前言:这篇文章主要总结事务,锁、索引的一些知识点,然后分享一下自己学习小心得,我会从点到线在到面展开说说,对于学习任何知识,我们都应该藐其全貌,不要一开始就选入细节
基础
一、基础架构:一条查询sql是怎么执行的?

二、 日志系统:一条更新语句是怎么执行的?
1.redolog与binlog区别?
① redolog是innodb存储引擎实现,而binlog是在Server层实现
② redolog是物理存储,而binlog是逻辑存储
③ redolog是循环写入(空间会用尽,所以每隔一段时间就需要擦除),而binlog是追加写入(所以说他是归档日志)
2、二阶段提交是怎么样?
3、第一步:写入redolog处于准备阶段
4、第二步:写入binlog
5、第三步:redolog提交阶段、
备注:将 redo log 的写入拆成了两个步骤:prepare 和 commit,这就是"两阶段提交"。
我的理解
从 “两阶段提交”的执行流程看,“ binlog 成功,redo log失败”的场景(备注:数据库 crash-重启后,会对记录对redo log进行检查 )
1、如果 redo log 已经commit,则视为有效。
2、如果 redo log prepare 但未commit,则check对应的bin log记录是否记录成功。
① bin log记录成功则将该prepare状态的redo log视为有效
② bin log记录不成功则将该prepare状态的redo log视为无效
3、一些参数补充说明
binlog日志模块
sync_binlog=1的时候,表示每次事务的 binlog 都持久化到磁盘(建议设置成1)
补充:binlog一共有三种模式
① statement模式:记录sql语句,优点占用内存少,如果出现函数可能到回到数据不一致
② row模式:直接记录数据,占用内存大
③ mixed:以上两种模式的混合
redolog日志模块
innodb_flush_log_at_trx_commit={0|1|2} (指定何时将事务日志刷到磁盘,默认为1)
0表示每秒将"log buffer"同步到"os buffer"且从"os buffer"刷到磁盘日志文件中。
1表示每事务提交都将"log buffer"同步到"os buffer"且从"os buffer"刷到磁盘日志文件中。
2表示每事务提交都将"log buffer"同步到"os buffer"但每秒才从"os buffer"刷到磁盘日志文件中。
问题:前面我说到定期全量备份的周期“取决于系统重要性,有的是一天一备,有的是一周一备”。那么在什么场景下,一天一备会比一周一备更有优势呢?或者说,它影响了这个数据库系统的哪个指标?
这个需要根据业务进行评估,空间换时间
三、 事务隔离:为什么你改了我还是看不见?
1、Mysql有哪些隔离级别?
① 读未提交:别人改数据的事务尚未提交,我在我的事务中也能读到。
② 读已提交:别人改数据的事务已经提交,我在我的事务中才能读到。
③ 可重复读:别人改数据的事务已经提交,我在我的事务中也不去读。
④ 串行:我的事务尚未提交,别人就别想改数据
2、事务隔离的实现
RC:每次查询的时候都会去创建一个视图
RR:事务启动的时候就会创建视图
RU:不存在视图
串行化:不存在视图这个概念,都是通过加锁方式实现事务的隔离
3、事务启动方式
① 把自动提交关掉:set autocommit=0
② 例子->显示启动事务
begin;
update t1 set a=1 where id = 2;
commit;
rollback;
这里有个需要注意的点:begin的时候是还没启动事务,在执行第一条sql才会启动
③ 如何查询长事务,查询持续时间超过60秒的事务
select * from information_schema.innodb_trx where TIME_TO_SEC(timediff(now(),trx_started))>60;
*4、**问题:如何避免长事务对业务的影响?*
1、set global general_log=on;开启通用日志,在业务功能测试阶段要求输出所有的 general_log,分析日志行为提前发现问题
1、确认是否有不必要的只读事务。把select语句放在事务外
2、通过 SET MAX_EXECUTION_TIME 命令,避免单sql执行时间过长
3、监控 information_schema.Innodb_trx 表,设置长事务阈值,超过就报警 / 或者 kill;
4、innodb_undo_tablespaces设置成 2,即是不是用系统表空间,使用独立空间,如果真的出现大事务导致回滚段过大,这样设置后清理起来更方便
四、 深入浅出索引(上)
总结:
*第一点:索引模型的选择*
1.索引的作用:提高数据查询效率
2.常见索引模型:哈希表、有序数组、搜索树
3.哈希表:键 - 值(key - value)。
4.哈希思路:把值放在数组里,用一个哈希函数把key换算成一个确定的位置,然后把value放在数组的这个位置
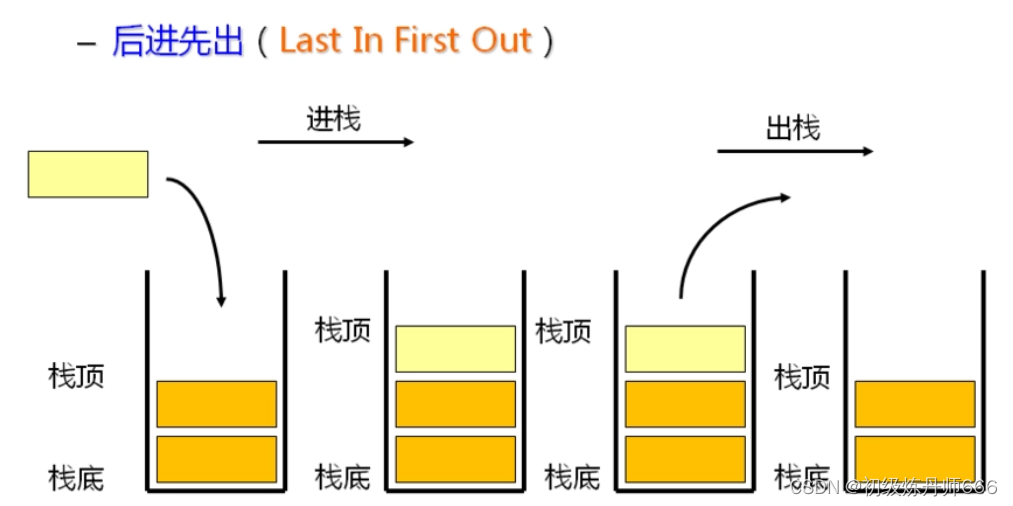
5.哈希冲突的处理办法:链表
6.哈希表适用场景:只有等值查询的场景
7.有序数组:按顺序存储。查询用二分法就可以快速查询,时间复杂度是:O(log(N))
8.有序数组查询效率高,更新效率低 9.有序数组的适用场景:静态存储引擎。
10.二叉搜索树:每个节点的左儿子小于父节点,父节点又小于右儿子
11.二叉搜索树:查询时间复杂度O(log(N)),更新时间复杂度O(log(N))
12.数据库存储大多不适用二叉树,因为树高过高,会适用N叉树
*第二点:Innodb的索引模型介绍*
\1. InnoDB中的索引模型:B+Tree
2.索引类型:主键索引、非主键索引 主键索引的叶子节点存的是整行的数据(聚簇索引),非主键索引的叶子节点内容是主键的值(二级索引)
3.主键索引和普通索引的区别:主键索引只要搜索ID这个B+Tree即可拿到数据。普通索引先搜索索引拿到主键值,再到主键索引树搜索一次(回表)
\4. 一个数据页满了,按照B+Tree算法,新增加一个数据页,叫做页分裂,会导致性能下降。空间利用率降低大概50%。当相邻的两个数据页利用率很低的时候会做数据页合并,合并的过程是分裂过程的逆过程。
5.从性能和存储空间方面考量,自增主键往往是更合理的选择。
*问题:说说下面重建索引的一些方案是否合理?*
*1.重建k索引*
*alter table T drop index k;*
*alter table T add index(k);*
*2.重建主键索引*
*alter table T drop primary key;*
*alter table T add primary key(id);*
*重建索引 k 的做法是合理的,可以达到省空间的目的。但是,重建主键的过程不合理。不论是删除主键还是创建主键,都会将整个表重建。所以连着执行这两个语句的话,第一个语句就白做了。这两个语句,你可以用这个语句代替 : alter table T engine=InnoDB*
五、 深入浅出索引(下)
总结:
\1. 覆盖索引:如果查询条件使用的是普通索引(或是联合索引的最左原则字段),查询结果是联合索引的字段或是主键,不用回表操作,直接返回结果,减少IO磁盘读写读取正行数据
\2. 最左前缀:联合索引的最左 N 个字段,也可以是字符串索引的最左 M 个字符
\3. 联合索引:根据创建联合索引的顺序,以最左原则进行where检索,比如(age,name)以age=1 或 age= 1 and name=‘张三’可以使用索引,单以name=‘张三’ 不会使用索引,考虑到存储空间的问题,还请根据业务需求,将查找频繁的数据进行靠左创建索引。
\4. 索引下推:like 'hello%’and age >10 检索,MySQL5.6版本之前,会对匹配的数据进行回表查询。5.6版本后,会先过滤掉age<10的数据,再进行回表查询,减少回表率,提升检索速度
*问题:*
*CREATE TABLE geek (*
*a int(11) NOT NULL,*
*b int(11) NOT NULL,*
*c int(11) NOT NULL,*
*d int(11) NOT NULL,*
*PRIMARY KEY (a,b),*
*KEY c (c),*
*KEY ca (c,a),*
*KEY cb (c,b)*
*) ENGINE=InnoDB;*
*针对下面两条sql,以上那个索引可以不用,为什么*
*select * from geek where c=N order by a limit 1;*
*select * from geek where c=N order by b limit 1;*
*答案:ca索引可以不用,永久记住最左匹配,以最左为主*
六、 全局所有和表锁:给表加个字段有这么多障碍吗?
1. *MySQL从加锁范围上分为哪三类?*
全局锁、表级锁、行级锁
*2. 全局锁加锁方法的执行命令是什么?主要的应用场景是什么?*
flush tables with read lock 应用场景:全库逻辑备份
*3. 做整库备份时为什么要加全局锁?*
不加锁的话,系统备份得到的库,不是同一个逻辑时间点的,会导致数据不一致。
*4. MySQL的自带备份工具, 使用什么参数可以确保一致性视图, 在什么场景下不适用?*
使用参数:-single-transaction 只适用于所有表使用事务引擎的库,部分表使用的引擎不支持事务的话,不能用该方法。
*5. 不建议使用set global readonly = true的方法加全局锁有哪两点原因?*
① 有些系统用readonly判断是主库还是备库,修改这个值对整个系统影响太大;
② 如果客户端发生异常,数据库就会一直保持readonly,会导致长时间无法写入数据,风险很高。
*6. 表级锁有哪两种类型? 各自的使用场景是什么?*
①表锁。lock tables xxx read/write。数据库引擎不支持行锁时,才会用到表锁。
②元数据锁。MDL,分为MDL 读锁和 MDL 写锁。执行DML的时候,会申请 MDL读锁;执行DDL的时候,会申请 MDL写锁。
7. *MDL中读写锁之间的互斥关系怎样的?*
读读共享,读写互斥,写写互斥。
*8. 如何安全的给小表增加字段?*
①减少长事务,避免跟长事务竞争 MDL锁,如果获取 MDL写锁阻塞,会影响后面 MDL读锁获取,导致所有会话阻塞。
②Alter table语句,设置超时时间,超过时间未获取到 MDL写锁,则放弃,后面再进行重试,避免影响后面的会话。
问题:
备份一般都会在备库上执行,你在用–single-transaction 方法做逻辑备份的过程中,如果主库上的一个小表做了一个 DDL,比如给一个表上加了一列。这时候,从备库上会看到什么现象呢?
DDL binlog同步到备库后,此时备库有MDL读锁,而同步过来的DDL变更到备库上需要MDL写锁,那么这个DDL会被阻塞,所以该DDL不会反应在备份的数据里面。当使用该备份数据进行恢复时,由于加了一列,那么恢复会异常
七、 行锁的功过:怎么减少行锁对性能的影响?
\1. 行锁两阶段协议:不是事务开始的时候开启,而是语句执行的时候上锁
这个就涉及到插入和更新sql的先后顺序去优化减少锁冲突
\2. 死锁:互相持有对方资源
\3. 死锁检测优劣,怎么避免大量死锁检测、高并发下避免死锁检测带来的负面影响:
① 确保业务上不会产生死锁,直接将死锁检测关闭。(innodb 自带死锁检测)
② 在数据库中间件中统一对更新同一行的请求进行排队,控制并发度。
③ 业务逻辑上进行优化,将一行数据分解成多行,降低写入压力。
八、 事务到底是隔离还是不隔离?
\1. mysql中有两个视图的概念
① 一个是view 用来创建虚表
② 另一个一致性视图,主要用来解决rr和rc问题
- “快照”在 MVCC 里是怎么工作的?
参考事务隔离流程图
实战
一、唯一索引和普通索引怎么选?
1、唯一索引和普通索引怎么选?
① 查询情况下,普通索引和唯一索引性能都差不多,因为mysql以页形式读到内存,在内存判断是很快的
② 更新情况下,唯一索引没有用到change buffer,而普通索引有用到,因为唯一索引就一条记录,如果内存有,直接就可以在内存操作,就没必要用change buffer
③ chang buffer与merge结合使用,有change buffer如果数据不存在,就不用重新查磁盘,直接写入到change buffer,等一下次查询就合并磁盘和增量修改,或者定时merge增量修改
④ 所以怎么选,写入比较频繁的建议用普通索引,如果是写完马上读,会触发merge,io次数不会减少,反而增加change buffer维护代价
2、merge 的执行流程是这样的:
① 从磁盘读入数据页到内存(老版本的数据页);
② 从 change buffer 里找出这个数据页的 change buffer 记录 (可能有多个),依次应用,得到新版数据页;
③ 写 redo log。这个 redo log 包含了数据的变更和 change buffer 的变更。
问题:如果某次写入使用了 change buffer 机制,之后主机异常重启,是否会丢失 change buffer 和数据。
这个问题的答案是不会丢失,虽然是只更新内存,但是在事务提交的时候,我们把 change buffer 的操作也记录到 redo log 里了,所以崩溃恢复的时候,change buffer 也能找回来。
二、mysql为什么有时候会选错索引?
*1、为什么有时候mysql会选错索引?*
扫描的行数过多情况下,优化器会选择扫描全表而不用索引
*2、解决办法*
通过explain sql后发现选错索引,可以采取以下方式:
① 通过指定索引 force index
② 通过sql优化让其走预期的索引
③ 删除不必要的索引
备注:这种情况生产上是比较少发生,索引不必过多关注
三、怎么给字符串加索引?
*1.为什么需要优化字符串上的索引*
如果字符串较长,索引字段占用内存空间大,B+树高度较高,这样查询IO次数较多,耗时长。 个人认为未出现性能瓶颈,不需要过度优化,全字段索引也ok。
*2.优化方法及优缺点、适用场景*
方法一:前缀索引 概念:在建立索引的时候指定索引长度,且该长度的字段区分度高
优点:a. 相比全字段索引,每页存储的索引更多,查询索引IO次数少,效率高。即既节省了内存空间,又提高了查询效率。
缺点:
a. 指定索引长度的区分度低的话,扫描主键索引次数就会多,效率低;
b. 不会使用覆盖索引,即使索引长度定义为全字段,也会去主键索引查询 适用场景:前缀索引区分度高
方法二:倒序存储 概念:字段保存的时候反序存储 优点:同前缀索引
缺点:
a.只适用于等值查询,不适用于范围、模糊查询。
b.每次保存、查询时需调用reverse()函数;
c.若后缀索引区分度低,扫描行数会增多。 适用场景:索引字段后缀区分度高,前缀区分度低。
方法三:添加hash字段,作为索引 概念:在表中添加一个hash字段并加索引,用于存储索引字段的哈希值如使用crc32()哈希函数,每次查询时先计算出字段的hash值,再利用hash字段查询。可能存在hash冲突,所以where需要加索引字段字段的等值条件。
优点:哈希函数冲突概率低的话,平均扫描行数接近1。
缺点:只适用于等值查询,不适用于范围、模糊查询。 适用场景:只适用于等值查询,不适用范围查询或模糊查询。
四、为什么我的mysql会抖一下
*1、首先,理解一下什么是脏页,什么是干净页*
① 脏页:内存与磁盘的内容不一致的时候,我们称这个内存也就是脏页
② 干净页:内存写入磁盘后,内容一致了,该内存页就是干净页
深层理解:每个表都是一个ibd文件, 每个文件都是分成n个16kb的page,page是IO的基本单位, 也就是从硬盘到内存每次都载入一个page,所以用到的page既在内存也在硬盘ibd文件里. 在内存page上写写改改后, 这个page没写回ibd文件, 就成了脏页
2、*那么,什么时候会刷脏页呢?*
① *redolog写满了*:redo log是在同一块地方进行循环的写,redo log记录的变动会被清除,在清除时可能redo log中有记录变更的数据还未刷入磁盘中,这时就得需要去判断这些变动的数据是否刷入磁盘,没有则进行刷脏页
② *内存满了*:内存不够用的时候,就要淘汰一些数据页,空出内存给别的数据页使用。如果淘汰的是“脏页”,就要先将脏页写到磁盘
③ 系统空闲的时候
④ mysql正常关闭
说明第②点为什么要刷脏页:反证法->如果内存满了不刷脏页到磁盘中,下次请求磁盘中的干净页到内存时,还是要额外判断redolog是否对该也有修改,有修改的话还是要刷到磁盘中,这样还不如在内存满了的时候,直接将它刷到磁盘中
*3、InnoDB 刷脏页的控制策略?*
*影响因素有:*
\1. 脏页比例
\2. 脏页刷盘速度
\3. 刷新相邻页面策略 (bufferpool脏页比例 或 redolog 都可能成为读写sql的瓶颈)
*参数控制:*
\1. 脏页比例默认75%,一定不要让其接近75%=脏页/总页
\2. 刷脏页速度 innodb_io_capacity定义的能力乘以R%来控制刷脏页的速度
\3. innodb_flush_neighbors=0(不开启脏页相邻淘汰) (对于机械硬盘顺序读写会有提升,ssd无提升,mysql8直接默认不开启)
\4. 避免大量刷脏页,脏页flush可能会产生内存抖动