Java 语言的面向对象,平台无关,安全,开发效率高等特点,使其在许多领域中得到了越来越广泛的应用。但是由于Java程序由于自身的局限性,使其无法应用于实时领域。由于垃圾收集器运行时将中断Java程序的运行,其运行时刻和垃圾搜集时间具有不确定性。在应用程序高频率分配和释放内存时,垃圾收集要占用的时间可能比程序自身运行的时间还要多。这些都使得 Java程序无法满足在实时领域应用的要求。
Java实时规范(RTSJ)的内存管理机制既保证了Java本身的内存安全的优势,同时又保证了在实时系统中对内存操作的的可预测性。不产生垃圾的代码不会导致请求式的垃圾收集;不引用堆中对象的代码可以抢占垃圾收集器的线程。为了能够保留垃圾收集的好处又能避免垃圾收集器对实时特性的影响,基于以上两个事实RTSJ扩展了Java内存管理机制,在传统的堆内存的基础上,又提出了内存区域(Memory Area)的概念。在新增加的这几个内存区域中分配对象不会导致垃圾收集器的执行,不会使系统受到其不可预测性的影响。
本文根据RTSJ的要求,介绍了RTSJ内存管理机制实现的各个基本要点,包括使用Display树的内存引用检查, LTMemory和VTMemory的分配机制, ScopeStack的维护等。文章通过研究一个可运行在多种操作系统并兼容多种硬件平台的开源的Java虚拟机SableVM的基础上,结合国内外最新的理论,提出了一个对其实时性进行改进的方案,并对其进行实验。该方案有别于国内外现有的实时Java虚拟机的实现,在内存管理方面即符合RTSJ的要求,同时又保证了Java程序可移植性的要求。
4 实时内存管理机制的设计
本章根据 RTSJ 规范的要求,以及实时 Java 内存管理与普通 Java 的不同点所提出的一些问题,提出了一个 Java 虚拟机实时内存管理的实现方案。该方案是在一个运行于Linux操作系统上的非实时的Java虚拟机SableVM的基础上进行的实时性改进,修改虚拟机的核心代码,把实时内存管理机制完全整合到SableVM中。
4.1 内存区域模型
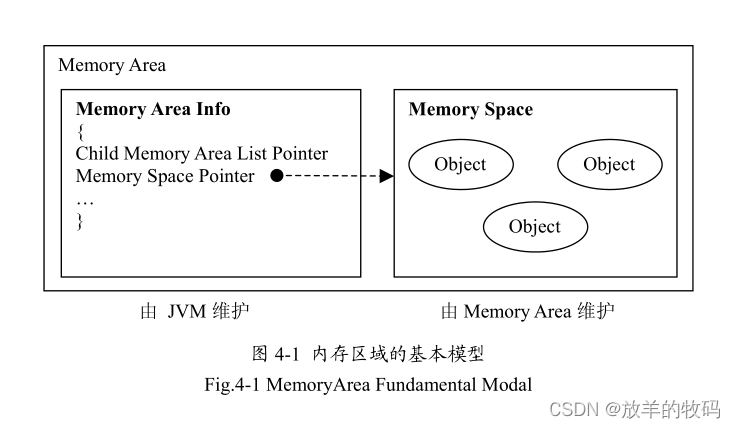
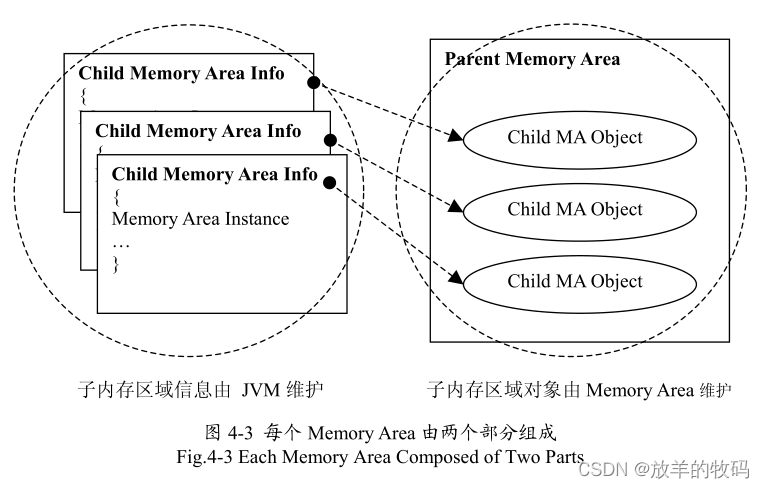
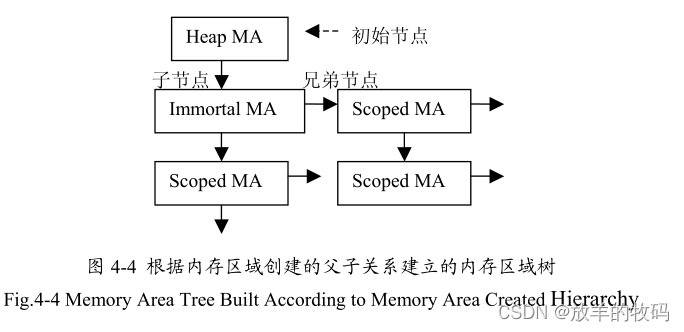
内存区域(Memory Area)的基本模型如图4-1 所示。内存区域由两部分组成,一部分是内存区域信息(Memory Area Info),它是虚拟机内存的管理单元,虚拟机内部对内存区域的管理都是对这个数据结构的操作;另一部分是内存空间(Memory Space), Java对象都是分配在这个区域之中。内存区域信息包含了一个一个指针指向其所维护的内存空间,因此通过内存区域信息就可以找到内存空间。同时内存区域信息是有层级关系的,每个内存区域可以包括多个子内存区域。
对于任何一个Java对象来说,它都包含了两个部分,一部分是由Java语言实现的Java类,另一部分是其在Java虚拟机内部对应的数据结构。Java的执行引擎执行Java类中的程序,同时维护其对应的虚拟机内部的数据结构。由于Java程序的运行是解释型的,显然维护虚拟机数据结构比维护Java数据结构更加高效,且更具有确定性。要提高Java程序的实时性,就要把Java类中核心部分更多的由虚拟机来维护和处理。
在内存空间中的对象都是Java对象实例,这些对象可分为普通对象和内存区域对象。内存区域对象也是一个普通的Java对象,它不仅可以分配在堆区域内,还可以分配在其它任何的内存区域内。同时它还给其他的Java对象提供了内存分配的服务,不过提供的分配空间不是在其自身的对象空间中,而是它自己新开辟的一块空间,在这里称它为内存空间(Memory Sapce)。
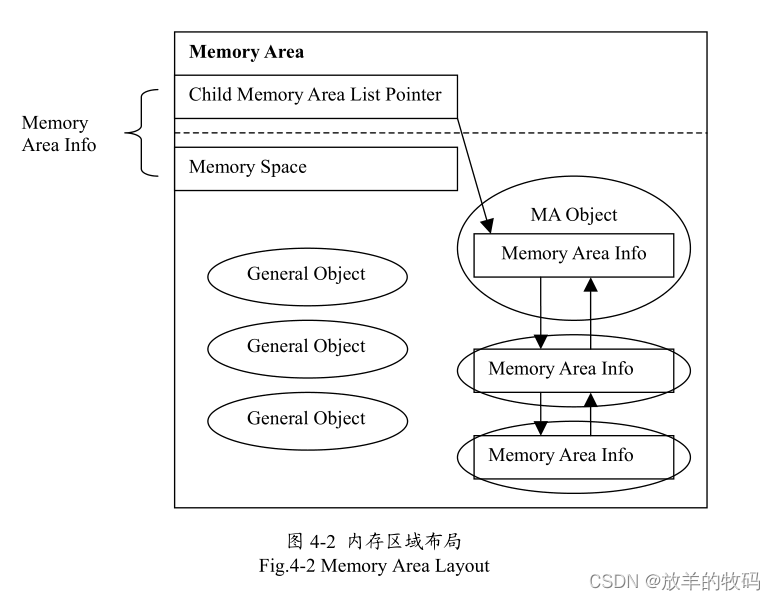
内存区域布局如图4-2所示。内存区域对象一方面跟 MemoryArea 的Java 类对应,另一方面该类中包含了一个实例变量,它的值是指向虚拟机中 MemoryArea 数据结构的指针。每个内存空间中的所有的MemoryArea数据结构是通过一个双向链表连接起来,目的是便干垃圾收集器的遍历与收集。
内存区域对象的管理也是分成两部分,如图4-3所示。内存区域是有父子层级关系的,子内存区域都有一个指针指向其分配在父内存区域中的Java对象。
内存区域的数据结构定义如下:
struct _rtt_memory_area_struct {
_rtt_memory_area *pChild; // 子 MemoryArea
_rtt_memory_area *pBrother; // 兄弟 MemoryArea
// 该内存区域的父节点
// 这是根据线程的进入顺序而建立的,会根据线程进入和退出而变化
_rtt_memory_area *pParent; //heap and immortal 永远为 NULL
_svmt_object_instance *pInstance; //point to the ma object instance
_rtt_memory_area_type typeID; // 内存区域类型 ID
_rtt_display_ref_checker refChecker; // 引用检查器
atomic_t refCounter; // 原子操作,引用计数器,
// 对于 heap and immortal memory 永远为 0
_rtt_memory_allocator mem_allocator; // 内存分配器, heap 分配器使用原始的
_svmt_object_instance *pPortal; // 用于线程间共享对象
pthread_mutex_t ma_mutex; // 用于同步对本 MA 的操作,
//HeapMemoryArea 不使用它
};每个内存区域都由其父内存区域来管理,即由父内存区域来决定其分配和释放的方法。每个父内存区域内部都维护着其第一层子内存区域的链表,这样层层的父子关系就构成了一棵树(见图4-4)。因为虚拟机刚启动的时,对象都是创建在堆中的,所以堆内存区域必然是所有内存区域的父亲。
4.2 线程的改进
内存区域是通过线程来操作的,根据RTSJ要求,领域内存(Scoped Memory)由实时线程的领域堆栈(Scope Stack)来维护,只有实时线程才有Scope Stack。由于实时线程不是本文的研究重点,为了使用并测试领域内存,本文仅在普通线程的基础上简单的模拟了实时线程的基本功能。
4.2.1 实时线程模拟
实时线程(RealtimeThread)继承于普通线程(Thread),因此RealtimeThread也有一个start()方法用于运行该线程。这个方法本应该调用实时的调度器,现为了方便实现,直接利用 Thread 原有的代码,在该方法中调用 Thread 的 Java 方法 start()。
JNIEXPORT void JNICALL Java_javax_realtime_RealtimeThread_
start (JNIEnv * _env, jobject obj)
{
_svmt_JNIEnv *env = _svmf_cast_svmt_JNIEnv (_env);
// 使用 sablevm 内置的调度器 , ,准备调用 thread.start()
_svmm_resuming_java(env);
jmethodID methodID = NULL;
jclass threadCls = NULL;
if ((threadCls = FindClass(_env, "java/lang/Thread"))==NULL)
goto end;
if ((methodID = GetMethodID(_env, threadCls, "start", "()V"))==NULL)
goto end;
else //call Thread.start()
CallNonvirtualVoidMethodA(_env, obj, threadCls, methodID, NULL);
end:
_svmm_stopping_java(env);
}运行thread.start()方法会调用虚拟机内部的JNI函数_svmf_thread_native_start(svmt_JNIEnv *env, jobject threadInstance),该函数维护好线程所需的各个数据结构之后,正式启动线程pthread_create (&new_env->thread.pthread, NULL, &_svmf_thread_start,new_env)。而这些函数是根据参数 threadInstance 来判断线程是Thread 还是RealtimeThread,具体判断方法下文有介绍。
实验证明,这个方法是可行的。研究实时内存管理更多关注的是实时线程中的Scope Stack如何对内存区域进行维护,不关心其调度的过程。
如图4-5说明了两种线程的差别。实时线程的数据结构中有2个Scope Stack指针,Scope Stack和Scope Stack Temp。图中可以看到Scope Stack是当前活动的领域堆栈,而Current MA是当前的内存分配上下文,也就是活动的内存区域,当前线程所分配的对象都在Current MA上分配。在执行executeInMemoryArea方法的时候,会创建一个临时的Scope Stack供它使用,它是当前的Scope Stack的拷贝,然后把线程的活动Scope Stack保存到Scope Stack Temp中,而把新创建的Scope Stack设为活动。
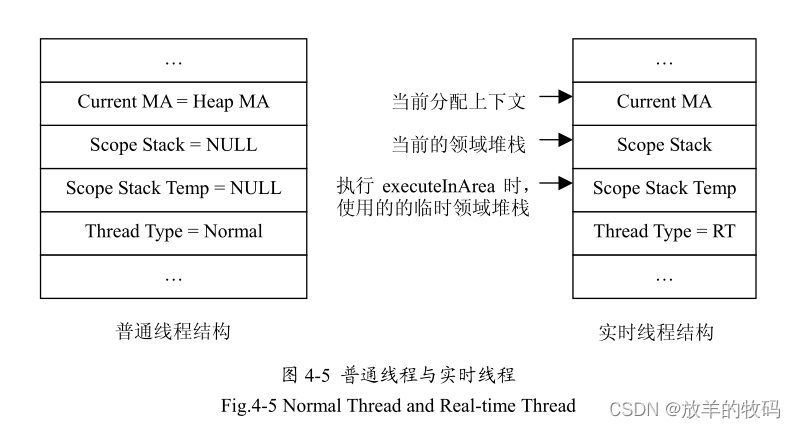
对于普通线程来说,其当前内存分配上下文永远是堆内存区域,而它的Scope Stack永远为空值。
为了在虚拟机内部判别各线程的类型,需要在虚拟机的线程数据结构中加入一个Thread Type成员变量。为了能够通过给定的线程实例(Thread Instance)来判断该线程实例是否是实时线程,可以把Scope Stack 指针放到RealtimeThread类中的实例变量中去。
public class RealtimeThread extends Thread implements Schedulable {
…
protected RawData scopeStack;
…
}只有实时线程才有 Scope Stack,对于普通线程是肯定不包含 scopeStack 这个实例变量的,这样通过 JNI 的 GetFieldID 和GetIntField 函数,如果能够从线程实例得到该scopeStack,则说明是实时线程,否则为非实时线程。
程序中的 RawData 类,是一个特殊的类,在它的定义中没有任何方法和字段,仅仅用于标识某字段是否用于存储虚拟机数据。在整个虚拟机的实现中,大量使用了该方法来解决虚拟机数据与 Java 数据的传递问题。
4.2.2 Scope Stack 的实现
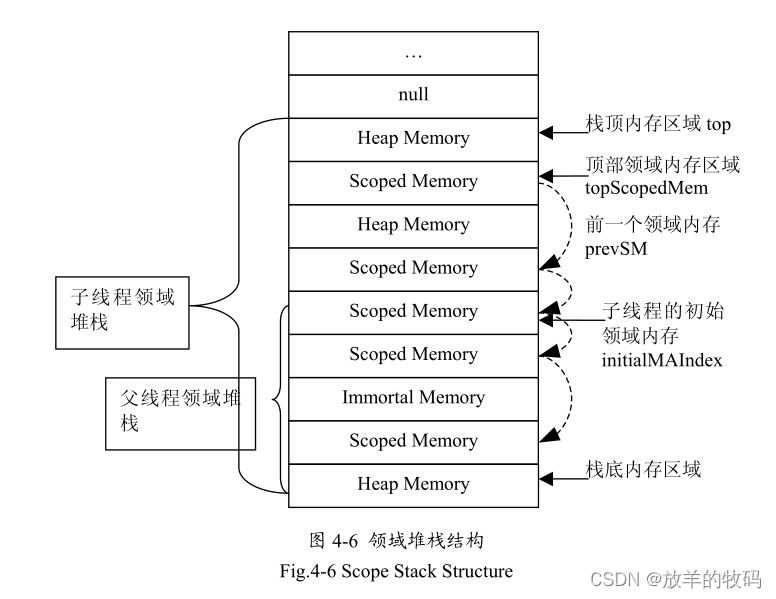
Scope Stack 是用来维护内存区域的,见图4-6 所示。它相当于一个内存区域的指针数组,同时附加一些维护这个数组的一些辅助数据。整个领域堆栈结构是由领域内存进入实时线程的顺序来构建的。从实时Java规范中可以知道,要切换实时线程的当前的内存分配上下文,需要运行相应的内存区域的enter方法。当在实时线程中创建一个子线程时,子线程会复制一份其父线程的领域堆栈的副本作为其的初始领域堆栈。由于子线程初始领域堆栈中的内存区域指针指向的是与其父线程相同的内存区域对象,这时领域堆栈指向的领域内存的引用计数都要增加1。
领域堆栈数据结构如下:
struct _rtt_scope_stack_struct {
_rtt_scope_stack_item item[SCOPE_STACK_SIZE]; // 领域堆栈项目数组
index_t top;
index_t topScopedMem;
index_t initialMAIndex;
} ;
struct _rtt_scope_stack_item_struct {
_rtt_memory_area *pMA;
index_t prevSM; // 前一个 Scoped Memory 的索引
};其中,top用于标识栈顶,栈顶指向的内存区域就是该线程的当前内存分配上下文topScopedMem用于标识最顶部的领域内存, prevSM用于标识前一个领域内存,这两个索引值把整个领域堆栈的领域内存都串联起来,这样便于实现对内存引用的检查,这在后文有介绍。initialMAIndex用于标识该线程的初始内存区域,对于根线程来说它是指向栈底,而对于子线程来说它就是指向器父线程的领域堆栈的栈顶。initialMAIndex的
一个典型用途就是用在垃圾收集器遍历所有线程的内存空间时,使用它可以避免重复遍历父子线程公共的内存区域。
对Scope Stack的操作,主要包括初始化、入栈、出栈、销毁,所有的这些操作都必须根据图4-6维护好Scope Stack数据结构的完整性。
4.3 内存区域的分配与回收
4.3.1 内存区域的分配
有了内存区域模型和改进的实时线程,就可以正确的在内存区域中分配和回收对象。内存区域分配对象是在Memory Space中。Memory Space的数据结构如下(以LTMemory Space 为例):
struct _rtt_lt_memory_struct {
_rtt_memory_area *pMA; // 指向其对应的 Memory Area 数据结构,包含了 MA Info
size_t size; // 空间的大小
void *start; // 空间开始的地址
void *end; // 空间结束的地址
void *alloc; // 当前分配的位置
jint hashcode_base; // 哈希表基址 , 分配在其中的对象的哈希值根据它来决定
} ;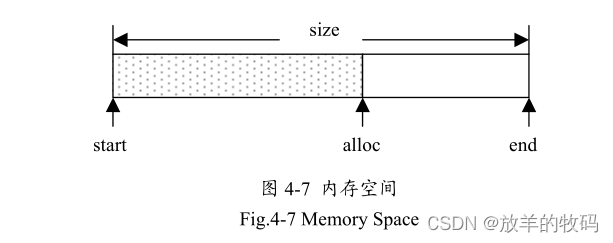
内存区域的内部数据结构Memory Area Info及Memory Space在Java程序创建Memory Area对象的同时而被分配。如图4-7所示, Memory Space初始化时start等于alloc,随着在其中不断的分配对象, alloc的值不断增长,直到alloc等于end。由于在其中每分配一个对象,只需把alloc的值返回作为该对象的起始指针,然后把alloc的值增加该对象的大小即可,因此该分配对象的时间是常数时间。
由于内存空间是整块整块分配的,这样产生的内存碎片较少,对系统的性能有利,常数的分配时间比较适合实时系统的需求。但同时却导致了内存利用率不够高,对于小内存的系统来说,有可能无法申请到一整块连续的大的内存空间。因此这种方案比较适合最求高性能的场合。
4.3.2 内存区域的回收
可以说该方案内存分配是十分简单而高效的,但它们的回收却比较复杂。当线程对Memory Area的引用降为0时,需要清空Memory Space但不回收它实际所占用的内存(即把start赋给 alloc),以便当有线程再次进入时可以重复利用。
由于内存区域对象有线程引用计数的因素,对它的回收则需要考虑两方面的问题:
1)不存在任何对Memory Area的引用;
2)它的线程引用计数为0。
只有同时满足这两方面的情况下,该内存区域的 Memory Area Info 和 Memory Space将被释放,同时它的Java对象被垃圾回收。
下面具体分析各种内存区域的回收。首先确保Heap Memory和Immortal Memory对象永不被回收。在此前提下,对于在Scoped Memory中分配的Memory Area对象,由于安全引用机制的保证,可以在父Scoped Memoy的线程引用计数降为0引发回收Memory Space时,回收其子树中所有的子Memory Area对象及内部数据结构。而对于分配在Heap Memory和Immortal Memory中的Memory Area,由于它们的引用计数永远为0,因此对于Heap Memory中的第一层子Memory Area可以根据上面的两条垃圾回收规则来回收,而 Immortal Memory 中的子Memory Area 由于 RTSJ 规定显然是永远不要回收的。
4.3.3 一个示例
下面举个简单的例子来说明内存上下文切换以及对象的分配与释放。一个实时Java程序的基本结构如下所示:
main() {
MyRealtimeThread rt = new MyRealtimeThread(); //创建在堆中
rt.start(); // 启动实时线程
}
class MyRealtimeThread extends RealtimeThread {
public void run() {
LTMemory ma = new LTMemory(minSize, maxSize); // 创建在堆中
ma.enter(logic); // 切换当前实时线程的分配上下文为 ma
// 现在 ma 中的 Memory Space 中的对象将被回收,
// 但是该内存空间并没有被释放,以便下一次再进入该内存时重新利用它
}
}
class MyLogic implements Runnable {
public void run() {
Integer I = new Integer(10); // 在 ma 中创建对象
}
}首先,程序初始时内存分配上下文是堆,在堆上创建了一个自定义的实时线程的实例,然后启动该实时线程。线程的 start 方法将调用 run 方法,在 run 方法中由于内存反派上下文没有变,仍是堆,因此在其中的ma也是创建在堆上。执行ma.enter(logic)之后,该ma被压入到当前线程的Scope Stack中,该线程的内存分配上下文即转换成ma。在enter 方法中会调用 logic 的 run 方法,此时分配的对象Ⅰ都是在 ma 中。当方法 enter 返回后,即logic对ma的引用计数将减1,从而导致ma的引用计数为0而导致对ma的回收(即把ma的alloc=start)。这种回收由于是立即回收,且回收的时间是常量时间,可以光目可预测的
4.3.4 内存分配时间
Scoped Memory提出了几种需要考虑对象分配时间的子类, CTMemory, LTMemory,VTMemory。由于RTSJ对VTMemory没有做过多的限定,它的实现比较灵活,这里暂时采用和LTMemory一样的机制。下面只考虑CTMemory和LTMemory两种情况。
CTMemory是采用常数时间分配算法,它分配内存的时间与对象的大小无关;而LTMemory采用线性时间分配算法,它分配内存的时间与对象的大小成正比。分配时间之所以有如此差别是因为,分配好一块对象内存时需要对它进行初始化,这个初始化时间是与对象大小成正比的,而为了实现常数时间分配,可以把对象初始化步骤在内存区域空间初始化时候对整个内存区域清零,这样分配对象时就不需要每次都清零,这样对象的分配时间也会大大减少,不过这使得在内存区域创建的时候需要花费更多的时间。因此LTMemory与CTMemory各有利弊,可根据实际来选择使用。
4.4 内存引用检查
为了避免出现非法引用,RTSJ 要求内存区域间的关系要满足单亲规则。因此要在各对象要发生引用的时候对他们各自所处的对内存区域的进行引用检测。引用检测的时机有以下几种情况:
1)指令 putfield, putstatic, aastore
2)执行MemoryArea.newInstance (在内存区域中创建对象实例时)
3)抛出异常时
引用检测采用的方法是Display Tree的方式。Display Tree如图4-8所示【15116.由于单亲规则只对领域内存有效,因此 Display Tree 是根据各个领域内存的父子关系而构造而成的,其他类型的内存区域可以忽略。
在图4-8 中, A-L 这几个 ScopeMemory 根据之间的父子关系连成了一棵树。对于每个节点ScopeMemory,它把相应的父子的关系保存在自身的一个表里面,同时还保存其所处的节点的深度depth。如ScopeMemoryC,它的父子关系表是【AIBIC】。

引用关系检查算法如图4-9所示。
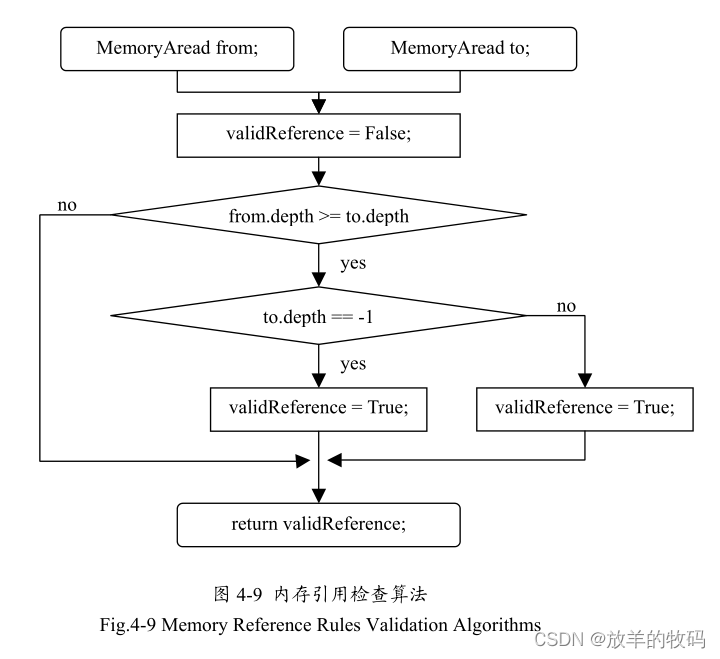
可以看到该算法仅需要简单的比较判断就实现了复杂的内存引用关系的检查,实现了常数时间的引用检查。但是构建父子关系表所需要的时间可能不是常数时间,因为越深的节点,其关系表就越长。这里采用的一个解决办法是使用固定长度的关系表,如使用长度为64的数组,一般内存区域的层级关系不会超过64层,因此它可以满足一般的需要。
4.5 垃圾收集器的改进
由于 RTSJ 提出的无堆内存的概念,使得代码引起垃圾收集的机会大大降低,而且垃圾收集的时刻被限定在可预测的范围之内。因为RTSJ未对垃圾收集器的类型和算法作要求,因此垃圾收集器不是改进的重点。但是由于Java自身的特点,垃圾收集器的支持必不可少。由于传统的垃圾收集器面向的是一个内存空间——堆,而在 RTSJ 兼容的实时系统中,垃圾收集器面向的是所有的内存区域(多个内存空间),因此必须进行改进才能使垃圾收集器正常运行。本文仅在传统的拷贝垃圾收集器的基础上对其进行改进,使其能够适应新添加的内存区域并与其完美的结合起来。
4.5.1 传统的拷贝垃圾收集器的实现
传统的拷贝垃圾收集器在垃圾收集过程中采用了4 步骤,如图4-10 所示。
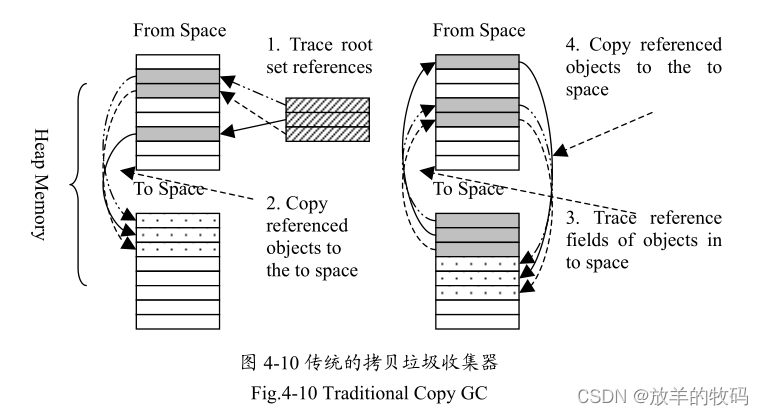
拷贝垃圾收集器包含了两个大小相同的存储空间,一个是 From Space,另一个是To Space,这两个空间交替使用。前者算是待垃圾收集的空间,后者是收集好的存储有效对象的空间。
首先遍历根集引用,根集引用包括所有线程的方法栈和本地引用链表。在调用本地方法的时候,有可能会通过JNI创建一些类实例,而这些类实例的引用不是放在Java栈中的,无法被垃圾收集器所遍历到,因此需要把这些引用单独放到一个链表中,便于垃圾收集器找到它们,在这里称之为native_ref. native_ref分为两种,一种是线程私有的本地引用链表native_locals,一种是所有线程共享的本地引用链表native_globals。
在遍历根集的过程中,把根集所引用的对象都拷贝到To Space中去,并给这些对象做好标记,以免下次遍历时重复拷贝。遍历完之后进入第三步,遍历To Space中的对象的引用字段,再把这些引用所指向的并且是在From Space中的对象拷贝到ToSpace中去。
经过这四步骤,有效的对象都拷贝到To Space中去了, From Space中的对象全部可以销毁。接着把堆空间的start指针指向To Space,调整好alloc和end指针,这样To Space就成为当前活动的堆分配空间。
可以说拷贝垃圾收集器的原理十分简单明了,当它有一个大缺点是占用内存大,需要一块额外的内存。
4.5.2 对垃圾收集器的改进
本设计在拷贝垃圾收集器的4步骤基础上,增加了一步对内存区域树的扫描,以保证垃圾收集器能够遍历到所有的对象,达到精确的回收。如图4-11所示。
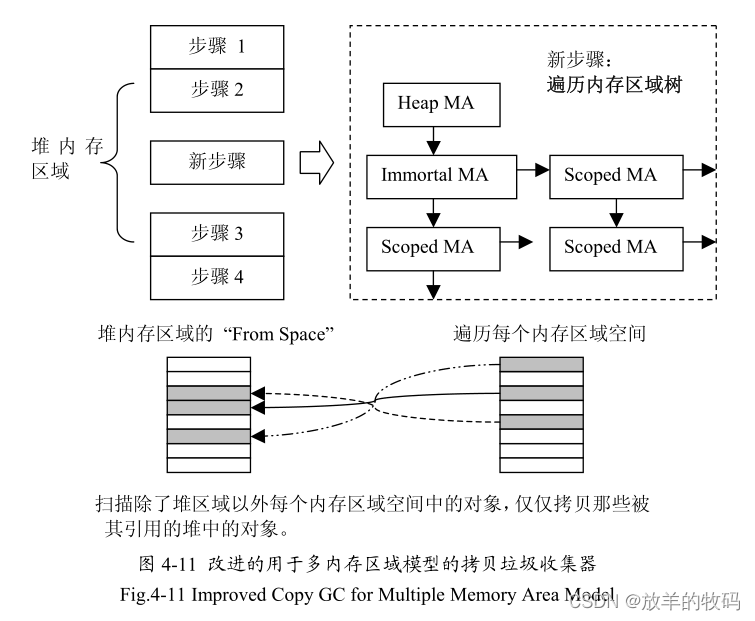
对内存区域的遍历算法的节选代码如下所示:
// 先保证两个永久内存对象 (heap 和 immortal memory) 不被回收
// 把这两个对象直接拷贝到 To Space 中
vm->heap.pMA->pInstance = _svmf_copy_object (env,
vm->heap.pMA->pInstance, &to_space_tail);
if(vm->immortal_mem->pMA!=NULL) // 如果 java 程序没使用 immortal 则为 null
vm->immortal_mem->pMA->pInstance = _svmf_copy_object (env,
vm->immortal_mem->pMA->pInstance, &to_space_tail);
// 扫描 scope stack 和 scope stack temp( 由 executeInArea 产生 )
if(thread->scope_stack!=NULL) {
// 扫描 scope stack
_rtt_scope_stack *pSS = thread->scope_stack;
// 从 scope stack 初始 ma 开始到栈顶遍历这样不会导致重复遍历
for (i=pSS->initialMAIndex; i<=pSS->top; ++i) {
pMA = pSS->item[i].pMA;
// 如果是 heap MA ,则跳过,因为它已经有专门的遍历程序
if(pMA->mem_allocator.fTraceMA==NULL) continue;
// 遍历该 pMA 中的对象的引用字段
pMA->mem_allocator.fTraceMA(env, pMA->mem_allocator.pMA_Space,
&to_space_tail);
// 拷贝自身对象到 To Space, 保证 MA 自身不被回收
pMA->pInstance = _svmf_copy_object (env, pMA->pInstance,
&to_space_tail);
}
pSS = thread->scope_stack_tmp;
// 遍历 scope stack temp
…
}代码主要工作是:
1.避免回收永久内存,如堆内存和不朽内存。
2.遍历所有实时线程的Scope Stack。
3.遍历Scope Stack中的每个内存区域Memory Area.
4.避免回收Scope Stack中的内存区域对象,因为它被Scope Stack引用了,它是由它的父内存区域来回收。




![[Linux]进程](https://img-blog.csdnimg.cn/42383dffcbcd44fe959424c80c447792.png)