- 博主简介:努力学习的22级计算机科学与技术本科生一枚🌸
- 博主主页: @是瑶瑶子啦
- 每日一言🌼: 你不能要求一片海洋,没有风暴,那不是海洋,是泥塘——毕淑敏
目录
- 一、核心
- 二、题目
一、核心
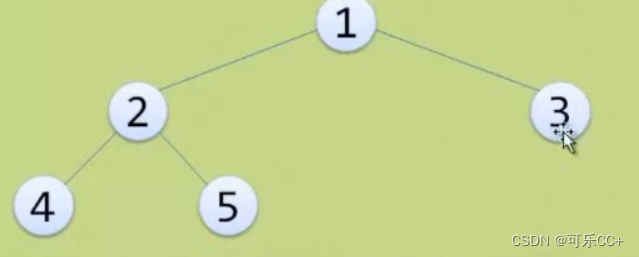
我们清楚,在二叉树的遍历中,通常有三个位置:
- 前序位置
- 中序位置
- 后序位置
今天我们来具体总结一下其中的两个位置:
- 🍊 前序:它能获得的信息:当前节点,但是不难获得左右节点(或者可以叫做子树的信息),一般大多数情况。
- 🍊后序:当前节点信息+左右子树信息。所以当一个二叉树的题目,在遍历的过程中不仅需要看遍历到的当前节点的信息时,还要看其子树的信息,那么通常要在后序位置上做文章,利用好递归函数的返回值——获取子树信息。—— 本质还是第二种二叉树问题:分解成子问题,利用好返回值
下面详细讲一个题目,来体会一下
二、题目
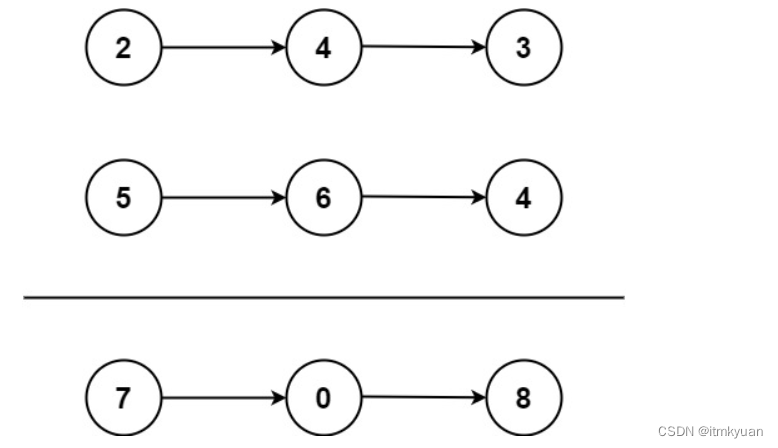
🔗652. 寻找重复的子树
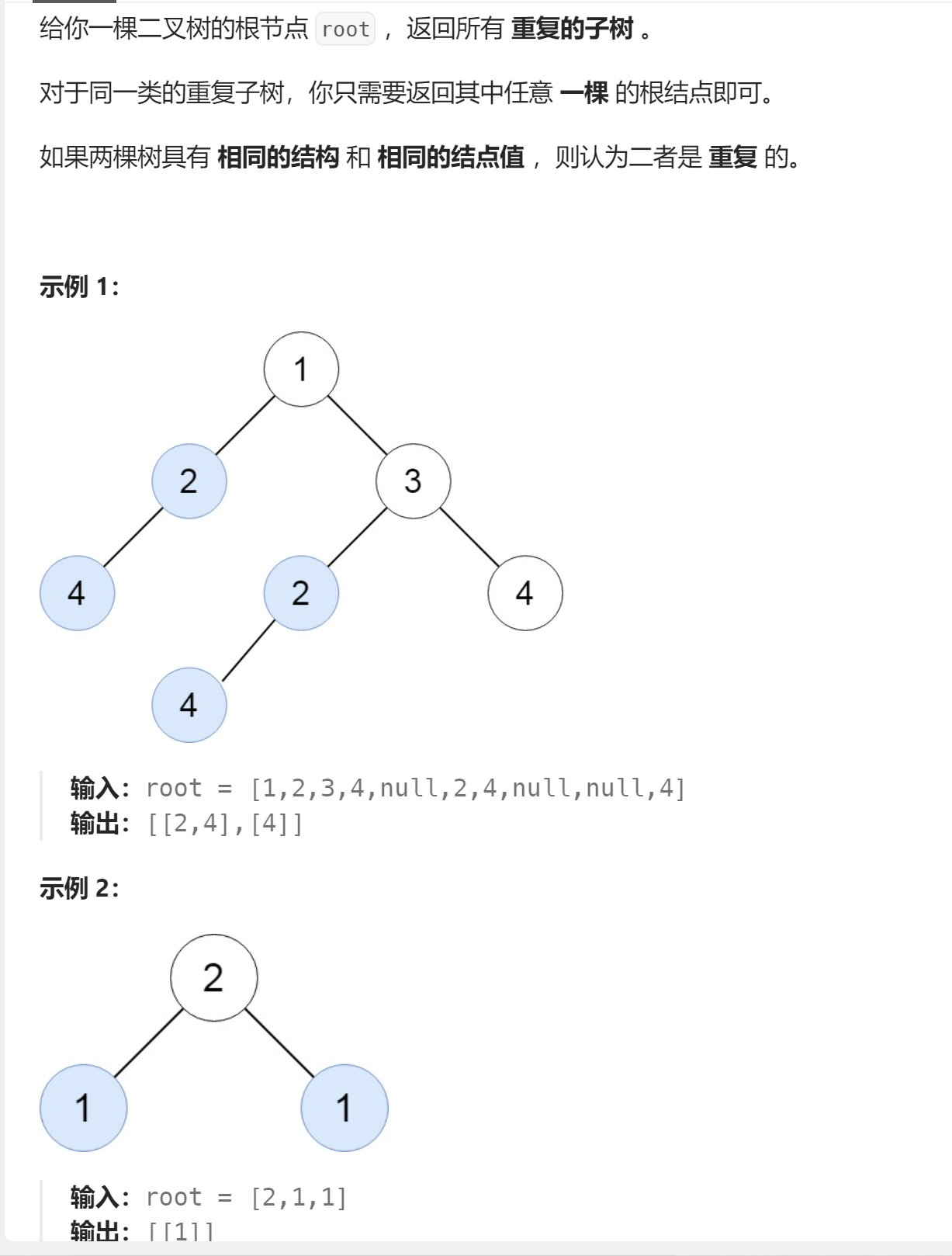
-
👧🏻思路:
- 首先,明确的是,这题的本质还是:遍历。因为每个节点为根就是一个子树,找重复子树,那么每个节点都要遍历到这是毋庸置疑的。⭐
- 遍历到了这个节点,我如何知道以这个节点为根的子树是什么样子的呢?——根节点+左右子树。这个时候只知道此时的根节点什么样子没什么用,关键是也要知道以它为根的左右子树什么样子。那么这个时候要在后序位置上做文章了。因为后序位置处于一个:既遍历到了根节点也遍历到了子树节点的一个位置,即:既有根节点信息,又有以此根节点为根的子树信息。⭐
- 其次,可以利用前面所讲的二叉树的序列化,以字符串的形式来把该二叉树存起来,再用字符串的哈希表来判断是否重复。
-
🙇🏻♀️代码:
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
Map<String, Integer> map = new HashMap<>(); //存储二叉树的序列化字符串,判断是否重复
List<TreeNode> ans = new ArrayList<>(); //存储答案,即:有重复子树的根节点
public List<TreeNode> findDuplicateSubtrees(TreeNode root) {
dfs(root); //遍历二叉树
return ans;
}
//这个遍历函数的作用:序列化一颗二叉树,返回序列化字符串(利用好返回值)
String dfs(TreeNode root){
if(root == null) return"#";
StringBuilder sb = new StringBuilder();
//前序位置
sb.append(root.val).append(",");
//中序
sb.append(dfs(root.left)).append(dfs(root.right));//获取左右子树信息
//后序位置
String key = sb.toString();//存储整个二叉树信息
map.put(key, map.getOrDefault(key, 0) + 1);
if(map.get(key) == 2) ans.add(root); //一旦超过2个。就add
return key;
}
}
💐若有疑问的地方,欢迎随时在评论区or私信找瑶瑶子交流讨论🌺

-
Java岛冒险记【从小白到大佬之路】
-
LeetCode每日一题–进击大厂
-
Go语言核心编程
-
算法