ES 7.6 - JAVA应用基础操作篇
- 环境准备
- 依赖配置
- 实体类准备
- 使用说明
- 索引/映射操作
- 创建索引和映射
- 索引和映射相关查询
- 删除索引
- 文档操作
- 插入数据
- 更新数据
- 删除数据
- 批量操作
- 文档查询
- 根据ID查询
- 根据字段精准查询
- 根据字段分词查询
- 控制返回字段
- 范围查询
- 组合查询
- 排序+分页
- 高亮搜索
- 聚合查询
- 场景查询实操
- 查询2023年中男、女的数量并找出对应的最大/最小年龄
- 查询在地址中包含 "深圳" 或者 备注中包含 "积极" 的 男性青年(18-30岁)
- 要求根据关键字找出匹配项目标,高亮实时预览
- 分别找出男、女性别中年龄最小的三个人(TOP N)
- 查询tag中带有某些标签的或者出身地在某某地的人,按照年龄降序,并且分页
- 总结
上文已经教了大家最基本的操作了,那我们在java代码里面要如何实现呢?本文的目的就是教大家在springboot框架下实现上文的API操作,也就是CURD!
环境准备
首先我们要知道ES的API都是HTTP请求!!!!,所以什么语言都可以操作,就是发送请求和处理返回而已嘛,只是说现在这种封装不需要我们做,有人做好了,这种叫做ES的客户端!
依赖配置
我们直接采用Spring-data-es的依赖,先看一下版本依赖说明:
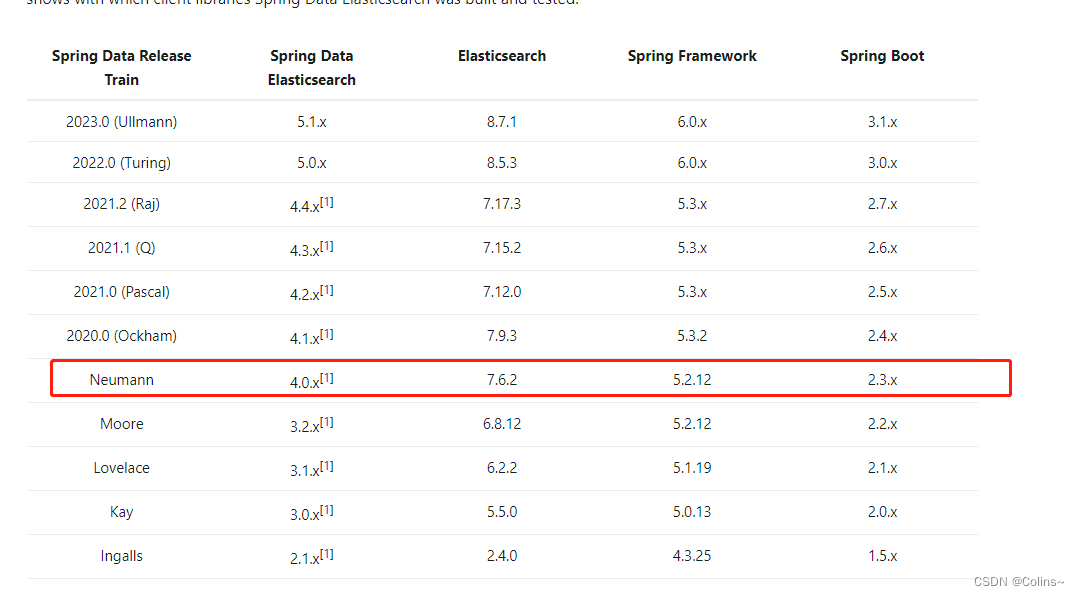
这里建议客户端版本和你自身搭建的es版本保持一致(es不同版本间api差异很大,如果不想出现莫名其妙的错的最好一致),所以这里我们选择springboot 2.3版本,这里给出spring-data-es的官方文档
# springboot版本
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.3.2.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
# spring-elasticsearch依赖
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-elasticsearch</artifactId>
<version>4.0.9.RELEASE</version>
</dependency>
因为我这ES是7.6的,所以选择使用HighLevelRestClient客户端,虽然这个已经在高版本过时了(8.x),但是在7.x版本里面官方建议使用这个
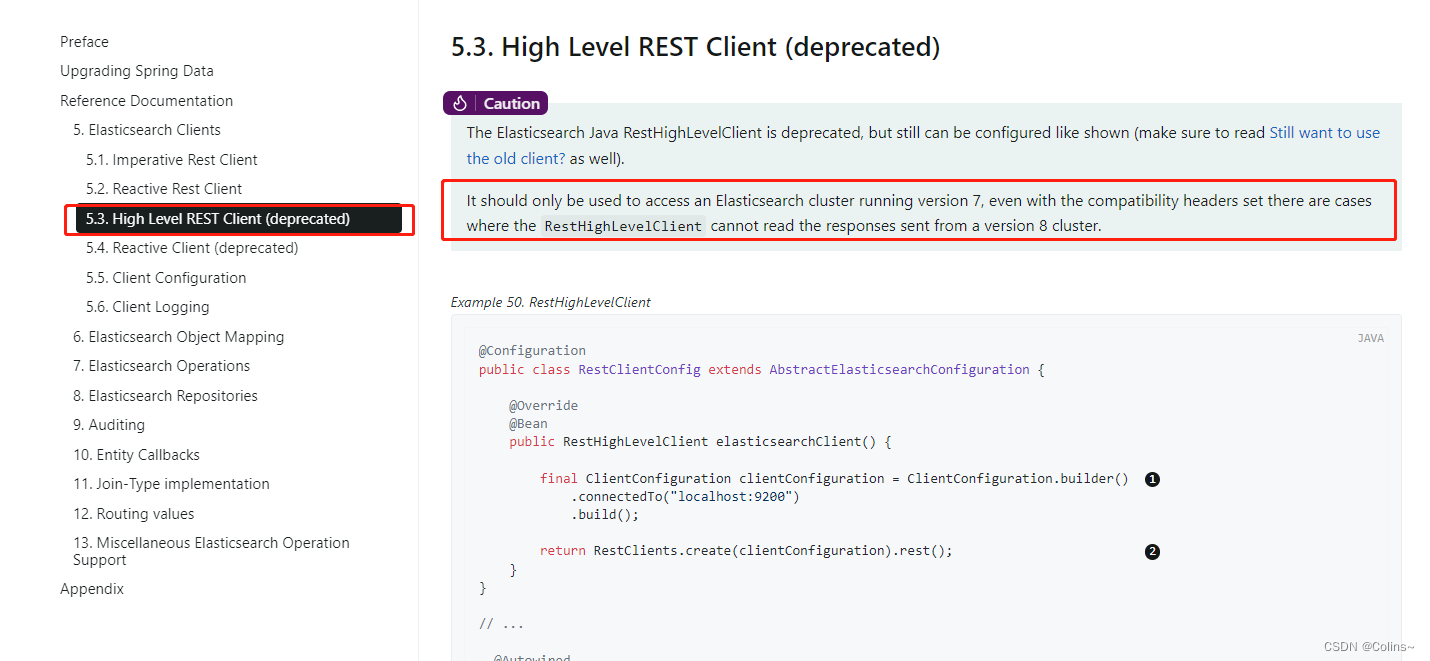
项目引入依赖后,使用非常简单,文件中配置一下ES地址,就可以愉快的访问啦:
# yml配置文件
spring:
elasticsearch:
rest:
uris: ip:port
username:
password:
实体类准备
@Data
@Document(indexName = "es_apply_test")
public class EsTest {
@Id
private Long id;
@Field(type = FieldType.Text,analyzer = "ik_max_word")
private String name;
@Field(type = FieldType.Keyword)
private String sex;
@Field(type = FieldType.Integer)
private Integer age;
@Field(type = FieldType.Text,analyzer = "ik_max_word")
private String remark;
@Field(type = FieldType.Keyword)
private String[] tag;
@Field(type = FieldType.Text,analyzer = "ik_max_word")
private String addressLocation;
@Field(type = FieldType.Keyword)
private String birthAddress;
@Field(type = FieldType.Date,pattern = "yyyy-MM-dd HH:mm:ss",format = DateFormat.custom)
private Date createTime;
@Field(type = FieldType.Boolean)
private Boolean hasGirlFriend;
public EsTest(){}
// 下面都是为了生成测试数据而准备的
private final static String[] city=new String[]{"深圳","广州","上海","北京","武汉"};
private final static String[] address=new String[]{"北京市朝阳区北辰东路15号","上海市黄浦区人民大道200号","深圳市福田区福中三路市民中心C区","武汉市江岸区一元街道沿江大道188号","广州市花都区新华街新都大道68号"};
public static EsTest getRandomData(Long id){
EsTest esTest = new EsTest();
esTest.setId(id);
esTest.setName(RandomUtil.randomString("张三李四王五陈六江文档词测试",3));
esTest.setSex(id%2==0 ? "男":"女");
esTest.setAge(RandomUtil.randomInt(15,30));
esTest.setRemark(RandomUtil.randomString("活波开朗,具有进取精神和团队精神,有较强的动手能力。良好协调沟通能力,适应力强,反应快、积极、细心、灵活, 具有一定的社会交往能力",15));
esTest.setTag(new String[]{RandomUtil.randomString("活波开朗,具有进取精神和团队精神,有较强的动手能力。良好协调沟通能力,适应力强,反应快、积极、细心、灵活, 具有一定的社会交往能力",3),
RandomUtil.randomString("活波开朗,具有进取精神和团队精神,有较强的动手能力。良好协调沟通能力,适应力强,反应快、积极、细心、灵活, 具有一定的社会交往能力",3),
RandomUtil.randomString("活波开朗,具有进取精神和团队精神,有较强的动手能力。良好协调沟通能力,适应力强,反应快、积极、细心、灵活, 具有一定的社会交往能力",3)});
esTest.setAddressLocation(address[RandomUtil.randomInt(0,address.length-1)]);
esTest.setBirthAddress(city[RandomUtil.randomInt(0,city.length-1)]);
esTest.setCreateTime(RandomUtil.randomDay(0,100));
esTest.setHasGirlFriend(id%4==0 ? true:false);
return esTest;
}
}
-
注解:@Document用来声明Java对象与ElasticSearch索引的关系
indexName 索引名称
type 索引类型
shards 主分区数量
replicas 副本分区数量
createIndex 索引不存在时,是否自动创建索引,默认true
不建议自动创建索引(自动创建的索引 是按着默认类型和默认分词器)
-
注解:@Id 表示索引的主键
-
注解:@Field 用来描述字段的ES数据类型,是否分词等配置,等于Mapping描述
index 设置字段是否索引,默认是true,如果是false则该字段不能被查询
store 默认为no,被store标记的fields被存储在和index不同的fragment中,以便于快速检索。虽然store占用磁盘空间,但是减少了计算。
type 数据类型(text、keyword、date、object、geo等)
analyzer 对字段使用分词器,注意一般如果要使用分词器,字段的type一般是text。
format 定义日期时间格式,详细见 官方文档: https://www.elastic.co/guide/reference/mapping/date-format/.
-
注解:@CompletionField 定义关键词索引 要完成补全搜索
analyzer 对字段使用分词器,注意一般如果要使用分词器,字段的type一般是text。
searchAnalyzer 显示指定搜索时分词器,默认是和索引是同一个,保证分词的一致性。
maxInputLength:设置单个输入的长度,默认为50 UTF-16 代码点
使用说明
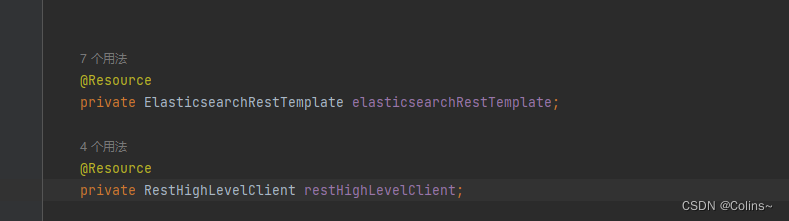
我们引入依赖后,在使用的时候有四种使用方式(下面我由简→难说明一下):
- ElasticsearchRepository:自动生成简单CURD方法,直接调用即可(复杂的不友好)
- ElasticsearchRestTemplate:内部使用的是RestHighLevelClient,它帮我们封装了一层
- RestHighLevelClient:直接使用客户端
- 自己封装客户端:之前说了本质就是HTTP请求,自己封装一下,直接调API呗,这比啥都好使
本文使用ElasticsearchRestTemplate(对小白友好),但是我个人强烈推荐直接用RestHighLevelClient,因为这个支持得更全面还同时支持同步和异步操作,本文有些操作也会用到这个
本文索引名称:es_apply_test
客户端注入:
索引/映射操作
创建索引和映射
@Test
void createIndexAndMapping() {
IndexOperations indexOperations = elasticsearchRestTemplate.indexOps(EsTest.class);
// 判断索引是否已经存在
if(!indexOperations.exists()){
// 不存在则创建
indexOperations.create();
Document mapping = indexOperations.createMapping(EsTest.class);
indexOperations.putMapping(mapping);
}
log.info("使用API查询查看..................");
}
索引和映射相关查询
@Test
void queryIndexAndMapping() {
IndexOperations indexOperations = elasticsearchRestTemplate.indexOps(EsTest.class);
boolean exists = indexOperations.exists();
log.info("索引是否存在:{}",exists);
Map<String, Object> mapping = indexOperations.getMapping();
log.info("映射:{}",JSONObject.toJSONString(mapping));
Map<String, Object> settings = indexOperations.getSettings();
log.info("索引设置:{}",JSONObject.toJSONString(settings));
// 索引刷新(这个功能用处,后面讲理论的时候你会知道是干嘛的)
indexOperations.refresh();
}
删除索引
@Test
void deletedIndex() {
IndexOperations indexOperations = elasticsearchRestTemplate.indexOps(EsTest.class);
indexOperations.delete();
}
文档操作
插入数据
/** 插入一条数据 */
@Test
void insertDoc() {
// 插入一条
elasticsearchRestTemplate.save(EsTest.getRandomData(1L));
// 同时插入多条 实际是遍历一条一条插入而不是用的bulk命令
elasticsearchRestTemplate.save(EsTest.getRandomData(2L),EsTest.getRandomData(3L));
}
更新数据
/** 更新数据 */
@Test
void updateDoc() throws IOException {
// es的数据结构都是文档,其实不存在文档更新,每次更新都会产生新的文档(这个是很低效的),所以es在API方面也看的出来对更新不是很友好
// 没办法,虽然更新很低效,但终究得改呀
// 下面提供几种方式
// 1.根据ID更新
UpdateQuery build = UpdateQuery.builder("1").withDocument(Document.parse("{ \"name\": \"根据ID更新\" }")).build();
elasticsearchRestTemplate.update(build,elasticsearchRestTemplate.getIndexCoordinatesFor(EsTest.class));
// 2.条件更新
// 采用highLevel客户端,根据查询条件 使用脚本更新 等同于_update_by_query API
UpdateByQueryRequest request = new UpdateByQueryRequest("es_apply_test");
request.setQuery(QueryBuilders.termQuery("age","24"));
request.setScript(new Script("ctx._source['age']='300';ctx._source['remark']='根据条件批量更新';"));
restHighLevelClient.updateByQuery(request, RequestOptions.DEFAULT);
}
删除数据
/** 删除数据 */
@Test
void deleteDoc() throws IOException {
// 1.根据ID删除
elasticsearchRestTemplate.delete("1",EsTest.class);
// 2.条件删除
NativeSearchQuery build = new NativeSearchQueryBuilder().withQuery(QueryBuilders.termQuery("id", "3")).build();
elasticsearchRestTemplate.delete(build,EsTest.class,elasticsearchRestTemplate.getIndexCoordinatesFor(EsTest.class));
}
批量操作
/** 批量增、删、改操作 */
@Test
void bulkDoc() throws IOException {
// 量大的话强烈推荐这种方式,因为ES本身是以查询突出,修改的吞吐量并不高
// 1. 批量插入
BulkRequest insertRequest = new BulkRequest();
for(int i=1;i<=20;i++){
IndexRequest indexRequest = new IndexRequest("es_apply_test");
indexRequest.id(String.valueOf(i));
indexRequest.source(JSONObject.toJSONString(EsTest.getRandomData((long)i)),XContentType.JSON);
insertRequest.add(indexRequest);
}
BulkResponse insertResult = restHighLevelClient.bulk(insertRequest, RequestOptions.DEFAULT);
log.info("是否失败: {},失败原因:{}",insertResult.hasFailures(),insertResult.buildFailureMessage());
// 2. 批量更新
BulkRequest updateRequest = new BulkRequest();
for(int i=1;i<=5;i++){
UpdateRequest indexRequest = new UpdateRequest();
indexRequest.id(String.valueOf(i));
indexRequest.index("es_apply_test");
HashMap<String, Object> objectObjectHashMap = new HashMap<>();
objectObjectHashMap.put("name","bulk批量更新");
indexRequest.doc(objectObjectHashMap);
updateRequest.add(indexRequest);
}
BulkResponse updateResult = restHighLevelClient.bulk(updateRequest, RequestOptions.DEFAULT);
log.info("是否失败: {},失败原因:{}",updateResult.hasFailures(),updateResult.buildFailureMessage());
// 3. 批量删除
BulkRequest deleteRequest = new BulkRequest();
for(int i=1;i<=5;i++){
DeleteRequest request = new DeleteRequest();
request.id(String.valueOf(i));
request.index("es_apply_test");
updateRequest.add(request);
}
BulkResponse deleteResult = restHighLevelClient.bulk(deleteRequest, RequestOptions.DEFAULT);
log.info("是否失败: {},失败原因:{}",deleteResult.hasFailures(),deleteResult.buildFailureMessage());
// 当然也可混合操作 就是 _bulk API
}
文档查询
根据ID查询
/** 根据id查 */
@Test
void getDataById() {
EsTest esTest = elasticsearchRestTemplate.get("1", EsTest.class);
log.info("结果:{}", JSONObject.toJSONString(esTest));
}
根据字段精准查询
@Test
void termQuery() {
// term 精准查询
TermQueryBuilder termQuery = QueryBuilders.termQuery("age", 10);
NativeSearchQuery nativeSearchQuery = new NativeSearchQuery(termQuery);
SearchHits<EsTest> termResult = elasticsearchRestTemplate.search(nativeSearchQuery, EsTest.class);
log.info("term-> 总数量:{} 结果:{}", termResult.getTotalHits(),JSONObject.toJSONString(termResult.getSearchHits()));
// terms 精准查询
TermsQueryBuilder termsQueryBuilder = QueryBuilders.termsQuery("tag", "良心力", "高于动");
NativeSearchQuery nativeSearchQuery1 = new NativeSearchQuery(termsQueryBuilder);
SearchHits<EsTest> termsResult = elasticsearchRestTemplate.search(nativeSearchQuery1, EsTest.class);
log.info("terms-> 总数量:{} 结果:{}", termsResult.getTotalHits(),JSONObject.toJSONString(termsResult.getSearchHits()));
}
根据字段分词查询
/** 根据字段分词查询 */
@Test
void matchQuery() {
// matchall 全量查询 默认是分页查询10条
MatchAllQueryBuilder matchAllQueryBuilder = QueryBuilders.matchAllQuery();
NativeSearchQuery nativeSearchQuery = new NativeSearchQuery(matchAllQueryBuilder);
SearchHits<EsTest> matchAll = elasticsearchRestTemplate.search(nativeSearchQuery, EsTest.class);
log.info("match all-> 总数量:{} 结果:{}", matchAll.getTotalHits(),JSONObject.toJSONString(matchAll.getSearchHits()));
// match 根据字段分词查询(字段分词)
MatchQueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("addressLocation", "街道");
NativeSearchQuery nativeSearchQuery1 = new NativeSearchQuery(matchQueryBuilder);
SearchHits<EsTest> match = elasticsearchRestTemplate.search(nativeSearchQuery1, EsTest.class);
log.info("match -> 总数量:{} 结果:{}", match.getTotalHits(),JSONObject.toJSONString(match.getSearchHits()));
// match_phrase 根据字段分词查询(字段不分词)
MatchPhraseQueryBuilder matchPhraseQueryBuilder = QueryBuilders.matchPhraseQuery("addressLocation", "街道,武汉");
NativeSearchQuery nativeSearchQuery2 = new NativeSearchQuery(matchPhraseQueryBuilder);
SearchHits<EsTest> matchPhrase = elasticsearchRestTemplate.search(nativeSearchQuery2, EsTest.class);
log.info("match_phrase -> 总数量:{} 结果:{}", matchPhrase.getTotalHits(),JSONObject.toJSONString(matchPhrase.getSearchHits()));
// multi_match 根据字段分词查询多个字段
MultiMatchQueryBuilder multiMatchQueryBuilder = QueryBuilders.multiMatchQuery("街道,武汉,队协", "addressLocation", "remark");
NativeSearchQuery nativeSearchQuery3 = new NativeSearchQuery(multiMatchQueryBuilder);
SearchHits<EsTest> multiMatch = elasticsearchRestTemplate.search(nativeSearchQuery3, EsTest.class);
log.info("multiMatch -> 总数量:{} 结果:{}", multiMatch.getTotalHits(),JSONObject.toJSONString(multiMatch.getSearchHits()));
}
控制返回字段
/** 控制返回字段 */
@Test
void fieldFilterQuery() {
// matchall 全量查询 并控制返回字段
NativeSearchQuery build = new NativeSearchQueryBuilder()
.withQuery(QueryBuilders.matchAllQuery())
.withFields("id", "name")
.build();
SearchHits<EsTest> matchAll = elasticsearchRestTemplate.search(build, EsTest.class);
log.info("match all-> 总数量:{} 结果:{}", matchAll.getTotalHits(),JSONObject.toJSONString(matchAll.getSearchHits()));
}
范围查询
/** 范围查询 */
@Test
void rangeQuery() {
// 范围查询 并控制返回字段
NativeSearchQuery build = new NativeSearchQueryBuilder()
.withQuery(QueryBuilders.rangeQuery("age").gte(20).lte(30))
.withFields("id", "name","age")
.build();
SearchHits<EsTest> matchAll = elasticsearchRestTemplate.search(build, EsTest.class);
log.info("match all-> 总数量:{} 结果:{}", matchAll.getTotalHits(),JSONObject.toJSONString(matchAll.getSearchHits()));
}
组合查询
/** 组合查询 and 、or 、!= */
@Test
void boolGroupQuery() {
// 范围查询 并控制返回字段
// =10岁 !=男
NativeSearchQuery build = new NativeSearchQueryBuilder()
.withQuery(QueryBuilders.boolQuery().must(QueryBuilders.termQuery("age",23)).mustNot(QueryBuilders.termQuery("sex","男")))
.withFields("id", "name","age","sex")
.build();
SearchHits<EsTest> matchAll = elasticsearchRestTemplate.search(build, EsTest.class);
log.info("match all-> 总数量:{} 结果:{}", matchAll.getTotalHits(),JSONObject.toJSONString(matchAll.getSearchHits()));
}
排序+分页
/** 排序+分页 */
@Test
void sortAndPageQuery() {
// 排序+分页 排序可以多个
NativeSearchQuery build = new NativeSearchQueryBuilder()
.withQuery(QueryBuilders.matchAllQuery())
.withSort(SortBuilders.fieldSort("age").order(SortOrder.ASC))
.withSort(SortBuilders.fieldSort("id").order(SortOrder.DESC))
.withSort(SortBuilders.scoreSort())
.withFields("id", "name","age","sex")
.withPageable(PageRequest.of(0,5))
.build();
SearchHits<EsTest> matchAll = elasticsearchRestTemplate.search(build, EsTest.class);
log.info("match all-> 总数量:{} 结果:{}", matchAll.getTotalHits(),JSONObject.toJSONString(matchAll.getSearchHits()));
}
高亮搜索
/** 高亮搜索 */
@Test
void highlightQuery() {
// 高亮搜索
NativeSearchQuery build = new NativeSearchQueryBuilder()
.withQuery(QueryBuilders.multiMatchQuery("武汉深圳", "addressLocation", "remark"))
.withFields("id", "name","addressLocation","remark")
.withHighlightBuilder(new HighlightBuilder().preTags("<span style='color:red'>").postTags("</span>"))
.withHighlightFields(new HighlightBuilder.Field("addressLocation"),new HighlightBuilder.Field("remark"))
.build();
SearchHits<EsTest> matchAll = elasticsearchRestTemplate.search(build, EsTest.class);
log.info("match all-> 总数量:{} 结果:{}", matchAll.getTotalHits(),JSONObject.toJSONString(matchAll.getSearchHits()));
}
聚合查询
/** 聚合查询 */
@Test
void aggregateQuery() {
// 不分组 聚合查询
NativeSearchQuery build = new NativeSearchQueryBuilder()
.addAggregation(AggregationBuilders.avg("ageAvg").field("age"))
.addAggregation(AggregationBuilders.sum("ageSum").field("age"))
.addAggregation(AggregationBuilders.max("ageMax").field("age"))
.addAggregation(AggregationBuilders.min("ageMin").field("age"))
.withPageable(PageRequest.of(0,1)) // 应该设置为0,因为只需要聚合数据,但无赖有校验设置不了
.build();
SearchHits<EsTest> search = elasticsearchRestTemplate.search(build, EsTest.class);
log.info("match all-> 总数量:{} 结果:{}", search.getTotalHits(),JSONObject.toJSONString(search.getAggregations()));
// 先分组 在聚合
NativeSearchQuery build1 = new NativeSearchQueryBuilder()
.addAggregation(AggregationBuilders.terms("groupBySex").field("sex")
.subAggregation(AggregationBuilders.avg("ageAvg").field("age"))
.subAggregation(AggregationBuilders.sum("ageSum").field("age"))
.subAggregation(AggregationBuilders.max("ageMax").field("age"))
.subAggregation(AggregationBuilders.min("ageMin").field("age"))
)
.withPageable(PageRequest.of(0,1)) // 应该设置为0,因为只需要聚合数据,但无赖有校验设置不了
.build();
SearchHits<EsTest> search1 = elasticsearchRestTemplate.search(build1, EsTest.class);
Map<String, Aggregation> map = search1.getAggregations().asMap();
Aggregation groupBySex = map.get("groupBySex");
log.info("打断点看吧:{}",groupBySex);
}
场景查询实操
查询2023年中男、女的数量并找出对应的最大/最小年龄
/** 查询2023年中男、女的数量并找出对应的最大/最小年龄 */
@Test
void demo1() {
NativeSearchQuery build = new NativeSearchQueryBuilder()
.addAggregation(AggregationBuilders.terms("groupBySex").field("sex")
.subAggregation(AggregationBuilders.count("count").field("id"))
.subAggregation(AggregationBuilders.max("maxAge").field("age"))
.subAggregation(AggregationBuilders.min("minAge").field("age"))
).withPageable(PageRequest.of(0,1)).build();
SearchHits<EsTest> search = elasticsearchRestTemplate.search(build, EsTest.class);
log.info("打断点查看:{}",search.getAggregations());
}
查询在地址中包含 “深圳” 或者 备注中包含 “积极” 的 男性青年(18-30岁)
要求关键词高亮
/** 查询在地址中包含 "深圳" 或者 备注中包含 "积极" 的 男性青年(18-30岁),要求关键词高亮 */
@Test
void demo2() {
NativeSearchQuery build = new NativeSearchQueryBuilder()
.withQuery(QueryBuilders.boolQuery().must(QueryBuilders.termQuery("sex","男"))
.must(QueryBuilders.rangeQuery("age").gte(18).lte(30))
.must(QueryBuilders.boolQuery()
.should(QueryBuilders.matchQuery("addressLocation","深圳"))
.should(QueryBuilders.matchQuery("remark","积极"))
)
)
.withHighlightBuilder(new HighlightBuilder().preTags("<span style='color:red'>").postTags("</span>"))
.withHighlightFields(new HighlightBuilder.Field("addressLocation"),new HighlightBuilder.Field("remark"))
.build();
SearchHits<EsTest> search = elasticsearchRestTemplate.search(build, EsTest.class);
log.info("总量:{} 数据:{}",search.getTotalHits(),JSONObject.toJSONString(search.getSearchHits()));
}
要求根据关键字找出匹配项目标,高亮实时预览
(搜地址、名称,返回 名称+id + 地址)
/** 搜索框:要求根据关键字找出匹配项目标,高亮实时预览(搜地址、名称,返回 名称+id + 地址) */
@Test
void demo3() {
NativeSearchQuery build = new NativeSearchQueryBuilder()
.withQuery(QueryBuilders.multiMatchQuery("林深","name","addressLocation"))
.withFields("id", "name","addressLocation")
.withHighlightBuilder(new HighlightBuilder().preTags("<span style='color:red'>").postTags("</span>"))
.withHighlightFields(new HighlightBuilder.Field("addressLocation"),new HighlightBuilder.Field("name"))
.build();
SearchHits<EsTest> search = elasticsearchRestTemplate.search(build, EsTest.class);
log.info("总量:{} 数据:{}",search.getTotalHits(),JSONObject.toJSONString(search.getSearchHits()));
}
分别找出男、女性别中年龄最小的三个人(TOP N)
/** 分别找出男、女性别中年龄最小的三个人(TOP N) */
@Test
void demo4() {
NativeSearchQuery build = new NativeSearchQueryBuilder()
.addAggregation(AggregationBuilders.terms("groupBySex").field("sex")
.subAggregation(AggregationBuilders.topHits("top3")
.sort("age",SortOrder.ASC)
.fetchSource(new String[]{"name","sex","age"},null)
.size(3)
)
)
.build();
SearchHits<EsTest> search = elasticsearchRestTemplate.search(build, EsTest.class);
log.info("打断点自己看-》总量:{} 数据:{}",search.getTotalHits(),search.getAggregations());
}
查询tag中带有某些标签的或者出身地在某某地的人,按照年龄降序,并且分页
/** 查询tag中带有某些标签的或者出身地在某某地的人,按照年龄降序,并且分页 */
@Test
void demo5() {
NativeSearchQuery build = new NativeSearchQueryBuilder()
.withQuery(QueryBuilders.boolQuery()
.should(QueryBuilders.termsQuery("tag","断能能","高于动","上格心","对朗步"))
.should(QueryBuilders.termsQuery("birthAddress","深圳","章丘"))
)
.withSort(SortBuilders.fieldSort("age").order(SortOrder.DESC))
.withSort(SortBuilders.scoreSort().order(SortOrder.DESC))
.withPageable(PageRequest.of(0,5))
.build();
SearchHits<EsTest> search = elasticsearchRestTemplate.search(build, EsTest.class);
log.info("总量:{} 数据:{}",search.getTotalHits(),search.getSearchHits());
}
总结
到了这恭喜你,你也成功的入门ES,成为了一名ES的CURD BOY,但你觉得ES就仅仅如此吗?少年加油吧,才刚开始呢!!
后面会介绍一些重点操作,以及相应的进阶理论知识,理论会偏多!
![[NLP]深入理解 Megatron-LM](https://img-blog.csdnimg.cn/5767492cc8b1460cb208630645dbe5f1.png)









![[论文阅读笔记25]A Comprehensive Survey on Graph Neural Networks](https://img-blog.csdnimg.cn/a60d7a56c9a444439815142a440d23f5.png)