前言
- 要弄清MAML怎么做,为什么这么做,就要看懂这两张图。
- 先说MAML**在做什么?**它是打着Mate-Learing的旗号干的是few-shot multi-task Learning的事情。具体而言就是想训练一个模型能够使用很少的新样本,快速适应新的任务。
定义问题
- 我们定义一个模型
f
f
f, 输入
x
x
x输出
a
a
a。
-定义每一个Task - T T T包含一个损失函数 L L L, 一个原始观察 q ( x 1 ) q(x_1) q(x1), 一个状态转移分布 q ( x 1 ∣ x t , a t ) q(x_1 | x_t,a_t) q(x1∣xt,at)以及集长度 H H H。在监督任务中H=1(也就是说当前的a只和当前的x有关)。
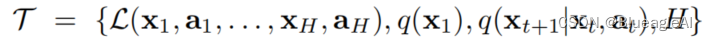
元学习方法介绍
- 元学习,被称为“Learn to Learn”的方法。元学习希望获取一个网络(结构+参数),满足一定的预设要求。
- 在我们的元学习场景中,我们考虑了一个跨任务的分布 p ( T ) p(T) p(T),我们希望我们的模型能够适应这个分布。在 K -shot学习的设置中,模型被训练来学习一个新的任务 T i T_i Ti,这个任务是从 p ( T ) p(T) p(T) 中抽取的,只使用了从 q i q_i qi 抽取的 K 个样本,并且由 T i T_i Ti 生成的反馈 L T i L_{T_i} LTi。在元训练期间,从 p ( T ) p(T) p(T) 中抽取一个任务 T i T_i Ti,模型会用从 T i T_i Ti 中抽取的 K 个样本和相应的损失 L T i L_{T_i} LTi的反馈进行训练,然后在来自 T i T_i Ti 的新样本上进行测试。然后,通过考虑模型在新数据上的测试误差更新参数,来改进模型 f f f。实际上,对抽样的任务 T i T_i Ti 进行的测试误差充当了元学习过程的训练错误。在元训练结束时,从 p ( T ) p(T) p(T) 中抽取新任务,并通过模型从 K 个样本中学习后的表现来衡量元能力。通常,在元训练期间保留用于元测试的任务。
A Model-Agnostic Meta-Learning Algorithm
-
给定一个初始的神经网络结构及参数,使用针对同一领域的多个任务集作为样本,对每个任务集分配这样一个网络,不同的任务集对各自的网络做一次loss计算和梯度更新,然后对所有更新之后的神经网络再计算一次loss,将这些loss综合考虑起来作为一个新的loss,来更新那个最开始的神经网络,再将获得到的网络作为新的初始神经网络,迭代这个过程。—引用自
-
这种方法背后的直觉是,一些内部表示比其他表示更可转移。The intuition behind this approach is that some internal representations are more transferrable than others.
-
实际上,我们的目标是找到对任务变化最敏感的模型参数,这样当改变梯度的方向,损失的小改变参数将产生大改进,如下图。

-
我们定义一个模型表示为 f θ f_{\theta} fθ。当适应新的任务 T i T_i Ti时,模型参数从 θ \theta θ变为 θ i ′ \theta'_i θi′.在我们的方法中,我们更新参数使用一个或多个任务T T i T_i Ti梯度向量.
-
当使用一个梯度进行更新:
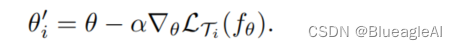
-
而元-目标是:
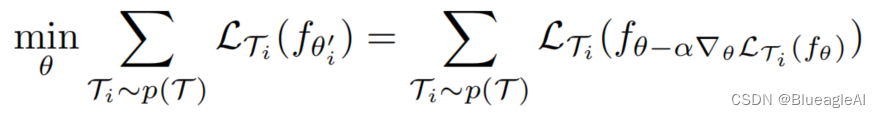
-整个算法如下:










![java八股文面试[JVM]——垃圾回收器](https://img-blog.csdnimg.cn/a56639a6c9c0481686b5d4b72b114552.jpeg#pic_center)