多层感知机是一组前向结构的人工神经网络,映射一组输入向量到一组输出向量。除了输入节点,每一个节点都是一个带有非线性激活函数的神经元。多层感知机在输入层和输出层之间添加了一个或者多个隐藏层,并通过激活函数转换隐藏层输出。以下介绍几种激活函数。
4.1 多层感知机
4.1.1 RuLU函数
求导表现好,要么参数消失,要么参数通过,减轻了梯度消失问题。
%matplotlib inline
import torch
from d2l import torch as d2l
x=torch.arange(-8,8,0.1,requires_grad=True)
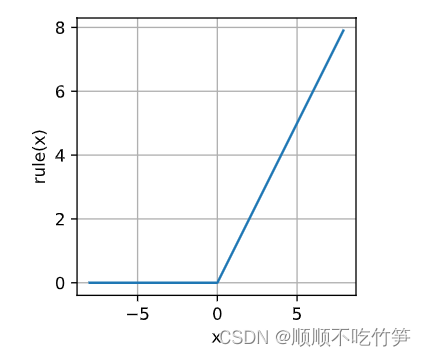
y=torch.relu(x)
# 此处使用detach().numpy()是因为带有梯度的不需要梯度
d2l.plot(x.detach().numpy(),y.detach().numpy(),"x","rule(x)",figsize=(3,3))
# torch.ones_like返回填充了标量值为1的张量
# retain_graph保留梯度,此处我不添加也不影响结果,暂时不知道为啥
y.backward(torch.ones_like(x))
d2l.plot(x.detach(),x.grad,"x","x.grad",figsize=(4,3))
4.1.2 sigmoid函数

sigmoid函数
y=torch.sigmoid(x)
d2l.plot(x.detach(),y.detach(),'x','sigmoid(x)',figsize=(4,3))
sigmoid反向传播函数
# 清除之前的梯度
x.grad.data.zero_()
y.backward(torch.ones_like(x))
d2l.plot(x.detach(),x.grad,'x','grad of sigmoid',figsize=(4,3))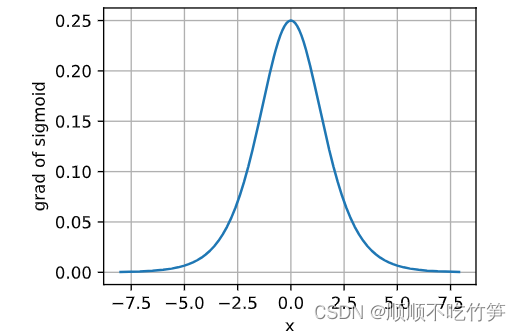
4.1.3 tanh函数
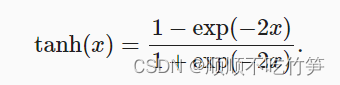
tanh函数
y=torch.tanh(x)
d2l.plot(x.detach(),y.detach(),'x','tanh(x)',figsize=(4,3))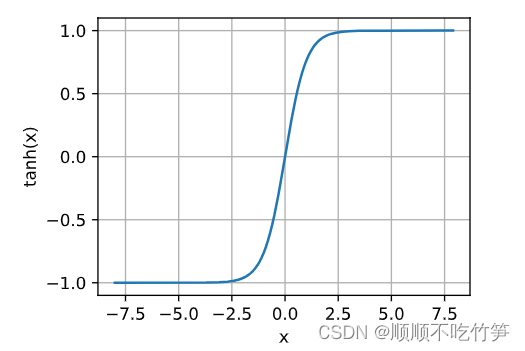
x.grad.data.zero_()
y.backward(torch.ones_like(x))
d2l.plot(x.detach(),x.grad,'x','grad of tannh',figsize=(3,4))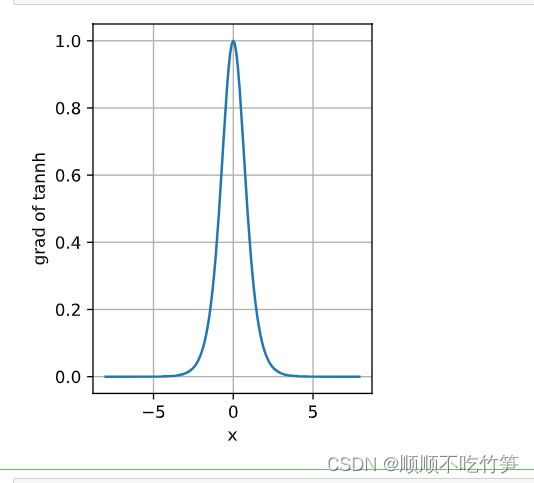
4.2 多层感知机简要实现(不使用torch工具包)
net = nn.Sequential(nn.Flatten(),nn.Linear(784,256),nn.ReLU(),nn.Linear(356,10))
def init_weight(m):
if type(m)==nn.Linear:
nn.init.normal_(m.weight,std=0.01)
net.apply(init_weight)
batch_size, lr, num_epochs = 256, 0.1, 10
loss = nn.CrossEntropyLoss(reduction='none')
trainer = torch.optim.SGD(net.parameters(), lr=lr)
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)4.4 模型选择、欠拟合和过拟合
我们训练模型的原因是为了提高模型的泛化能力,在未遇到的个体上,也可以很好的评估风险。
样本有限,当在训练数据上拟合比在潜在分布更接近的现象叫做过拟合。用于对抗过拟合的技术叫做正则化。
当训练误差和验证误差都很严重,但他们之间仅有一点差距的现象叫做欠拟合。
4.4.1 数据集
首先用n阶多项式生成训练集和测试集的标签
import math
import numpy as np
import torch
from torch import nn
from d2l import torch as d2l
max_degree = 20 # 多项式的最大阶数
n_train, n_test = 100, 100 # 训练和测试数据集大小
true_w = np.zeros(max_degree) # 分配大量的空间
true_w[0:4] = np.array([5, 1.2, -3.4, 5.6])
# 创建随机的训练和测试数据,并排成一列
features = np.random.normal(size=(n_train + n_test, 1))
# 打乱数据
np.random.shuffle(features)
# 求出【x^0,x^1,...,x^max_degree-1】,并改成一行
poly_features = np.power(features, np.arange(max_degree).reshape(1, -1))
# 每个x^i除以i!
for i in range(max_degree):
poly_features[:, i] /= math.gamma(i + 1) # gamma(n)=(n-1)!
# labels的维度:(n_train+n_test,)
labels = np.dot(poly_features, true_w)
labels += np.random.normal(scale=0.1, size=labels.shape)
# NumPy ndarray转换为tensor,这里不能注释
true_w, features, poly_features, labels = [torch.tensor(x, dtype=
torch.float32) for x in [true_w, features, poly_features, labels]]
features[:2], poly_features[:2, :], labels[:2]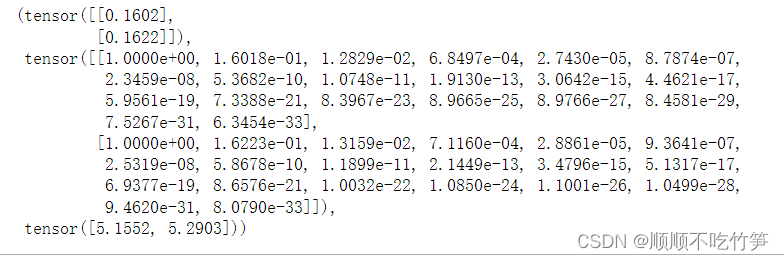
4.4.2 创建评估损失函数
def evaluate_loss(net, data_iter, loss):
"""评估给定数据集上模型的损失"""
metric = d2l.Accumulator(2) # 损失的总和,样本数量
for X,y in data_iter:
out=net(X)
y=y.reshape(out.shape)
l = loss(out,y)
metric.add(l.sum(), l.numel())
return metric[0]/metric[1]4.4.3 创建训练函数
每训练20次计算损失比率
def train(train_features, test_features, train_labels, test_labels,
num_epochs=400):
loss = nn.MSELoss(reduction='none')
# 货期train_features最后一列
input_shape = train_features.shape[-1]
# bias=False表示不设置偏置值
net = nn.Sequential(nn.Linear(input_shape, 1, bias=False))
batch_size = min(10, train_labels.shape[0])
# 抽取batch_size个数据
train_iter = d2l.load_array((train_features, train_labels.reshape(-1,1)),
batch_size)
test_iter = d2l.load_array((test_features, test_labels.reshape(-1,1)),
batch_size, is_train=False)
# 优化算法采用SGD
trainer = torch.optim.SGD(net.parameters(), lr=0.01)
# xlim和ylim代表x轴和y轴的范围
animator = d2l.Animator(xlabel='epoch', ylabel='loss', yscale='log',
xlim=[1, num_epochs], ylim=[1e-3, 1e2],
legend=['train', 'test'])
for epoch in range(num_epochs):
d2l.train_epoch_ch3(net, train_iter, loss, trainer)
if epoch == 0 or (epoch + 1) % 20 == 0:
animator.add(epoch + 1, (evaluate_loss(net, train_iter, loss),
evaluate_loss(net, test_iter, loss)))
print('weight:', net[0].weight.data.numpy())查看训练损失和测试损失
# 从多项式特征中选择前4个维度,即1,x,x^2/2!,x^3/3!
train(poly_features[:n_train, :4], poly_features[n_train:, :4],
labels[:n_train], labels[n_train:])4.5 权重衰减
为了解决过拟合的问题,通过向损失函数中添加权重参数的平方和作为惩罚。损失函数可以这么写:L'=L+λ*||W||^2,λ用来控制惩罚的大小。由于惩罚项和参数的平方成正比,鼓励权重接近0,以此来减小模型复杂度。
4.6 暂退法
在当前层中随机丢弃一些节点,以此来消除对每个元素的依赖性。