文章目录
- Summary
- 1. INTRODUCTION
- 2. MOTION PLANNING AND CONTROL
- 2.1. Vehicle Dynamics and Control
- 2.2. Parallel Autonomy
- 2.3. Motion Planning for Autonomous Vehicles
- 3. INTEGRATED PERCEPTION AND PLANNING
- 3.1. From Classical Perception to Current Challenges in Neural Network–Based Perception Systems
- 3.2. End-to-End Planning
- 4. BEHAVIOR-AWARE MOTION PLANNING
- 4.1. Cooperation and Interaction
- 4.2. Game-Theoretic Approaches
- 4.3. Probabilistic Approaches
- 4.4. Partially Observable Markov Decision Processes
- 4.5. Learning-Based Approaches
- 5. VERIFICATION AND SYNTHESIS
- 6. FLEET MANAGEMENT
- 7. CONCLUSION
这是一篇MIT18年发布在《Annual Review of Control, Robotics, and Autonomous Systems》的文章。本着学习的精神对这篇文章进行阅读并记录相关笔记,可能会有纰漏,还请批评斧正。
Summary
本文主要讨论了自主驾驶车辆领域中规划和决策的最新趋势和挑战。涵盖了三种不同的方法:传统PipeLine式的规划、行为意识决策规划和端到端规划,并强调了智能感知和规划的整合以及基于机器学习的方法。同时,也讨论了验证和安全性方面的问题以及自主驾驶车队管理方面的挑战。
1. INTRODUCTION
人们在日常出行上需要花费大量的时间,同时交通事故也造成了人员的伤亡。然而,自动驾驶汽车极有潜力能够解决这些问题,自动驾驶汽车能够极大地方便人们的生活,提高生产力与效率,保证交通系统的安全性,但自动驾驶汽车的实现需要从车辆设计到控制、感知、规划、协调和人际互动等等方面的进步……
作者在这篇文章中主要关注以下问题:
- 车辆如何决定下一步去哪里;
- 车辆如何使用传感器提供的数据来做出短期和长期的决策;
- 与其他车辆的交互对决策规划系统的影响;
- 车辆如何从自身历史信息和人类驾驶信息中学习驾驶;
- 如何确保车辆控制和规划系统的正确性和安全性;
- 如何进行道路上的多车协同管理,以最有效的方式将人员和物资运送到目的地。
实现完全的自动驾驶还需面临技术、法律、社会等方面的挑战。作者介绍了DARPA挑战赛使得自动驾驶汽车能够在十分接近真实场景的环境中工作,但也指出无论是DARPA中的方案,还是现有(-2018)比较先进的方案,都只能在环境相对简单、低速的状况下进行。
自动驾驶汽车需要对复杂的、不可预测的动态环境进行及时的推理,即使在复杂的城市道路环境中,也需要达到人类驾驶员水平的安全性、可靠性。
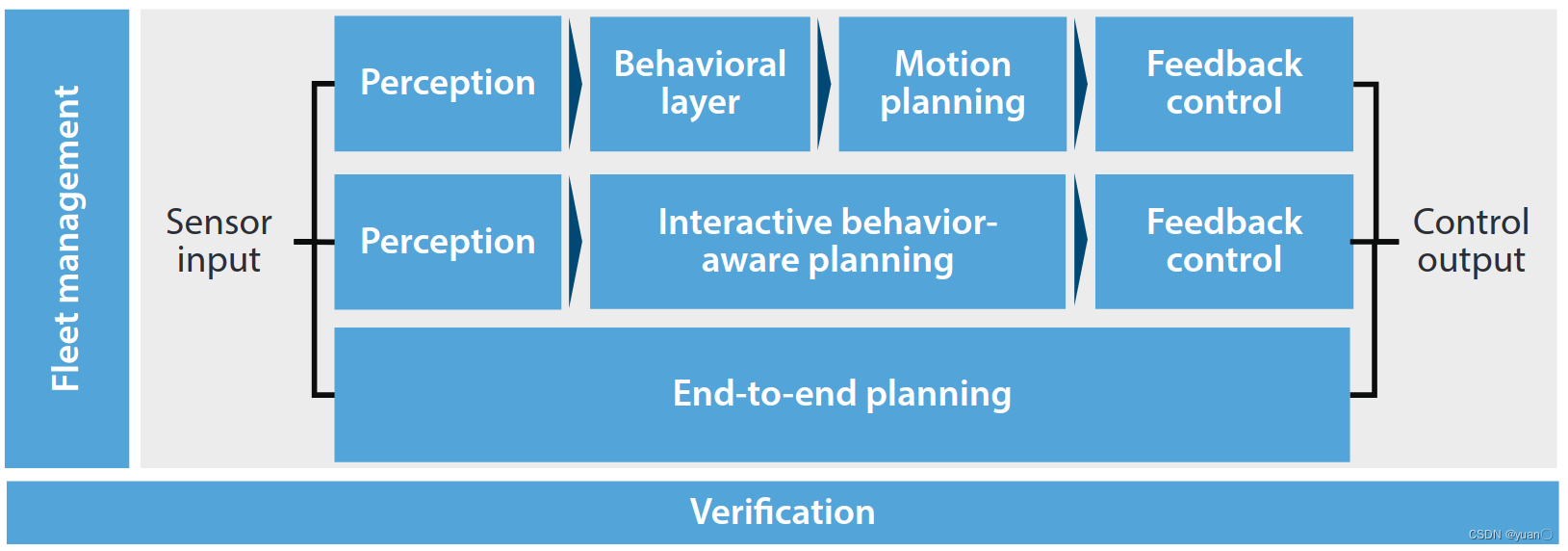
作者将现阶段的决策规划方法分为三种类型:
- sequential planning(传统的PipeLine式的planning)【第二章】
- end-to-end planning(端到端)【第三章】
- behavior-aware planning(行为意识决策规划)【第四章】
【第五章】主要是一些验证方法;【第六章】则是自动驾驶车辆编队运行的一些方法;【第七章】总结与展望。
2. MOTION PLANNING AND CONTROL
回顾一些传统的Control和Motion Planning的一些方法;还有parallel autonomy (人机共驾?);回顾现存决策规划的一些挑战。
2.1. Vehicle Dynamics and Control
对于一些低速的场景,使用运动学模型就足够,涉及到的控制方法有:PID、反馈线性化、MPC等等
对于高速或者驾驶行为比较激烈的场景,需要动力学模型的介入,涉及的方法有:非线性控制、MPC、反馈前馈控制。
作者还指出,不同的控制方法依赖于不同的车辆模型,并介绍了一些车辆模型识别的相关技术。这部分暂时还未接触过,不同的车辆应该有不同的高自由度模型以应对控制开发、仿真等需求。
2.2. Parallel Autonomy
作者首先介绍了常见自动驾驶控制系统的三种模式:
- series autonomy:由人类驾驶员发布指令给车辆进行具体执行。
- interleaved autonomy:人类驾驶员和控制系统交替控制。
- parallel autonomy:我理解为人机共驾,驾驶员和控制系统并行决策,提升在遇到危险时的安全性。parallel autonomy也是作者在这一节中主要介绍的。
作者指出,一种比较直观的方式合并驾驶员的输入以及控制系统的输出是将二者进行线性组合;另一种则是基于优化的方式,将驾驶员意图和系统目标的偏差最小化。基于优化的方式有一种典型的策略能够将优化问题简化——给定车辆速度 V V V,只对转向角进行优化。
2.3. Motion Planning for Autonomous Vehicles
作者先推荐了两篇运动控制方向的经典文章:
[1] Real-time motion planning methods for autonomous on-road driving: State-of-the-art and future research directions
[2] A Survey of Motion Planning and Control Techniques for Self-driving Urban Vehicles
作者给出传统Motion Planning的三种解决方案:
- 输入空间离散化+碰撞检测,比较经典的就是Lattice Planner和road-aligned primitives,比较适用于高速场景,这种方式简洁高效?(对计算量应该有不小要求)。空间离散化一般可以对状态空间或者控制空间进行操作。
- 随机采样类的算法。例如RRT,PRM等等。算法计算量不小,非最优的。
- 基于约束优化和滚动优化的方法,多应用于路径跟踪控制。考虑了车辆模型(动力学/运动学),轨迹通常比较平滑。这类方法需要考虑如何将问题转化为凸空间问题进行求解。
自动驾驶车辆还需要考虑到交通规则的约束问题,在一些情况(例如,超过非法停放的车辆)下,还需对一些规则作出违反。对此,可以将交通规则作为cost function,也可以将其作为逻辑函数。Minimum-violation routing这个问题还需面临环境、车辆模型等等诸多不确定的因素,单纯的基于规则的方法可能难以覆盖全部的场景。
作者提到的一些方法需要对交通参与者行为轨迹进行预测,但作者也指出,复杂场景以及交通参与者之间交互所产生的影响也是目前研究的一个方向与挑战。
3. INTEGRATED PERCEPTION AND PLANNING
3.1. From Classical Perception to Current Challenges in Neural Network–Based Perception Systems
感知的概述,我不是这个方向的,暂时不做深入理解。
3.2. End-to-End Planning
传统的Framework,各模块是相互解耦的,通过接口进行连接。作者在这里提到一种通过训练感知模块的部分功能去整合规划模块的任务。比如用弱监督学习的方式利用历史驾驶数据集进行轨迹预测与输出;用语义分割的方式生成路径……
更进一步的端到端,也可以称为行为映射法(behavior reflex approach),在1989年就有人用神经网络开始做了(ALVINN, Autonomous Land Vehicle in a Neural Network)。随着GPU算力的快速增长,网络层数不断加深,参数不断增多,end-to-end的效果也慢慢显露出来。NVIDIA在2006的工作中,通过建立原始前视摄像头与转向控制命令之间的映射关系,同时通过图像旋转、移动等等操作以及增加纠正样本的方法,能够使车辆适应一些更为复杂的场景。接着,作者介绍了一些关于通过观察输入图像的哪些区域对网络的输出贡献最大的研究(比如车道内的位置和方向)。
对于端到端规划到什么程度,有研究规划到决策层(直行、转向等等),也有规划到控制层(执行层,方向盘转角等等)。比如Xu et al利用LSTM去做的通过视频直接分别去学离散的决策和连续的控制的工作。
作者还介绍了DAgger,不仅仅是监督学习,强化学习等领域也是端到端应用的重点。下面是AI对DAgger (Dataset Aggregation)的介绍。
DAgger (Dataset Aggregation)是一种迭代式的强化学习方法,用于解决模型在测试时可能遇到的分布偏移问题。在DAgger中,首先通过人工指导或其他方法训练一个初始的模型,并用该模型对环境进行交互(比如在游戏中进行游戏),并收集一批“专家演示数据”。然后,使用这些数据重新训练模型,并用新模型再次与环境交互,生成新一批数据。这个过程可以重复多次,直到模型的性能足够好以满足需求。
DAgger的主要思想是将专家模型的知识与网络自己的探索相结合,以便让网络自己学习如何在新场景中进行操作。由于新模型的行动可能与专家演示数据不同,因此每次重新训练的数据集都在专家演示数据上添加了网络行为,这样新数据集就会更加接近真实场景,从而提高模型的性能。
DAgger是一种强化学习领域中效果比较好的方法,已被广泛应用于机器人控制、自动驾驶、游戏智能等领域。
机器人移动路径规划中也有经常运用端到端。机器人在需要能够现实世界中能够解决突发的各类问题以及适应未知环境,但像ensemble, bootstrap, 和Monte Carlo dropout等等用于量化神经网络不确定性的方法对于未知环境可能无法提供准确的不确定度的估计。遇到这情况时,可以将E2E的方法退回到传统的方法之中。
强化学习需要用到仿真环境,最后作者介绍了一些关于基于仿真环境训练强化学习的一些策略。
4. BEHAVIOR-AWARE MOTION PLANNING
第二章的大部分方法需要对其他交通参与者未来的行为进行预测,然而当环境拥挤时,预测每一个动态物体的运动是不现实的。
DARPA城市赛中有不少关于tactical planning(战术层规划)的方案,比如状态机、决策树等等,但这些rule-based的方案难以估计未知的、复杂变化的场景。
作者写到自动驾驶汽车和交通参与者之间能够进行交互、互相推断各自意图,基于所见进行推断但不需要明确的通信。这和V2X或者车路协同等等方式有些不太一致,没有明确的信息,可能会产生更大的不确定性,会威胁到整个交通系统的安全。
4.1. Cooperation and Interaction
多智能体之间的交互是十分重要的。一个智能体依赖于其他智能体作出决策,在遇到环境复杂、不确定的情况下,很可能会产生“不确定爆炸(exploding uncertainty)”和“机器人冻结问题”(freezing-robot problem,简单理解就是机器人面对过多的选择而无法进行决策)。对此,有以下三种主要的解决方案:
- 更好的环境建模以及对未来预期的建模。但依然会存在Freezing-robot Problem。
- 相当于假设所有其他机器人都是可控的:这会让策略非常激进,同时会带来潜在的风险。
- 基于联合分布的方式:包括联合概率分布和联合代价(cost)分布。
下面是一篇关于协作式规划(cooperative planning)的综述,cooperative planning不考虑与其他车辆、基础设施通信的问题,即不考虑V2X。
Ulbrich S, Grossjohann S, Appelt C, Homeier K, Rieken J, Maurer M. 2015. Structuring cooperative behavior planning implementations for automated driving. In 2015 IEEE 18th International Conference on Intelligent Transportation Systems (ITSC), pp. 2159–65. New York: IEEE
4.2. Game-Theoretic Approaches
博弈论有一个前提:假设所有的agent都会以采取最优的策略进行决策。这类方法可以用类似于基于概率的方式去计算,比如最大似然估计和最大后验估计。
博弈论的方法和上一种方法的区别在于并非基于联合代价或分布进行的:在双方博弈中,自车首先计算一个动作,然后模拟其他车辆以最大化自身预期奖励,其结果可能是高度交互的而不是被动反应的。
但随着agent数量的增多,会使得博弈问题呈指数级增长。一种简答的解决方法是将动作空间进行离散化,然后去搜索所有的可能。比如采用决策树的方式,但决策树也会随着agent的增多,指数级增长。为了更快实现最优或近似最优,有采用Monte Carlo tree search的方式;为了减少计算复杂度,有只让车辆受到前车的影响,从而将问题的复杂简化到agent数量的二次方。
也有采用Stackelberg game的方法,考虑最坏的情况,从而使每个agent不完全依赖于其他所有agent。这种方式复杂度较低,与agent呈线性关系,但决策速度较慢,决策较为保守。
4.3. Probabilistic Approaches
这一节主要讲了概率方法在自动驾驶领域中的应用。其中提到了一些具体的方法,比如Wei等人基于高速公路并道场景,使用MDP(Markov decision process)作为决策方法,搜索出可能的策略集,再依据cost fuction,选出最优的策略;还有使用离散流形来进行轨迹采样,智能驾驶模型来描述车流中单个车辆的纵向位置和速度的动力学,以及使用粒子滤波器来估计行为参数等。此外,还介绍了如何使用概率图模型来描述观测数据之间的依赖关系。这些方法的目标是提高自动驾驶车辆在复杂交通环境中的决策能力和安全性。
4.4. Partially Observable Markov Decision Processes
这一节介绍了部分可观察马尔可夫决策过程(Partially Observable Markov Decision Processes,POMDP)的概念和应用。在概率情况下,这个问题通常被建模为一个部分可观察的马尔可夫决策过程,其中其他代理的意图和重新规划程序并不是直接可观察的。POMDP通常离线进行,不仅仅计算当前状态的最优策略,而是计算每一个可能观测状态的最优策略。
POMDP问题是PSPACE完备的,也就意味着POMDP问题的解决需要花上大量的计算时间,这与决策模块所要求的100ms是冲突的。有些研究通过在预先规划的路径上规划所有车辆的运动,降低了给定问题的状态空间维数,简化问题。
PSPACE是计算机科学中的一个概念,代表着一类计算问题的复杂度。具体来说,PSPACE表示能够在多项式空间复杂度内解决的问题,即问题的解决所需的计算空间与问题规模的多项式成正比。这类问题通常涉及到对大量状态或组合的搜索和存储,如棋类游戏的解法、自动机的行为分析等。PSPACE问题的解决通常需要使用高级算法和数据结构。
有些研究在POMDP中整合了其他车辆的意图以及道路信息。POMDP也可不考虑交通参与者之间的交互,只考虑自车能达到的状态。作者还指出规划的视野一般小于10s,在高速公路或者城市道路场景中,实际所需的驾驶动作还是相对不多的,所以规划只需要达到一定精度就行,不用达到最优的状态。同时在抽象的轨迹上进行规划而不是具体的轨迹上进行规划,能够显著降低复杂度。
为POMDP找到合适的符号表示是困难的,因为它在很大程度上取决于具体的任务和情况。通常的方法是使用连续空间的等距离散化。一方面,这样的离散化通常过于粗糙,不能代表足够的细节来找到问题的解决方案。另一方面,它对不需要高精度的信息进行冗余编码。
4.5. Learning-Based Approaches
主要介绍了基于数据驱动的学习方法,该方法被应用于自动驾驶中的行为感知和运动规划。这些方法通常会将决策和规划分离开来,通过使用监督学习方法,如支持向量机、高斯混合模型(Gaussian mixture models)和人工神经网络,来训练模型。此外,反向强化学习技术(IRL)也被广泛用于学习专家驾驶员的决策和行为模式,并用于生成自动驾驶的决策和规划。最后,该节还介绍了一些新兴的学习方法,例如最大熵深度逆强化学习和对抗生成式模型学习,这些方法可以直接从原始输入数据中学习自动驾驶的行为模式。
5. VERIFICATION AND SYNTHESIS
暂略
6. FLEET MANAGEMENT
暂略
7. CONCLUSION
- 数据驱动的方式还是需要进一步的创新。
- 要保证自动驾驶汽车(算法)的可验证性、安全性和可解释性。
- 提升各类算法的泛化能力,以使自动驾驶汽车能够适应各类场景。
展望
- 复杂环境下的安全性、系统兼容性以及交互性
- 不确定环境下保证安全性能
- 极端场景下的适应能力
- 继续探索基于学习的方法
- 算法需要验证与评估
- 需要开发具有随机路线、在线性能和有限服务质量的大规模车队管理方法。