背景
随着信息化程度的不断提高,企业内部系统的数量和复杂度不断增加,因此,数据库系统的同步问题已成为越来越重要的问题。
缓存失效
在缓存中缓存的条目(entry)在源头被更改或者被删除的时候立即让缓存中的条目失效。如果缓存在一个独立的进程中运行(例如Redis,Memcache),那么简单的缓存失效逻辑可以放在独立的进程或服务中,从而简化主应用的逻辑。在一些场景中,缓存失效逻辑可以更复杂一点,让它利用更改事件中的更新数据去更新缓存中受影响的条目。
简化单体应用
许多应用更新数据库,然后在数据库中的更改被提交后,做一些额外的工作:更新搜索索引,更新缓存,发送通知,运行业务逻辑,等等。这种情况通常称为双写(dual-writes),因为应用没有在一个事务内写多个系统。这样不仅应用逻辑复杂难以维护,而且双写容易丢失数据或者在一些系统更新成功而另一些系统没有更新成功的时候造成不同系统之间的状态不一致。使用捕获更改数据技术(change data capture,CDC),在源数据库的数据更改提交后,这些额外的工作可以被放在独立的线程或者进程(服务)中完成。这种实现方式的容错性更好,不会丢失事件,容易扩展,并且更容易支持升级。
共享数据库
当多个应用共用同一个数据库的时候,一个应用提交的更改通常要被另一个应用感知到。一种实现方式是使用消息总线,尽管非事务性的消息总线总会受上面提到的双写影响。但是,另一种实现方式,变得很直接:每个应用可以直接监控数据库的更改,并且响应更改。
数据集成
数据通常被存储在多个地方,尤其是当数据被用于不同的目的的时候,会有不同的形式。保持多系统的同步是很有挑战性的,但是可以通过使用数据同步工具加上简单的事件处理逻辑来实现简单的ETL类型的解决方案。
命令查询职责分离
在命令查询职责分离 [Command Query Responsibility Separation (CQRS)]架构模式中,更新数据使用了一种数据模型,读数据使用了一种或者多种数据模型。由于数据更改被记录在更新侧(update-side),这些更改将被处理以更新各种读展示。所以CQRS应用通常更复杂,尤其是他们需要保证可靠性和全序(totally-ordered)处理。Debezium和CDC可以使这种方式更可行:写操作被正常记录,但是Debezium捕获数据更改,并且持久化到全序流里,然后供那些需要异步更新只读视图的服务消费。写侧(write-side)表可以表示面向领域的实体(domain-oriented entities),或者当CQRS和 Event Sourcing 结合的时候,写侧表仅仅用做追加操作命令事件的日志。
Flink CDC
CDC Connectors for Apache Flink 是Apache Flink的一组源连接器,使用变更数据捕获 (CDC) 从不同数据库中获取变更。Apache Flink ®的 CDC Connectors集成 Debezium 作为捕获数据更改的引擎。所以它可以充分发挥 Debezium 的能力。
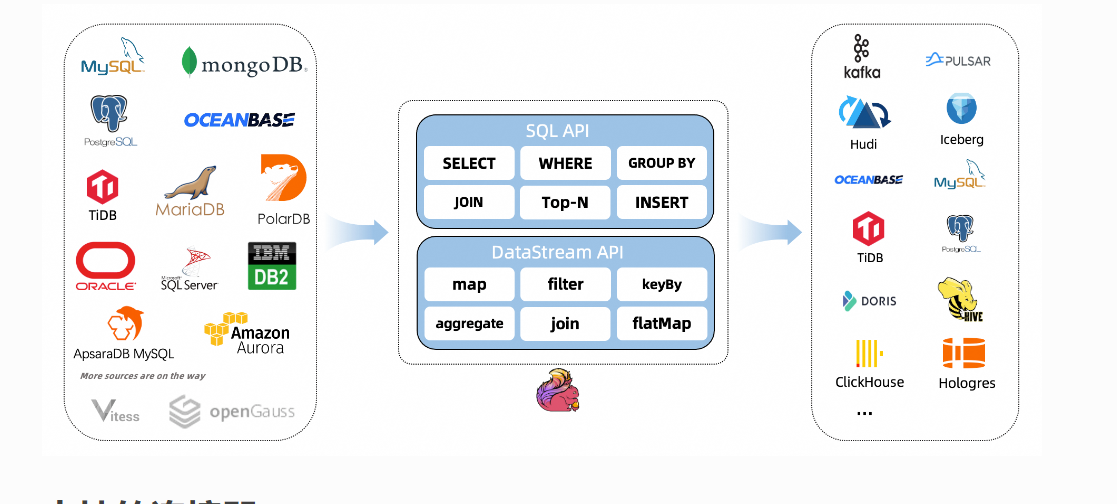
数据抓取
FlinkCDC 使用 MySQL 的 binlog 技术进行数据抓取。binlog 是 MySQL 用于记录数据库变更操作的日志,包括对表的增删改操作。FlinkCDC 通过对 binlog 进行解析和读取,得到最新的增量数据,并将其转换为 Flink 支持的数据格式,如 Avro 或 JSON。
如下代码可以帮我们监听数据库的变更日志:
JdbcIncrementalSource<String> oracleChangeEventSource =
new OracleSourceBuilder()
.hostname("host")
.port(1521)
.databaseList("XE")
.schemaList("DEBEZIUM")
.tableList("DEBEZIUM.PRODUCTS")
.username("username")
.password("password")
.deserializer(new JsonDebeziumDeserializationSchema())
.includeSchemaChanges(true) // output the schema changes as well
.startupOptions(StartupOptions.initial())
.debeziumProperties(debeziumProperties)
.splitSize(2)
.build();
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// enable checkpoint
env.enableCheckpointing(3000L);
// set the source parallelism to 4
env.fromSource(
oracleChangeEventSource,
WatermarkStrategy.noWatermarks(),
"OracleParallelSource")
.setParallelism(4)
.print()
.setParallelism(1);
env.execute("Print Oracle Snapshot + RedoLog");
数据同步
FlinkCDC 将抓取到的增量数据同步到 Flink 或者其他的计算引擎中进行处理。同步方式有两种:
pull 模式:FlinkCDC 在启动时会向 MySQL 中的某个位置开始读取 binlog,然后通过一个 HTTP 接口将增量数据暴露给 Flink。Flink 每隔一段时间就会调用该接口拉取增量数据。
push 模式:FlinkCDC 将增量数据通过一个 Kafka Topic 推送给 Flink。Flink 在消费 Kafka Topic 时,就可以直接消费到增量数据。
监听到数据变动,能拿到变更前后的数据对比,经过Sink数据转换成相应的INSERT、UPDATE、DELETE等相关SQL语句,并同步到目标数据库。
public class CustomSink extends RichSinkFunction<String> {
@Override
public void invoke(String value, Context context) throws Exception {
System.out.println("监听到活动数据:" + LocalDateTime.now() + value);
JSONObject jsonObject = JSONObject.parseObject(value);
User before = jsonObject.getObject("before", User.class);
User after = jsonObject.getObject("after", User.class);
try {
String table = jsonObject.getJSONObject("source").getString("table");
SqlParse sqlParse = new SqlParse();
String executeSQL = "";
if(before == null){
// 插入
executeSQL = sqlParse.getInsert(after,table);
}else if(after == null){
// 删除
executeSQL = sqlParse.getDeleteSQL(before,table);
}
else{
// 更新
executeSQL = sqlParse.getUpdateSQL(before,after,table);
}
SpringJDBC.executeSQL(executeSQL);
}catch (Exception e){
System.out.println("执行错误");
}
}
}
通用形SqlParse只能解析同构数据,异构数据需要单独处理。
增量数据的解析和处理
FlinkCDC 将抓取到的增量数据转换为 Flink 支持的数据格式后,交由 Flink 进行进一步的处理。Flink 可以对数据进行各种运算,如聚合、过滤、变换等,最终将处理结果输出到其他的存储介质中。
总的来说,FlinkCDC 的原理就是通过解析 MySQL 中的 binlog,抓取到最新的增量数据,并将其转换为 Flink 支持的数据格式,然后将增量数据同步到 Flink 或者其他的计算引擎中进行处理。通过 Flink 的强大计算能力,可以对增量数据进行各种计算,从而实现实时数据处理和分析的功能。
优缺点比较
优点:
- 能监听多种数据源:MySQL、Oracle、PgSQL等;
- 支持流式处理,可以实现数据的实时处理和分析;
- 支持增量更新,可以实现数据的实时同步;
- 支持容错处理,可以实现数据的高可靠性;
缺点:
- 对Oracle支持不太友好,需要将开启归档日志,并且部分字段解析需要了解其语义;
- 对于大表的查询性能较差;
- 对于大规模数据的处理效率较低;