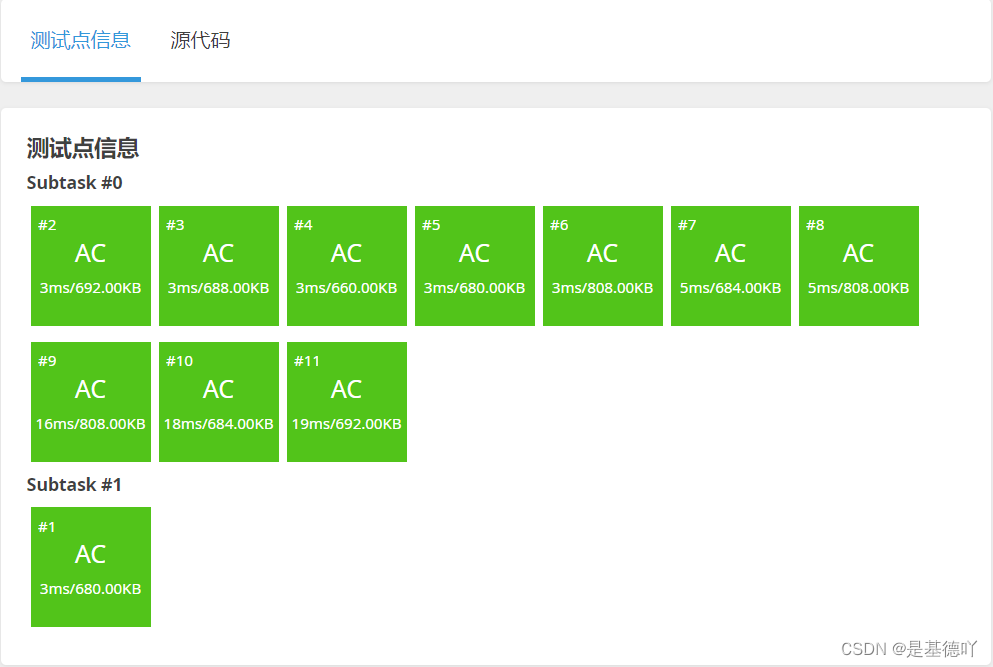
Kotlin开发笔记:协程基础

导语
本章内容与书的第十五章相关,主要介绍与协程相关的知识。总的来说,本文将会介绍Kotlin中关于异步编程的内容,主要就是与协程有关。在Kotlin中协程是利用continuations数据结构构建的,用于保存函数的内部状态,以便后续函数调用与使用。
并行与并发
首先我们要理清一个容易混淆的概念:并行与并发。说实话,我在看本章之前也没有对并行和并发的区别做了解,不过既然遇上了,还是好好弄清楚。
-
并发执行(Concurrency)是指在同一时间段内,多个任务交替执行,每个任务都在一小段时间内得到执行。这些任务可能在同一时间点上并不同时执行,但它们在整个时间段内以交替的方式执行,从外部观察看,它们似乎是同时执行的。并发通常用于提高资源利用率,使多个任务能够在有限资源下高效地执行。
-
并行执行(Parallelism)是指在同一时刻,多个任务同时执行,每个任务都在不同的处理器核心或计算资源上执行。这需要多核处理器或分布式计算环境,以同时执行多个任务。并行可以提高实际的计算速度,特别是对于需要大量计算的任务。
其实从外部来看,两者的区别不大–它们似乎都是同时进行的。但是实现的逻辑却完全不同,并发执行更像是弱化版的并行执行,它在一段时间内交替执行多个任务–这一点就像是Java中的多线程(在多核处理器上也可以实现并行执行)。而并行执行则是真正意义上的多个任务同时进行。
协程更多是用于并发执行而不是并行执行。
什么是协程
一般来说,我们的函数总是会有一个入口和一个出口。但是协程不同,虽然协程也是函数,但是协程有多个函数的入口,且其会记忆之前调用的状态,并且对协程的调用可以直接跳转到协程的中间,即它在上一次中断的地方。
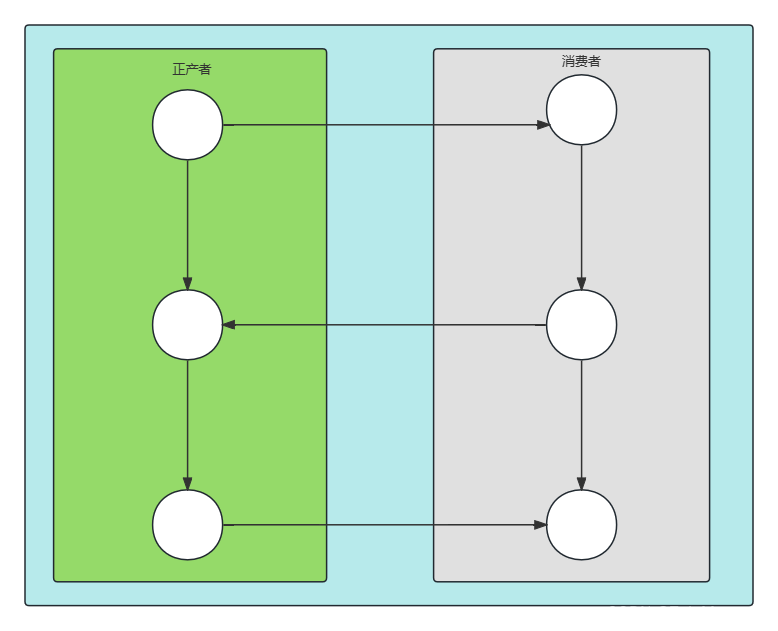
比如说上面这张图,白色的圆点代表的是函数的中断,箭头代表恢复函数的运行。通过两个函数的协作,这显然可以达到并发执行的效果,执行流也在它们之间进行切换。
首先,生产者协程调用消费者协程。在执行部分代码之后,消费者保存其当前状态,并返回或让步给调用方。生产者执行更多的步骤,并回调给消费者。然而这一次调用不是从起始处开始的,而是在上一次执行停止的地方恢复,并回复上一次调用的状态。
线程和协程
很显然线程和协程实现的效果可以说是类似,但显然线程和协程并不是一种东西。我倾向于把线程看做是代码的执行器,线程是计算机程序执行的最小单位,它负责执行程序中的代码指令。每个线程都有自己的执行上下文,包括程序计数器、寄存器、栈和状态等,这些上下文使得线程能够独立地执行指令序列。而协程则是利用数据结构实现的代码执行流。代码必须通过线程来执行但是协程会协助代码的执行,确保它们来交替执行,协程在底层就帮我们处理了线程间的切换,值的传递等工作。
所以会出现“同线程,不同协程”和“同协程,不同线程”的情况。
使用协程
协程需要一个使用场景,我们先来创建一个示例,之后再慢慢修改这个示例。让我们先从平常的顺序执行开始:
fun task1(){
println("start task1 in Thread ${Thread.currentThread()}")
println("end task1 in Thread ${Thread.currentThread()}")
}
fun task2(){
println("start task2 in Thread ${Thread.currentThread()}")
println("end task2 in Thread ${Thread.currentThread()}")
}
fun main() {
println("start")
run{
task1()
task2()
println("called task1 and task2 from ${Thread.currentThread()}")
}
println("done")
}
这就是一个简单的判断当前函数在哪个线程执行的函数,运行结果为:
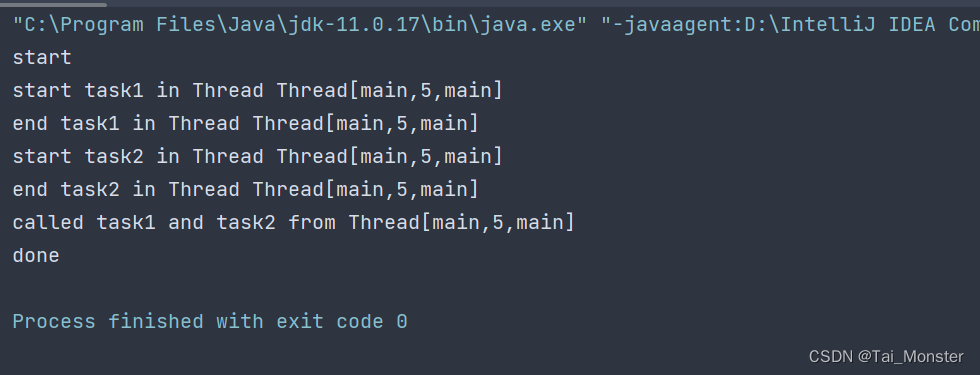
可以看到它按照我们的预期–顺序执行下来了,没有任何意外。
创建一个协程
这里书上引入了一个拓展库:kotlinx.coroutines,这个库包含便利函数和类来帮助我们使用协程进行编程,在使用前我们用Meaven导入依赖,然后引入类。最后将之前的run函数改为runBlocking函数:
fun main() {
println("start")
runBlocking{
task1()
task2()
println("called task1 and task2 from ${Thread.currentThread()}")
}
println("done")
}
这个函数接收一个lambda表达式,并在协程中执行该参数。然而最后输出的结果是和一开始一样的。区别就是lambda表达式中的参数并发执行了–在调用runBlocking之前的代码和代用该方法之后的代码并发执行了。不过这个runBlocking会阻塞当前的线程。
具体来说,协程需要在一个CoroutinesScope中启动,这个CoroutinesScope也可以看做是一个协程作用域,launch 是一个协程构建器,用于启动一个新的协程,并将其添加到指定的协程作用域中。协程作用域可以是 runBlocking、CoroutineScope、GlobalScope 或其他自定义的协程作用域。
其中比较特殊的就是GlobalScope,在 Kotlin 协程中,GlobalScope 是一个顶级协程作用域(Coroutine Scope),它是一个全局范围的协程作用域,可以用于在应用程序的整个生命周期中启动协程。
GlobalScope 是一个特殊的协程作用域,它不需要显式地创建,您可以直接在其内部启动协程。它的生命周期与应用程序的生命周期相对应。这意味着您可以在任何地方启动 GlobalScope 内的协程,而协程会在整个应用程序运行期间持续执行。
启动一个任务
在之前的代码中我们已经在协程中执行了task1和task2函数了,接下来我们再修改代码让task1和task2在不同的协程中执行。
fun main() {
println("start")
runBlocking{
launch{ task1() }
launch{ task2() }
println("called task1 and task2 from ${Thread.currentThread()}")
}
println("done")
}
launch函数启动一个新的协程来执行给定的lambda,不过和runBlocking不同的是launch函数将不会阻塞当前的线程。launch函数会返回一个作业(Job),该作业可以用于等待任务完成或者取消任务。我们来看这段新的代码的输出:
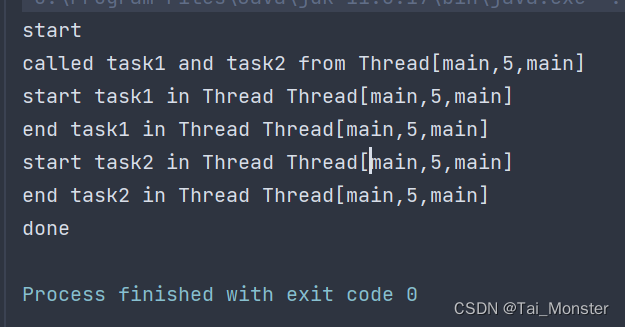
可以看到runBlocking最后第一句代码最先执行出来了,可见launch函数并没有阻塞其之后的代码。不过这里倒是没有打印出和协程相关的内容,这里我们打开协程的调试,具体就是在IDEA的VM Option中加入命令:-Dkotlinx.coroutines.debug即可
接下来输出:
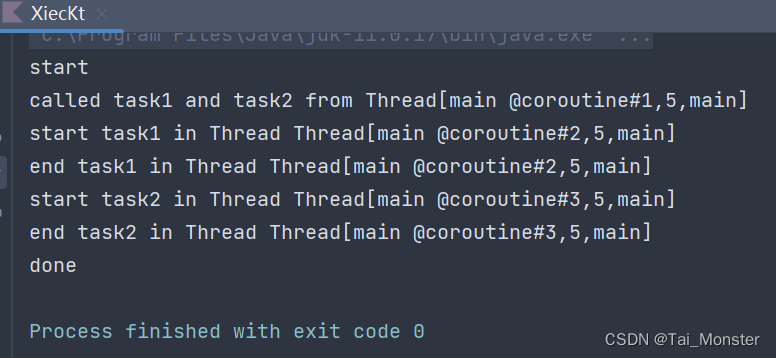
可以看到这里有了三个协程,分别是由runBlocking和两个launch启动的。
延阻函数
Kotlin中的协程库中带有挂起点–一个将挂起当前任务的执行而让另一个任务执行的函数。调用这样一个函数就像你在演讲时将麦克风递给一个同事,让他们说几句话。在kotlin中也有两个函数可以实现:delay函数和yield函数。
delay函数会将当前的任务暂停指定的毫秒数。yield函数则不会造成任何显式延迟,但是它会降低当前任务的优先级。
不过这两个方法都只能在延阻函数中使用,延阻函数就是需要加上suspend修饰的函数。不过使用suspend标记函数并不会自动使函数在协程中运行或者并发运行。
我们修改之前的函数:
suspend fun task1(){
println("start task1 in Thread ${Thread.currentThread()}")
yield()
println("end task1 in Thread ${Thread.currentThread()}")
}
suspend fun task2(){
println("start task2 in Thread ${Thread.currentThread()}")
yield()
println("end task2 in Thread ${Thread.currentThread()}")
}
fun main() {
println("start")
runBlocking{
launch{ task1() }
launch{ task2() }
println("called task1 and task2 from ${Thread.currentThread()}")
}
println("done")
}
这里我们在task1和task2函数中间加入了yield函数,这样理论上他们就会交替执行了,实际上的输出也是如此:
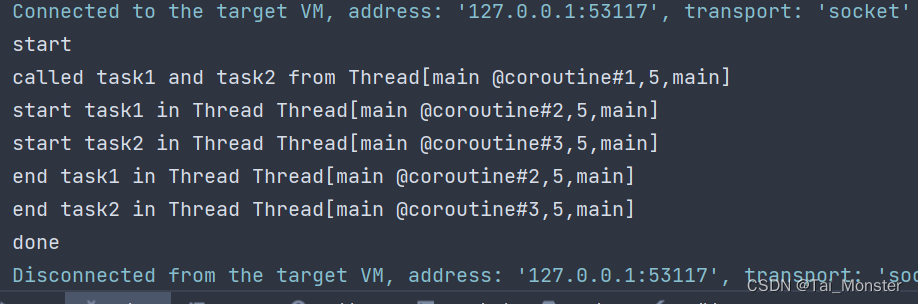
协程上下文和线程
协程在默认情况下会运行在和调用方相同的协程作用域的线程中执行。我们当然也可以设置协程的上下文和执行的线程。
显示设置上下文
launch函数和runBlocking函数可以接受一系列参数,其中就可以传递一个CoroutineContext来设置这些函数启动时的协程的执行上下文。其实也相当于给它指定了执行线程池。协程上下文包含一个协程调度器,它确定了相关的协程在哪个线程或哪些线程上执行。协程调度器可以将协程限制在一个特定的线程执行,或将它分派到一个线程池,亦或是让它不受限地运行。
所有的协程构建器诸如 launch 和 async 接收一个可选的 CoroutineContext 参数,它可以被用来显式的为一个新协程或其它上下文元素指定一个调度器。
这里有几种常见的调度器:
- Dispatchers.Default :在默认的线程池中开始执行的协程。这个池中的线程数为2或等于系统的核数,以较高者为准。此池用于计算密集型的任务。
- Dispathers.IO :可用于在专用于IO密集型任务的池中执行携程。如果线程在IO上阻塞,并且创建了更多任务,那么这个池的大小可能会增加。
- Dispathers.Main :可用于Android设备和Swing UI,来运行只从main线程更新UI的任务。
- Dispathers.Unconfined : 不受限的调度器。该协程调度器在调用它的线程启动了一个协程,但它仅仅只是运行到第一个挂起点。挂起后,它恢复线程中的协程,而这完全由被调用的挂起函数来决定。非受限的调度器非常适用于执行不消耗 CPU 时间的任务,以及不更新局限于特定线程的任何共享数据(如UI)的协程。
我们来修改上面代码来显式地设置调度器:
fun main() {
println("start")
runBlocking{
launch(Dispatchers.Default){ task1() }
launch{ task2() }
println("called task1 and task2 from ${Thread.currentThread()}")
}
println("done")
}
这里我们将task1运行在Default调度器中,其他代码不变,来看看输出:
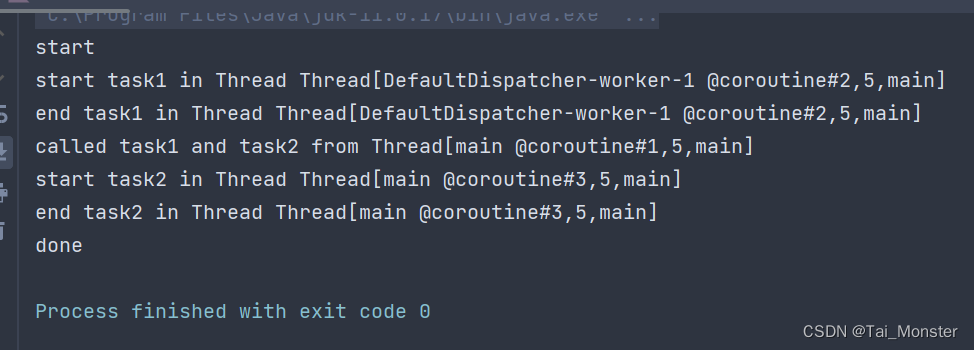
可以看到task1运行在了Default调度器中的线程中了,而其他代码还是运行在主线程中。
运行在自定义池中
既然可以运行在线程池中,那么我们也可以自己创建线程池来给协程使用。我们来创建一个单线程的线程池提供给协程使用。不过我们要将这个线程池包装成调度器,这里可以用asCoroutineDispatcher函数来将一个执行器转化为调度器。
同时还有一个问题,如果我们不关闭调度器,那么程序可能会一直运行下去。这是因为除了main之外,执行器池中还有一个活动线程,它将使JVM保持活动状态。这个时候可以用use函数,use函数会自动帮我们关闭调度器,类似于Java中的finally块。修改代码:
fun main() {
Executors.newSingleThreadExecutor().asCoroutineDispatcher().use { context ->
println("start")
runBlocking{
launch(context){ task1() }
launch{ task2() }
println("called task1 and task2 from ${Thread.currentThread()}")
}
println("done")
}
}
继续看输出结果:
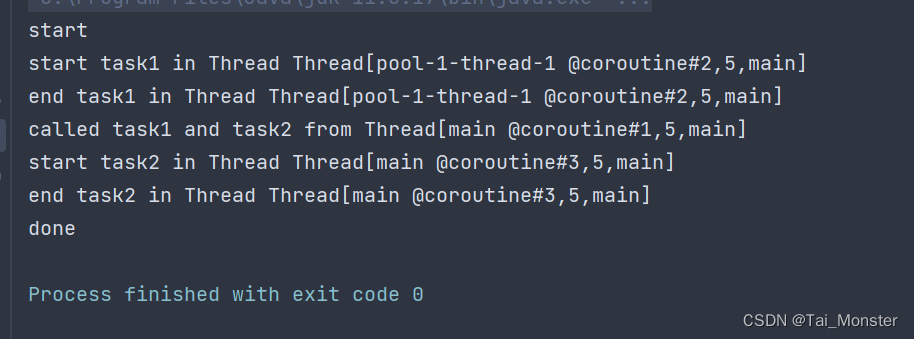
可以看到task1任务成功执行在了我们自己定义的线程池中。
在挂起点后切换线程
除了第一个参数之外,还有第二个参数,可以帮助我们在挂起点后切换线程。我们的第一个参数设置的是协程的上下文,通过第二个参数的设置我们可以指定协程的启动模式。
要在当前上下文中运行协程,可以将参数设置为DEFAULT。如果想要延迟计算可以设置为LAZY,知道调用显示的start才会计算。ATOMIC将以不可取消的模式启动。使用UNDISPATCHED来在最初的上下文上运行,但在挂起点之后切换线程。
这里我们为了切换线程,简单修改一下代码:
fun main() {
Executors.newSingleThreadExecutor().asCoroutineDispatcher().use { context ->
println("start")
runBlocking{
launch(context,CoroutineStart.UNDISPATCHED){ task1() }
launch(){ task2() }
println("called task1 and task2 from ${Thread.currentThread()}")
}
println("done")
}
}
输出结果为:
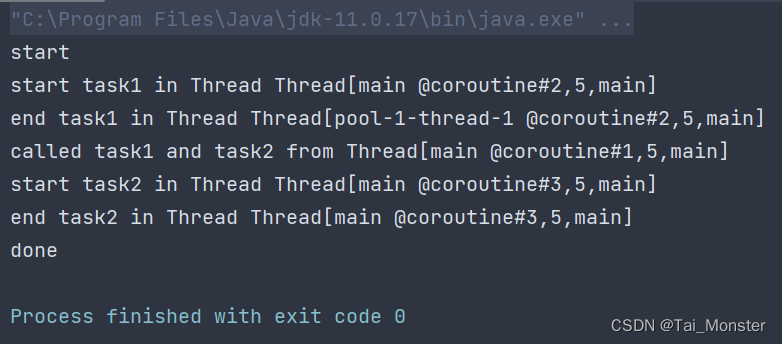
可以看到,task1函数最初会在main线程中启动,但是挂起后就会在指定的上下文中的线程中运行。这里最初的上下文是什么呢?可以看到task1是被包含在launch块中的,而launch块之前又是被包含在runBlocking块中的,这个runBlocking的上下文就是最初的上下文,显然runBlocking是运行在main线程中的,所以task1最初就会运行在main中,一旦挂起后又会运行在我们第一个参数指定的上下文线程中,也就是我们自己定义的线程池。这下就实现了切换运行线程的效果。
修改上下文
之前我们是通过start参数来实现切换线程的效果的,除了修改start参数之外,我们还可以通过修改上下文来实现这个效果。Kotlin中的withContext函数可以只去一部分代码,并在和前后不同的上下文中执行这部分代码。我们继续修改:
suspend fun task1(){
println("start task1 in Thread ${Thread.currentThread()}")
yield()
println("end task1 in Thread ${Thread.currentThread()}")
}
suspend fun task2(){
println("start task2 in Thread ${Thread.currentThread()}")
yield()
println("end task2 in Thread ${Thread.currentThread()}")
}
fun main() {
Executors.newSingleThreadExecutor().asCoroutineDispatcher().use { context ->
runBlocking{
println("starting in Thread ${Thread.currentThread()}")
withContext(Dispatchers.Default){ task1()}
launch { task2() }
}
println("ending in Thread ${Thread.currentThread()}")
}
}
看看输出:
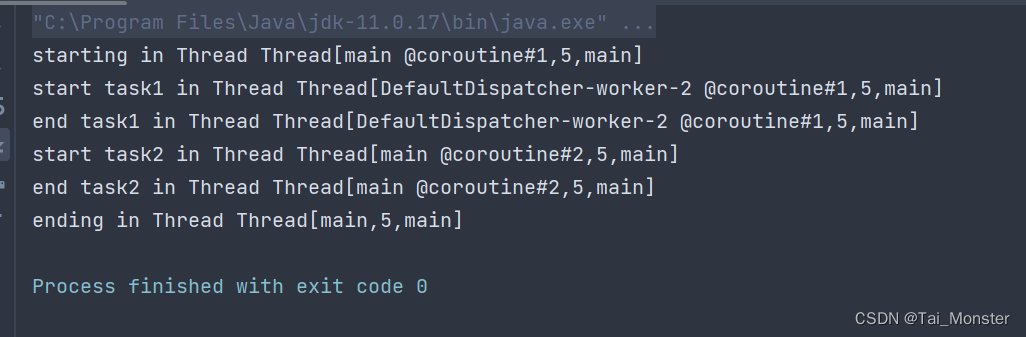
可以看到,task1的确是运行在了我们指定的线程池中,而且其他代码没有受到影响。而且看调试输出,这个withContext函数并没有启动新的协程。
async和await
接下来我们介绍一个和异步计算有关的函数–async,它和launch很类似。不同之处在于返回的东西,launch函数会返回一个Job对象,通过这个对象我们可以控制协程,但是我们无法通过Job来获得计算结果。而async接收的参数和launch一样,但是它可以返回计算的结果,就和Java中的Fature< T >差不多。async返回一个Deferred<T>未来对象,该对象除了其他方法外还有一个await方法,用于检查协程的状态,取消等。对await的调用会阻塞执行流,但不会阻塞线程,并且最后会活动启动协程的结果。我们接下来就通过这个async来计算计算机的核数:
fun main() {
runBlocking {
val ans = async(Dispatchers.Default) {
println("执行线程是 ${Thread.currentThread()}")
Runtime.getRuntime().availableProcessors()
}
println("当前线程是${Thread.currentThread()}")
println("计算机的核数是${ans.await()}")
}
}
这里最后一行的代码将会等待async块计算完成,所以这最后一句会被暂时阻塞直到计算完成。我们来看看输出:
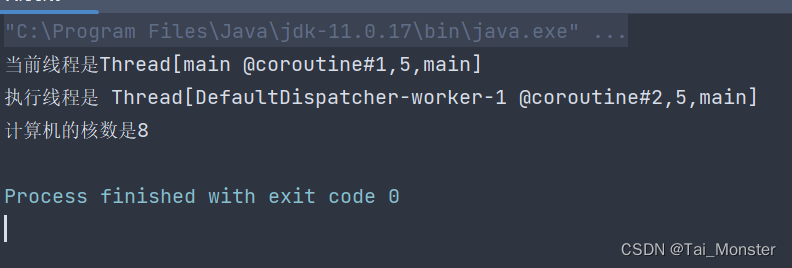
我们再来稍微修改下代码并输出:
fun main() {
runBlocking {
val ans = async(Dispatchers.Default) {
println("执行线程是 ${Thread.currentThread()}")
delay(1000)
Runtime.getRuntime().availableProcessors()
}
println("计算机的核数是${ans.await()}")
println("当前线程是${Thread.currentThread()}")
}
}
这里我们将计算机核数的这一句往前移动并且在async中延迟了1秒钟来模拟计算,可以猜一猜最后的输出是什么,正确答案是:
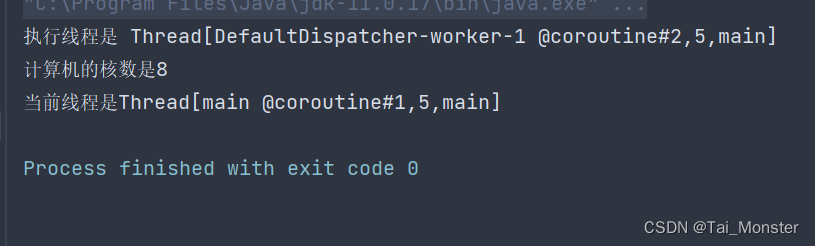
为什么会这样呢?首先创建了一个async协程,一般来说这个协程并不会立即执行,而是需要准备几秒。所以接下来就执行到了打印计算机核数的这一句。而这一句由于调用了await函数,所以会阻塞当前的协程,直到async计算完成。所以后面的打印当前线程这一句也会被阻塞。接下来async就准备完成然后启动了,所以首先打印的是执行线程这一句,然后计算完成打印计算机核数,最后解除阻塞打印当前线程。