几个nlp的小任务(生成式任务——语言模型(CLM与MLM))
news2026/2/11 19:03:50


本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/935773.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章

【AI底层逻辑】——篇章7(下):计算资源软件代码共享
续上篇... 目录
续上篇...
三、计算资源
1、第一阶段:数据大集中
2、第二阶段:资源云化
①“云”的分类
②虚拟化技术
③边缘计算的普及
四、软件代码共享
总结 往期精彩: 三、计算资源
AlphaGo算法论文虽然已经发表,但…

华为OD七日集训第2期 - 按算法分类,由易到难,循序渐进,玩转OD(文末送书)
目录 一、适合人群二、本期训练时间三、如何参加四、7日集训第2期五、精心挑选21道高频100分经典题目,作为入门。第1天、逻辑分析第2天、字符串处理第3天、数据结构第4天、递归回溯第5天、二分查找第6天、深度优先搜索dfs算法第7天、动态规划 六、集训总结1、《代码…

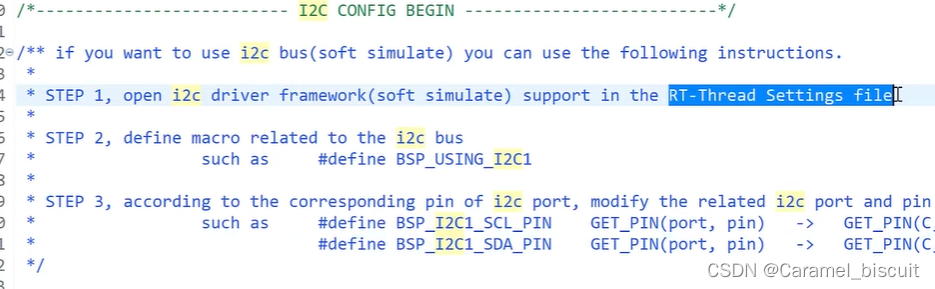
RT-Thread IO设备模型
IO设备模型
RTT提供了一套简单的I/O设备模型框架,它位于硬件和应用程序之间,共分成三层,从上到下分别是I/O设备管理层、设备驱动框架层、设备驱动层。 应用程序通过I/O设备管理接口获得正确的设备驱动,然后通过这个设备驱动与底层…

递归算法学习——全排列
目录
编辑
一,问题描述
1.例子:
题目接口: 二,问题分析和解决
1.问题分析
2.解题代码 一,问题描述 首先我们得来先看看全排列的问题描述。全排列问题的问题描述如下: 给定一个不含重复数字的数组 n…

DTC状态变化例子 4
例子1: 此示例概述了两个操作周期排放相关的 OBD DTC 中 DTC 状态位的操作。该图显示了两个操作周期排放相关的 OBD DTC 的处理。该处理也可应用于非排放相关的 OBD DTC,此处显示仅供一般参考。 0 接收到清除诊断信息 → DTC 状态字节初始化。 1, 2 相关…

基于类电磁机制算法优化的BP神经网络(预测应用) - 附代码
基于类电磁机制算法优化的BP神经网络(预测应用) - 附代码 文章目录 基于类电磁机制算法优化的BP神经网络(预测应用) - 附代码1.数据介绍2.类电磁机制优化BP神经网络2.1 BP神经网络参数设置2.2 类电磁机制算法应用 4.测试结果&…

RabbitMQ---订阅模型-Topic
订阅模型-Topic
• Topic类型的Exchange与Direct相比,都是可以根据RoutingKey把消息路由到不同的队列。只不过Topic类型Exchange可以让队列在绑定Routing key 的时候使用通配符! • Routingkey 一般都是有一个或多个单词组成,多个单词之间以…

【clojure】入门篇-01
一、环境的配置
1.java环境配置 clojureScript 需要java环境的配置需要下载jdk进行java环境变量配置 下载官网
java环境变量的配置教程
2.Leningen环境配置
1.下载.bat文件内容
2.配置环境变量
2.8.3及以上内容进行配置
lein教程
2.使用vscode
vscode官网
下载插件 C…

SIP 协议路由规则详解
文章目录 SIP 路由关键字段SIP 路由图解 SIP 路由关键字段
SIP 协议实际上和 HTTP 类似,都是基于文本、可阅读的应用层协议,二者的不同之处在于 SIP 协议是有状态的。在 SIP 协议中,影响报文路由的相关字段如下表所示,总结起来如…

给微软.Net runtime运行时提交的几个Issues
前言 因为目前从事的CLRJIT,所以会遇到一些非常底层的问题,比如涉及到微软的公共运行时和即时编译器或者AOT编译器的编译异常等情况,这里分享下自己提的几个Issues。原文:微软.Net runtime运行时提交的几个Issues Issues 一.issues one 第一个System.Numerics.Vecto…

深度强化学习。介绍。深度 Q 网络 (DQN) 算法
马库斯布赫霍尔茨 一. 引言 深度强化学习的起源是纯粹的强化学习,其中问题通常被框定为马尔可夫决策过程(MDP)。MDP 由一组状态 S 和操作 A 组成。状态之间的转换使用转移概率 P、奖励 R 和贴现因子 gamma 执行。概率转换P(系统动…

SaaS多租户系统架构设计
前言:多租户是SaaS(Software-as-a-Service)下的一个概念,意思为软件即服务,即通过网络提供软件服务。SaaS平台供应商将应用软件统一部署在自己的服务器上,客户可以根据工作的实际需求,通过互联网…
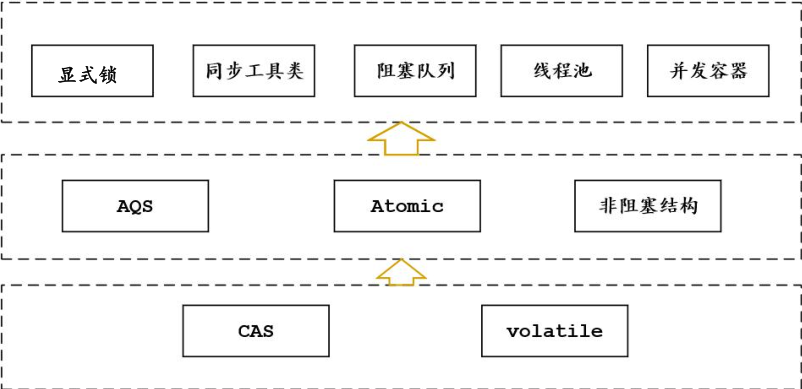
万字长文解析AQS抽象同步器核心原理(深入阅读AQS源码)
AQS抽象同步器核心原理
在争用激烈的场景下使用基于CAS自旋实现的轻量级锁有两个大的问题:
CAS恶性空自旋会浪费大量的CPU资源。在SMP架构的CPU上会导致“总线风暴”。
解决CAS恶性空自旋的有效方式之一是以空间换时间,较为常见的方案有两种ÿ…

ubuntu使用二进制安装mysql常见问题
一、安装mysql完毕后初始化失败
【/usr/local/mysql/bin】./mysqld --usermysql --basedir/usr/local/mysql --datadir/usr/local/mysql/data/ --initialize 输入命令:apt-get install libaio1 libaio-dev
二、初始化成功后重启服务失败
rootyanhong:/usr/local/…

4 hadoop集群配置案例
3)配置集群
(1)核心配置文件,core-site.xml
cd $HADOOP_HOME/etc/hadoopvim core-site.xml文件内容如下:
<?xml version"1.0" encoding"UTF-8"?>
<?xml-stylesheet type"text…
![java八股文面试[多线程]——并发三大特性 原子 可见 顺序](https://img-blog.csdnimg.cn/36c3a2a28bd74d2aa98429af4793c1ac.png)
java八股文面试[多线程]——并发三大特性 原子 可见 顺序
AutomicInteger : volatile CAS
总线LOCK MESI 两个协议 TODO volatile的可见性和禁止重排序是怎么实现的: DCL场景: new操作会在字节码层面生成两个步骤: 分配内存、调用构造器 然后把引用赋值给singleton
不加volatile则会发生指令重…

Windows下MATLAB调用Python函数操作说明
MATLAB与Python版本的兼容
具体可参看MATLAB与Python版本的兼容 操作说明
操作说明请参看下面两个链接:
操作指南 简单说明: 我安装的是MATLAB2022a和Python3.8.6(安装时请勾选所有可以勾选的,包括路径)。对应版本安…

基于闪电连接过程算法优化的BP神经网络(预测应用) - 附代码
基于闪电连接过程算法优化的BP神经网络(预测应用) - 附代码 文章目录 基于闪电连接过程算法优化的BP神经网络(预测应用) - 附代码1.数据介绍2.闪电连接过程优化BP神经网络2.1 BP神经网络参数设置2.2 闪电连接过程算法应用 4.测试结…

基于阿基米德优化算法优化的BP神经网络(预测应用) - 附代码
基于阿基米德优化算法优化的BP神经网络(预测应用) - 附代码 文章目录 基于阿基米德优化算法优化的BP神经网络(预测应用) - 附代码1.数据介绍2.阿基米德优化优化BP神经网络2.1 BP神经网络参数设置2.2 阿基米德优化算法应用 4.测试结…