1. 导读
NVIDIA Megatron-LM 是一个基于 PyTorch 的分布式训练框架,用来训练基于Transformer的大型语言模型。Megatron-LM 综合应用了数据并行(Data Parallelism),张量并行(Tensor Parallelism)和流水线并行(Pipeline Parallelism)来复现 GPT-3.
2. 动机
在自然语言处理(NLP)领域,大型模型能够提供更精准和强大的语义理解与推理能力。随着计算资源的普及和数据集的增大,模型参数的数量呈指数级增长。然而,训练这样规模庞大的模型面临着一些挑战:
- 显存限制: 即便是目前最大的GPU主内存也难以容纳这些模型的参数。举例来说,一个1750亿参数的GPT-3模型需要约700GB的参数空间,对应的梯度约为700GB,而优化器状态还需额外的1400GB,总计需求高达2.8TB。
- 计算挑战: 即使我们设法将模型适应单个GPU(例如通过在主机内存和设备内存之间进行参数交换),模型所需的大量计算操作也会导致训练时间大幅延长。举个例子,使用一块NVIDIA V100 GPU来训练拥有1750亿参数的GPT-3模型,大约需要耗时288年。
- 并行策略挑战: 不同的并行策略对应不同的通信模式和通信量,这也是一个需要考虑的挑战。
3. 并行策略和方法简介
3.1 数据并行
数据并行模式会在每个worker之上复制一份模型,这样每个worker都有一个完整模型的副本。输入数据集是分片的,一个训练的小批量数据将在多个worker之间分割;worker定期汇总它们的梯度,以确保所有worker看到一个一致的权重版本。对于无法放进单个worker的大型模型,人们可以在模型之中较小的分片上使用数据并行。
数据并行扩展通常效果很好,但有两个限制:
- a)超过某一个点之后,每个GPU的batch size变得太小,这降低了GPU的利用率,增加了通信成本;
- b)可使用的最大设备数就是batch size,限制了可用于训练的加速器数量。
3.2 模型并行
人们会使用一些内存管理技术,如激活检查点(activation checkpointing)来克服数据并行的这种限制,也会使用模型并行来对模型进行分区来解决这两个挑战,使得权重及其关联的优化器状态不需要同时驻留在处理器上。
模型并行模式会让一个模型的内存和计算分布在多个worker之间,以此来解决一个模型在一张卡上无法容纳的问题,其解决方法是把模型放到多个设备之上。
模型并行分为两种:流水线并行和张量并行,就是把模型切分的方式。
- 流水线并行(pipeline model parallel)是把模型不同的层放到不同设备之上,比如前面几层放到一个设备之上,中间几层放到另外一个设备上,最后几层放到第三个设备之上。
- 张量并行则是层内分割,把某一个层做切分,放置到不同设备之上,也可以理解为把矩阵运算分配到不同的设备之上,比如把某个矩阵乘法切分成为多个矩阵乘法放到不同设备之上。
具体如下图,上面是层间并行(流水线并行),纵向切一刀,前面三层给第一个GPU,后面三层给第二个GPU。下面是层内并行(tensor并行),横向切一刀,每个张量分成两块,分到不同GPU之上。
这两种模型切分方式是可以同时存在的,实现正交和互补的效果。

从另一个角度看看,两种切分同时存在,是正交和互补的(orthogonal and complimentary)。

通信分析
对于模型并行的通信状况。
流水线并行:通信在流水线阶段相邻的切分点之上,通信类型是P2P通信,单词通信数据量较少但是比较频繁,而且因为流水线的特点,会产生GPU空闲时间,这里称为流水线气泡(Bubble)。
比如下图之中,上方是原始流水线,下面是流水线并行,中间给出了 Bubble 位置。
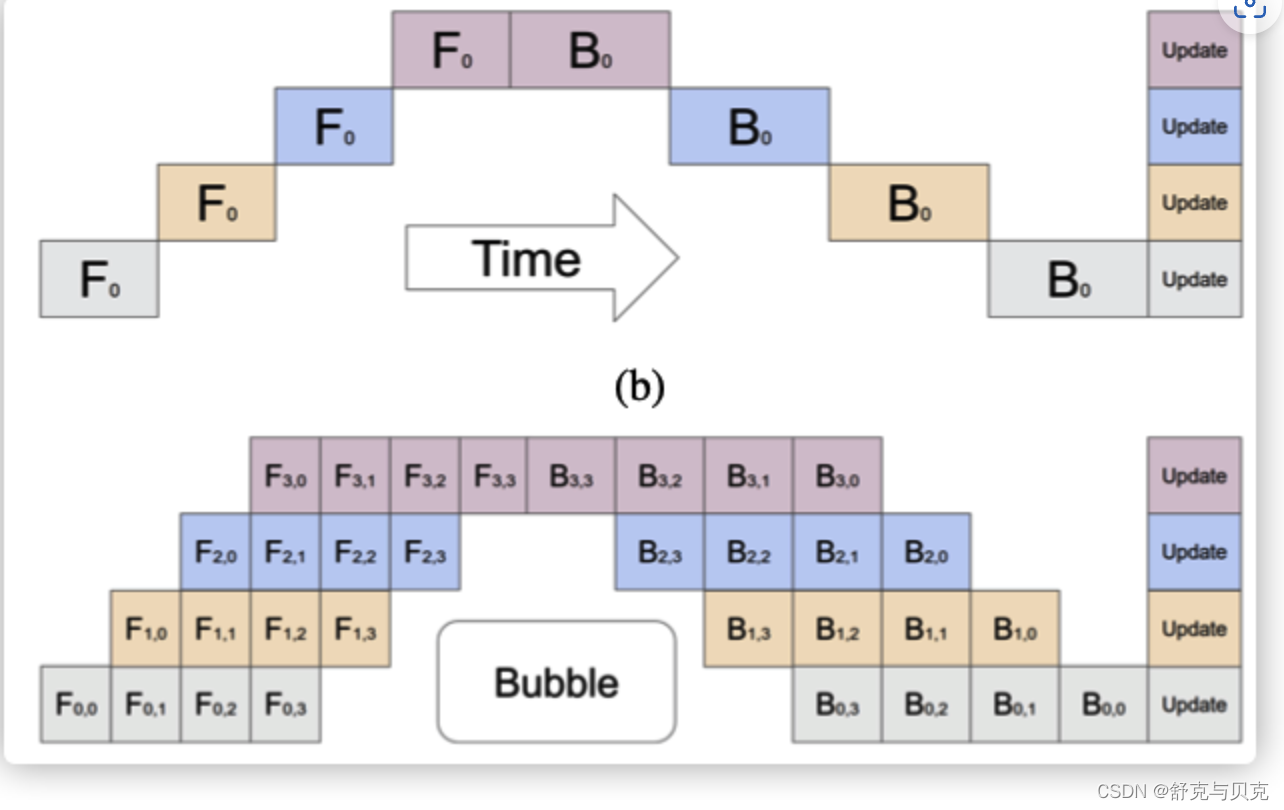
张量并行:通信发生在每层的前向传播和后向传播过程之中,通信类型是all-reduce,不但单次通信数据量大,并且通信频繁。
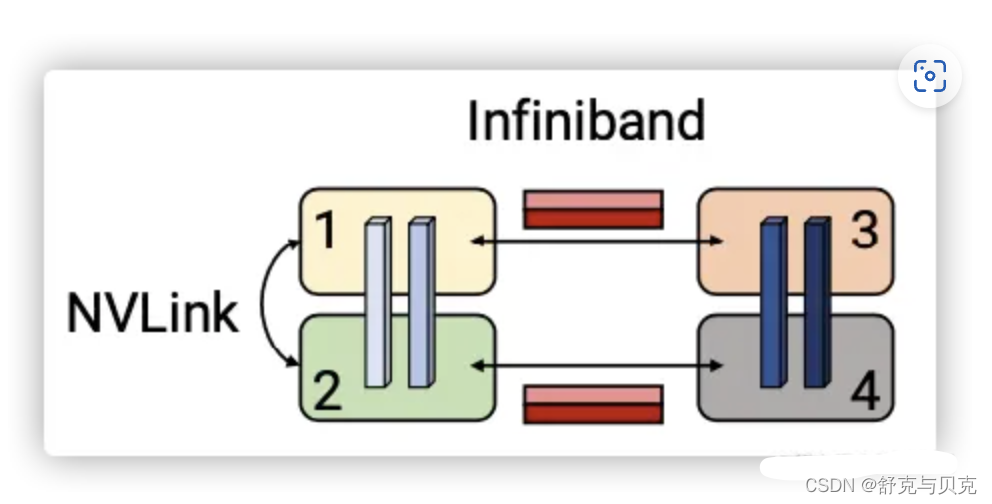
张量并行一般都在同一个机器之上,所以通过 NVLink 来进行加速,对于流水线并行,一般通过 Infiniband 交换机进行连接。
3.2.1 张量并行
张量模型并行化(tensor model parallelism)将每个transformer 层内的矩阵乘法被分割到多个GPU上,虽然这种方法在NVIDIA DGX A100服务器(有8个80GB-A100 GPU)上对规模不超过200亿个参数的模型效果很好,但对更大的模型就会出现问题。因为较大的模型需要在多个multi-GPU服务器上分割,这导致了两个问题。
- 张量并行所需的all-reduce通信需要通过服务器间的链接,这比multi-GPU服务器内的高带宽NVLink要慢;
- 高度的模型并行会产生很多小矩阵乘法(GEMMs),这可能会降低GPU的利用率。
3.2.2 流水线并行
流水线模型并行化是另一项支持大型模型训练的技术。在流水线并行之中,一个模型的各层会在多个GPU上做切分。一个批次(batch)被分割成较小的微批(micro-batches),并在这些微批上进行流水线式执行。
通过流水线并行,一个模型的层被分散到多个设备上。当用于具有相同transformer块重复的模型时,每个设备可以被分配相同数量的transformer层。Megatron不考虑更多的非对称模型架构,在这种架构下,层的分配到流水线阶段是比较困难的。在流水线模型并行中,训练会在一个设备上执行一组操作,然后将输出传递到流水线中下一个设备,下一个设备将执行另一组不同操作。
原始的流水线并行会有这样的问题:一个输入在后向传递中看到的权重更新并不是其前向传递中所对应的。所以,流水线方案需要确保输入在前向和后向传播中看到一致的权重版本,以实现明确的同步权重更新语义。
模型的层可以用各种方式分配给worker,并且对于输入的前向计算和后向计算使用不同的schedule。层的分配策略和调度策略导致了不同的性能权衡。无论哪种调度策略,为了保持严格的优化器语义,优化器操作步骤需要跨设备同步,这样,在每个批次结束时需要进行流水线刷新来完成微批执行操作(同时没有新的微批被注入)。Megatron-LM引入了定期流水线刷新。
在每个批次的开始和结束时,设备是空闲的。我们把这个空闲时间称为流水线bubble,并希望它尽可能的小。根据注入流水线的微批数量(micro-batches),多达50%的时间可能被用于刷新流水线。微批数量与流水线深度(size)的比例越大,流水线刷新所花费的时间就越少。因此,为了实现高效率,通常需要较大的batch size。
一些方法将参数服务器与流水线并行使用。然而,这些都存在不一致的问题。TensorFlow的GPipe框架通过使用同步梯度下降克服了这种不一致性问题。然而,这种方法需要额外的逻辑来处理这些通信和计算操作流水线,并且会遇到降低效率的流水线气泡,或者对优化器本身的更改会影响准确性。
某些异步和bounded-staleness方法,如PipeMare、PipeDream和PipeDream-2BW完全取消了刷新,但这样会放松了权重更新语义。Megatron会在未来的工作中考虑这些方案。
3.2.3 技术组合
用户可以使用多种技术来训练大型模型,每种技术都涉及不同的权衡考量。此外,这些技术也可以结合使用。然而,技术的结合可能导致复杂的相互作用,特别是在系统拓扑方面的设计,不仅需要根据算法特点对模型进行合理切割,还需要在软硬件一体的系统架构设计中进行推敲,以实现良好的性能。因此,以下问题显得尤为重要:
如何组合并行技术,以在保留严格的优化器语义的同时,在给定的批量大小下最大限度地提高大型模型的训练吞吐量?
Megatron-LM的开发人员演示了一种名为PTD-P的技术,它结合了流水线、张量和数据并行。这种技术在1000个GPU上训练大型语言模型,以良好的计算性能(达到峰值设备吞吐量的52%)。 PTD-P利用跨多GPU服务器的流水线并行、多GPU服务器内的张量并行和数据并行的组合,利用了在同一服务器和跨服务器的GPU之间具有高带宽链接的优化集群环境,能够训练具有一万亿参数的模型,并具备良好的扩展性。
这种技术示范了如何在大规模分布式系统中充分发挥不同并行技术的优势,以实现高效的大型模型训练。
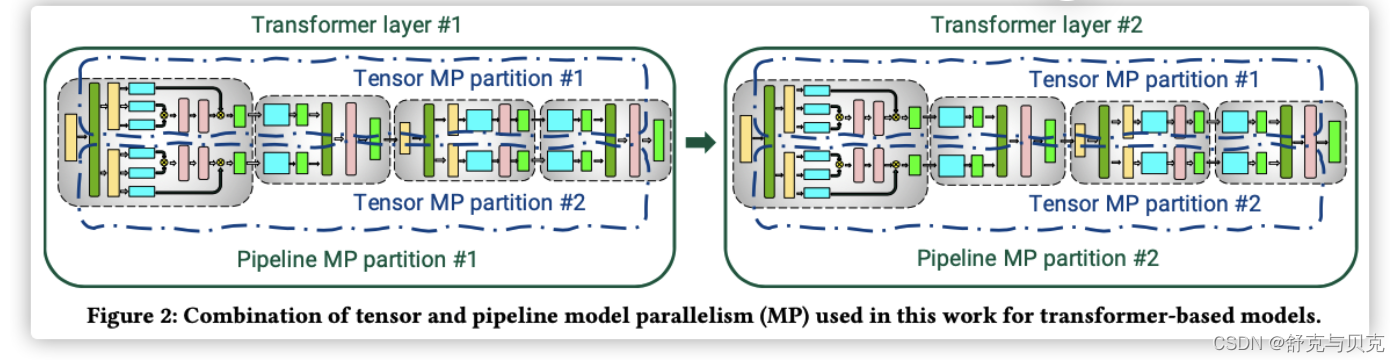
要实现这种规模化的吞吐量,需要在多个方面进行创新和精心设计:
- 高效的核实现: 关键是实现高效的核(kernel),使大部分计算操作成为计算绑定而不是内存绑定。这意味着计算任务能够更快地完成,从而提高整体的计算效率。
- 智能的计算图分割: 针对设备上的计算图进行智能的分割,以减少通过网络传输的数据量。通过将计算分散到多个设备上,不仅减少了数据传输的成本,还可以限制设备的空闲时间,从而提高整体的计算效率。
- 通信优化和高速硬件利用: 在特定领域实施通信优化,利用高速硬件如先进的GPU,以及在同一服务器内和不同服务器GPU之间使用高带宽链接,可以大幅提升数据传输的速度和效率。这对于分布式系统中的数据交换至关重要。
通过在上述方面进行创新和优化,可以有效地提高大型模型训练的规模化吞吐量,实现更高的训练效率和性能。这需要结合领域专业知识和系统设计,以解决各种挑战并取得成功。
3.2.4 指导原则
Megatron开发者对不同的并行模式组合以及其之间的影响进行了研究,并总结出了分布式训练的一些指导原则:
- 并行模式的相互作用: 不同的并行化策略之间以复杂的方式相互影响。并行模式的选择会影响通信量、计算核的效率以及由于流水线刷新(流水线气泡)而导致的worker空闲时间。例如,张量模型并行在多GPU服务器上表现良好,但对于大型模型,最好采用流水线模型并行。
- 流水线并行的调度影响: 用于流水线并行的调度方式会影响通信量、流水线气泡的大小以及存储激活所需的内存。Megatron提出了一种新的交错调度方式,相比先前的调度方式,它在稍微增加内存占用的基础上,可以提高多达10%的吞吐量。
- 超参数的影响: 超参数的值,如微批量大小(microbatch size),会影响内存占用、在worker上执行的核效果以及流水线气泡的大小。
- 通信密集性: 分布式训练是通信密集型的过程。使用较慢的节点间连接或者更多的通信密集型分区会限制性能表现。
综合上述指导原则,Megatron开发者通过深入研究不同并行技术的相互作用,超参数的调优以及通信密集性等因素,为分布式训练提供了更加明确的方向,以实现更高效的大型模型训练吞吐量。
4. 结论
Megatron在训练拥有万亿参数的大型模型时,采用了PTD-P(Pipeline, Tensor, and Data Parallelism)方法,从而实现了高度聚合的吞吐量(502 petaFLOP/s)。
在该方法中,Tensor模型并行用于intra-node transformer层,这使得在基于HGX系统的平台上能够高效运行。同时,Pipeline模型并行则被应用于inter-node transformer层,充分利用了集群中多网卡的设计,提升了模型训练的效率。
除此之外,数据并行也在前述两种并行策略的基础上进行了加强,从而使得训练能够扩展到更大规模,并且实现更快的训练速度。









![[论文阅读笔记25]A Comprehensive Survey on Graph Neural Networks](https://img-blog.csdnimg.cn/a60d7a56c9a444439815142a440d23f5.png)