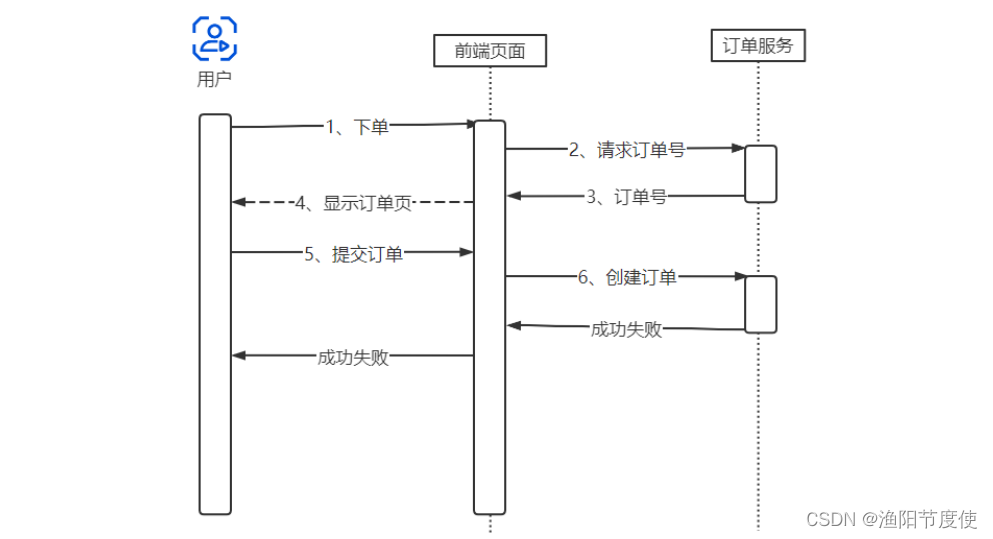
订单重复下单问题(幂等)
用户在点击“提交订单”的按钮时,不小心点了两下,那么浏览器就会向服务端连续发送两条创建订单的请求。这样肯定是不行的
解决办法是,让订单服务具备幂等性。什么是幂等性?幂等操作的特点是,操作任意多次执行所产生的影响,均与一次执行所产生的影响相同。也就是说,对于幂等方法,使用同样的参数,对它进行多次调用和一次调用,其对系统产生的影响是一样的。
读写分离与分库分表
使用 Redis 作为 MySQL 的前置缓存,可以帮助 MySQL 挡住绝大部分的查询请求。这种方法对于像电商中的商品系统、搜索系统这类与用户关联不大的系统、效果特别好。因为在这些系统中、任何人看到的内容都是一样的,也就是说,对后端服来说,任何人的查询请求和返回的数据都是一样的。在这种情况下,Redis 缓存的命中率非常高,几乎所有的请求都可以命中缓存。但是与用户相关的系统(不是用户系统本身,用户信息等相关数据在用户登录时进行缓存,就价值很高),使用缓存的效果就没有那么好了,比如,订单系统、账户系统、购物车系统、订单系统等等。对于这些系统而言,各个用户查询的信息与用户自身相关,即使同一个功能界面,用户看到的数据也是不一样的。比如,“我的订单”这个功能,用户看到的都是自己的订单数据。在这种情况下,缓存的命中率就比较低了,会有相当一部分查询请求因为命中不了缓存,穿透到 MySQL 数据库中。随着系统的用户数量越来越多,穿透到 MySQL 数据库中的读写请求也会越来越多,当单个 MySQL 支撑不了这么多的并发请求时,该怎么办?
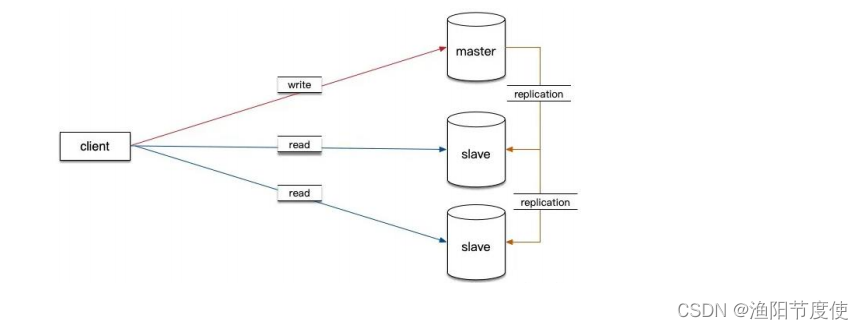
读写分离
读写分离是提升 MySQL 并发能力的首选方案,当单个 MySQL 无法满足要求的时候,只能用多个 MySQL 实例来承担大量的读写请求。MySQL 与大部分常用的关系型数据库一样,都是典型的单机数据库,不支持分布式部署。用一个单机数据库的多个实例组成一个集群,提供分布式数据库服务,是一件非常困难的事情。一个简单且非常有效的是用多个具有相同数据的 MySOL 实例来分担大量查询请求,也就是“读写分离”。很多系统,特别是互联网系统,数据的读写比例严重不均衡,读写比例一般在 9:1 到几十比 1,即平均每发生几十次查询请求,才会有一次更新请求,那就是说数据库需要应对的绝大部分请求都是只读查询请求。
分布式存储系统支持分布式写是非常困难的,因为很难解决好数据一致性的问题。但分布式读相对来说就简单得多,能够把数据尽可能实时同步到只读实例上,它们就可以分担大量的查询请求了。读写分离的另一个好处是,实施起来相对比较简单。把使用单机 MySQL 的系统升级为读写分离的多实例架构非常容易,一般不需要修改系统的业务逻辑,只需要简单修改 DAO (Data Access Object,一般指应用程序中负责访问数据库的抽象层)层的代码,把对数据库的读写请求分开,请求不同的 MySQL 实例就可以了。通过读写分离这样一个简单的存储架构升级,数据库支持的并发数量就可以增加几倍到十几倍。所以,当系统的用户数越来越多时,读写分离应该是首要考虑的扩容方案。
主库负责执行应用程序发来的数据更新请求,然后将数据变更同步到所有的从库中。这样,主库和所有从库中的数据一致,多个从库可以共同分担应用的查询请求。
分库分表
除了访问 MySQL 的并发问题,还要解决海量数据的问题,很多的时候,会使用分布式的存储集群,因为 MySQI 本质上是一个单机数据库,所以很多场景下,其并不适合存储 TB 级别以上的数据。
如何规划分库分表
哪种情况适合分表,哪种情况适合分库。选择分厍或是分表的目的是解决如下两个问题。
第一,是为了解决因数据量太大而导致查询慢的问题。这里所说的“查询”,其实主要是事务中的查询和更新操作,因为只读的查询可以通过缓存和主从分离来解决。分表主要用于解决因数据量大而导致的查询慢的问题。
第二,是为了应对高并发的问题。如果一个数据库实例撑不住,就把并发请求分散到多个实例中,所以分库可用于解决高并发的问题。
简单地说,如果数据量太大,就分表;如果并发请求量高,就分库。一般情况下,解决方案大都需要同时做分库分表,可以根据预估的并发量和数据量,分别计算应该拆分成多少个库以及多少张表。
实现
数据量
在设计系统,预估订单的数量每个月订单 2000W,一年的订单数可达2.4 亿。而每条订单的大小大致为 1KB,按照 MySQL 的知识,为了让 B+树的高度控制在一定范围,保证查询的性能,每个表中的数据不宜超过2000W。在这种情况下,为了存下 2.4 亿的订单,似乎应该将订单表分为 16(12 往上取最近的 2 的幂)张表。
选择分片键
既然决定订单系统分库分表,则还有一个重要的问题,那就是如何选择一个合适的列作为分表的依据,该列一般称为分片键(Sharding Key)。选择合适的分片键和分片算法非常重要,因为其将直接影响分库分表的效果。
这个问题的解决办法是,在生成订单 ID 的时候,把用户 ID 的后几位作为订单 ID 的一部分。这样按订单 ID 查询的时候,就可以根据订单 ID 中的用户 ID 找到分片。 所以在系统中订单 ID 从唯一 ID 服务获取 ID 后,还会将用户 ID的后两位拼接,形成最终的订单 ID。
在分片算法上,常用的有按范围,比如时间范围分片,哈希分片,查表法分片。最经常使用是哈希分片,对表的个数 进行直接取模
一旦做了分库分表,就会极大地限制数据库的查询能力,原本很简单的查询,分库分表之后,可能就没法实现了。分库分表一定是在数据量和并发请求量大到所有招数都无效的情况下,才会采用的最后一招。
具体实现
如何在代码中实现读写分离和分库分表呢?一般来说有三种方法。
1)纯手工方式:修改应用程序的 DAO 层代码,定义多个数据源,在代码中需要访问数据库的每个地方指定每个数据库请求的数据源。
2)组件方式:使用像 Sharding-JDBC 这些组件集成在应用程序内,用于代理应用程序的所有数据库请求,并把请求自动路由到对应的数据库实例上。
3)代理方式:在应用程序和数据库实例之间部署一组数据库代理实例,比如Atlas 或 Sharding-Proxy。对于应用程序来说,数据库代理把自己伪装成一个单节点的 MySQL 实例,应用程序的所有数据库请求都将发送给代理,代理分离请求,然后将分离后的请求转发给对应的数据库实例。
在这三种方式中一般推荐第二种,使用分离组件的方式。采用这种方式,代码侵入非常少,同时还能兼顾性能和稳定性。如果应用程序是一个逻辑非常简单的微服务,简单到只有几个 SQL,或者应用程序使用的编程语言没有合适的读写分离组件,那么也可以考虑通过纯手工的方式。不推荐使用代理方式(第三种方式),原因是代理方式加长了系统运行时数据库请求的调用链路,会浩成一定的性能损失,而且代理服务本身也可能会出现故障和性能瓶颈等问题。代理方式有一个好处,对应用程序完全透明。
所以在我们的订单服务中,使用了第二种方式,引入了 Sharding-JDBC,考虑要同时支持读写分离和分库分表,配置如下:

具体参考sharding-jdbc配置文件