如果我有一个32核心的服务器,我就可以实现1个亿的数据分片,我有32核心的服务器么?没有,所以我至今无法实现1个亿的数据分片。——MyCAT ‘s Plan
话说“每一个成功的男人背后都有一个女人”,自然MyCAT也逃脱不了这个诅咒,MyCAT背后是阿里曾经开源的知名产品——Cobar,核心功能和优势是MySQL数据库分片,此产品曾经广为流传,据说最早的发起者对Mysql很精通,后来从阿里跳槽了,阿里随后开源的Cobra,并维持到2013年年初,然后,就没有然后了。
Cobra的确做的很不错,基于Java,实现了MySQL二进制协议,因此可以将自己伪装成一个MySQL Server,并且很多MySQL客户端都能访问,这个做法很好,比自己实现一个新的数据库协议要明智的多,因为生态环境在哪里摆着。
由于是Java开发的,下载下来解压,只要配置几个不是很复杂的配置文件,猛击鼠标,就能启动Cobra,因此这个开源产品赢得了很多Java粉丝的追捧,当然,笨人也跟着进入,并且在某个大型云项目中——“苦海无边”的煎熬过。
爱情就像是见鬼,你根本不知道鬼是怎样的,只有撞见鬼以后,你才真正明白,什么是爱情。爱情也会很快褪色,你不会告诉TA你不好的地方,你会拼命将你的优点无限放大,就差把自己当成世界上第二伟大的人了。相信每个用过Cobra的人都经历了这样的过程,围城里的人已经出不来了,但还有更多的人拼命想挤进来。
仅以此文,献给哪些努力在IT界寻求未来的精英们以及小白们,还有更多被无视的,就差要打算转行的同仁人,同在江湖混,不容易啊,面试时候就装装糊涂,放人家一马,说不定,以后又是一个Made in China的乔布斯啊。
关于Cobra的十个秘密
第一个秘密:纳尼,Cobra会假死?
Cobra的确会假死,很多人遇到这个问题,如何简单的来验证这点呢?我们来做个小实验,假如你的分片表中配置有表company,则打开mysql终端,执行下面的SQL:
select sleep(500) from company;此SQL会执行等待500秒,你再努力以最快的速度打开N个mysql终端,都执行相同的SQL,确保N>当前Cobra的执行线程数:show @@threadpool的所有Processor1-E的线程池的线程数量总和,然后你再执行任何简单的SQL,或者试图新建立连接,都会无法响应,此时show @@threadpool里面看到TASK_QUEUE_SIZE已经在积压中。
不可能吧,据说Cobra是NIO的非阻塞的,怎么可能阻塞!别激动,去看看代码,Cobra前端是NIO的,而后端跟Mysql的交互,是阻塞模式,其NIO代码只给出了框架,还未来得及实现。真相永远在代码里,所以,为了发现真相,还是转行去做码农吧,貌似码农也像之前的技术工人,越来越稀罕了。
第二个秘密:高可用的陷阱?
每一个秘密的背后,总是隐藏着更大的秘密。Cobra假死的的秘密背后,还隐藏着一个更为“强大”的秘密,那就是假死以后,Cobra的频繁主从切换问题。我们看看Cobra的一个很好的优点——“高可用性”的实现机制,下图解释了Cobra如何实现高可用性:
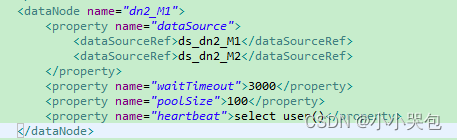
分片节点dn2_M1配置了两个dataSource,并且配置了心跳检测(heartbeat)语句,在这种配置下,每个dataNode会定期对当前正在使用的dataSource执行心跳检测,默认是第一个,频率是10秒钟一次,当心跳检测失败以后,会自动切换到第二个dataSource上进行读写,假如Cobra发生了假死,则在假死的1分钟内,Cobra会自动切换到第二个节点上,因为假死的缘故,第二个节点的心跳检测也超时。于是,1分钟内Cobra频繁来回切换,懂得MySQL主从复制机制的人都知道,在两个节点上都执行写操作意味着什么?——可能数据一致性被破坏,谁也不知道那个机器上的数据是最新的。
还有什么情况下,会导致心跳检测失败呢?这是一个不得不说的秘密:当后端数据库达到最大连接后,会对新建连接全部拒绝,此时,Cobar的心跳检测所建立的新连接也会被拒绝,于是,心跳检测失败,于是,一切都悄悄的发生了。
幸好,大多数同学都没有配置高可用性,或者还不了解此特性,因此,这个秘密,一直在安全的沉睡。
第三个秘密:看上去很美的自动切换
Cobar很诱人的一个特性是高可用性,高可用性的原理是数据节点DataNode配置引用两个DataSource,并做心跳检测,当第一个DataSource心跳检测失败后,Cobar自动切换到第二个节点,当第二个节点失败以后,又自动切换回第一个节点,一切看起来很美,无人值守,几乎没有宕机时间。
在真实的生产环境中,我们通常会用至少两个Cobar实例组成负载均衡,前端用硬件或者HAProxy这样的负载均衡组件,防止单点故障,这样一来,即使某个Cobar实例死了,还有另外一台接手,某个Mysql节点死了,切换到备节点继续,至此,一切看起来依然很美,喝着咖啡,听着音乐,领导视察,你微笑着点头——No problem,Everything is OK!直到有一天,某个Cobar实例果然如你所愿的死了,不管是假死还是真死,你按照早已做好的应急方案,优雅的做了一个不是很艰难的决定——重启那个故障节点,然后继续喝着咖啡,听着音乐,轻松写好故障处理报告发给领导,然后又度过了美好的一天。
你忽然被深夜一个电话给惊醒,你来不及发火,因为你的直觉告诉你,这个问题很严重,大量的订单数据发生错误很可能是昨天重启cobar导致的数据库发生奇怪的问题。你努力排查了几个小时,终于发现,主备两个库都在同时写数据,主备同步失败,你根本不知道那个库是最新数据,紧急情况下,你做了一个很英明的决定,停止昨天故障的那个cobar实例,然后你花了3个通宵,解决了数据问题。
这个陷阱的代价太高,不知道有多少同学中枪过,反正我也是躺着中枪过了。若你还不清楚为何会产生这个陷阱,现在我来告诉你:
- Cobar启动的时候,会用默认第一个Datasource进行数据读写操作
- 当第一个Datasource心跳检测失败,会切换到第二个Datasource
- 若有两个以上的Cobar实例做集群,当发生节点切换以后,你若重启其中任何一台Cobar,就完美调入陷阱
那么,怎么避免这个陷阱?目前只有一个办法,节点切换以后,尽快找个合适的时间,全部集群都同时重启,避免隐患。为何是重启而不是用节点切换的命令去切换?想象一下32个分片的数据库,要多少次切换?
MyCAT怎么解决这个问题的?很简单,节点切换以后,记录一个properties文件( conf目录下),重启的时候,读取里面的节点index,真正实现了无故障无隐患的高可用性。
第四个秘密:只实现了一半的NIO
NIO技术用作JAVA服务器编程的技术标准,已经是不容置疑的业界常规做法,若一个Java程序员,没听说过NIO,都不好意思说自己是Java人。所以Cobar采用NIO技术并不意外,但意外的是,只用了一半。
Cobar本质上是一个“数据库路由器”,客户端连接到Cobar,发生SQL语句,Cobar再将SQL语句通过后端与MySQL的通讯接口Socket发出去,然后将结果返回给客户端的Socket中。下面给出了SQL执行过程简要逻辑:
SQL->FrontConnection->Cobar->MySQLChanel->MySQL
FrontConnection 实现了NIO通讯,但MySQLChanel则是同步的IO通讯,原因很简单,指令比较复杂,NIO实现有难度,容易有BUG。后来最新版本Cobar尝试了将后端也NIO化,大概实现了80%的样子,但没有完成,也存在缺陷。
由于前端NIO,后端BIO,于是另一个有趣的设计产生了——两个线程池,前端NIO部分一个线程池,后端BIO部分一个线程池。各自相互不干扰,但这个设计的结果,导致了线程的浪费,也对性能调优带来很大的困难。
由于后端是BIO,所以,也是Cobar吞吐量无法太高、另外也是其假死的根源。
MyCAT在Cobar的基础上,完成了彻底的NIO通讯,并且合并了两个线程池,这是很大一个提升。从1.1版本开始,MyCAT则彻底用了JDK7的AIO,有一个重要提升。
第五个秘密:阻塞、又见阻塞
Cobar本质上类似一个交换机,将后端Mysql 的返回结果数据经过加工后再写入前端连接并返回,于是前后端连接都存在一个“写队列”用作缓冲,后端返回的数据发到前端连接FrontConnection的写队列中排队等待被发送,而通常情况下,后端写入的的速度要大于前端消费的速度,在跨分片查询的情况下,这个现象更为明显,于是写线程就在这里又一次被阻塞。
解决办法有两个,增大每个前端连接的“写队列”长度,减少阻塞出现的情况,但此办法只是将问题抛给了使用者,要是使用者能够知道这个写队列的默认值小了,然后根据情况进行手动尝试调整也行,但Cobar的代码中并没有把这个问题暴露出来,比如写一个告警日志,队列满了,建议增大队列数。于是绝大多数情况下,大家就默默的排队阻塞,无人知晓。
MyCAT解决此问题的方式则更加人性化,首先将原先数组模式的固定长度的队列改为链表模式,无限制,并且并发性更好,此外,为了让用户知道是否队列过长了(一般是因为SQL结果集返回太多,比如1万条记录),当超过指定阀值(可配)后,会产生一个告警日志。
<system><property name="frontWriteQueueSize">1024</property></system>第六个秘密:又爱又恨的SQL 批处理模式
正如一枚硬币的正反面无法分离,一块磁石怎样切割都有南北极,爱情中也一样,爱与恨总是纠缠着,无法理顺,而Cobar的 SQL 批处理模式,也恰好是这样一个令人又爱又恨的个性。
通常的SQL 批处理,是将一批SQL作为一个处理单元,一次性提交给数据库,数据库顺序处理完以后,再返回处理结果,这个特性对于数据批量插入来说,性能提升很大,因此也被普遍应用。JDBC的代码通常如下:
String sql = "insert into travelrecord (id,user_id,traveldate,fee,days) values(?,?,?,?,?)";
ps = con.prepareStatement(sql);
for (Map<String, String> map : list) {
ps.setLong(1, Long.parseLong(map.get("id")));
ps.setString(2, (String) map.get("user_id"));
ps.setString(3, (String) map.get("traveldate"));
ps.setString(4, (String) map.get("fee"));
ps.setString(5, (String) map.get("days"));
ps.addBatch();
}
ps.executeBatch();
con.commit();
ps.clearBatch();但Cobar的批处理模式的实现,则有几个地方是与传统不同的:
- 提交到cobar的批处理中的每一条SQL都是单独的数据库连接来执行的
- 批处理中的SQL并发执行
并发多连接同时执行,则意味着Batch执行速度的提升,这是让人惊喜的一个特性,但单独的数据库连接并发执行,则又带来一个意外的副作用,即事务跨连接了,若一部分事务提交成功,而另一部分失败,则导致脏数据问题。看到这里,你是该“爱”呢还是该“恨”?
先不用急着下结论,我们继续看看Cobar的逻辑,SQL并发执行,其实也是依次获取独立连接并执行,因此还是有稍微的时间差,若某一条失败了,则cobar会在会话中标记”事务失败,需要回滚“,下一个没执行的SQL就抛出异常并跳过执行,客户端就捕获到异常,并执行rollback,回滚事务。绝大多数情况下,数据库正常运行,此刻没有宕机,因此事务还是完整保证了,但万一恰好在某个SQL commit指令的时候宕机,于是杯具了,部分事务没有完成,数据没写入。但这个概率有多大呢?一条insert insert 语句执行commit指令的时间假如是50毫秒,100条同时提交,最长跨越时间是5000毫秒,即5秒中,而这个C指令的时间占据程序整个插入逻辑的时间的最多20%,假如程序批量插入的执行时间占整个时间的20%(已经很大比例了),那就是20%×20%=4%的概率,假如机器的可靠性是99.9%,则遇到失败的概率是0.1%×4%=十万分之四。十万分之四,意味着99.996%的可靠性,亲,可以放心了么?
另外一个问题,即批量执行的SQL,通常都是insert的,插入成功就OK,失败的怎么办?通常会记录日志,重新找机会再插入,因此建议主键是能日志记录的,用于判断数据是否已经插入。
最后,假如真要多个SQL使用同一个后端MYSQL连接并保持事务怎么办?就采用通常的事务模式,单条执行SQL,这个过程中,Cobar会采用Session中上次用过的物理连接执行下一个SQL语句,因此,整个过程是与通常的事务模式完全一致。
线程池:一个连接要在可用之前,做如下同步指令:
12:34:37.044 DEBUG [Processor1-E3] (MySQLConnection.java:325) -org.opencloudb.mysql.nio.MySQLConnection$StatusSync@15aaf0b3
need syn schemaCmd MySQL Command Packet{length=0,id=0}
need syn charCmd MySQL Command Packet{length=0,id=0}
need syn txIsolationCmd MySQL Command Packet{length=0,id=0}
need syn autcommitCmd MySQL Command Packet{length=0,id=0}后端物理连接是有限的,只能一个线程使用,因此,最佳的连接池,是 基于DB Server的,而不是基于DB Server的的某一个database上,另外,为了最有效的获取一个“合适的连接”,需要判断某个空闲连接的上述4个指令是否与想要得到的连接的请求参数“最大匹配”,目前没有研究过开源的其他Java连接池是否有此功效,Mycat中目前已经按照此策略,进行了最大可能的优化