文章目录
- 1. 进程控制
- 1.1 进程概述
- 1.1.1 并行和并发
- 1.1.2 PCB
- 1.1.4 进程状态
- 1.1.5 进程命令
- 1.2 进程创建
- 1.2.1 函数
- 1.2.2 fork() 剖析
- 1.3 父子进程
- 1.3.1 进程执行位置
- 1.3.2 循环创建子进程
- 1.3.3 终端显示问题
- 1.3.4 进程数数
- 1.4 execl和execlp函数
- 1.4.1 execl()
- 1.4.2 execlp()
- 1.4.3 函数的使用
- 1.5 进程控制
- 1.5.1 结束进程
- 1.5.2 孤儿进程
- 1.5.3 僵尸进程
- 1.5.4 进程回收
- 1.5.4.1 wait()
- 1.5.4.2 waitpid()
- 2. 管道
- 2.1 管道
- 2.2 匿名管道
- 2.2.1 创建匿名管道
- 2.2.2 进程间通信
- 2.3 有名管道
- 2.3.1 创建有名管道
- 2.3.2 进程间通信
- 2.4 管道的读写行为
- 3. 内存映射(mmap)
- 3.1 创建内存映射区
- 3.2 进程间通信
- 3.2.1 有血缘关系
- 3.2.2 没有血缘关系
- 3.3 拷贝文件
- 4. 共享内存
- 4.1 创建/打开共享内存
- 4.1.1 shmget
- 4.1.2 ftok
- 4.2 关联和解除关联
- 4.2.1 shmat
- 4.2.2 shmdt
- 4.3 删除共享内存
- 4.3.1 shmctl
- 4.3.2 相关shell命令
- 4.3.3 共享内存状态
- 4.4 进程间通信
- 4.5 shm和mmap的区别
- 5. 信号
- 5.1 信号概述
- 5.1.1 信号编号
- 5.1.2 查看信号信息
- 5.1.3 信号的状态
- 5.2 信号相关函数
- 5.2.1 kill/raise/abort
- 5.2.2 定时器
- 5.2.2.1 alarm
- 5.2.2.2 setitimer
- 5.3 信号集
- 5.3.1 阻塞/未决信号集
- 5.3.2 信号集函数
- 5.4 信号捕捉
- 5.4.1 signal
- 5.4.2 sigaction
- 5.5 SIGCHLD 信号
- 6. 守护进程
- 6.1 进程组
- 6.2 会话
- 6.3 创建守护进程
- 6.4 守护进程的应用
1. 进程控制
1.1 进程概述
从严格意义上来讲,程序和进程是两个不同的概念,他们的状态,占用的系统资源都是不同的。
- 程序:就是磁盘上的可执行文件文件, 并且只占用磁盘上的空间,是一个静态的概念。
- 进程:被执行之后的程序叫做进程,不占用磁盘空间,需要消耗系统的内存,CPU资源,每个运行的进程的都对应一个属于自己的虚拟地址空间,这是一个动态的概念。
1.1.1 并行和并发
-
CPU时间片
CPU在某个时间点只能处理一个任务,但是操作系统都支持多任务的,那么在计算机CPU只有一个的情况下是怎么完成多任务处理的呢?每个人分一点,但是又不叫吃饱。
CPU会给每个进程被分配一个时间段,进程得到这个时间片之后才可以运行,使各个程序从表面上看是同时进行的。
如果在时间片结束时进程还在运行,CPU的使用权将被收回,该进程将会被中断挂起等待下一个时间片。
如果进程在时间片结束前阻塞或结束,则CPU当即进行切换,这样就可避免CPU资源的浪费。
因此可以得知,在我们使用的计算机中启动的多个程序,从宏观上看是同时运行的,从微观上看由于CPU一次只能处理一个进程,所有它们是轮流执行的,只不过切换速度太快,感觉不到,因此CPU的核数越多计算机的处理效率越高。 -
并发和并行
这两个概念都可笼统的解释为:多个进程同时运行. 但是他们两个的同时并不是一个概念。Erlang 之父 Joe Armstrong 用一张小孩能看懂的图解释了并发与并行的区别:
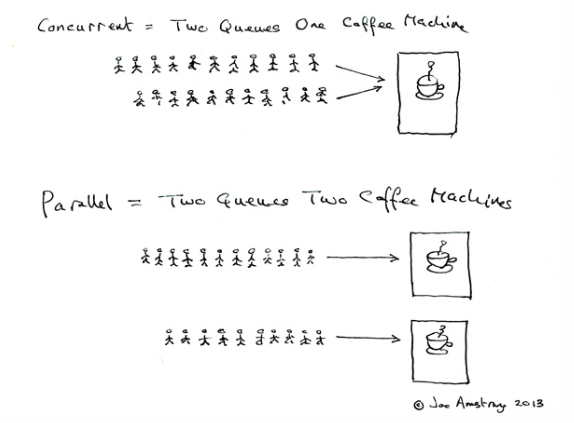
并发:第一幅图是并发。
- 并发的同时运行是一个假象,咖啡机也好CPU也好在某一个时间点只能为某一个个体来服务,因此不可能同时处理多任务,这是通过上图的咖啡机/计算机的CPU快速的时间片切换实现的。
- 并发是针对某一个硬件资源而言的,在某个时间段之内处理的任务的总量,量越大效率越高。
- 并发也可以理解为是不断努力自我升华的结果。
并行:第二幅图是并行。
- 并行的多进程同时运行是真实存在的,可以在同一时刻同时运行多个进程
- 并行需要依赖多个硬件资源,单个是无法实现的(图中有两台咖啡机)。
- 并行可以理解为出生就有天然的硬件优势,资源多办事效率就高。
1.1.2 PCB
PCB - 进程控制块(Processing Control Block),Linux内核的进程控制块本质上是一个叫做
task_struct的结构体。
在这个结构体中记录了进程运行相关的一些信息,介绍一些常用的信息:
-
进程id:每一个进程都一个唯一的进程ID,类型为
pid_t, 本质是一个整形数 -
进程的状态:进程有不同的状态, 状态是一直在变化的,有就绪,运行,挂起,停止等状态。
-
进程对应的虚拟地址空间的信息。
-
描述控制终端的信息,进程在哪个终端启动默认就和哪个终端绑定。
-
当前工作目录:默认情况下, 启动进程的目录就是当前的工作目录
-
umask掩码:在创建新文件的时候,通过这个掩码屏蔽某些用于对文件的操作权限。
-
文件描述符表:每个被分配的文件描述符都对应一个已经打开的磁盘文件
-
和信号相关的信息:在Linux中 调用函数, 键盘快捷键, 执行shell命令等操作都会产生信号。
- 阻塞信号集:记录当前进程中阻塞哪些已产生的信号,使其不能被处理
-
未决信号集:记录在当前进程中产生的哪些信号还没有被处理掉。
-
用户id和组id:当前进程属于哪个用户, 属于哪个用户组
-
会话(Session)和进程组:多个进程的集合叫进程组,多个进程组的集合叫会话。
-
进程可以使用的资源上限:可以使用shell命令
ulimit -a查看详细信息。
1.1.4 进程状态
进程一共有五种状态分别为:创建态,就绪态,运行态,阻塞态(挂起态),退出态(终止态)
其中 创建态 和 退出态 维持的时间是非常 短 的,稍纵即逝。
我们需将就绪态, 运行态, 挂起态,三者之间的状态切换搞明白。
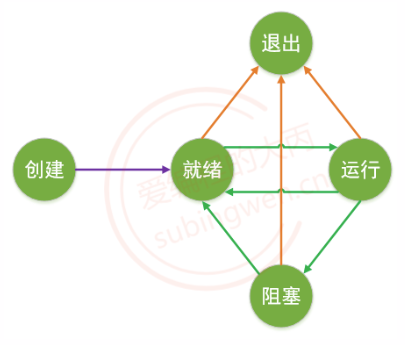
- 就绪态: 等待CPU资源
- 进程被创建出来了,有运行的资格但是还没有运行,需要抢CPU时间片
- 得到CPU时间片,进程开始运行,从就绪态转换为运行态。
- 进程的CPU时间片用完了, 再次失去CPU, 从运行态转换为就绪态。
- 运行态:获取到CPU资源的进程,进程只有在这种状态下才能运行
- 运行态不会一直持续,进程的CPU时间片用完之后, 再次失去CPU,从运行态转换为就绪态
- 只要进程还没有退出,就会在就绪态和运行态之间不停的切换。
- 阻塞态:进程被强制放弃CPU,并且没有抢夺CPU时间片的资格
- 比如: 在程序中调用了某些函数(比如: sleep()),进程又运行态转换为阻塞态(挂起态)
- 当某些条件被满足了(比如:slee() 睡醒了),进程的阻塞状态也就被解除了,进程从阻塞态转换为就绪态。
- 退出态: 进程被销毁, 占用的系统资源被释放了
- 任何状态的进程都可以直接转换为退出态。
1.1.5 进程命令
在研究如何创建进程之前,先来看一下如何在终端中通过命令完成进程相关的操作。
- 查看进程
$ ps aux
- a: 查看所有终端的信息
- u: 查看用户相关的信息
- x: 显示和终端无关的进程信息
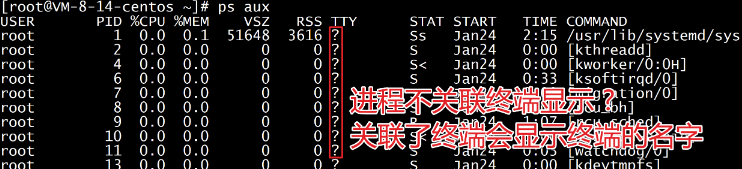
如果特别想知道每个参数控制着哪些信息, 可以通过 ps a, ps u, ps x分别查看。
- 杀死进程
kill命令可以发送某个信号到对应的进程,进程收到某些信号之后默认的处理动作就是退出进程,如果要给进程发送信号,可以先查看一下Linux给我们提供了哪些标准信号。
查看Linux中的标准信号:
$ kill -l
1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP
6) SIGABRT 7) SIGBUS 8) SIGFPE 9) SIGKILL 10) SIGUSR1
11) SIGSEGV 12) SIGUSR2 13) SIGPIPE 14) SIGALRM 15) SIGTERM
16) SIGSTKFLT 17) SIGCHLD 18) SIGCONT 19) SIGSTOP 20) SIGTSTP
21) SIGTTIN 22) SIGTTOU 23) SIGURG 24) SIGXCPU 25) SIGXFSZ
26) SIGVTALRM 27) SIGPROF 28) SIGWINCH 29) SIGIO 30) SIGPWR
31) SIGSYS 34) SIGRTMIN 35) SIGRTMIN+1 36) SIGRTMIN+2 37) SIGRTMIN+3
38) SIGRTMIN+4 39) SIGRTMIN+5 40) SIGRTMIN+6 41) SIGRTMIN+7 42) SIGRTMIN+8
43) SIGRTMIN+9 44) SIGRTMIN+10 45) SIGRTMIN+11 46) SIGRTMIN+12 47) SIGRTMIN+13
48) SIGRTMIN+14 49) SIGRTMIN+15 50) SIGRTMAX-14 51) SIGRTMAX-13 52) SIGRTMAX-12
53) SIGRTMAX-11 54) SIGRTMAX-10 55) SIGRTMAX-9 56) SIGRTMAX-8 57) SIGRTMAX-7
58) SIGRTMAX-6 59) SIGRTMAX-5 60) SIGRTMAX-4 61) SIGRTMAX-3 62) SIGRTMAX-2
63) SIGRTMAX-1 64) SIGRTMAX
9号信号(SIGKILL)的行为是无条件杀死进程,想要杀死哪个进程就可以把这个信号发送给这个进程,操作如下:
# 无条件杀死进程, 进程ID通过 ps aux 可以查看(PID)
$ kill -9 进程ID
$ kill -SIGKILL 进程ID
1.2 进程创建
1.2.1 函数
Linux中进程ID为
pid_t类型,其本质是一个正整数
通过上边的ps aux命令已经得到了验证。PID为1的进程是Linux系统中创建的第一个进程。
- 获取当前进程的进程ID(PID)
#include <sys/types.h>
#include <unistd.h>
pid_t getpid(void);
- 获取当前进程的父进程 ID(PPID)
#include <sys/types.h>
#include <unistd.h>
pid_t getppid(void);
- 创建一个新的进程
#include <unistd.h>
pid_t fork(void);
Linux中看似创建一个新的进程非常简单,函数连参数都没有
实际上如果想要真正理解这个函数还是要下功夫。
1.2.2 fork() 剖析
pid_t fork(void);
启动磁盘上的应用程序, 得到一个进程, 如果在这个启动的进程中调用fork()函数,就会得到一个新的进程,我们习惯将其称之为子进程。
前面说过每个进程都对应一个属于自己的虚拟地址空间,子进程的地址空间是基于父进程的地址空间拷贝出来的,虽然是拷贝但是两个地址空间中存储的信息不可能是完全相同的,下图是拷贝之后父子进程各自的虚拟地址空间:
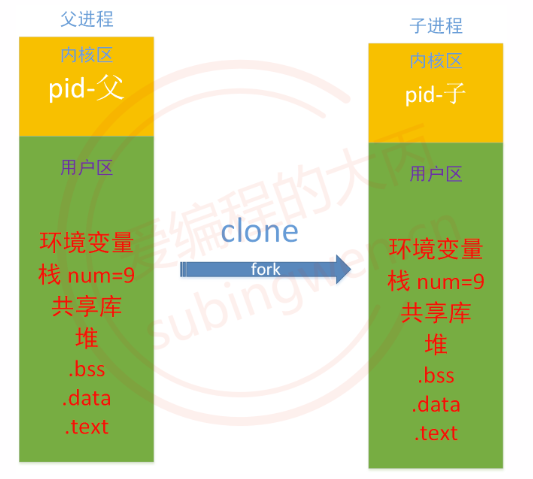
- 相同点:
拷贝完成之后(注意这个时间点),两个地址空间中的用户区数据是相同的。
用户区数据主要数据包括:- 代码区:默认情况下父子进程地址空间中的源代码始终相同。
- 全局数据区:父进程中的全局变量和变量值全部被拷贝一份放到了子进程地址空间中
- 堆区:父进程中的堆区变量和变量值全部被拷贝一份放到了子进程地址空间中
- 动态库加载区(内存映射区):父进程中数据信息被拷贝一份放到了子进程地址空间中
- 栈区:父进程中的栈区变量和变量值全部被拷贝一份放到了子进程地址空间中
- 环境变量:默认情况下,父子进程地址空间中的环境变量始终相同。
- 文件描述符表:
父进程中被分配的文件描述符都会拷贝到子进程中,在子进程中可以使用它们打开对应的文件
- 区别:
- 父子进程各自的虚拟地址空间是相互独立的,不会互相干扰和影响。
- 父子进程地址空间中代码区代码虽然相同,但是父子进程执行的代码逻辑可能是不同的。
- 由于父子进程可能执行不同的代码逻辑,因此地址空间拷贝完成之后,
全局数据区, 栈区, 堆区, 动态库加载区(内存映射区)数据会各自发生变化,由于地址空间是相互独立的,因此不会互相覆盖数据。 - 由于每个进都有自己的进程ID,因此内核区存储的父子进程ID是不同的。
- 进程启动之后进入就绪态,运行需要争抢CPU时间片而且可能执行不同的业务逻辑,所以父子进程的状态可能是不同的。
- fork() 调用成功之后,会返回两个值,父子进程的返回值是不同的。
该函数调用成功之后,从一个虚拟地址空间变成了两个虚拟地址空间,每个地址空间中都会将 fork() 的返回值记录下来这就是为什么会得到两个返回值的原因。- 父进程的虚拟地址空间中将该返回值标记为一个大于0的数(其实记录的是子进程的进程ID)
- 子进程的虚拟地址空间中将该返回值标记 0
- 在程序中需要通过 fork() 的返回值来判断当前进程是子进程还是父进程。
int main()
{
// 在父进程中创建子进程
pid_t pid = fork();
printf("当前进程fork()的返回值: %d\n", pid);
if(pid > 0)
{
// 父进程执行的逻辑
printf("我是父进程, pid = %d\n", getpid());
}
else if(pid == 0)
{
// 子进程执行的逻辑
printf("我是子进程, pid = %d, 我爹是: %d\n", getpid(), getppid());
}
else // pid == -1
{
// 创建子进程失败了
}
// 不加判断, 父子进程都会执行这个循环
for(int i=0; i<5; ++i)
{
printf("%d\n", i);
}
return 0;
}
1.3 父子进程
1.3.1 进程执行位置
在父进程中成功创建了子进程,子进程就拥有父进程代码区的所有代码,那么子进程中的代码是在什么位置开始运行的呢?
父进程是从main()函数开始运行的,子进程是在父进程中调用fork()函数之后被创建, 子进程就从fork()之后开始向下执行代码。

上图中演示了父子进程中代码的执行流程,可以看到如果在程序中对fork()的返回值做了判断,就可以控制父子进程的行为,如果没有做任何判断这个代码块父子进程都可以执行。
在编写多进程程序的时候,一定要将代码想象成多份进行分析,因为直观上看代码就一份,但实际上数据都是多份,且多份数据中变量名都相同,但是他们的值却不一定相同。
1.3.2 循环创建子进程
掌握了进程创建函数之后,实现一个简单的功能,在一个父进程中循环创建3个子进程,也就是最后需要得到4个进程,1个父进程,3个子进程
为了方便验证程序的正确性,要求在程序中打印出每个进程的进程ID。
// process_loop.c
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
int main()
{
for(int i=0; i<3; ++i)
{
pid_t pid = fork();
printf("当前进程pid: %d\n", getpid());
}
return 0;
}
编译并执行上面的代码,得到了如下结果:
# 编译
$ gcc process_loop.c
# 执行
$ ./a.out
# 最终得到了 8个进程
当前进程pid: 18774 ------ 1
当前进程pid: 18774 ------ 1
当前进程pid: 18774 ------ 1
当前进程pid: 18777 ------ 2
当前进程pid: 18776 ------ 3
当前进程pid: 18776 ------ 3
当前进程pid: 18775 ------ 4
当前进程pid: 18775 ------ 4
当前进程pid: 18775 ------ 4
当前进程pid: 18778 ------ 5
当前进程pid: 18780 ------ 6
当前进程pid: 18779 ------ 7
当前进程pid: 18779 ------ 7
当前进程pid: 18781 ------ 8
通过程序打印的信息发现程序循环了三次,最终得到了8个进程,也就是创建出了7个子进程,没有在程序中加条件控制,所有的代码父子进程都是有资格执行的。
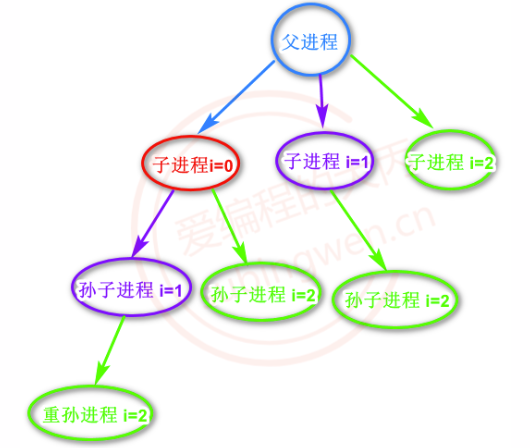
上图中的树状结构,蓝色节点代表父进程:
- 循环第一次 i = 0,创建出一个子进程,即红色节点,子进程变量值来自父进程拷贝,因此 i=0
- 循环第二次 i = 1,蓝色父进程和红色子进程都去创建子进程,得到两个紫色进程,子进程变量值来自父进程拷贝,因此 i=1
- 循环第三次 i = 2,蓝色父进程和红色、紫色子进程都去创建子进程,因此得到4个绿色子进程,子进程变量值来自父进程拷贝,因此 i=2
- 循环第四次 i = 3,所有进程都不满足条件
for(int i=0; i<3; ++i)因此不进入循环,退出了。
解决方案:可以只让父进程创建子进程,如果是子进程不让其继续创建子进程,只需在程序中添加关于父子进程的判断即可。
// 需要在上边的程序中控制不让子进程, 再创建子进程即可
// process_loop.c
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
int main()
{
pid_t pid;
// 在循环中创建子进程
for(int i=0; i<3; ++i)
{
pid = fork();
if(pid == 0)
{
// 不让子进程执行循环, 直接跳出
break;
}
}
printf("当前进程pid: %d\n", getpid());
return 0;
}
最后编译并执行程序,查看最终结果,可以看到最后确实得到了4个不同的进程
pid最小的为父进程,其余为子进程:
# 编译
$ gcc process_loop.c
# 执行
$ ./a.out
当前进程pid: 2727
当前进程pid: 2730
当前进程pid: 2729
当前进程pid: 2728
在多进程序中,进程的执行顺序是没有规律的,因为所有的进程都需要在就绪态争抢CPU时间片,抢到了就执行,抢不到就不执行
默认进程的优先级是相同的,操作系统不会让某一个进程一直抢不到CPU时间片。
1.3.3 终端显示问题
在执行多进程程序的时候,经常会遇到下图中的问题
看似进程还没有执行完成,貌似因为什么被阻塞了,实际上终端是正常的,通过键盘输入一些命令,终端也能接受输入并输出相关信息,那为什么终端会显示成这样呢?
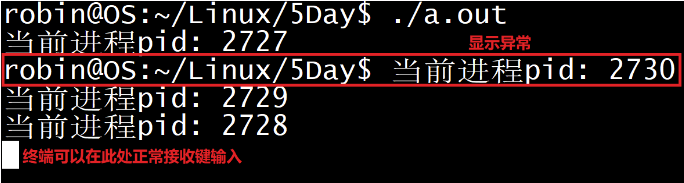
-
a.out 进程启动之后,共创建了3个子进程,其实 a.out 也是有父进程的就是当前的终端
-
终端只能检测到 a.out 进程的状态,a.out执行期间终端切换到后台,a.out执行完毕之后终端切换回前台
-
当终端切换到前之后,a.out的子进程还没有执行完毕,当子进程输出的信息就显示到终端命令提示符的后边了,导致终端显示有问题,但是此时终端是可以接收键盘输入的,只是看起来不美观而已。
-
想要解决这个问题,需要让所有子进程退出之后再退出父进程,比如:在父进程代码中调用 sleep()
pid_t pid = fork();
if(pid > 0)
{
sleep(3); // 让父进程睡一会儿
}
else if(pid == 0)
{
// 子进程
}
1.3.4 进程数数
当父进程创建一个子进程,那么父子进程之间可以通过全局变量互动,实现交替数数的功能吗?
// number.c
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
// 定义全局变量
int number = 10;
int main()
{
printf("创建子进程之前 number = %d\n", number);
pid_t pid = fork();
// 父子进程都会执行这一行
printf("当前进程fork()的返回值: %d\n", pid);
//如果是父进程
if(pid > 0)
{
printf("我是父进程, pid = %d, number = %d\n", getpid(), ++number);
printf("父进程的父进程(终端进程), pid = %d\n", getppid());
sleep(1);
}
else if(pid == 0)
{
// 子进程
number += 100;
printf("我是子进程, pid = %d, number = %d\n", getpid(), number);
printf("子进程的父进程, pid = %d\n", getppid());
}
return 0;
}
编译程序并测试:
$ gcc number.c
$ ./a.out
创建子进程之前 number = 10
当前进程fork()的返回值: 3513
当前进程fork()的返回值: 0
我是子进程, pid = 3513, number = 110
子进程的父进程, pid = 3512
我是父进程, pid = 3512, number = 11
#没有接着子进程的110继续数,父子进程各玩各的,测试失败
父进程的父进程(终端进程), pid = 2175
通过验证得到结论:两个进程中是不能通过全局变量实现数据交互的
因为每个进程都有自己的地址空间,两个同名全局变量存储在不同的虚拟地址空间中,二者没有任何关联性。
如果要进行进程间通信需要使用:管道,共享内存,本地套接字,内存映射区,消息队列等方式。
1.4 execl和execlp函数
在项目开发过程中,有时候有这种需求,需要通过现在运行的进程启动磁盘上的另一个可执行程序,也就是通过一个进程启动另一个进程,这种情况下我们可以使用 exec族函数
//函数原型
#include <unistd.h>
extern char **environ;
int execl(const char *path, const char *arg, ...
/* (char *) NULL */);
int execlp(const char *file, const char *arg, ...
/* (char *) NULL */);
int execle(const char *path, const char *arg, ...
/*, (char *) NULL, char * const envp[] */);
int execv(const char *path, char *const argv[]);
int execvp(const char *file, char *const argv[]);
int execvpe(const char *file, char *const argv[],
char *const envp[]);
这些函数执行成功后不会返回,因为调用进程的实体,包括代码段,数据段和堆栈等都已经被新的内容取代(也就是说用户区数据基本全部被替换掉了),只留下进程ID等一些表面上的信息仍保持原样.
只有调用失败了,它们才会返回一个 -1,从原程序的调用点接着往下执行。
也就是说exec族函数并没有创建新进程的能力
让启动的新进程寄生到自己虚拟地址空间之内,并挖空了自己的地址空间用户区,把新启动的进程数据填充进去。
exec族函数中最常用的有两个execl()和execlp(),这两个函数是对其他4个函数做了进一步的封装,介绍一下。
1.4.1 execl()
该函数可用于执行任意一个可执行程序,函数需要通过指定的文件路径才能找到这个可执行程序。
#include <unistd.h>
// 变参函数
int execl(const char *path, const char *arg, ...);
- 参数:
path: 要启动的可执行程序的路径, 推荐使用绝对路径arg: ps aux 查看进程的时候, 启动的进程的名字, 可以随意指定, 一般和要启动的可执行程序名相同...: 要执行的命令需要的参数,可以写多个,最后以 NULL 结尾,表示参数指定完了。
- 返回值:如果这个函数执行成功, 没有返回值,如果执行失败, 返回 -1
1.4.2 execlp()
该函数常用于执行已经设置了环境变量的可执行程序,函数中的 p 就是path,也是说这个函数会自动搜索系统的环境变量PATH
因此使用这个函数执行可执行程序不需要指定路径,只需要指定出名字即可。
// p == path
int execlp(const char *file, const char *arg, ...);
- 参数:
file: 可执行程序的名字- 在环境变量PATH中,可执行程序可以不加路径
- 没有在环境变量PATH中, 可执行程序需要指定绝对路径
arg: ps aux 查看进程的时候, 启动的进程的名字, 可以随意指定, 一般和要启动的可执行程序名相同...: 要执行的命令需要的参数,可以写多个,最后以 NULL 结尾,表示参数指定完了。
- 返回值:如果这个函数执行成功, 没有返回值,如果执行失败, 返回 -1
1.4.3 函数的使用
一般不会在进程中直接调用,如果直接调用这个进程的代码区代码被替换也就不能按照原来的流程工作了。
一般在调用这些函数的时候都会先创建一个子进程,在子进程中调用 exec 族函数,子进程的用户区数据被替换掉开始执行新的程序中的代码逻辑,但是父进程不受任何影响仍然可以继续正常工作。
execl() 或者 execlp() 函数的使用方法如下:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
int main()
{
// 创建子进程
pid_t pid = fork();
// 在子进程中执行磁盘上的可执行程序
if(pid == 0)
{
// 磁盘上的可执行程序 /bin/ps
#if 1
execl("/bin/ps", "title", "aux", NULL);
// 也可以这么写
// execl("/bin/ps", "title", "a", "u", "x", NULL);
#else
execlp("ps", "title", "aux", NULL);
// 也可以这么写
// execl("ps", "title", "a", "u", "x", NULL);
#endif
// 如果成功,当前子进程的代码区被ps中的代码区代码替换
// 下面的所有代码都不会执行
// 如果函数调用失败了,才会继续执行下面的代码
perror("execl");
printf("++++++++++++++++++++++++\n");
printf("++++++++++++++++++++++++\n");
printf("++++++++++++++++++++++++\n");
printf("++++++++++++++++++++++++\n");
printf("++++++++++++++++++++++++\n");
printf("++++++++++++++++++++++++\n");
}
else if(pid > 0)
{
printf("我是父进程.....\n");
}
return 0;
}

1.5 进程控制
进程控制主要是指进程的退出, 进程的回收和进程的特殊状态 孤儿进程和僵尸进程。
1.5.1 结束进程
想要直接退出某个进程可以在程序的任何位置调用exit()或者_exit()函数。
函数的参数相当于退出码, 如果参数值为 0 程序退出之后的状态码就是0, 如果是100退出的状态码就是100。
// 专门退出进程的函数, 在任何位置调用都可以
// 标准C库函数
#include <stdlib.h>
void exit(int status);
// Linux的系统函数
// 可以这么理解, 在linux中 exit() 函数 封装了 _exit()
#include <unistd.h>
void _exit(int status);
在 main 函数中直接使用 return 也可以退出进程,
假如是在一个普通函数中调用 return 只能返回到调用者的位置,而不能退出进程。
// ***** return 必须要在main()函数中调用, 才能退出进程 *****
// 举例:
// 没有问题的例子
int main()
{
return 0; // 进程退出了
}
// 不能退出的例子 //
int func()
{
return 666; // 返回到调用者调用该函数的位置, 返回到 main() 函数的第19行
}
int main()
{
// 调用这个函数, 当前进程不能退出
int ret = func();
}
1.5.2 孤儿进程
在一个启动的进程中创建子进程,这时候父子进程同时运行,但是父进程由于某种原因先退出了,子进程还在运行,这时候这个子进程就可以被称之为孤儿进程。
操作系统是非常关爱运行的每一个进程的,当检测到某一个进程变成了孤儿进程,这时候系统中就会有一个固定的进程领养这个孤儿进程。
如果使用Linux没有桌面终端,这个领养孤儿进程的进程就是 init 进程(PID=1)
如果有桌面终端,这个领养孤儿进程就是桌面进程。
那么问题来了,系统为什么要领养这个孤儿进程呢?
在子进程退出的时候, 进程中的用户区可以自己释放, 但是进程内核区的pcb资源自己无法释放,必须要由父进程来释放子进程的pcb资源,孤儿进程被领养之后,这件事爹就可以代劳,避免系统资源的浪费。
下面这段代码就可以得到一个孤儿进程:
int main()
{
// 创建子进程
pid_t pid = fork();
// 父进程
if(pid > 0)
{
printf("我是父进程, pid=%d\n", getpid());
}
else if(pid == 0)
{
sleep(1); // 强迫子进程睡眠1s, 这个期间, 父进程退出, 当前进程变成了孤儿进程
// 子进程
printf("我是子进程, pid=%d, 父进程ID: %d\n", getpid(), getppid());
}
return 0;
}
# 程序输出的结果
$ ./a.out
我是父进程, pid=22459
我是子进程, pid=22460, 父进程ID: 1 # 父进程向退出, 子进程变成孤儿进程, 子进程被1号进程回收
1.5.3 僵尸进程
在一个启动的进程中创建子进程,这时候就有了父子两个进程,父进程正常运行, 子进程先与父进程结束, 子进程无法释放自己的PCB资源, 需要父进程来做这个件事儿, 但是如果父进程也不管, 这时候子进程就变成了僵尸进程。
僵尸进程不能将它看成是一个正常的进程,这个进程已经死亡,用户区资源已经被释放,只是还占用一些内核资源(PCB)。
运行下面的代码就可以得到一个僵尸进程了:
int main()
{
pid_t pid;
// 创建子进程
for(int i=0; i<5; ++i)
{
pid = fork();
if(pid == 0)
{
break;
}
}
// 父进程
if(pid > 0)
{
// 需要保证父进程一直在运行
// 一直运行不退出, 并且也做回收, 就会出现僵尸进程
while(1)
{
printf("我是父进程, pid=%d\n", getpid());
sleep(1);
}
}
else if(pid == 0)
{
// 子进程, 执行这句代码之后, 子进程退出了
printf("我是子进程, pid=%d, 父进程ID: %d\n", getpid(), getppid());
}
return 0;
}
# ps aux 查看进程信息
# Z+ --> 这个进程是僵尸进程, defunct, 表示进程已经死亡
robin 22598 0.0 0.0 4352 624 pts/2 S+ 10:11 0:00 ./app
robin 22599 0.0 0.0 0 0 pts/2 Z+ 10:11 0:00 [app] <defunct> # 子进程
robin 22600 0.0 0.0 0 0 pts/2 Z+ 10:11 0:00 [app] <defunct> # 子进程
robin 22601 0.0 0.0 0 0 pts/2 Z+ 10:11 0:00 [app] <defunct> # 子进程
robin 22602 0.0 0.0 0 0 pts/2 Z+ 10:11 0:00 [app] <defunct> # 子进程
robin 22603 0.0 0.0 0 0 pts/2 Z+ 10:11 0:00 [app] <defunct> # 子进程
消灭僵尸进程的方法是杀死这个僵尸进程的父进程,这样僵尸进程的资源就被系统回收了.
kill -9僵尸进程PID的方式是不能消灭僵尸进程的,这个命令只对活着的进程有效,僵尸进程已经死了,鞭尸是不能解决问题的。
1.5.4 进程回收
为了避免僵尸进程的产生,一般我们会在父进程中进行子进程的资源回收
回收方式有两种,一种是阻塞方式wait(),一种是非阻塞方式waitpid()。
1.5.4.1 wait()
这是个阻塞函数,如果没有子进程退出, 函数会一直阻塞等待
当检测到子进程退出了, 该函数阻塞解除回收子进程资源。
这个函数被调用一次, 只能回收一个子进程的资源,如有多个子进程需要资源回收, 函数需被调用多次。
// 函数原型
// man 2 wait
#include <sys/wait.h>
pid_t wait(int *status);
- 参数:传出参数,通过传递出的信息判断回收的进程是怎么退出的,如果不需要该信息可以指定为 NULL。取出整形变量中的数据需要使用一些宏函数,具体操作方式如下:
WIFEXITED(status): 返回1, 进程是正常退出的WEXITSTATUS(status):得到进程退出时候的状态码,相当于 return 后边的数值, 或者 exit()函数的参数WIFSIGNALED(status): 返回1, 进程是被信号杀死了WTERMSIG(status): 获得进程是被哪个信号杀死的,会得到信号的编号
- 返回值:
- 成功:返回被回收的子进程的进程ID
- 失败: -1
- 没有子进程资源可以回收了, 函数的阻塞会自动解除, 返回-1
- 回收子进程资源的时候出现了异常
下面代码演示了如何通过 wait()回收多个子进程资源:
// wait 函数回收子进程资源
#include <sys/wait.h>
int main()
{
pid_t pid;
// 创建子进程
for(int i=0; i<5; ++i)
{
pid = fork();
if(pid == 0)
{
break;
}
}
// 父进程
if(pid > 0)
{
// 需要保证父进程一直在运行
while(1)
{
// 回收子进程的资源
// 子进程由多个, 需要循环回收子进程资源
pid_t ret = wait(NULL);
if(ret > 0)
{
printf("成功回收了子进程资源, 子进程PID: %d\n", ret);
}
else
{
printf("回收失败, 或者是已经没有子进程了...\n");
break;
}
printf("我是父进程, pid=%d\n", getpid());
}
}
else if(pid == 0)
{
// 子进程, 执行这句代码之后, 子进程退出了
printf("我是子进程, pid=%d, 父进程ID: %d\n", getpid(), getppid());
}
return 0;
}
1.5.4.2 waitpid()
waitpid() 函数可以看做是 wait() 函数的升级版,通过该函数可以控制回收子进程资源的方式是阻塞还是非阻塞,另外还可以通过该函数进行精准打击,可以精确指定回收某个或者某一类或者是全部子进程资源。
// 函数原型
// man 2 waitpid
#include <sys/wait.h>
// 这个函数可以设置阻塞, 也可以设置为非阻塞
// 这个函数可以指定回收哪些子进程的资源
pid_t waitpid(pid_t pid, int *status, int options);
- 参数:
-
pid:
- -1:回收所有的子进程资源, 和wait()是一样的, 无差别回收,并不是一次性就可以回收多个, 也是需要循环回收的
- 大于0:指定回收某一个进程的资源 ,pid是要回收的子进程的进程ID
- 0:回收当前进程组的所有子进程ID
- 小于 -1:pid 的绝对值代表进程组ID,表示要回收这个进程组的所有子进程资源
-
status: NULL, 和wait的参数是一样的
-
options: 控制函数是阻塞还是非阻塞
- 0: 函数行为是阻塞的 ==> 和wait一样
- WNOHANG: 函数行为是非阻塞的
-
- 返回值
- 如果函数是非阻塞的, 并且子进程还在运行, 返回0
- 成功: 得到子进程的进程ID
- 失败: -1
- 没有子进程资源可以回收了, 函数如果是阻塞的, 阻塞会解除, 直接返回-1
- 回收子进程资源的时候出现了异常
下面代码演示了如何通过 waitpid()阻塞回收多个子进程资源:
// 和wait() 行为一样, 阻塞
#include <sys/wait.h>
int main()
{
pid_t pid;
// 创建子进程
for(int i=0; i<5; ++i)
{
pid = fork();
if(pid == 0)
{
break;
}
}
// 父进程
if(pid > 0)
{
// 需要保证父进程一直在运行
while(1)
{
// 回收子进程的资源
// 子进程由多个, 需要循环回收子进程资源
int status;
pid_t ret = waitpid(-1, &status, 0); // == wait(NULL);
if(ret > 0)
{
printf("成功回收了子进程资源, 子进程PID: %d\n", ret);
// 判断进程是不是正常退出
if(WIFEXITED(status))
{
printf("子进程退出时候的状态码: %d\n", WEXITSTATUS(status));
}
if(WIFSIGNALED(status))
{
printf("子进程是被这个信号杀死的: %d\n", WTERMSIG(status));
}
}
else
{
printf("回收失败, 或者是已经没有子进程了...\n");
break;
}
printf("我是父进程, pid=%d\n", getpid());
}
}
else if(pid == 0)
{
// 子进程, 执行这句代码之后, 子进程退出了
printf("===我是子进程, pid=%d, 父进程ID: %d\n", getpid(), getppid());
}
return 0;
}
下面代码演示了如何通过 waitpid()非阻塞回收多个子进程资源:
// 非阻塞处理
#include <sys/wait.h>
int main()
{
pid_t pid;
// 创建子进程
for(int i=0; i<5; ++i)
{
pid = fork();
if(pid == 0)
{
break;
}
}
// 父进程
if(pid > 0)
{
// 需要保证父进程一直在运行
while(1)
{
// 回收子进程的资源
// 子进程由多个, 需要循环回收子进程资源
// 子进程退出了就回收,
// 没退出就不回收, 返回0
int status;
pid_t ret = waitpid(-1, &status, WNOHANG); // 非阻塞
if(ret > 0)
{
printf("成功回收了子进程资源, 子进程PID: %d\n", ret);
// 判断进程是不是正常退出
if(WIFEXITED(status))
{
printf("子进程退出时候的状态码: %d\n", WEXITSTATUS(status));
}
if(WIFSIGNALED(status))
{
printf("子进程是被这个信号杀死的: %d\n", WTERMSIG(status));
}
}
else if(ret == 0)
{
printf("子进程还没有退出, 不做任何处理...\n");
}
else
{
printf("回收失败, 或者是已经没有子进程了...\n");
break;
}
printf("我是父进程, pid=%d\n", getpid());
}
}
else if(pid == 0)
{
// 子进程, 执行这句代码之后, 子进程退出了
printf("===我是子进程, pid=%d, 父进程ID: %d\n", getpid(), getppid());
}
return 0;
}
2. 管道
2.1 管道
管道的是进程间通信(IPC - InterProcess Communication)的一种方式,管道的本质其实就是内核中的一块内存(或者叫内核缓冲区)
这块缓冲区中的数据存储在一个环形队列中,因为管道在内核里边,因此我们不能直接对其进行任何操作。
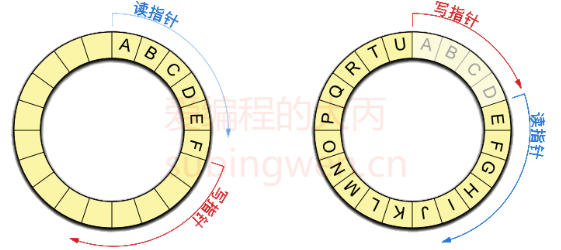
因为管道数据是通过队列来维护的,我们先来分析一个管道中数据的特点:
-
管道对应的内核缓冲区大小是固定的,默认为4k(也就是队列最大能存储4k数据)
-
管道分为两部分:读端和写端(队列的两端),数据从写端进入管道,从读端流出管道。
-
管道中的数据只能读一次,做一次读操作之后数据也就没有了(读数据相当于出队列)。
-
管道是单工的:数据只能单向流动, 数据从写端流向读端。
-
对管道的操作(读、写)默认是阻塞的
- 读管道:管道中没有数据,读操作被阻塞,当管道中有数据之后阻塞才能解除
- 写管道:管道被写满了,写数据的操作被阻塞,当管道变为不满的状态,写阻塞解除
管道在内核中, 不能直接对其进行操作,通过什么方式去读写管道呢?
其实管道操作就是文件IO操作,内核中管道的两端分别对应两个文件描述符
通过写端的文件描述符把数据写入到管道中,通过读端的文件描述符将数据从管道中读出来。
读写管道的函数就是Linux中的文件IO函数 read/write
// 读管道
ssize_t read(int fd, void *buf, size_t count);
// 写管道的函数
ssize_t write(int fd, const void *buf, size_t count);
分析一下为什么可以使用管道进行进程间通信,看一下图片:
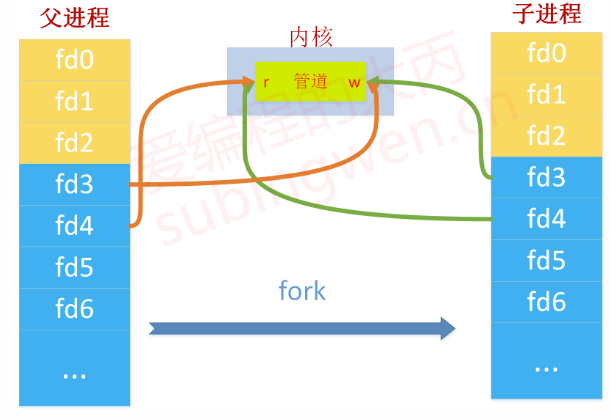
在上图中假设父进程一系列操作:可以通过文件描述符表中的文件描述符fd3写管道,通过fd4读管道,然后再通过 fork() 创建出子进程,那么在父进程中被分配的文件描述符 fd3, fd4也就被拷贝到子进程中,子进程通过 fd3可以将数据写入到内核的管道中,通过fd4将数据从管道中读出来。
也就是说管道是独立于任何进程的,并且充当了两个进程用于数据通信的载体,只要两个进程能够得到同一个管道的入口和出口(读端和写端的文件描述符),那么他们之间就可以通过管道进行数据的交互。
2.2 匿名管道
2.2.1 创建匿名管道
匿名管道是管道的一种,既然是匿名也就是说这个管道没有名字,但其本质不变,就是位于内核中的一块内存,匿名管道拥有上面介绍的管道的所有特性
额外我们需知,匿名管道只能实现有血缘关系的进程间通信,如:父子进程,兄弟进程,爷孙进程,叔侄进程。
// 创建匿名函数的函数原型
#include <unistd.h>
// 创建一个匿名的管道, 得到两个可用的文件描述符
int pipe(int pipefd[2]);
- 参数:传出参数,需要传递一个整形数组的地址,数组大小为 2,也就是说最终会传出两个元素
pipefd[0]: 对应管道读端的文件描述符,通过它可以将数据从管道中读出pipefd[1]: 对应管道写端的文件描述符,通过它可以将数据写入到管道中
- 返回值:成功返回 0,失败返回 -1
2.2.2 进程间通信
使用匿名管道只能够实现有血缘关系的进程间通信,要求写一段程序完成下边的功能:
需求描述:
在父进程中创建一个子进程, 父子进程分别执行不同的操作:
- 子进程: 执行一个shell命令 "ps aux", 将命令的结果传递给父进程
- 父进程: 将子进程命令的结果输出到终端
需求分析:
- 子进程中执行shell命令相当于启动一个磁盘程序,因此需要使用 execl()/execlp()函数
- execlp(“ps”, “ps”, “aux”, NULL)
- 子进程中执行完shell命令直接就可以在终端输出结果,如果将这些信息传递给父进程呢?
- 数据传递需要使用管道,子进程需要将数据写入到管道中
- 将默认输出到终端的数据写入到管道就需要进行输出的重定向,需要使用
dup2()做这件事情dup2(fd[1], STDOUT_FILENO);
- 父进程需要读管道,将从管道中读出的数据打印到终端
- 父进程最后需要释放子进程资源,防止出现僵尸进程
在使用管道进行进程间通信的注意事项:必须要保证数据在管道中的单向流动。
这句话怎么理解呢,通过下面的图来分析一下:
第一步: 在父进程中创建了匿名管道,得到了两个分配的文件描述符,fd3操作管道的读端,fd4操作管道的写端。
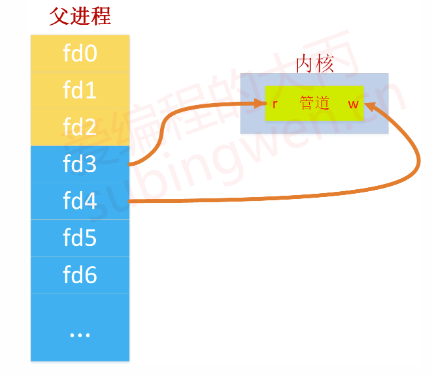
第二步:父进程创建子进程,父进程的文件描述符被拷贝,在子进程的文件描述符表中也得到了两个被分配的可以使用的文件描述符,通过fd3读管道,通过fd4写管道。通过下图可以看到管道中数据的流动不是单向的,有以下这么几种情况:
父进程通过fd4将数据写入管道,然后父进程再通过fd3将数据从管道中读出
父进程通过fd4将数据写入管道,然后子进程再通过fd3将数据从管道中读出
子进程通过fd4将数据写入管道,然后子进程再通过fd3将数据从管道中读出
子进程通过fd4将数据写入管道,然后父进程再通过fd3将数据从管道中读出
前边说到过,管道行为默认是阻塞的,假设子进程通过写端将数据写入管道,父进程的读端将数据读出,这样子进程的读端就读不到数据,导致子进程阻塞在读管道的操作上,这样就会给程序的执行造成一些不必要的影响。
如果我们本来也没有打算让进程读或者写管道,那么就可以将进程操作的读端或者写端关闭。
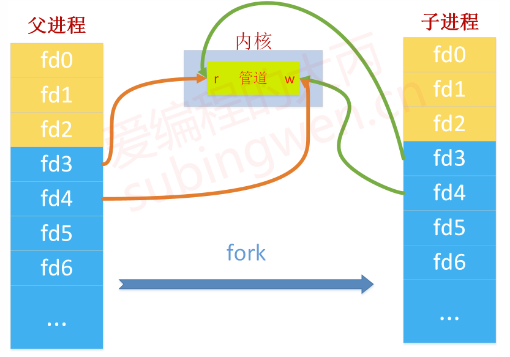
第三步:为了避免两个进程都读管道,但是可能其中某个进程由于读不到数据而阻塞的情况,我们可以关闭进程中用不到的那一端的文件描述符,这样数据就只能单向的从一端流向另外一端了,如下图,我们关闭了父进程的写端,关闭了子进程的读端:
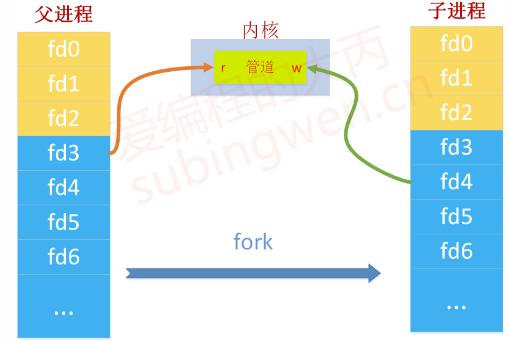
根据上面的分析,最终可以写出下面的代码:
// 管道的数据是单向流动的:
// 操作管道的是两个进程, 进程A读管道, 需要关闭管道的写端, 进程B写管道, 需要关闭管道的读端
// 如果不做上述的操作, 会对程序的结果造成一些影响, 对管道的操作无法结束
#include <fcntl.h>
#include <sys/wait.h>
int main()
{
// 1. 创建匿名管道, 得到两个文件描述符
int fd[2];
int ret = pipe(fd);
if(ret == -1)
{
perror("pipe");
exit(0);
}
// 2. 创建子进程 -> 能够操作管道的文件描述符被复制到子进程中
pid_t pid = fork();
if(pid == 0)
{
// 关闭读端
close(fd[0]);
// 3. 在子进程中执行 execlp("ps", "ps", "aux", NULL);
// 在子进程中完成输出的重定向, 原来输出到终端现在要写管道
// 进程打印数据默认输出到终端, 终端对应的文件描述符: stdout_fileno
// 标准输出 重定向到 管道的写端
dup2(fd[1], STDOUT_FILENO);
execlp("ps", "ps", "aux", NULL);
perror("execlp");
}
// 4. 父进程读管道
else if(pid > 0)
{
// 关闭管道的写端
close(fd[1]);
// 5. 父进程打印读到的数据信息
char buf[4096];
// 读管道
// 如果管道中没有数据, read会阻塞
// 有数据之后, read解除阻塞, 直接读数据
// 需要循环读数据, 管道是有容量的, 写满之后就不写了
// 数据被读走之后, 继续写管道, 那么就需要再继续读数据
while(1)
{
memset(buf, 0, sizeof(buf));
int len = read(fd[0], buf, sizeof(buf));
if(len == 0)
{
// 管道的写端关闭了, 如果管道中没有数据, 管道读端不会阻塞
// 没数据直接返回0, 如果有数据, 将数据读出, 数据读完之后返回0
break;
}
printf("%s, len = %d\n", buf, len);
}
close(fd[0]);
// 回收子进程资源
wait(NULL);
}
return 0;
}
2.3 有名管道
2.3.1 创建有名管道
有名管道拥有管道的所有特性,之所以称为有名是因管道在磁盘上有实体文件, 文件类型为p ,有名管道文件大小永为0,因有名管道是将数据存储到内存的缓冲区中,打开这个磁盘上的管道文件就可以得到操作有名管道的文件描述符,通过文件描述符读写管道存储在内核中的数据。
有名管道也可称为 fifo (first in first out),有名管道既可进行有血缘关系的进程间通信,也可进行没有血缘关系的进程间通信。
创建有名管道的方式有两种,一种是通过命令,一种是通过函数。
- 通过命令
$ mkfifo 有名管道的名字
- 通过函数
#include <sys/types.h>
#include <sys/stat.h>
// int open(const char *pathname, int flags, mode_t mode);
int mkfifo(const char *pathname, mode_t mode);
- 参数:
- pathname: 要创建的有名管道的名字
- mode: 文件的操作权限, 和open()的第三个参数一个作用,最终权限:
(mode & ~umask)
- 返回值:创建成功返回 0,失败返回 -1
2.3.2 进程间通信
不管有血缘关系还是没血缘关系,使用有名管道实现进程间通信的方式是相同的
就是在两个进程中分别以读、写的方式打开磁盘上的管道文件
得到用于读管道、写管道的文件描述符,就可调用对应的read()、write()函数进行读写操作了。
有名管道操作需要通过 open() 操作得到读写管道的文件描述符,如果只是读端打开了或者只是写端打开了,进程会阻塞在这里不会向下执行
直到在另一个进程中将管道的对端打开,当前进程的阻塞也就解除了。
所以当发现进程阻塞在了open()函数上不要感到惊讶。·
- 写管道的进程
1. 创建有名管道文件
mkfifo()
2. 打开有名管道文件, 打开方式是 o_wronly
int wfd = open("xx", O_WRONLY);
3. 调用write函数写文件 ==> 数据被写入管道中
write(wfd, data, strlen(data));
4. 写完之后关闭文件描述符
close(wfd);
#include <fcntl.h>
#include <sys/stat.h>
int main()
{
// 1. 创建有名管道文件
int ret = mkfifo("./testfifo", 0664);
if(ret == -1)
{
perror("mkfifo");
exit(0);
}
printf("管道文件创建成功...\n");
// 2. 打开管道文件
// 因为要写管道, 所有打开方式, 应该指定为 O_WRONLY
// 如果先打开写端, 读端还没有打开, open函数会阻塞, 当读端也打开之后, open解除阻塞
int wfd = open("./testfifo", O_WRONLY);
if(wfd == -1)
{
perror("open");
exit(0);
}
printf("以只写的方式打开文件成功...\n");
// 3. 循环写管道
int i = 0;
while(i<100)
{
char buf[1024];
sprintf(buf, "hello, fifo, 我在写管道...%d\n", i);
write(wfd, buf, strlen(buf));
i++;
sleep(1);
}
close(wfd);
return 0;
}
- 读管道的进程
1. 这两个进程需要操作相同的管道文件
2. 打开有名管道文件, 打开方式是 o_rdonly
int rfd = open("xx", O_RDONLY);
3. 调用read函数读文件 ==> 读管道中的数据
char buf[4096];
read(rfd, buf, sizeof(buf));
4. 读完之后关闭文件描述符
close(rfd);
#include <fcntl.h>
#include <sys/stat.h>
int main()
{
// 1. 打开管道文件
// 因为要read管道, so打开方式, 应该指定为 O_RDONLY
// 如果只打开了读端, 写端还没有打开, open阻塞, 当写端被打开, 阻塞就解除了
int rfd = open("./testfifo", O_RDONLY);
if(rfd == -1)
{
perror("open");
exit(0);
}
printf("以只读的方式打开文件成功...\n");
// 2. 循环读管道
while(1)
{
char buf[1024];
memset(buf, 0, sizeof(buf));
// 读是阻塞的, 如果管道中没有数据, read自动阻塞
// 有数据解除阻塞, 继续读数据
int len = read(rfd, buf, sizeof(buf));
printf("读出的数据: %s\n", buf);
if(len == 0)
{
// 写端关闭了, read解除阻塞返回0
printf("管道的写端已经关闭, 拜拜...\n");
break;
}
}
close(rfd);
return 0;
}
2.4 管道的读写行为
关于管道不管是有名的还是匿名,在读写时,它们表现出的行为是一致的
下面是对其读写行为的总结:
- 读管道,需要根据写端的状态进行分析:
- 写端没有关闭 (操作管道写端的文件描述符没有被关闭)
- 如果管道中没有数据 ==> 读阻塞, 如果管道中被写入了数据, 阻塞解除
- 如果管道中有数据 ==> 不阻塞,管道中的数据被读完了, 再继续读管道还会阻塞
- 写端已经关闭了 (没有可用的文件描述符可以写管道了)
- 管道中没有数据 ==> 读端解除阻塞, read函数返回0
- 管道中有数据 ==> read先将数据读出, 数据读完之后返回0, 不会阻塞了
- 写端没有关闭 (操作管道写端的文件描述符没有被关闭)
- 写管道,需要根据读端的状态进行分析:
- 读端没有关闭
- 如果管道有存储的空间, 一直写数据
- 如果管道写满了, 写操作就阻塞, 当读端将管道数据读走了, 解除阻塞继续写
- 读端关闭了,管道破裂(异常), 进程直接退出
- 读端没有关闭
管道的两端默认是阻塞的,如何将管道设置为非阻塞呢?
管道的读写两端的非阻塞操作是相同的,下面的代码中将匿名的读端设置为了非阻塞:
// 通过fcntl 修改就可以, 一般情况下不建议修改
// 管道操作对应两个文件描述符, 分别是管道的读端 和 写端
// 1. 获取读端的文件描述符的flag属性
int flag = fcntl(fd[0], F_GETFL);
// 2. 添加非阻塞属性到 flag中
flag |= O_NONBLOCK;
// 3. 将新的flag属性设置给读端的文件描述符
fcntl(fd[0], F_SETFL, flag);
// 4. 非阻塞读管道
char buf[4096];
read(fd[0], buf, sizeof(buf));
3. 内存映射(mmap)
3.1 创建内存映射区
想要实现进程间通信,可通过函数创建一块内存映射区
和管道不同的是管道对应的内存空间在内核中,而内存映射区对应的内存空间在进程的用户区(用于加载动态库的那个区域)
也就是说进程间通信使用的内存映射区不是一块,而是在每个进程内部都有一块。
由于每个进程的地址空间是独立的,各个进程之间也不能直接访问对方的内存映射区,要通信的进程需将各自的内存映射区和同一个磁盘文件进行映射,这样进程之间就可以通过磁盘文件这个唯一的桥梁完成数据的交互了。
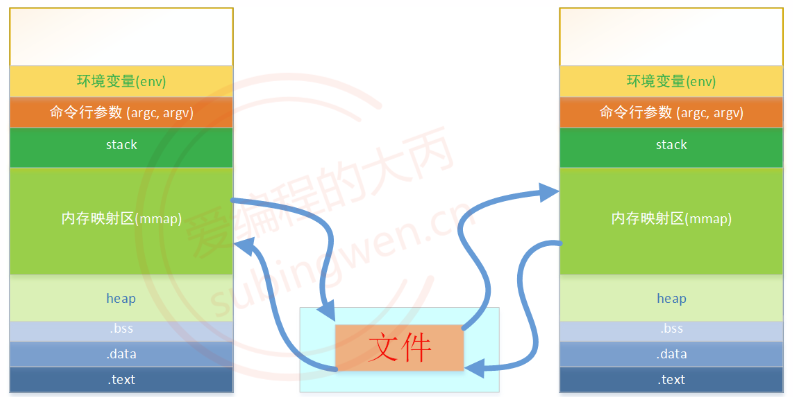
如上图所示:
磁盘文件数据可完全加载到进程的内存映射区也可部分加载到进程的内存映射区,当进程A中的内存映射区数据被修改了,数据会被自动同步到磁盘文件,同时和磁盘文件建立映射关系的其他进程内存映射区中的数据也会和磁盘文件进行数据的实时同步,这个同步机制保障了各进程间的数据共享。
使用内存映射区既可以进程有血缘关系的进程间通信也可以进程没有血缘关系的进程间通信。
创建内存映射区的函数原型如下:
#include <sys/mman.h>
// 创建内存映射区
void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);
- 参数:
-
addr: 从动态库加载区的什么位置开始创建内存映射区,一般定为NULL, 委托内核分配
-
length: 创建的内存映射区的大小(byte),实际上这个大小是按4k的整数倍去分配的
-
prot: 对内存映射区的操作权限
- PROT_READ: 读内存映射区
- PROT_WRITE: 写内存映射区
- 如果要对映射区有读写权限: PROT_READ | PROT_WRITE
-
flags:
- MAP_SHARED: 多个进程可以共享数据,进行映射区数据同步
- MAP_PRIVATE: 映射区数据是私有的,不能同步给其他进程
-
fd: 文件描述符, 对应一个打开的磁盘文件,内存映射区通过这个文件描述符和磁盘文件建立关联
-
offset: 磁盘文件的偏移量,文件从偏移到的位置开始进行数据映射
使用这个参数需要注意两个问题:- 偏移量必须是4k的整数倍, 写0代表不偏移
- 这个参数必须大于 0
-
- 返回值:
- 成功: 返回一个内存映射区的起始地址
- 失败:
MAP_FAILED(that is, (void *) -1)
mmap() 函数的参数较多,在使用该函数创建用于进程间通信的内存映射区的时候,各参数的指定有一些注意事项
- 第一个参数 addr 指定为
NULL即可- 第二个参数 length 必须要 > 0
- 第三个参数 prot,进程间通信需要对内存映射区有读写权限,因此需要指定为:
PROT_READ | PROT_WRITE- 第四个参数 flags,如果要进行进程间通信, 需要指定 MAP_SHARED
- 第五个参数 fd,打开的文件必须大于0,进程间通信需要文件操作权限和映射区操作权限相同
- 内存映射区创建成功之后, 关闭这个文件描述符不会影响进程间通信
- 第六个参数 offset,不偏移指定为0,如果偏移必须是4k的整数倍
内存映射区使用完之后也需要释放,释放函数原型如下:
int munmap(void *addr, size_t length);
- 参数:
- addr: mmap()的返回值, 创建的内存映射区的起始地址
- length: 和mmap()第二个参数相同即可
- 返回值:函数调用成功返回 0,失败返回 -1
3.2 进程间通信
操作内存映射区和操作管道是不一样的,
内存映射区是直接对内存地址进行操作,管道是通过文件描述符读写队列中的数据
管道的读写是阻塞的,内存映射区的读写是非阻塞的。
3.2.1 有血缘关系
由于创建子进程会发生虚拟地址空间的复制,那么在父进程中创建的内存映射区也会被复制到子进程中,这样在子进程里边就可以直接使用这块内存映射区了,所以对于有血缘关系的进程,进行进程间通信是非常简单的,处理代码如下:
1. 先创建内存映射区, 得到一个起始地址, 假设使用ptr指针保存这个地址
2. 通过fork()创建子进程->子进程中也就有一个内存映射区, 子进程中也有一个ptr指针指向这个地址
3. 父进程往自己的内存映射区写数据, 数据同步到了磁盘文件中
磁盘文件数据又同步到子进程的映射区中
子进程从自己的映射区往外读数据, 这个数据就是父进程写的
#include <sys/mman.h>
#include <fcntl.h>
int main()
{
// 1. 打开一个磁盘文件
int fd = open("./english.txt", O_RDWR);
// 2. 创建内存映射区
void* ptr = mmap(NULL, 4000, PROT_READ|PROT_WRITE,
MAP_SHARED, fd, 0);
if(ptr == MAP_FAILED)
{
perror("mmap");
exit(0);
}
// 3. 创建子进程
pid_t pid = fork();
if(pid > 0)
{
// 父进程, 写数据
const char* pt = "我你爹, 你我儿?";
memcpy(ptr, pt, strlen(pt)+1);
}
else if(pid == 0)
{
// 子进程, 读数据
usleep(1); // 内存映射区不阻塞, 为了让子进程读出数据
printf("从映射区读出的数据: %s\n", (char*)ptr);
}
// 释放内存映射区
munmap(ptr, 4000);
return 0;
}
3.2.2 没有血缘关系
对于没有血缘关系的进程间通信,需要在每个进程中分别创建内存映射区,但是这些进程的内存映射区必须要关联相同的磁盘文件,这样才能实现进程间的数据同步。
进程A的测试代码:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <sys/mman.h>
#include <fcntl.h>
int main()
{
// 1. 打开一个磁盘文件
int fd = open("./english.txt", O_RDWR);
// 2. 创建内存映射区
void* ptr = mmap(NULL, 4000, PROT_READ|PROT_WRITE,
MAP_SHARED, fd, 0);
if(ptr == MAP_FAILED)
{
perror("mmap");
exit(0);
}
const char* pt = "我你爹, 你我儿?";
memcpy(ptr, pt, strlen(pt)+1);
// 释放内存映射区
munmap(ptr, 4000);
return 0;
}
进程B的测试代码:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <sys/mman.h>
#include <fcntl.h>
int main()
{
// 1. 打开一个磁盘文件
int fd = open("./english.txt", O_RDWR);
// 2. 创建内存映射区
void* ptr = mmap(NULL, 4000, PROT_READ|PROT_WRITE,
MAP_SHARED, fd, 0);
if(ptr == MAP_FAILED)
{
perror("mmap");
exit(0);
}
// 读内存映射区
printf("从映射区读出的数据: %s\n", (char*)ptr);
// 释放内存映射区
munmap(ptr, 4000);
return 0;
}
3.3 拷贝文件
用内存映射区除了可实现进程间通信,也可进行文件的拷贝,用这种方式拷贝文件可减少工作量,我们只需负责创建内存映射区和打开磁盘文件,关于文件中的数据读写就无需关心了。
使用内存映射区拷贝文件思路:
- 打开被拷贝文件,得到文件描述符 fd1,并计算出这个文件的大小 size
- 创建内存映射区A并且和被拷贝文件关联,也就是和fd1关联起来,得到映射区地址 ptrA
- 创建新文件,得到文件描述符fd2,用于存储被拷贝的数据,并且将这个文件大小拓展为 size
- 创建内存映射区B并且和新创建的文件关联,也就是和fd2关联起来,得到映射区地址 ptrB
- 进程地址空间之间的数据拷贝,memcpy(ptrB, ptrA,size),数据自动同步到新建文件中
- 关闭内存映射区
文件拷贝示例代码如下:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <fcntl.h>
#include <sys/mman.h>
int main()
{
// 1. 打开一个操盘文件english.txt得到文件描述符
int fd = open("./english.txt", O_RDWR);
// 计算文件大小
int size = lseek(fd, 0, SEEK_END);
// 2. 创建内存映射区和english.txt进行关联, 得到映射区起始地址
void* ptrA = mmap(NULL, size, PROT_READ|PROT_WRITE, MAP_SHARED, fd, 0);
if(ptrA == MAP_FAILED)
{
perror("mmap");
exit(0);
}
// 3. 创建一个新文件, 存储拷贝的数据
int fd1 = open("./copy.txt", O_RDWR|O_CREAT, 0664);
// 拓展这个新文件
ftruncate(fd1, size);
// 4. 创建一个映射区和新文件进行关联, 得到映射区的起始地址second
void* ptrB = mmap(NULL, size, PROT_READ|PROT_WRITE, MAP_SHARED, fd1, 0);
if(ptrB == MAP_FAILED)
{
perror("mmap----");
exit(0);
}
// 5. 使用memcpy拷贝映射区数据
// 这两个指针指向两块内存, 都是内存映射区
// 指针指向有效的内存, 拷贝的是内存中的数据
memcpy(ptrB, ptrA, size);
// 6. 释放内存映射区
munmap(ptrA, size);
munmap(ptrB, size);
close(fd);
close(fd1);
return 0;
}
4. 共享内存
共享内存不同于内存映射区,它不属于任何进程,并且不受进程生命周期的影响。
通过调用Linux提供的系统函数就可得到这块共享内存。
使用前需让进程和共享内存进行关联,得到共享内存的起始地址之后就可直接进行读写操作了,进程也可以和这块共享内存解除关联, 解除关联之后就不能操作这块共享内存了。
在所有进程间通信的方式中共享内存的效率是最高的。
共享内存操作默认不阻塞,
如果多个进程同时读写共享内存,可能出现数据混乱,共享内存需要借助其他机制来保证进程间的数据同步,比如:信号量.
共享内存内部没有提供这种机制。
4.1 创建/打开共享内存
4.1.1 shmget
如共享内存不存在就需先创建出来,如已存在就需先打开这块共享内存。
不管是创建还是打开共享内存使用的函数是同一个
// 函数原型
#include <sys/ipc.h>
#include <sys/shm.h>
int shmget(key_t key, size_t size, int shmflg);
- 参数:
- key: 类型 key_t 是个整形数, 通过这个key可以创建或者打开一块共享内存,该参数的值一定要大于0
- size: 创建共享内存的时候, 指定共享内存的大小,如果是打开一块存在的共享内存, size是没有意义的
- shmflg:创建共享内存的时候指定的属性
- IPC_CREAT: 创建新的共享内存,如果创建共享内存, 需要指定对共享内存的操作权限,比如:IPC_CREAT | 0664
- IPC_EXCL: 检测共享内存是否已经存在了,必须和 IPC_CREAT一起使用
- 返回值:共享内存创建或者打开成功返回标识共享内存的唯一的ID,失败返回-1
函数使用举例:
场景1:创建一块大小为4k的共享内存
shmget(100, 4096, IPC_CREAT|0664);
场景2:创建一块大小为4k的共享内存, 并且检测是否存在
// 如果共享内存已经存在, 共享内存创建失败, 返回-1, 可以perror() 打印错误信息
shmget(100, 4096, IPC_CREAT|0664|IPC_EXCL);
场景3:打开一块已经存在的共享内存
// 函数参数虽然指定了大小和IPC_CREAT, 但是都不起作用
// 因为共享内存已经存在, 只能打开, 参数4096也没有意义
shmget(100, 4096, IPC_CREAT|0664);
shmget(100, 0, 0);
场景4:打开一块共享内存, 如果不存在就创建
shmget(100, 4096, IPC_CREAT|0664);
4.1.2 ftok
shmget() 函数的第一个参数是一个大于0的正整数,如果不想自己指定可以通过 ftok()函数直接生成这个key值。
// ftok函数原型
#include <sys/types.h>
#include <sys/ipc.h>
// 将两个参数作为种子, 生成一个 key_t 类型的数值
key_t ftok(const char *pathname, int proj_id);
-
参数:
-
pathname: 当前操作系统中一个存在的路径
-
proj_id: 这个参数只用到了int中的一个字节
传参的时候要将其作为 char 进行操作,取值范围: 1-255
-
-
返回值:函数调用成功返回一个可用于创建、打开共享内存的key值,调用失败返回-1
使用举例:
// 根据路径生成一个key_t
key_t key = ftok("/home/robin", 'a');
// 创建或打开共享内存
shmget(key, 4096, IPC_CREATE|0664);
4.2 关联和解除关联
4.2.1 shmat
创建/打开共享内存之后还必须和共享内存进行关联,这样才能得到共享内存的起始地址,通过得到的内存地址进行数据的读写操作
关联函数的原型如下:
void *shmat(int shmid, const void *shmaddr, int shmflg);
- 参数:
- shmid: 要操作的共享内存的ID, 是 shmget() 函数的返回值
- shmaddr: 共享内存的起始地址, 用户不知道, 需要让内核指定, 写NULL
- shmflg: 和共享内存关联的对共享内存的操作权限
- SHM_RDONLY: 读权限, 只能读共享内存中的数据
- 0: 读写权限,可以读写共享内存数据
- 返回值:关联成功,返回值共享内存的起始地址,关联失败返回 (void *) -1
4.2.2 shmdt
当进程不需要再操作共享内存,可以让进程和共享内存解除关联
另外如果没有执行该操作,进程退出之后,结束的进程和共享内存的关联也就自动解除了。
int shmdt(const void *shmaddr);
- 参数:shmat() 函数的返回值, 共享内存的起始地址
- 返回值:关联解除成功返回0,失败返回-1
4.3 删除共享内存
4.3.1 shmctl
shmctl() 函数是一个多功能函数,可设置、获取共享内存状态也可将共享内存标记为删除状态。
当共享内存被标记为删除状态之后,并不会马上被删除,直到所有的进程全部和共享内存解除关联,共享内存才会被删除。
因为通过shmctl()函数只是标记删除共享内存,所以在程序中多次调用该操作也没关系。
// 共享内存控制函数
int shmctl(int shmid, int cmd, struct shmid_ds *buf);
// 参数 struct shmid_ds 结构体原型
struct shmid_ds {
struct ipc_perm shm_perm; /* Ownership and permissions */
size_t shm_segsz; /* Size of segment (bytes) */
time_t shm_atime; /* Last attach time */
time_t shm_dtime; /* Last detach time */
time_t shm_ctime; /* Last change time */
pid_t shm_cpid; /* PID of creator */
pid_t shm_lpid; /* PID of last shmat(2)/shmdt(2) */
// 引用计数, 多少个进程和共享内存进行了关联
shmatt_t shm_nattch; /* 记录了有多少个进程和当前共享内存进行了管联 */
...
};
- 参数:
- shmid: 要操作的共享内存的ID, 是 shmget() 函数的返回值
- cmd: 要做的操作
- IPC_STAT: 得到当前共享内存的状态
- IPC_SET: 设置共享内存的状态
- IPC_RMID: 标记共享内存要被删除了
- buf:
- cmd==IPC_STAT, 作为传出参数, 会得到共享内存的相关属性信息
- cmd==IPC_SET, 作为传入参, 将用户的自定义属性设置到共享内存中
- cmd==IPC_RMID, buf就没意义了, 这时候buf指定为NULL即可
- 返回值:函数调用成功返回值大于等于0,调用失败返回-1
4.3.2 相关shell命令
使用ipcs 添加参数-m可以查看系统中共享内存的详细信息
$ ipcs -m
------------ 共享内存段 --------------
key shmid 拥有者 权限 字节 nattch 状态
0x00000000 425984 oracle 600 524288 2 目标
0x00000000 327681 oracle 600 524288 2 目标
0x00000000 458754 oracle 600 524288 2 目标
使用 ipcrm 命令可以标记删除某块共享内存
# key == shmget的第一个参数
$ ipcrm -M shmkey
# id == shmget的返回值
$ ipcrm -m shmid
4.3.3 共享内存状态
// 参数 struct shmid_ds 结构体原型
struct shmid_ds {
struct ipc_perm shm_perm; /* Ownership and permissions */
size_t shm_segsz; /* Size of segment (bytes) */
time_t shm_atime; /* Last attach time */
time_t shm_dtime; /* Last detach time */
time_t shm_ctime; /* Last change time */
pid_t shm_cpid; /* PID of creator */
pid_t shm_lpid; /* PID of last shmat(2)/shmdt(2) */
// 引用计数, 多少个进程和共享内存进行了关联
shmatt_t shm_nattch; /* 记录了有多少个进程和当前共享内存进行了管联 */
...
};
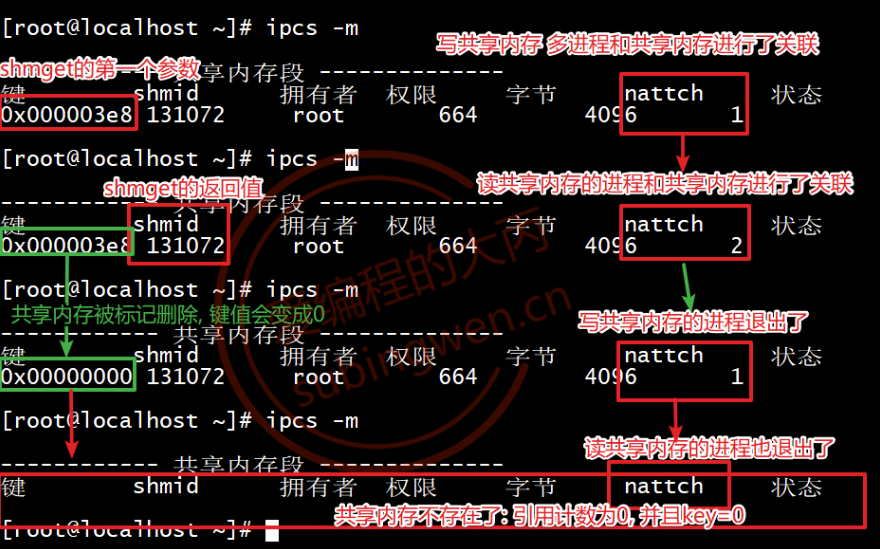
通过shmctl()我们可得知,共享内存的信息是存储到一个叫做struct shmid_ds的结构体中,其中有一个非常重要的成员叫做shm_nattch,在这个成员变量里边记录着当前共享内存关联的进程的个数,一般将其称为引用计数。
当共享内存被标记为删除状态,并且这个引用计数变为0之后共享内存才会被真正的被删除掉。
当共享内存被标记为删除状态之后,共享内存的状态也会发生变化,共享内存内部维护的key从一个正整数变为0,其属性从公共的变为私有。这里的私有指只有已经关联成功的进程才允许继续访问共享内存,不再允许新的进程和这块共享内存进行关联了。
下图演示了共享内存的状态变化:
4.4 进程间通信
使用共享内存实现进程间通信的操作流程如下:
1. 调用linux的系统API创建一块共享内存
- 这块内存不属于任何进程, 默认进程不能对其进行操作
2. 准备好进程A, 和进程B, 这两个进程需要和创建的共享内存进行关联
- 关联操作: 调用linux的 api
- 关联成功之后, 得到了这块共享内存的起始地址
3. 在进程A或者进程B中对共享内存进行读写操作
- 读内存: printf() 等;
- 写内存: memcpy() 等;
4. 通信完成, 可以让进程A和B和共享内存解除关联
- 解除成功, 进程A和B不能再操作共享内存了
- 共享内存不受进程生命周期的影响的
5. 共享内存不在使用之后, 将其删除
- 调用linux的api函数, 删除之后这块内存被内核回收了
写共享内存的进程代码:
#include <stdio.h>
#include <sys/shm.h>
#include <string.h>
int main()
{
// 1. 创建共享内存, 大小为4k
int shmid = shmget(1000, 4096, IPC_CREAT|0664);
if(shmid == -1)
{
perror("shmget error");
return -1;
}
// 2. 当前进程和共享内存关联
void* ptr = shmat(shmid, NULL, 0);
if(ptr == (void *) -1)
{
perror("shmat error");
return -1;
}
// 3. 写共享内存
const char* p = "hello 共享内存";
memcpy(ptr, p, strlen(p)+1);
// 阻塞程序
printf("按任意键继续, 删除共享内存\n");
getchar();
shmdt(ptr);
// 删除共享内存
shmctl(shmid, IPC_RMID, NULL);
printf("共享内存已删除...\n");
return 0;
}
读共享内存的进程代码:
#include <stdio.h>
#include <sys/shm.h>
#include <string.h>
int main()
{
// 1. 创建共享内存, 大小为4k
int shmid = shmget(1000, 0, 0);
if(shmid == -1)
{
perror("shmget error");
return -1;
}
// 2. 当前进程和共享内存关联
void* ptr = shmat(shmid, NULL, 0);
if(ptr == (void *) -1)
{
perror("shmat error");
return -1;
}
// 3. 读共享内存
printf("共享内存数据: %s\n", (char*)ptr);
// 阻塞程序
printf("按任意键继续, 删除共享内存\n");
getchar();
shmdt(ptr);
// 删除共享内存
shmctl(shmid, IPC_RMID, NULL);
printf("共享内存已经被删除...\n");
return 0;
}
4.5 shm和mmap的区别
共享内存和内存映射区都可以实现进程间通信,下面来分析一下二者的区别:
-
实现进程间通信的方式
- shm: 多个进程只需要一块共享内存就够了,共享内存不属于进程,需要和进程关联才能使用
- 内存映射区: 位于每个进程的虚拟地址空间中, 并且需要关联同一个磁盘文件才能实现进程间数据通信
-
效率:
- shm: 直接对内存操作,效率高
- 内存映射区: 需要内存和文件之间的数据同步,效率低
-
生命周期
- shm:进程退出对共享内存没有影响,调用相关函数/命令/ 关机才能删除共享内存
- 内存映射区:进程退出, 内存映射区也就没有了
-
数据的完整性 -> 突发状态下数据能不能被保存下来(比如: 突然断电)
- shm:数据存储在物理内存中, 断电之后系统关闭, 内存数据也就丢失了
- 内存映射区:可以完整的保存数据, 内存映射区数据会同步到磁盘文件
5. 信号
5.1 信号概述
Linux中的信号是一种消息处理机制, 它本质上是一个整数,不同的信号对应不同的值
由于信号的结构简单所以天生不能携带很大的信息量,但信号在系统中优先级非常高。
在Linux中的很多常规操作中都会有相关的信号产生,先从我们最熟悉的场景说起:
通过键盘操作产生了信号:用户按下Ctrl-C,这个键盘输入产生一个硬件中断,使用这个快捷键会产生信号, 这个信号会杀死对应的某个进程通过shell命令产生了信号:通过kill命令终止某一个进程,kill -9 进程PID通过函数调用产生了信号:如果CPU当前正在执行这个进程的代码调用,比如函数sleep(),进程收到相关的信号,被迫挂起通过对硬件进行非法访问产生了信号:正在运行的程序访问了非法内存,发生段错误,进程退出。
信号也可以实现进程间通信,但是信号能传递的数据量很少,不满足大部分需求,另外信号的优先级很高,并且它对应的处理动作是回调完成的,它会打乱程序原有的处理流程,影响到最终的处理结果。
因此非常不建议使用信号进行进程间通信。
5.1.1 信号编号
通过 kill -l 命令可以察看系统定义的信号列表:
# 执行shell命令查看信号
$ kill -l
1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP
6) SIGABRT 7) SIGBUS 8) SIGFPE 9) SIGKILL 10) SIGUSR1
11) SIGSEGV 12) SIGUSR2 13) SIGPIPE 14) SIGALRM 15) SIGTERM
16) SIGSTKFLT 17) SIGCHLD 18) SIGCONT 19) SIGSTOP 20) SIGTSTP
21) SIGTTIN 22) SIGTTOU 23) SIGURG 24) SIGXCPU 25) SIGXFSZ
26) SIGVTALRM 27) SIGPROF 28) SIGWINCH 29) SIGIO 30) SIGPWR
31) SIGSYS 34) SIGRTMIN 35) SIGRTMIN+1 36) SIGRTMIN+2 37) SIGRTMIN+3
38) SIGRTMIN+4 39) SIGRTMIN+5 40) SIGRTMIN+6 41) SIGRTMIN+7 42) SIGRTMIN+8
43) SIGRTMIN+9 44) SIGRTMIN+10 45) SIGRTMIN+11 46) SIGRTMIN+12 47) SIGRTMIN+13
48) SIGRTMIN+14 49) SIGRTMIN+15 50) SIGRTMAX-14 51) SIGRTMAX-13 52) SIGRTMAX-12
53) SIGRTMAX-11 54) SIGRTMAX-10 55) SIGRTMAX-9 56) SIGRTMAX-8 57) SIGRTMAX-7
58) SIGRTMAX-6 59) SIGRTMAX-5 60) SIGRTMAX-4 61) SIGRTMAX-3 62) SIGRTMAX-2
63) SIGRTMAX-1 64) SIGRTMAX
下表中详细阐述了信号产生的时机和对应的默认处理动作:
| 编号 | 信号 | 对应事件 | 默认动作 |
|---|---|---|---|
| 1 | SIGHUP | 用户退出shell时,由该shell启动的所有进程将收到这个信号 | 终止进程 |
| 2 | SIGINT | 当用户按下了<Ctrl+C>组合键时,用户终端向正在运行中的由该终端启动的程序发出此信号 | 终止进程 |
| 3 | SIGQUIT | 用户按下<ctrl+>组合键时产生该信号,用户终端向正在运行中的由该终端启动的程序发出些信号 | 终止进程 |
| 4 | SIGILL | CPU检测到某进程执行了非法指令 | 终止进程并产生core文件 |
| 5 | SIGTRAP | 该信号由断点指令或其他 trap指令产生 | 终止进程并产生core文件 |
| 6 | SIGABRT | 调用abort函数时产生该信号 | 终止进程并产生core文件 |
| 7 | SIGBUS | 非法访问内存地址,包括内存对齐出错 | 终止进程并产生core文件 |
| 8 | SIGFPE | 在发生致命的运算错误时发出。不仅包括浮点运算错误,还包括溢出及除数为0等所有的算法错误 | 终止进程并产生core文件 |
| 9 | SIGKILL | 无条件终止进程。本信号不能被忽略,处理和阻塞 | 终止进程,可以杀死任何进程 |
| 10 | SIGUSE1 | 用户定义的信号。即程序员可以在程序中定义并使用该信号 | 终止进程 |
| 11 | SIGSEGV | 指示进程进行了无效内存访问(段错误) | 终止进程并产生core文件 |
| 12 | SIGUSR2 | 另外一个用户自定义信号,程序员可以在程序中定义并使用该信号 | 终止进程 |
| 13 | SIGPIPE | Broken pipe向一个没有读端的管道写数据 | 终止进程 |
| 14 | SIGALRM | 定时器超时,超时的时间由系统调用alarm设置 | 终止进程 |
| 15 | SIGTERM | 程序结束信号,与SIGKILL不同的是,该信号可以被阻塞和终止。通常用来示程序正常退出。执行shell命令Kill时,缺省产生这个信号 | 终止进程 |
| 16 | SIGSTKFLT | Linux早期版本出现的信号,现仍保留向后兼容 | 终止进程 |
| 17 | SIGCHLD | 子进程结束时,父进程会收到这个信号 | 忽略这个信号 |
| 18 | SIGCONT | 如果进程已停止,则使其继续运行 | 继续/忽略 |
| 19 | SIGSTOP | 停止进程的执行。信号不能被忽略,处理和阻塞 | 为终止进程 |
| 20 | SIGTSTP | 停止终端交互进程的运行。按下<ctrl+z>组合键时发出这个信号 | 暂停进程 |
| 21 | SIGTTIN | 后台进程读终端控制台 | 暂停进程 |
| 22 | SIGTTOU | 该信号类似于SIGTTIN,在后台进程要向终端输出数据时发生 | 暂停进程 |
| 23 | SIGURG | 套接字上有紧急数据时,向当前正在运行的进程发出些信号,报告有紧急数据到达。如网络 | |
| 24 | SIGXCPU | 进程执行时间超过了分配给该进程的CPU时间 ,系统产生该信号并发送给该进程 | 终止进程 |
| 25 | SIGXFSZ | 超过文件的最大长度设置 | 终止进程 |
| 26 | SIGVTALRM | 虚拟时钟超时时产生该信号。类似于SIGALRM,但是该信号只计算该进程占用CPU的使用时间 | 终止进程 |
| 27 | SGIPROF | 类似于SIGVTALRM,它不公包括该进程占用CPU时间还包括执行系统调用时间 | 终止进程 |
| 28 | SIGWINCH | 窗口变化大小时发出 | 忽略该信号 |
| 29 | SIGIO | 此信号向进程指示发出了一个异步IO事件 | 忽略该信号 |
| 30 | SIGPWR | 关机 | 终止进程 |
| 31 | SIGSYS | 无效的系统调用 | 终止进程并产生core文件 |
| 34~64 | SIGRTMIN ~ SIGRTMAX | LINUX的实时信号,它们没有固定的含义(可以由用户自定义) | 终止进程 |
5.1.2 查看信号信息
通过Linux提供的 man 文档可以查询所有信号的详细信息:
# 查看man文档的信号描述
$ man 7 signal
在信号描述中介绍了对产生的信号的五种默认处理动作,分别是:
Term:信号将进程终止Ign:信号产生之后默认被忽略了Core:信号将进程终止, 并且生成一个core文件(一般用于gdb调试)Stop:信号会暂停进程的运行Cont:信号会让暂停的进程继续运行
关于对信号的介绍有一句非常重要的描述:
The signals SIGKILL and SIGSTOP cannot be caught, blocked, or ignored.
9号信号和19号信号不能被 捕捉, 阻塞, 和 忽略
9号信号: 无条件杀死进程
19号信号: 无条件暂停进程
有些信号在不同的平台对应的值是不一样的,对应我们使用PC机来说,需要看中间一列的值:
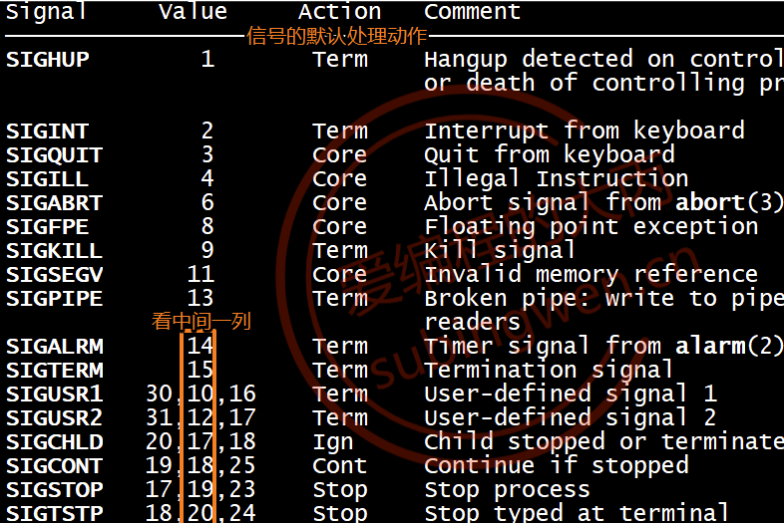
5.1.3 信号的状态
Linux中的信号有三种状态,分别为:产生,未决,递达。
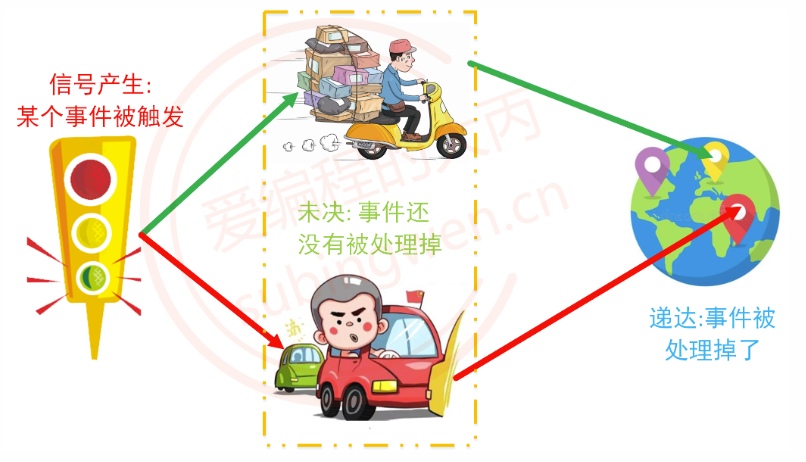
产生:键盘输入, 函数调用, 执行shell命令, 对硬件进行非法访问都会产生信号未决:信号产生了, 但是这个信号还没有被处理掉, 这个期间信号的状态称之为未决状态递达:信号被处理了(被某个进程处理掉)
5.2 信号相关函数
Linux中能够产生信号的函数有很多,下面介绍几个常用函数:
5.2.1 kill/raise/abort
这三个函数的功能比较类似,可以发送相关的信号给到对应的进程。
- kill 发送指定的信号到指定的进程
// 函数原型
#include <signal.h>
// 给某一个进程发送一个信号
int kill(pid_t pid, int sig);
- 参数:
- pid: 进程ID(man 文档里边写的比较详细)
- sig: 要发送的信号
函数使用举例:
// 自己杀死自己
kill(getpid(), 9);
// 子进程杀死自己的父进程
kill(getppid(), 10);
- raise:给当前进程发送指定的信号
// 函数原型
// 给自己发送某一个信号
#include <signal.h>
int raise(int sig); // 参数就是要给当前进程发送的信号
- abort:给当前进程发送一个固定信号 (SIGABRT)
// 函数原型
// 这是一个中断函数, 调用这个函数, 发送一个固定信号 (SIGABRT), 杀死当前进程
#include <stdlib.h>
void abort(void);
5.2.2 定时器
5.2.2.1 alarm
alarm() 函数只能进行单次定时,定时完成发射出一个信号。
#include <unistd.h>
unsigned int alarm(unsigned int seconds);
- 参数: 倒计时seconds秒, 倒计时完成发送一个信号 SIGALRM , 当前进程会收到这个信号,这个信号默认的处理动作是中断当前进程
- 返回值: 大于0表示倒计时还剩多少秒,返回值为0表示倒计时完成, 信号被发出
使用这个定时器函数, 检测一下当前计算机1s钟之内能数多少个数
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
int main()
{
// 1. 设置一个定时器, 定时1s
alarm(1); // 1s之后会发出一个信号, 这个信号将中断当前进程
int i = 0;
while(1)
{
printf("%d\n", i++);
}
return 0;
}
执行上述程序的时候, 计算一下时间
# 直接通过终端输出
$ time ./a.out
real 0m1.013s # 实际数数用的总时间
user 0m0.060s # 用户区代码使用的时间
sys 0m0.324s # 内核区使用的时间
real = user + sys + 消耗的时间(频率的从用户区到内核区进程切换)
# 不直接写终端, 将数据重定向到磁盘文件中
$ time ./a.out > a.txt
Alarm clock
real 0m1.002s # 用户实际数数的时间变长了
user 0m0.740s
sys 0m0.236s
文件IO操作需要进行用户区到内核区的切换,处理方式不同,二者之间切换的频率也不同。
也就是说对文件IO操作进行优化是可以提供程序的执行效率的。
5.2.2.2 setitimer
setitimer () 函数可以进行周期性定时,每触发一次定时器就会发射出一个信号。
// 这个函数可以实现周期性定时, 每个一段固定的时间, 发出一个特定的定时器信号
#include <sys/time.h>
struct itimerval {
struct timeval it_interval; /* 时间间隔 */
struct timeval it_value; /* 第一次触发定时器的时长 */
};
// 举例: luffy有一个闹钟, 并且使用这个闹钟定时:
// 早晨7点中起床, 第一次闹钟响起时可能起不来, 之后每隔5分钟再响一次
// - it_value: 当前设置闹钟的时间点 到 明天早晨7点 对应的总秒数
// - it_interval: 闹钟第一次响过之后, 每隔5分钟响一次
// 这个结构体表示的是一个时间段: tv_sec + tv_usec
struct timeval {
time_t tv_sec; /* 秒 */
suseconds_t tv_usec; /* 微妙 */
};
int setitimer(int which, const struct itimerval *new_value,
struct itimerval *old_value);
- 参数:
- which: 定时器使用什么样的计时法则, 不同的计时法则发出的信号不同
ITIMER_REAL: 自然计时法, 最常用, 发出的信号为SIGALRM, 一般使用这个宏值,自然计时法时间 = 用户区 + 内核 + 消耗的时间(从进程的用户区到内核区切换使用的总时间)ITIMER_VIRTUAL: 只计算程序在用户区运行使用的时间,发射的信号为 SIGVTALRMITIMER_PROF: 只计算内核运行使用的时间, 发出的信号为SIGPROF
- new_value: 给定时器设置的定时信息, 传入参数
- old_value: 上一次给定时器设置的定时信息, 传出参数,如果不需要这个信息, 指定为NULL
- which: 定时器使用什么样的计时法则, 不同的计时法则发出的信号不同
5.3 信号集
5.3.1 阻塞/未决信号集
在PCB中有两个非常重要的信号集。一个称之为“阻塞信号集”,另一个称之为“未决信号集”。
这两个信号集 体现在内核中就是两张表。
但是操作系统不允许我们直接对这两个信号集进行任何操作,而是需要自定义另外一个集合,借助信号集操作函数来对PCB中的这两个信号集进行修改。
-
信号的 “未决” 是一种状态,指的是从信号的产生到信号被处理前的这一段时间。
-
信号的 “阻塞” 是一个开关动作,指的是阻止信号被处理,但不是阻止信号产生。
信号的阻塞就是让系统暂时保留信号留待以后发送。
由于另外有办法让系统忽略信号,所以一般情况下信号的阻塞只是暂时的,只是为了 防止信号打断某些敏感的操作。

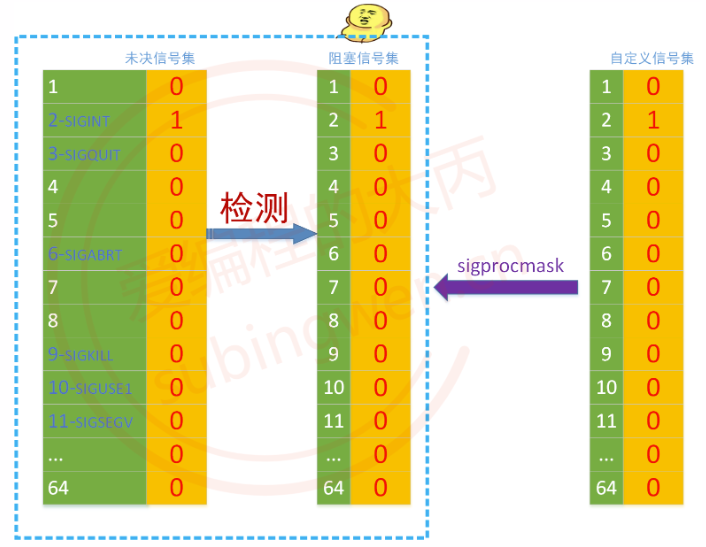
阻塞信号集和未决信号集在内核中的结构是相同的
它们都是一个整形数组(被封装过的), 一共 128 字节 (int [32] == 1024 bit),1024个标志位,其中前31个标志位,每一个都对应一个Linux中的标准信号,通过标志位的值来标记当前信号在信号集中的状态。
# 上图对信号集在内核中存储的状态的描述
# 前31个信号: 1-31 , 对应 1024个标志位的前31个标志位
信号 标志位(从低地址位 到 高地址位)
1 -> 0
2 1
3 2
4 3
31 30
- 在阻塞信号集中,描述这个信号有没有被阻塞
- 默认情况下没有信号是被阻塞的, 因此信号对应的标志位的值为 0
- 如果某个信号被设置为了阻塞状态, 这个信号对应的标志位 被设置为 1
- 在未决信号集中, 描述信号是否处于未决状态
- 如果这个信号被阻塞了, 不能处理, 这个信号对应的标志位被设置为1
- 如果这个信号的阻塞被解除了, 未决信号集中的这个信号马上就被处理了, 这个信号对应的标志位值变为0
- 如果这个信号没有阻塞, 信号产生之后直接被处理, 因此不会在未决信号集中做任何记录
5.3.2 信号集函数
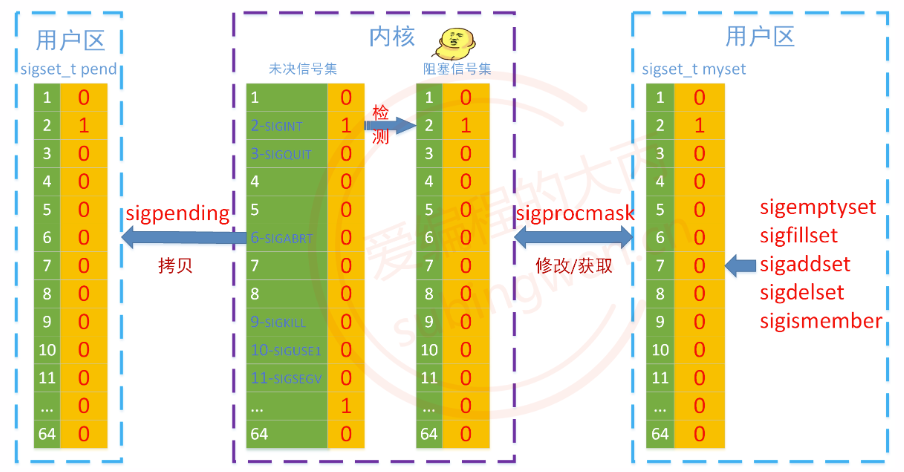
因为用户是不能直接操作内核中的阻塞信号集和未决信号集的,必须要调用系统函数
阻塞信号集可通过系统函数进行读写操作,未决信号集只能对其进行读操作。
先来看一下读/写阻塞信号集的函数:
#include <signal.h>
// 使用这个函数修改内核中的阻塞信号集
// sigset_t 被封装之后得到的数据类型, 原型:int[32], 里边一共有1024给标志位, 每一个信号对应一个标志位
int sigprocmask(int how, const sigset_t *set, sigset_t *oldset);
- 参数:
- how:
SIG_BLOCK: 将参数 set 集合中的数据追加到阻塞信号集中SIG_UNBLOCK: 将参数 set 集合中的信号在阻塞信号集中解除阻塞SIG_SETMASK: 使用参 set 结合中的数据覆盖内核的阻塞信号集数据
oldset: 通过这个参数将设置之前的阻塞信号集数据传出,如果不需要可以指定为NULL
- how:
- 返回值:函数调用成功返回0,调用失败返回-1
sigprocmask() 函数有一个 sigset_t 类型的参数,对这种类型的数据进行初始化
需要调用一些相关的操作函数:
#include <signal.h>
// 如果在程序中读写 sigset_t 类型的变量
// 阻塞信号集和未决信号集都存储在 sigset_t 类型的变量中, 这个变量对应一块内存
// 阻塞信号集和未决信号集, 对应的内存中有1024bit = 128字节
// 将set集合中所有的标志位设置为0
int sigemptyset(sigset_t *set);
// 将set集合中所有的标志位设置为1
int sigfillset(sigset_t *set);
// 将set集合中某一个信号(signum)对应的标志位设置为1
int sigaddset(sigset_t *set, int signum);
// 将set集合中某一个信号(signum)对应的标志位设置为0
int sigdelset(sigset_t *set, int signum);
// 判断某个信号在集合中对应的标志位到底是0还是1, 如果是0返回0, 如果是1返回1
int sigismember(const sigset_t *set, int signum);
未决信号集不需要我们修改, 如果设置了某个信号阻塞, 当这个信号产生之后, 内核会将这个信号的未决状态记录到未决信号集中,当阻塞的信号被解除阻塞, 未决信号集中的信号随之被处理, 内核再次修改未决信号集将该信号的状态修改为递达状态(标志位置0)。
因此,写未决信号集的动作都是内核做的,这是一个读未决信号集的操作函数:
#include <signal.h>
// 这个函数的参数是传出参数, 传出的内核未决信号集的拷贝
// 读一下这个集合就指定哪个信号是未决状态
int sigpending(sigset_t *set);
下面举一个简单的例子,演示一下信号集操作函数的使用:
需求:
在阻塞信号集中设置某些信号阻塞, 通过一些操作产生这些信号,
然后读未决信号集, 最后再解除这些信号的阻塞
假设阻塞这些信号:
- 2号信号: SIGINT: ctrl+c
- 3号信号: SIGQUIT: ctrl+\
- 9号信号: SIGKILL: 通过shell命令给进程发送这个信号 kill -9 PID
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <signal.h>
int main()
{
// 1. 初始化信号集
sigset_t myset;
sigemptyset(&myset);
// 设置阻塞的信号
sigaddset(&myset, SIGINT); // 2
sigaddset(&myset, SIGQUIT); // 3
sigaddset(&myset, SIGKILL); // 9 测试不能被阻塞
// 2. 将初始化的信号集中的数据设置给内核
sigset_t old;
sigprocmask(SIG_BLOCK, &myset, &old);
// 3. 让进程一直运行, 在当前进程中产生对应的信号
int i = 0;
while(1)
{
// 4. 读内核的未决信号集
sigset_t curset;
sigpending(&curset);
// 遍历这个信号集
for(int i=1; i<32; ++i)
{
int ret = sigismember(&curset, i);
printf("%d", ret);
}
printf("\n");
sleep(1);
i++;
if(i==10)
{
// 解除阻塞, 重新设置阻塞信号集
//sigprocmask(SIG_UNBLOCK, &myset, NULL);
sigprocmask(SIG_SETMASK, &old, NULL);
}
}
return 0;
}
结论:程序中对 9 号信号的阻塞是无效的,因为它无法被阻塞。
一张图总结这些信号集操作函数之间的关系:
5.4 信号捕捉
Linux中的每个信号产生后都会有对应的默认处理行为,如果想要忽略这个信号或修改某些信号的默认行为就需要在程序中捕捉该信号。
程序中进行信号捕捉可看做一个注册的动作,提前告诉应用程序信号产生后做什么处理,当进程中对应的信号产生了,这个处理动作也就被调用了。
5.4.1 signal
使用 signal() 函数可以捕捉进程中产生的信号,并且修改捕捉到的函数的行为,这个信号的自定义处理动作是一个回调函数,内核通过 signal() 得到这个回调函数的地址,在信号产生之后该函数会被内核调用。
#include <signal.h>
// 在程序中什么时候产生信号, 程序猿是不知道的, 因此不能在信号产生之后再去处理
// 在信号产生之前, 提供一个注册函数, 用来捕捉信号
// - 假设在将来这个信号产生了, 就委托内核进行捕捉, 这个信号的默认动作就不能被执行
// - 执行什么样的处理动作 ==> 在signal函数中指定的处理动作
// - 如果这个信号不产生, 回调函数永远不会被调用
sighandler_t signal(int signum, sighandler_t handler);
- 参数:
- signum: 需要捕捉的信号
- handler: 信号捕捉到之后的处理动作, 这是一个函数指针, 函数原型
typedef void (*sighandler_t)(int);
这个回调函数是需要我们写的, 若我们不调用, 由内核调用,
内核调用回调函数的时候, 会给它传递一个实参,这个实参的值就是捕捉的那个信号值。
下面的测试程序中使用 signal() 函数来捕捉定时器产生的信号 SIGALRM:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <sys/time.h>
#include <signal.h>
// 定时器信号的处理动作
void doing(int arg)
{
printf("当前捕捉到的信号是: %d\n", arg);
// 打印当前的时间
}
int main()
{
// 注册要捕捉哪一个信号, 执行什么样的处理动作
signal(SIGALRM, doing);
// 1. 调用定时器函数设置定时器函数
struct itimerval newact;
// 3s之后发出第一个定时器信号, 之后每隔1s发出一个定时器信号
newact.it_value.tv_sec = 3;
newact.it_value.tv_usec = 0;
newact.it_interval.tv_sec = 1;
newact.it_interval.tv_usec = 0;
// 这个函数也不是阻塞函数, 函数调用成功, 倒计时开始
// 倒计时过程中程序是继续运行的
setitimer(ITIMER_REAL, &newact, NULL);
// 编写一个业务处理, 阻止当前进程自己结束, 让当前进程被发出的信号杀死
while(1)
{
sleep(1000000);
}
return 0;
}
5.4.2 sigaction
sigaction() 函数和 signal() 函数的功能是一样的,用于捕捉进程中产生的信号,并将用户自定义的信号行为函数(回调函数)注册给内核,内核在信号产生之后调用这个处理动作。
sigaction() 可以看做是 signal() 函数是加强版,函数参数更多更复杂,函数功能也更强一些。
// 函数原型
#include <signal.h>
int sigaction(int signum, const struct sigaction *act, struct sigaction *oldact);
- 参数:
- signum: 要捕捉的信号
- act: 捕捉到信号之后的处理动作
- oldact: 上一次调用该函数进行信号捕捉设置的信号处理动作, 该参数一般指定为NULL
- 返回值:函数调用成功返回0,失败返回-1
该函数的参数是一个结构体类型,结构体原型如下:
struct sigaction {
void (*sa_handler)(int); // 指向一个函数(回调函数)
void (*sa_sigaction)(int, siginfo_t *, void *);
sigset_t sa_mask; // 初始化为空即可, 处理函数执行期间不屏蔽任何信号
int sa_flags; // 0
void (*sa_restorer)(void); //不用
};
结构体成员介绍:
-
sa_handler: 函数指针,指向的函数就是捕捉到的信号的处理动作
-
sa_sigaction: 函数指针,指向的函数就是捕捉到的信号的处理动作
-
sa_mask:
在信号处理函数执行期间, 临时屏蔽某些信号, 将要屏蔽的信号设置到集合中即可- 当前处理函数执行完毕, 临时屏蔽自动解除
- 假设在这个集合中不屏蔽任何信号, 默认也会屏蔽一个(捕捉的信号是谁, 就临时屏蔽谁)
-
sa_flags:使用哪个函数指针指向的函数处理捕捉到的信号
0:使用sa_handler(一般情况下使用这个)SA_SIGINFO:使用 sa_sigaction (使用信号传递数据==进程间通信)
-
sa_restorer: 被废弃的成员
示例代码,通过sigaction()捕捉阻塞信号集中解除阻塞的信号,如果捕捉多个信号,可以给不同的信号添加不同的处理动作,代码中的处理动作只有一个:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <signal.h>
// 信号的处理动作
void callback(int num)
{
printf("当前捕捉的信号: %d\n", num);
}
int main()
{
// 1. 初始化信号集
sigset_t myset;
sigemptyset(&myset);
// 设置阻塞的信号
sigaddset(&myset, SIGINT); // 2
sigaddset(&myset, SIGQUIT); // 3
sigaddset(&myset, SIGKILL); // 9 测试不能被阻塞
// 当阻塞的信号被解除阻塞, 该信号就可以被捕捉到了
// 如果信号被捕捉到之后, 马上就被处理掉了 --> 递达状态
struct sigaction act;
act.sa_handler = callback;
act.sa_flags = 0;
sigemptyset(&act.sa_mask);
sigaction(SIGINT, &act, NULL);
// 和sigint的处理动作相同
sigaction(SIGQUIT, &act, NULL);
sigaction(SIGKILL, &act, NULL);
// 2. 将初始化的信号集中的数据设置给内核
sigset_t old;
sigprocmask(SIG_BLOCK, &myset, &old);
// 3. 让进程一直运行, 在当前进程中产生对应的信号
int i = 0;
while(1)
{
// 4. 读内核的未决信号集
sigset_t curset;
sigpending(&curset);
// 遍历这个信号集
for(int i=1; i<32; ++i)
{
int ret = sigismember(&curset, i);
printf("%d", ret);
}
printf("\n");
sleep(1);
i++;
if(i==10)
{
// 解除阻塞, 重新设置阻塞信号集
//sigprocmask(SIG_UNBLOCK, &myset, NULL);
sigprocmask(SIG_SETMASK, &old, NULL);
}
}
return 0;
}
结论:程序中对 9 号信号的捕捉是无效的,因为它无法被捕捉。
5.5 SIGCHLD 信号
当子进程退出、暂停、从暂停回复运行的时候,在子进程中会产生一个SIGCHLD信号,并将其发送给父进程,但是父进程收到这个信号后默认忽略。
我们可以在父进程中对这个信号加以利用,基于这个信号来回收子进程的资源,因此需要在父进程中捕捉子进程发送过来的这个信号。
下面是基于信号回收子进程资源的示例代码:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <sys/wait.h>
#include <signal.h>
// 回收子进程处理函数
void recycle(int num)
{
printf("捕捉到的信号是: %d\n", num);
// 子进程的资源回收, 非阻塞
// SIGCHLD信号17号信号, 1-31号信号不支持排队
// 如果这些信号同时产生多个, 最终处理的时候只处理一次
// 假设多个子进程同时退出, 父进程同时收到了多个sigchld信号
// 父进程只会处理一次这个信号, 因此当前函数被调用了一次, waitpid被调用一次
// 相当于只回收了一个子进程, 但是是同时死了多个子进程, 因此就出现了僵尸进程
// 解决方案: 循环回收即可
while(1)
{
// 如果是阻塞回收, 就回不到另外一个处理逻辑上去了
pid_t pid = waitpid(-1, NULL, WNOHANG);
if(pid > 0)
{
printf("child died, pid = %d\n", pid);
}
else if(pid == 0)
{
// 没有死亡的子进程, 直接退出当前循环
break;
}
else if(pid == -1)
{
printf("所有子进程都回收完毕了, 拜拜...\n");
break;
}
}
}
int main()
{
// 设置sigchld信号阻塞
sigset_t myset;
sigemptyset(&myset);
sigaddset(&myset, SIGCHLD);
sigprocmask(SIG_BLOCK, &myset, NULL);
// 循环创建多个子进程 - 20
pid_t pid;
for(int i=0; i<20; ++i)
{
pid = fork();
if(pid == 0)
{
break;
}
}
if(pid == 0)
{
printf("我是子进程, pid = %d\n", getpid());
}
else if(pid > 0)
{
printf("我是父进程, pid = %d\n", getpid());
// 注册信号捕捉, 捕捉sigchld
struct sigaction act;
act.sa_flags =0;
act.sa_handler = recycle;
sigemptyset(&act.sa_mask);
// 注册信号捕捉, 委托内核处理将来产生的信号
// 当信号产生之后, 当前进程优先处理信号, 之前的处理动作会暂停
// 信号处理完毕之后, 回到原来的暂停的位置继续运行
sigaction(SIGCHLD, &act, NULL);
// 解除sigcld信号的阻塞
// 信号被阻塞之后,就捕捉不到了, 解除阻塞之后才能捕捉到这个信号
sigprocmask(SIG_UNBLOCK, &myset, NULL);
// 父进程执行其他业务逻辑就可以了
// 默认父进程执行这个while循环, 但是信号产生了, 这个执行逻辑或强迫暂停
// 父进程去处理信号的处理函数
while(1)
{
sleep(100);
}
}
return 0;
}
6. 守护进程
守护进程(Daemon Process),也就是通常说的 Daemon 进程(精灵进程),是 Linux 中的后台服务进程。它是一个生存期较长的进程,通常独立于控制终端并且周期性地执行某种任务或等待处理某些发生的事件。一般采用以d结尾的名字。
6.1 进程组
多个进程的集合就是进程组, 这个组中必须有一个组长, 组长就是进程组中的第一个进程,组长以外的都是普通的成员,每个进程组都有一个唯一的组ID,进程组的ID和组长的PID是一样的。
进程组中的成员是可以转移的,如果当前进程组中的成员被转移到了其他的组,或者进制中的所有进程都退出了,那么这个进程组也就不存在了。
如果进程组中组长死了, 但是当前进程组中有其他进程,这个进程组还是继续存在的。
下面介绍几个常用的进程组函数:
得到当前进程所在的进程组的组ID
pid_t getpgrp(void);
获取指定的进程所在的进程组的组ID,参数 pid 就是指定的进程
pid_t getpgid(pid_t pid);
将某个进程移动到其他进程组中或者创建新的进程组
int setpgid(pid_t pid, pid_t pgid);
- 参数:
- pid: 某个进程的进程ID
- pgid: 某个进程组的组ID
- 如果pgid对应的进程组存在,pid对应的进程会移动到这个组中, pid != pgid
- 如果pgid对应的进程组不存在,会创建一个新的进程组, 因此要求 pid == pgid, 当前进程就是组长了
- 返回值:函数调用成功返回0,失败返回-1
6.2 会话
会话(session)是由一个或多个进程组组成的,一个会话可以对应一个控制终端, 也可以没有。
一个普通的进程可以调用 setsid() 函数使自己成为新 session 的领头进程(会长),并且这个 session 领头进程还会被放入到一个新的进程组中。
// 函数原型
#include <unistd.h>
// 获取某个进程所属的会话ID
pid_t getsid(pid_t pid);
// 将某个进程变成会话 =>> 得到一个守护进程
// 使用哪个进程调用这个函数, 这个进程就会变成一个会话
pid_t setsid(void);
使用这个函数的注意事项:
- 调用这个函数的进程不能是组长进程, 如果是,该函数调用失败,如何保证这个函数能调用成功呢?
先fork()创建子进程, 终止父进程,- 让子进程调用这个函数 如果调用这个函数的进程不是进程组长, 会话创建成功
这个进程会变成当前会话中的第一个进程,同时也会变成新的进程组的组长
该函数调用成功之后, 当前进程就脱离了控制终端,因此不会阻塞终端
6.3 创建守护进程
如果要创建一个守护进程,标准步骤如下,部分操作可以根据实际需求进行取舍:
-
创建子进程, 让父进程退出
- 因为父进程有可能是组长进程,不符合条件,也没有什么利用价值,退出即可
- 子进程没有任何职务, 目的是让子进程最终变成一个会话, 最终就会得到守护进程
-
通过子进程创建新的会话,调用函数 setsid(),脱离控制终端, 变成守护进程
-
改变当前进程的工作目录 (可选项)
- 某些文件系统可以被卸载, 比如: U盘, 移动硬盘
进程如果在这些目录中运行,运行期间这些设备被卸载了,运行的进程也就不能正常工作了。 - 修改当前进程的工作目录需要调用函数
chdir()
- 某些文件系统可以被卸载, 比如: U盘, 移动硬盘
int chdir(const char *path);
- 重新设置文件的掩码 (可选项,)
- 掩码: umask, 在创建新文件的时候需要和这个掩码进行运算, 去掉文件的某些权限
- 设置掩码需要使用函数
umask()
mode_t umask(mode_t mask);
-
关闭/重定向文件描述符 (建议做)
-
启动一个进程, 文件描述符表中默认有三个被打开了, 对应的都是当前的终端文件
-
因为进程通过调用 setsid() 已经脱离了当前终端, 因此关联的文件描述符也就没用了, 可以关闭.如下第一代码部分
-
重定向文件描述符(和关闭二选一): 改变文件描述符关联的默认文件, 让他们指向一个特殊的文件
/dev/null,只要把数据扔到这个特殊的设备文件中, 数据被被销毁了
-
close(STDIN_FILENO);
close(STDOUT_FILENO);
close(STDERR_FILENO);
int fd = open("/dev/null", O_RDWR);
// 重定向之后, 这三个文件描述符就和当前终端没有任何关系了
dup2(fd, STDIN_FILENO);
dup2(fd, STDOUT_FILENO);
dup2(fd, STDERR_FILENO);
- 根据实际需求在守护进程中执行某些特定的操作
6.4 守护进程的应用
写一个守护进程, 每隔2s获取一次系统时间, 并将得到的时间写入到磁盘文件中。
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <signal.h>
#include <sys/time.h>
#include <time.h>
// 信号的处理动作
void writeFile(int num)
{
// 得到系统时间
time_t seconds = time(NULL);
// 时间转换, 总秒数 -> 可以识别的时间字符串
struct tm* loc = localtime(&seconds);
// sprintf();
char* curtime = asctime(loc); // 自带换行
// 打开一个文件, 如果文件不存在, 就创建, 文件需要有追加属性
// ./对应的是哪个目录? /home/robin
// 0664 & ~022
int fd = open("./time+++++++.log", O_WRONLY|O_CREAT|O_APPEND, 0664);
write(fd, curtime, strlen(curtime));
close(fd);
}
int main()
{
// 1. 创建子进程, 杀死父进程
pid_t pid = fork();
if(pid > 0)
{
// 父进程
exit(0); // kill(getpid(), 9); raise(9); abort();
}
// 2. 子进程, 将其变成会话, 脱离当前终端
setsid();
// 3. 修改进程的工作目录, 修改到一个不能被修改和删除的目录中 /home/robin
chdir("/home/robin");
// 4. 设置掩码, 在进程中创建文件的时候这个掩码就起作用了
umask(022);
// 5. 重定向和终端关联的文件描述符 -> /dev/null
int fd = open("/dev/null", O_RDWR);
dup2(fd, STDIN_FILENO);
dup2(fd, STDOUT_FILENO);
dup2(fd, STDERR_FILENO);
// 5. 委托内核捕捉并处理将来发生的信号-SIGALRM(14)
struct sigaction act;
act.sa_flags = 0;
act.sa_handler = writeFile;
sigemptyset(&act.sa_mask);
sigaction(SIGALRM, &act, NULL);
// 6. 设置定时器
struct itimerval val;
val.it_value.tv_sec = 2;
val.it_value.tv_usec = 0;
val.it_interval.tv_sec = 2;
val.it_interval.tv_usec = 0;
setitimer(ITIMER_REAL, &val, NULL);
while(1)
{
sleep(100);
}
return 0;
}