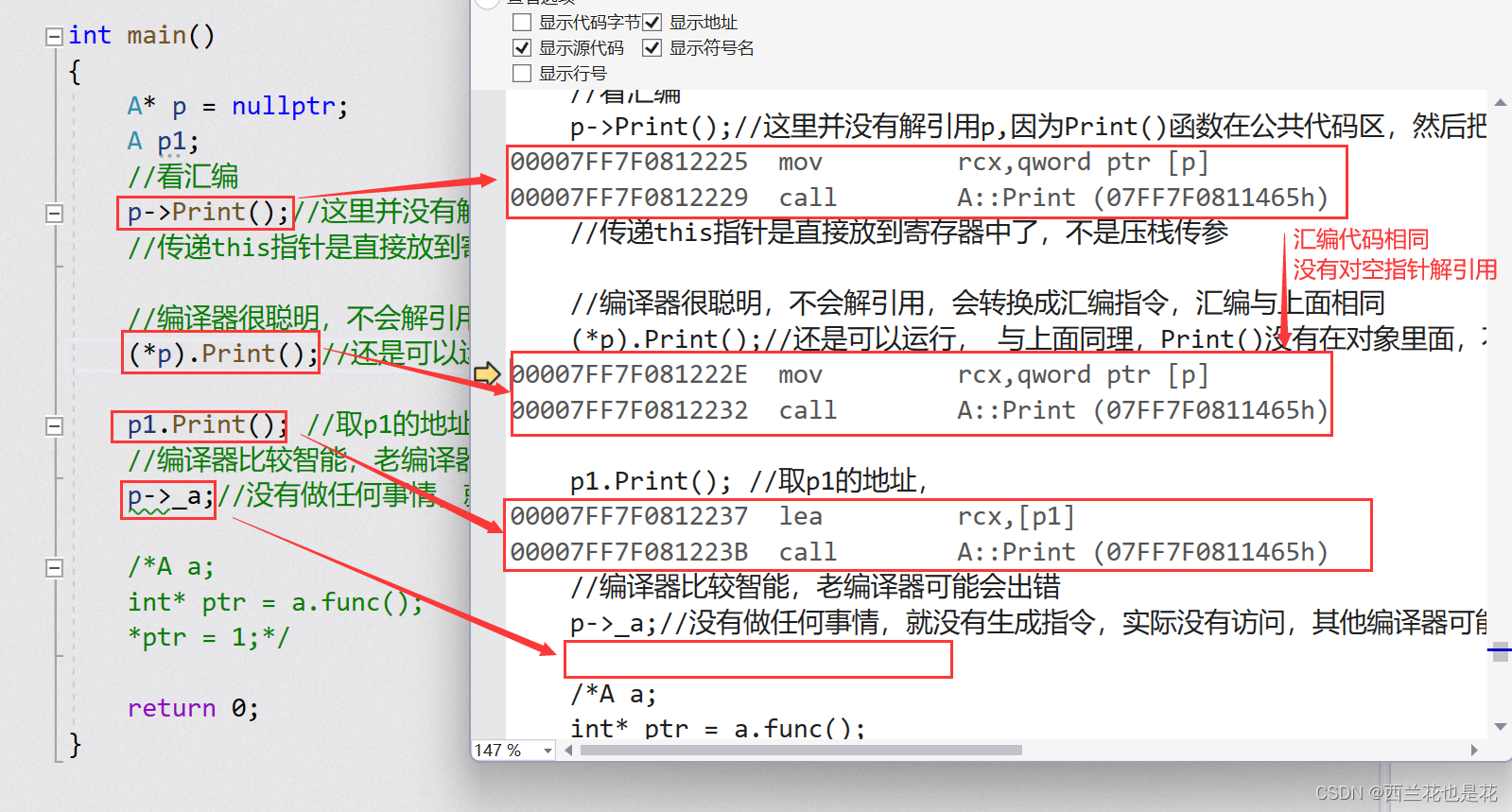
grep
grep主打的就是查找功能 ,它能够在一个或者多个文件中搜索某一特定的字符模式。
grep的语法
grep [选项] 模式 文件名
先说选项:
1.选项
要么是正则要么是字符串
-c 列出共出现多少次
-i 忽略大小写
-n 在前面列出行号
-v 列出没有匹配的 换句话说 反着来
-r 迭代
2. 模式
这里说白了就是写你要查的目标字符串 可以用“ ”隔开来构成字符串 当然也可以使用 正则表达式
sed
啥是sed?以我的理解就是以非交互的形式 对一个文件进行增删改查,所以我可以认为sed是一个行编辑器。
sed的原理
我们在使用之前要了解其原理的,它其实是将原数据拷贝到内存上处理,因此操作的结果是对原数据没有任何“伤害”的。
sed 的语法
sed [选项] '{command}[flags]' [filename]
那么我们先介绍内部命令也就是command部分的内容
1.command
这里其实可以叫做内部命令,我们将从增删改查的方向来进行讲解:
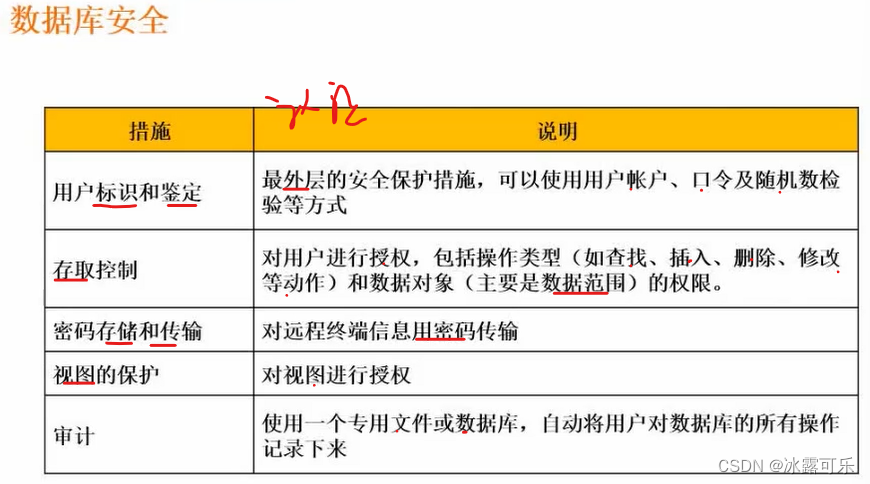
1.增
a + 要加的内容 (默认每行)
当然可以在a前面添加模糊匹配 形如 /^***/ 这样的字段 ***表示的是要模糊查询的目标字符
我们注意到了上图表达了 a 就是尾插 那肯定还有一个前插咯
i 代表的是 前插~~ 用法与上述类似
2.删
其关键字就是d

3.改
又分为替换、转换;
s:替换的意思就是将原字符串替换成一个新的字符串~~

将全部的student替换成boy了/g代表的就是全部 当然这是flag的内容
y: 转换是对字符就比如说

c:是全文改变
4.查
那就是 p
要注意的是直接使用p的话会重复打印 因为会打印俩部分 一是文本还有就是内存的也会被打印出来
2.选项
所有命令的选项都是对命令的增强
-e 植入多个命令 用;隔开
-f 调用写入文件里面的命令
-n 抑制内存输出
-r 正则表达式
-i 就是直接修改源文件了 而不是在内存上
当然这里要考虑到安全性 因此 基本上使用的是 -i.xxx 搞一个备份存储上去
3.标志(flag)
跟在command后面的做补充
数字 : 就代表第几个进行操作(可能会找到多个匹配的点)
g:全部
w:写入到...进行备份
p:打印输出
awk
是一种可以处理数据,产生格式化报表的语言
先搞懂 如何划分行列的:行区分(换行符) 列区分(一个/多个 空格 或者是tab制表符)
awk语法
awk [options] [BEGIN]{program}[END][FILENAME]
有几个要注意的点:一是命令需要用 ' ' 包起来,二是要有{}包裹program
接下来我将从 行截取 列截取分别讲解awk的基本应用
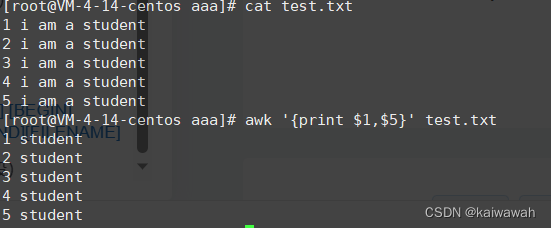
列截取(字段)
我们将数据的列称作字段,具体的截取规则如下
$0 代表的是整个文本
$N 代表第几列
$NF 代表了最后一列
当然了,这里应该是默认空格或者多个空格作为分割的,我们也可以自定义一下分隔符,也是选项中的内容了 -F "**" (**代表了自定义的分隔符)
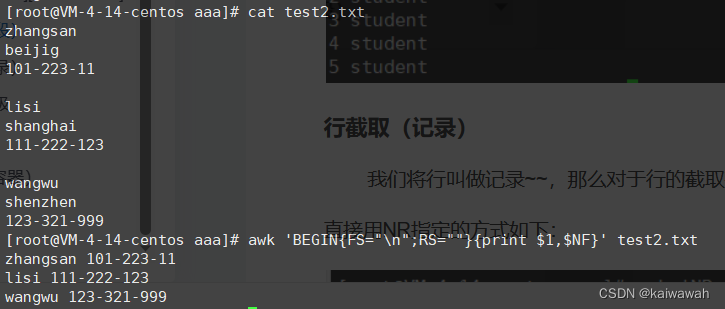
行截取(记录)
我们将行叫做记录~~,那么对于行的截取有俩种方式:1、正则表达式 2、NR指定行号
直接用NR指定的方式如下:
![]()
那么使用正则表达式的话:
![]()
以上内容既然有了行,列;我们就可以定义某个点咯~~
![]()
程序的优先级
在awk语法上面,我们注意到了有BEGIN END的这样子的字段,那么代表的啥呢?
BEGIN :处理数据源之前干什么 也就是说 不需要有数据源就可以执行了
PROGRAM :对数据源干了什么
END : 处理完数据源之后干了什么
注意到上面的命令中是没有数据源的。
高级应用
既然前面提到了awk是一门语言,那肯定有变量、运算了。
1.变量(容器)
说到容量,简单理解就是一个放在内存的临时容器,需要临时存储就放进去,需要用到就取出来。
![]()
当然还有数组了: ![]()
用法都差不多,不再赘述
2.运算
赋值运算 =
比较 > < >= <= ==
数学 + - * / %
逻辑 && || !
匹配 ~ !~ (模糊) == (精确)
![]()
![]()
0代表假..
环境变量
常见的内置变量:
FIELDWIDTHS 定义了字段的宽度(列与列之间的)
FS 相当于-F 可以自定义分隔符
OFS 输出想要呈现到屏幕上的分隔符
RS 那就是行分隔符咯
ORS 同理