Is SNN a great work ? Is SNN a convolutional work ?
ANN的量化在SNN中是怎么体现的,和threshold有关系吗,threshold可训练和这个有关吗(应该无关)
解决过发放不发放的问题。
Intuation
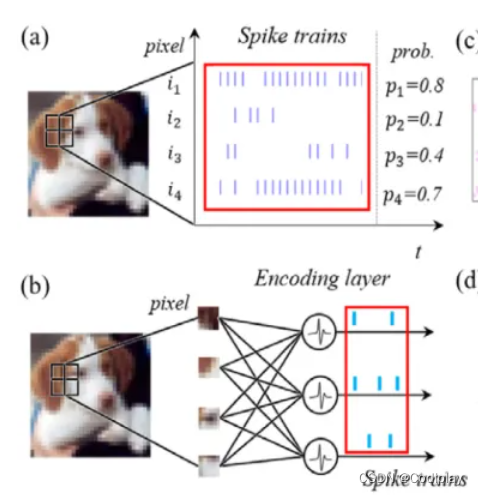
SNN编码方式 Image to spike pattern:
https://zhuanlan.zhihu.com/p/416187474
一种方法是:如 (a) 所示。在每一个时间步骤,采样的原始像素强度 (pixel intensity) 到一个二进制值 (通常归一化为[0,1]),其中的这个强度值就等于发射一个脉冲的概率。这个采样样遵循一个特定的概率分布,例如伯努利分布或泊松分布。
另一种方法是 (b) 所示。使用一个编码器来产生全局的脉冲信号。这个编码器的每个神经元接受图片多个像素的强度值intensity 信号作为输入, 而产生脉冲作为输出。 虽然编码层是 ANN-SNN 混合层,而不是像网络中的其他层那样的完整 SNN 层,但它的权重是可训练的,因为我们的训练方法也是 BP 兼容的。由于神经元的数量可以灵活定制,参数也可以调整,因此它可以适应整体最佳化问题,从而获得更高的精确度。
发放率与ANN的match
发放率在
[
0
,
1
]
[0,1]
[0,1]之间,与在
[
0
,
θ
]
[0, \theta]
[0,θ]没区别,就是乘了一个
θ
\theta
θ的区别
有一个需要讨论的点,就是
T
T
T(time duration),而resolution =
1
/
T
1/T
1/T,当
T
T
T越大的时候,分的越精细,可以分的份数越多
对于
A
N
N
ANN
ANN,最intuitive的想法就是找到
A
N
N
m
a
x
ANN_{max}
ANNmax然后以最大值这个区间平均分成
T
T
T份,每一份对应一个离散的
S
N
N
SNN
SNN值
BTW,其实可以看出这个思想和
A
N
N
t
o
Q
A
N
N
ANNtoQANN
ANNtoQANN完全一致,所以这个思路是很direct的
对于intuitive的想法有几个地方是可以改进的,第一是最大值的选择,第二是T的选择。
Spiking deep convolutional neural networks for energy-efficient object recognition
2015.开山之作
将脉冲和非脉冲网络之间的特征差异考虑了。主要挑战就是对于脉冲神经元中的负值和偏置的表示,这个通过使用修正的线性单元(ReLUs)和将偏置设为零解决了。同时,卷积网络的最大池化操作被空间线性子采样替代,同样地转换结果也有很小的损失。
本文的核心是通过三步tailor a regular CNN into an architecture that is suitable for spiking architecture:
- abs() + ReLU to solve negative output values
- No biases from all conv and FCL
- linear subsampling instead of maxpooling
spike generation:
归一化 I ,rand() < I, generate spikes
spike counter:
记录 output neurons in 100ms / 200ms
Fast-classifying, high-accuracy spiking deep networks through weight and threshold balancing
IJCNN.2015 ETH Zurich
写的很好的参考资料
- 这篇文章首次提出了造成误差的不发放(did not receive sufficient input)过发放问题(too many input spikes in one timestep / some of the input weights are higher than the threshold)。
- two weight normalizations to prevent the ReLU from overestimating output activations 在保证相对大小不变的情况下,使用缩放因子来防止出现过发放的问题。
对每一层:- worst-case scenario:rescale all the weights by that maximum possible positive input(理论上) (确实要用positive input,即一个neuron的sum input weight)
Q:
第二种方法为什么要这么做?没太看懂原理。
继承上篇论文并extension
the ReLU can be considered a firing rate approximation of an IF neuron with no refractory period [22], whereby the output of the ReLU is proportional to the number of spikes produced by an IF neuron within a given time window.
ReLU可以被看作没有绝对不应期的IF神经元的发射率近似,因此ReLU的输出应该和给定时间窗口内IF神经元发射的脉冲数量成比例
Secondly, for classification tasks, only the maximum activation of all units in the output layer is of importance, allowing the overall rate to be scaled by a constant factor.
对于分类任务,只有输出层中所有单元的最大激活是重要的,允许总体速率按一个常数因子进行缩放。
the relative scale of the neuron weights to each other and to the threshold of the neuron are the only parameters that matter
待训练的参数:在不偏向提供外部参考值的情况下,神经元权重之间的相对尺度和神经元阈值的相对尺度是唯一重要的参数
会造成误差的几种:
- For a fixed simulation duration,under-activation。
比如你的w很小,threshold很高,在短暂的t时间内没有一个neuron能积累到超过阈值 - For a fixed simulation duration,over-activation。
w太大,或者你threshold设置的太小,每次都发放。没有区分度。如果所有的都每次都发放,时间窗内有同样的两个类别产生的spike数量相同
该文章通过weight normalization来避免过发放 - 由于脉冲输入的概率属性,由于脉冲序列的不均匀性,一系列脉冲会过激活或者欠激活;
Theory and Tools for the Conversion of Analog to Spiking Convolutional Neural Networks
2016.11 ETH Zurich
“analog-to-digital conversion” 是指将模拟信号(如神经元的电压变化)转换为数字表示,以便计算机能够处理和分析
- 第一次理论证明conversion等效
- 分析误差,采取一定措施
- 修改CNN operations including max-pooling, softmax, and batch-normalization
Conversion of Continuous-Valued Deep Networks to Efficient Event-Driven Networks for Image Classification
2017.11 ETH Zurich
- a theoretical groundwork for ANN-SNN conversion
OPTIMAL CONVERSION OF CONVENTIONAL ARTIFICIAL NEURAL NETWORKS TO SPIKING NEURAL NETWORKS
Shikuang Deng1 & Shi Gu1 UESTC 2020
shift
QFFS
frontier 2022