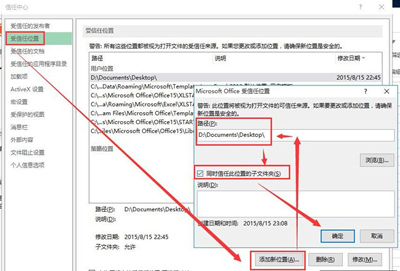
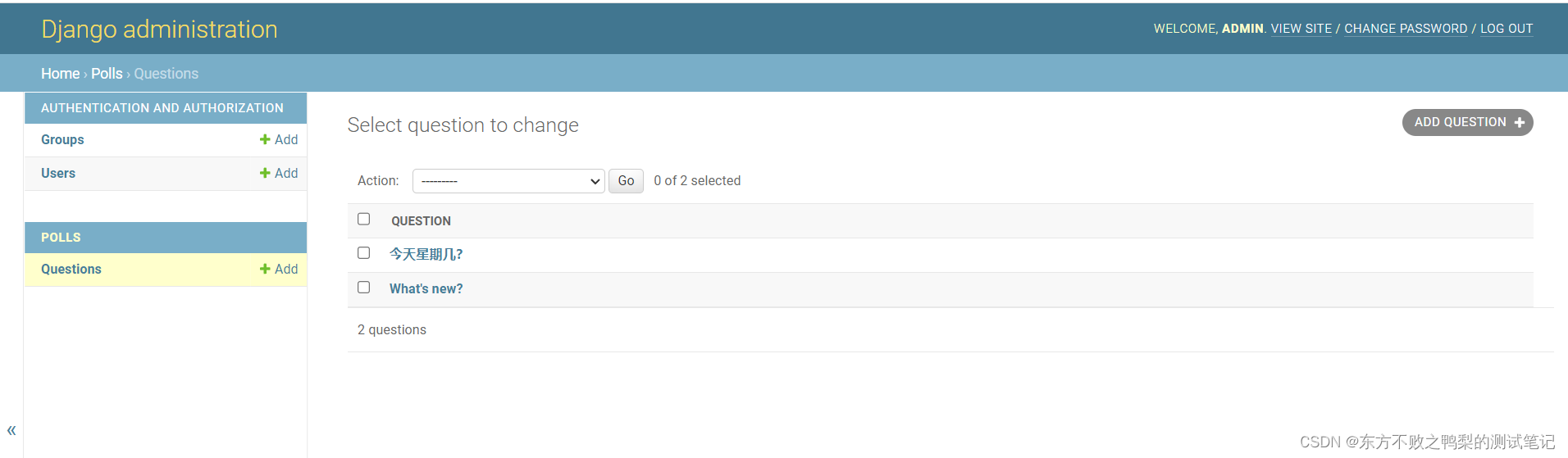
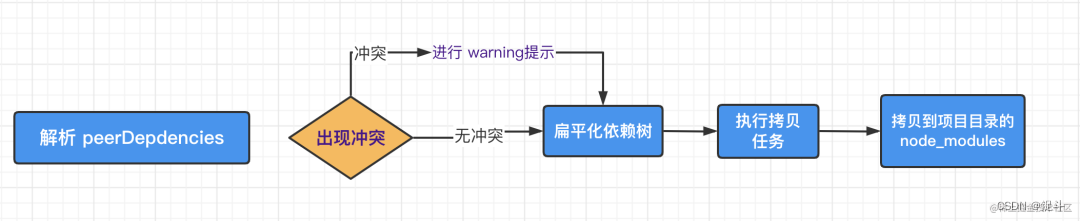
一、简述
图像分类模型能够预测与训练数据具有相同分布的数据。然而,在现实场景中,输入数据可能会发生变化。例如,当使用不同的相机进行推理时,照明条件、对比度、颜色失真等可能与训练集不同,并显着影响模型的性能。为了应对这一挑战,Hendrycks 等人提出了 AugMix 算法。可以应用于任何图像分类模型,以提高其鲁棒性和不确定性估计。
AugMix 是一种数据增强技术,可生成每个训练图像的增强变化。当与一致性损失相结合时,它会鼓励模型对同一图像的所有版本做出一致的预测。尽管使用这些增强的数据版本训练模型需要更长的时间,但生成的模型变得更加稳定、一致,并且能够抵抗各种输入。
训练图像的增强版本是通过应用由一到三个随机选择的增强操作(例如平移、剪切和对比度)组成的三个平行链来生成的,具有随机确定的强度。然后,将这些链与不同权重的原始图像组合起来,生成增强图像的单一版本。增强版本包含多个随机源,包括操作的选择、这些操作的强度、增强链的长度和混合权重。
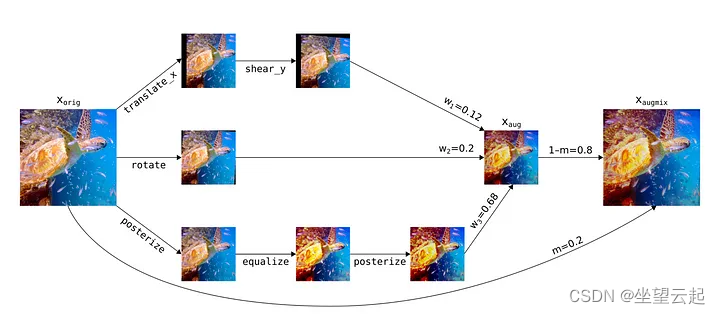
对于每个训练图像,AugMix 生成两个保留图像语义内容的增强版本(augmix1 和 augmix2)。
您可以在下图中查看图像及其增强版本的示例。
![[NLP]深入理解 Megatron-LM](https://img-blog.csdnimg.cn/5767492cc8b1460cb208630645dbe5f1.png)









![[论文阅读笔记25]A Comprehensive Survey on Graph Neural Networks](https://img-blog.csdnimg.cn/a60d7a56c9a444439815142a440d23f5.png)