一、说明
在这篇博文中,我们分享了将 Netflix 大规模搜索和推荐系统的多个相关机器学习模型整合到一个统一模型中的系统设计经验。给定不同的推荐用例,许多推荐系统将每个用例视为单独的机器学习任务,并为每个任务训练定制的 ML 模型。相比之下,我们的方法从单个多任务机器学习模型中为多个用例生成建议。这不仅提高了模型性能,还简化了系统架构,从而提高了可维护性。此外,为搜索和建议构建通用的可扩展框架使我们能够更快地为新用例构建系统。我们描述了为实现这种整合所做的权衡,以及我们学到的可以普遍应用的经验教训。
二、背景

图 1:典型推荐系统中的多个用例
在电子商务、流媒体服务和社交媒体等大型现实世界推荐系统应用程序中,训练多个机器学习模型以优化系统不同部分的项目推荐。不同的用例有单独的模型,如通知(用户到项目的建议)、相关项目(基于项目到项目的建议)、搜索(查询到项目建议)和类别探索(类别到项目的建议)(图 1)。然而,这可能会迅速导致系统管理开销和维护大量专用模型的隐性技术债务(Sculley et al., 2015)。这种复杂性会导致长期成本增加,并降低 ML 系统的可靠性和有效性(Ehsan & Basillico,2022 年)。
图 2 显示了这种具有模型扩散的 ML 系统的外观。通知、相关项、搜索和类别探索等不同用例具有不同的 UI 画布,用户可以在其中与之交互。针对这些不同用例的 ML 系统通常会演变为具有多个离线管道,这些管道具有类似的步骤,例如标签生成、特征化和模型训练。在在线端,不同的模型可能托管在不同的服务中,具有不同的推理 API。但是,离线管道和在线基础结构中都存在许多共性,这种设计没有利用这些共性。

图 2:ML 系统中的模型扩散
在这篇博客中,我们描述了我们利用这些任务的共性来整合这些模型的离线和在线堆栈的努力。这种方法不仅减少了技术债务,而且通过利用从一个任务中获得的知识来改进另一个相关任务,从而提高了模型的有效性。此外,我们注意到在跨多个推荐任务有效实施创新更新方面的优势。
图 3 显示了整合的系统设计。在特定于用例的标签准备的初始步骤之后,我们统一了离线管道的其余部分并训练了单个多任务模型。在在线端,灵活的推理管道根据延迟、数据新鲜度和其他需求在不同环境中托管模型,并且模型通过统一的画布无关 API 公开。
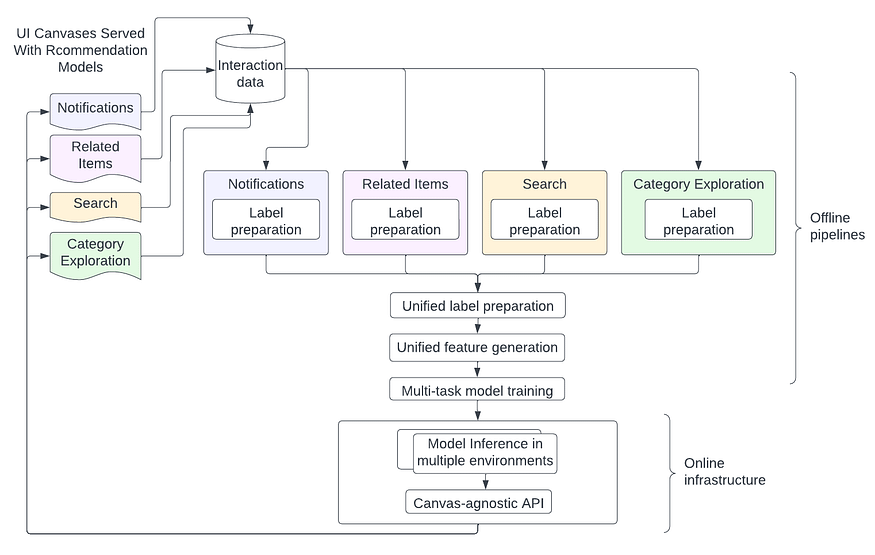
图 3:整合的 ML 系统
三、离线设计
在脱机模型训练管道中,每个建议任务都映射到需要显示建议的请求上下文。请求上下文架构因特定任务而异。例如,对于查询到项目建议,请求上下文将由查询、国家/地区和语言等元素组成。另一方面,对于逐项建议,请求上下文还将包括源项目和国家信息。请求上下文架构的组合是量身定制的,以适应每个建议任务的要求。
脱机管道从以下阶段记录的交互数据训练模型:
标签准备: 清理记录的交互数据并生成(request_context,标签)对。
特征提取:为上述生成的(request_context,标签)元组生成特征向量。
模型训练:基于(feature_vector,标签)行训练模型。
模型评估:使用适当的评估指标评估训练模型的性能。
部署: 使模型可用于在线投放。
对于模型整合,我们将统一请求上下文设置为跨任务的所有上下文元素的联合。对于特定任务,缺少或不必要的上下文值将替换为 sentinel(默认)值。我们引入了一个task_type分类变量作为统一请求上下文的一部分,以通知目标推荐任务的模型。
在标签准备中,来自每个画布的数据都会使用统一的请求上下文架构进行清理、分析和存储。然后将来自不同画布的标签数据与适当的分层合并在一起,以获得统一的标记数据集。在特征提取中,并非所有特征都包含某些任务的值,并使用适当的默认值填充。
四、在线设计
大规模提供单个 ML 模型会带来某些独特的在线 MLOps 挑战(Kreuzberger 等人,2022 年)。每个用例在以下方面可能有不同的要求:
- 延迟和吞吐量: 不同的服务级别协议 (SLA),以保证延迟和吞吐量目标,以提供最佳的最终用户体验。
- 可用性: 模型服务正常运行时间的不同保证,无需诉诸回退。
- 候选集:不同类型的项目(例如视频、游戏、人物等),可以根据特定于用例的业务需求进一步策划。
- 预算: 模型推理成本的不同预算目标。
- 业务逻辑: 不同的预处理和后处理逻辑。
从历史上看,特定于用例的模型会进行调整以满足独特的要求。核心在线 MLOps 挑战是支持各种用例,而不会在模型性能方面倒退到最低公分母。
我们通过以下方式应对这一挑战:
- 根据用例在不同的系统环境中部署相同的模型。每个环境都有“旋钮”来调整模型推理的特征,包括模型延迟、模型数据新鲜度和缓存策略以及模型执行并行性。
- 公开用于消费系统的通用、与用例无关的 API。为了实现这种灵活性,API 支持异构上下文输入(用户、视频、流派等)、异构候选选择(用户、视频、流派等)、超时配置和回退配置。
五、吸取的教训
将ML模型合并为单个模型可以被认为是软件重构的一种形式(Cinnéide等人,2016)。与软件重构类似,其中相关代码模块被重组和整合以消除冗余并提高可维护性,模型整合可以被认为是将不同的预测任务组合到单个模型中,并利用共享的知识和表示。这样做有几个好处。
5.1 减少代码和部署占用空间
支持新的 ML 模型需要在代码、数据和计算资源方面进行大量投资。设置训练管道以生成标签、功能、训练模型和管理部署非常复杂。维护此类管道需要不断升级底层软件框架并推出错误修复。模型整合是降低此类成本的重要杠杆。
5.2 提高可维护性
生产系统必须具有高可用性:必须快速检测和解决任何问题。ML 团队通常有随叫随到的轮换,以确保运营的连续性。单一的统一代码库使待命工作更轻松。好处包括几乎没有上下文切换,工作流的同质性,更少的故障点和更少的代码行。
5.3 将模型改进快速应用于多个画布
使用多任务模型构建整合的 ML 系统使我们能够将一个用例中的改进快速应用于其他用例。例如,如果针对特定用例尝试某个功能,则通用管道允许我们在其他用例中尝试该功能,而无需额外的管道工作。对于其他用例,需要权衡潜在的回归,因为为一个用例引入了功能。但是,在实践中,如果合并模型中的不同用例足够相关,则这不是问题。
5.4 更好的可扩展性
将多个用例整合到一个模型中需要灵活的设计,并在合并多个用例时要额外考虑。因此,这种基本的可扩展性使系统经得起未来的考验。例如,我们最初设计模型训练基础设施来整合一些用例。然而,事实证明,整合这些多个用例所需的灵活设计对于在同一基础设施上载入新模型训练用例是有效的。特别是,我们包含可变请求上下文模式的方法简化了使用相同的基础设施为新用例训练模型的过程。
六、结语
尽管 ML 系统整合不是灵丹妙药,可能并非适用于所有情况,但我们相信,在许多情况下,这种整合可以简化代码,允许更快的创新并提高系统的可维护性。我们的经验表明,合并对相似目标进行排名的模型会带来许多好处,但目前尚不清楚对目标进行排名完全不同且具有非常不同的输入特征的模型是否会从这种合并中受益。在未来的工作中,我们计划为何时最适合ML模型整合建立更具体的指导方针。最后,NLP 和建议的大型基础模型可能会对 ML 系统设计产生重大影响,并可能导致系统级别的更多整合。