1. 分析需求
打开某音热搜,选择需要获取的热榜如图

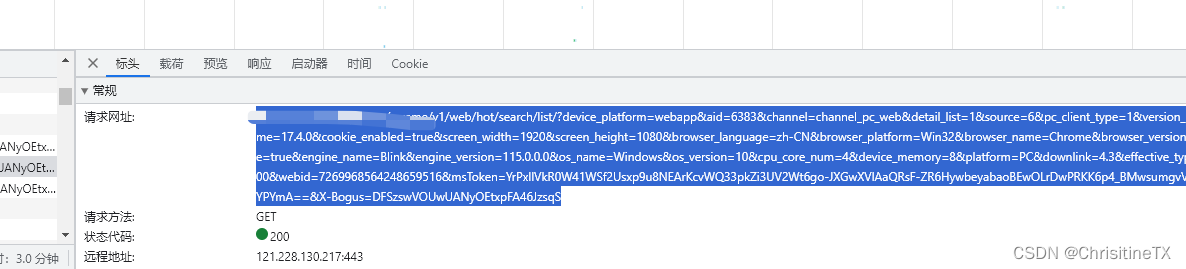
查找包含热搜内容的接口返回如图

将url地址保存
2. 开发
定义请求头
headers = {
'Cookie': '自己的cookie',
'Accept': 'application/json, text/plain, */*',
'Accept-Encoding': 'gzip, deflate',
'Host': 'www.douyin.com',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/15.4 Safari/605.1.15',
'Accept-Language': 'zh-CN,zh-Hans;q=0.9',
'Referer': 'https://www.douyin.com/hot',
'Connection': 'keep-alive'
}
配置上面获取到的url
定义抓取元素数组
position_list = [] # 热搜排名
title_list = [] # 热搜标题
time_list = [] # 热搜时间
hot_value_list = [] # 热度值
hot_url = [] # 热搜链接
开始请求
r = requests.get(url, headers=headers)
# 用json接收请求数据
json_data = r.json()
解析响应
data_list = json_data['data']['word_list']
循环赋值
for data in data_list:
title = data.get('word', '') # 热搜标题
title_list.append(title)
position = data.get('position', 0) # 热搜排名
position_list.append(position)
hot_value = data.get('hot_value', '') # 热搜值
hot_value_list.append(hot_value)
event_time = data.get('event_time', '') # 热搜时间戳
if event_time:
timestamp = float(event_time)
# 时间戳转时间
dt_object = datetime.datetime.fromtimestamp(timestamp)
formatted_date = dt_object.strftime("%Y-%m-%d %H:%M:%S")
time_list.append(formatted_date)
else:
time_list.append('')
hot_url.append('https://www.douyin.com/hot/' + data.get('sentence_id', '')) # 热榜链接
写入csv
df = pd.DataFrame(
{
'热搜排名': position_list,
'热搜标题': title_list,
'热搜时间': time_list,
'热度值': hot_value_list,
'热搜链接': hot_url,
}
)
# 保存结果到csv文件
df.to_csv('抖音热搜.csv', index=False, encoding='utf_8_sig')
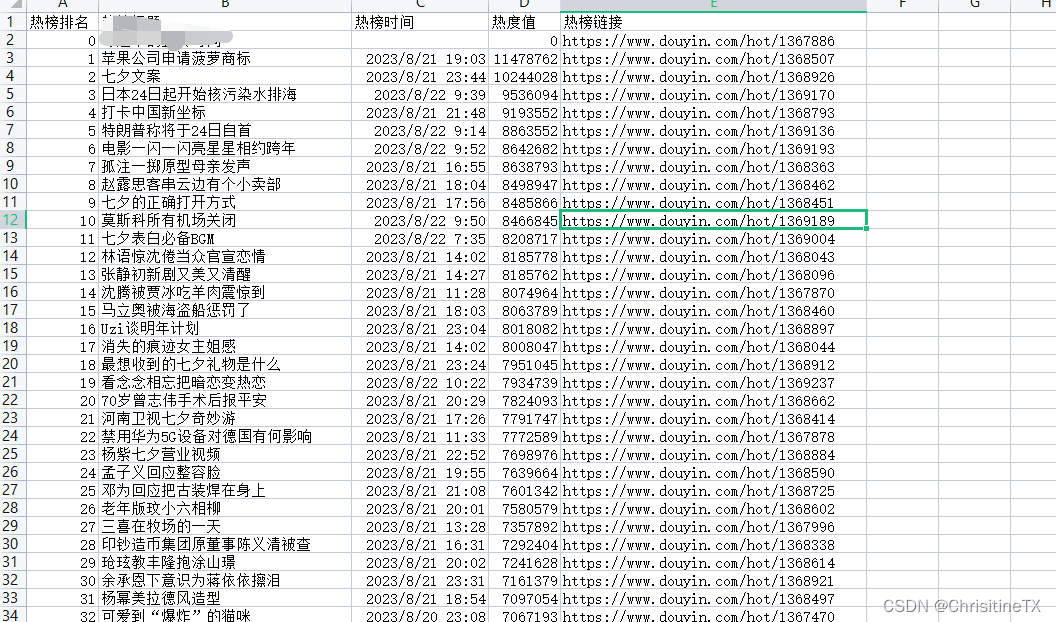
3. 效果验证