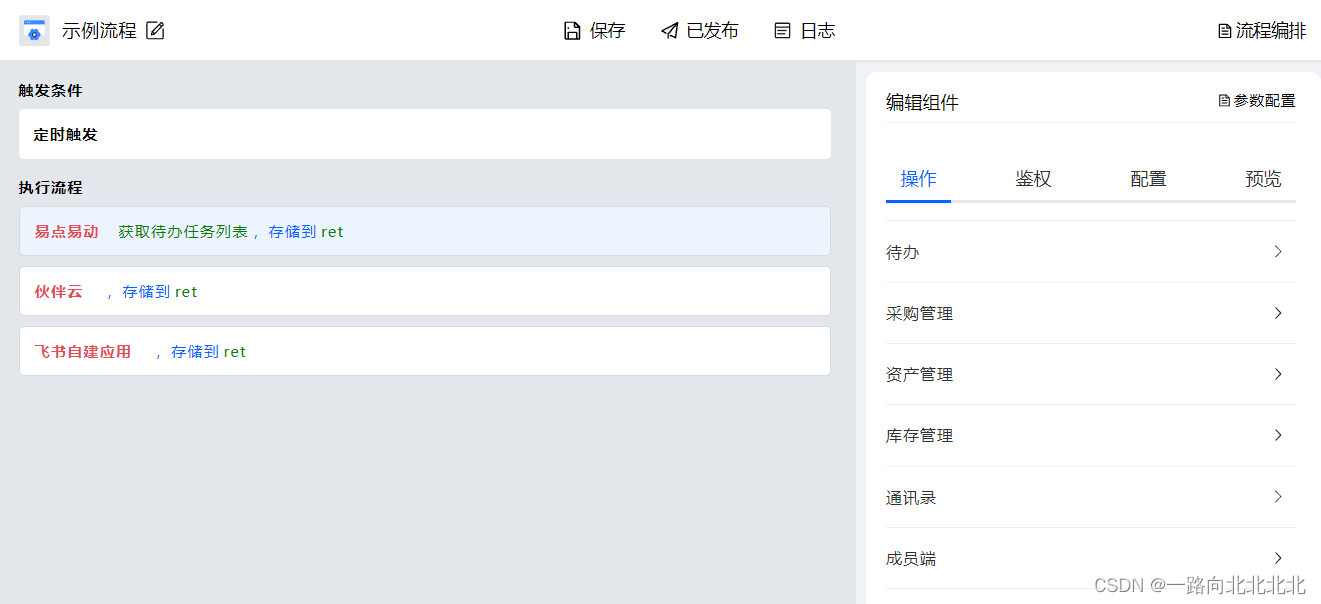
集成易点易动管理系统连接更多应用
场景描述:
基于易点易动开放平台能力,无代码集成易点易动与多个应用互通互连,实现固定资产管理数字化、智能化。通过Aboter可搭建业务自动化流程,实现多个应用之间的数据连接。
开放能力:
消息推送:
新…

无涯教程-分类算法 - 多项式逻辑回归模型函数
Logistic逻辑回归的另一种有用形式是多项式Logistic回归,其中目标或因变量可以具有3种或更多可能的unordered类型,即没有定量意义的类型。
用Python实现
现在,无涯教程将在Python中实现上述多项式逻辑回归的概念。为此,使用…
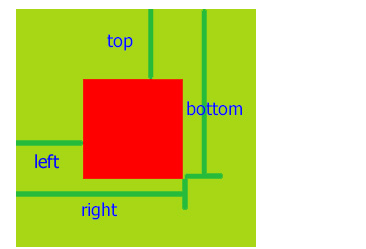
前端js实现获取指定元素(top,lef,right,bottom)到视窗的距离 ;getBoundingClientRect()获取
getBoundingClientRect()获取元素位置,这个方法没有参数 该函数返回一个Object对象,该对象有6个属性:top,lef,right,bottom,width,height; <div id"box"></div>var objectdocument.getElementById(box); …

产教融合 | 中南大学暑期实训,用万应低代码践行敏捷开发之路
融合学究与实践,方能成为当代“数字英才”。 2023年8月11日,由潇湘大数据研究院、中南大学计算机学院及云畅科技联合组织的2020级数据科学与大数据技术专业暑期‘生产实训’项目圆满结束。本次实训全程线下进行,基于“深度创新培育计划”&…
宇凡微Y51T合封射频芯片,集成433M芯片和MCU
宇凡微推出的Y51T芯片的设计理念很有趣,将MCU和射频芯片集成在一颗芯片内,从而实现高度的集成度和功能优势。这样的设计在某些应用中确实能够带来诸多优点: Y51T将51H MCU和Y4455 433MHz射频芯片融合在一颗芯片内,实现了高度集成的…
GPU中统一内存最新机制解析
通过异构内存管理简化 GPU 应用程序开发 异构内存管理 (HMM) 是一项 CUDA 内存管理功能,它扩展了 CUDA 统一内存编程模型的简单性和生产力,以包括具有 PCIe 连接的 NVIDIA GPU 的系统上的系统分配内存。 系统分配内存是指最终由操作系统分配的内存&#…

face-api实现人脸识别。
face-api实现人脸识别 face-api的由来tensorflow.js 是什么部分代码模型介绍 face-api的由来
访问地址 JavaScript API for face detection and face recognition in the browser implemented on top of the tensorflow.js core API 官方说明 翻译:在tensorflow.js…
oppo手机怎么录屏?录制屏幕,就看这里!
“有人知道oppo手机怎么录屏吗,前几年买的oppo手机,用到现在感觉挺流畅的,也不是很卡顿,最近听说我这个型号的手机也有录屏功能,但是我不知道怎么打开,就想问问大伙,oppo手机怎么录屏呀。”
在…
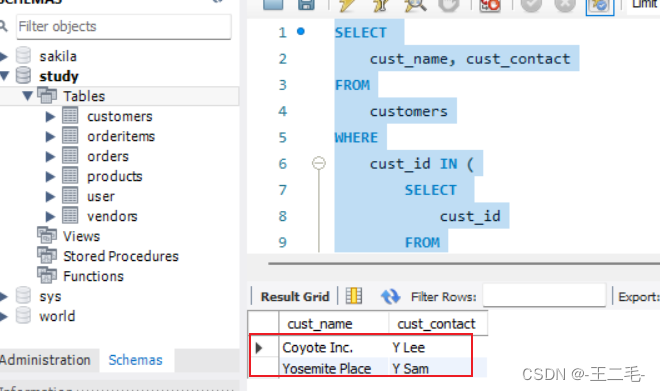
MySql015——使用子查询
一、创建customers表
########################
# Create customers table
########################
use study;CREATE TABLE customers
(cust_id int NOT NULL AUTO_INCREMENT,cust_name char(50) NOT NULL ,cust_address char(50) NULL ,cust_city char…

LED地板屏幕的工作原理
LED地砖屏是一款数字化地面展示设备,它的实现主要是以数字技术为核心,通过微电脑全数字化处理以及先进的电路保护设备,对视频进行同步控制,并实现了高分辨率的显示效果,在展厅设计以及舞台演出中都有相关的应用。免费提…
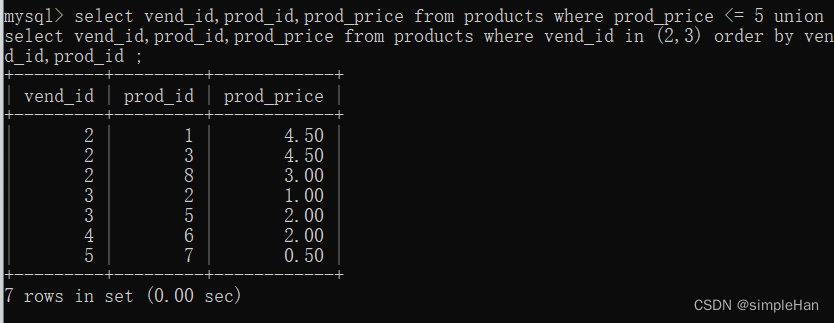
【MySQL】组合查询
目录 一、组合查询
1.创建组合查询
2.union规则
3.包含或取消重复的行
4.对组合查询结果排序 一、组合查询 多数SQL查询都只包含从一个或多个表中返回数据的单条SELECT语句。MySQL也允许执行多个查询(多条SELECT语句),并将结果作为单个查…
kafka和消息队列
https://downloads.apache.org/kafka/3.5.1/kafka_2.13-3.5.1.tgz d
kafka依赖与zookeeper
kakka配置文件
broker.id1 #每个 broker 在集群中的唯一标识,正整数。每个节点不一样
listenersPLAINTEXT://192.168.74.70:9092 ##监听地址
num.network.threads3 #…