文章目录
- 引言
- 1. 文本向量化
- 2. one-hot编码
- 3. 词向量-word2vec
- 3.1 词向量-基于语言模型
- 4 词向量 - word2vec基于窗口
- 4.1 词向量-如何训练
- 5. Huffman树
- 6. 负采样-negative sampling
- 7. Glove基于共现矩阵
- 7.1 Glove词向量
- 7.2 Glove对比word2vec
- 8. 词向量训练总结
- 9. 词向量应用
- 9.1词向量应用-寻找近义词
- 9.2 词向量应用-句向量或文本向量
- 9.3 词向量应用-KMeans
- 10. 词向量总结
引言
词向量和文本向量是自然语言处理(NLP)中用于表达文本数据的数学模型。
词向量:
- One-Hot 编码: 每个词都用一个很长的向量表示,向量的长度是词典的大小,其中只有一个元素是1,其他都是0。
- TF-IDF: 考虑词在文档中的频率和在整个语料库中的逆文档频率。
- Word2Vec: 通过神经网络模型来学习词的向量,使得语义上相近的词在向量空间中也相近。
- GloVe: 全局向量,基于共现矩阵和相关词的相对比例来生成词向量。
- FastText: 类似于Word2Vec,但考虑了词内字符的子结构。
文本向量:
- 词袋模型(BoW): 文本被表示为词的集合,不考虑词的顺序。
- TF-IDF: 文本中的每个词都由其TF-IDF值来表示。
- 段落向量(Doc2Vec): 相似于Word2Vec,但是整个文档有一个独立的向量。
- 平均词向量: 一个文本中所有词的词向量的平均值。
10.BERT, GPT: 使用预训练的语言模型,获取每个词或整个句子/段落的嵌入向量。 - RNN, LSTM, GRU: 对于序列文本,这些循环网络能够捕获文本中的时序信息,输出整个序列的表示。
词向量和文本向量广泛应用于文本分类、信息检索、情感分析、机器翻译等NLP任务。它们可以有效地捕捉文本的语义信息,并用于各种机器学习模型。
1. 文本向量化
- 对于机器来说,字符是没有含义的,只是有区别
- 只使用字符无法去刻画字与字、词与词、文本与文本之间的关系
- 文本转化为向量可以更好地刻画文本之间的关系
- 向量化后,可以启用大量的机器学习算法,具有很高的价值
- 文本是由词和字组成的,想将文本转化为向量,首先要能够把词和字转化为向量
- 所有向量应该有同一维度n,我们可以称这个n维空间是一个语义空间
我 [0.78029002 0.77010974 0.07479124 0.4106988 ]
爱 [0.14092194 0.63690971 0.73774712 0.42768218]
北京 [0.95780568 0.51903789 0.76615855 0.6399924 ]
天安门 [0.73861383 0.49694373 0.13213538 0.41237077]
2. one-hot编码
One-Hot编码是一种用于表示类别变量的方法,常用于自然语言处理和其他机器学习应用。在这种编码方案中,每个唯一的类别或词都由一个全为0的向量表示,除了一个位置为1。这个"1"的位置通常由词或类别在词汇表或类别列表中的索引决定。
例如,如果我们有一个词汇表:[‘苹果’, ‘香蕉’, ‘橙子’],对应的One-Hot编码可能如下:
‘苹果’:[1, 0, 0]
‘香蕉’:[0, 1, 0]
‘橙子’:[0, 0, 1]
One-Hot编码的优点是简单、有效,但也有缺点,比如它不能捕捉词之间的关系(例如,"苹果"和"香蕉"都是水果)。此外,当词汇表很大时,One-Hot编码会非常占用存储空间和计算资源,因为每个词都需要一个与词汇表大小相等的向量。
在对文本向量化时,也可以考虑词频
不错 [0, 0, 0, 1, 0]
不错 不错 [0, 0, 0, 2, 0]
有时也可以不事先准备词表,临时构建
如做文本比对任务,成对输入,此时维度可随时变化

one-hot编码-缺点
- 如果有很多词,编码向量维度会很高,而且向量十分稀疏(大部分位置都是零),计算负担很大(维度灾难)
- 编码向量不能反映字词之间的语义相似性,只能做到区分
3. 词向量-word2vec
Word2Vec是一种用于生成词向量的模型,由Google的研究人员Mikolov等人于2013年提出。与One-Hot编码不同,Word2Vec生成的是稠密的、低维度的向量,这些向量能够捕捉词与词之间的语义关系。
Word2Vec主要有两种架构:
- Skip-gram:给定一个词,预测其上下文。
- Continuous Bag of Words (CBOW):给定一个上下文,预测中间的词。
Word2Vec通过大量的文本数据进行训练,以捕捉词之间的共现关系,并将这些信息编码到低维向量中。这些向量有许多有趣的性质,例如相似的词会被映射到向量空间中相近的点。
例如,Word2Vec能够捕捉到类比关系,比如“国王 - 男人 + 女人 = 女王”。
Word2Vec的优点包括:
- 捕捉复杂的词关系。
- 向量维度相对较低,节省存储和计算资源。
缺点包括:
- 需要大量的数据进行训练。
- 不能很好地处理文本中的多义词。
我们希望得到一种词向量,使得向量关系能反映语义关系,比如:
cos(你好, 您好) > cos(你好,天气)
即词义的相似性反映在向量的相似性
国王 - 男人 = 皇后 -女人
即向量可以通过数值运算反映词之间的关系
同时,不管有多少词,向量维度应当是固定的
3.1 词向量-基于语言模型
基于语言模型的词向量生成方法与Word2Vec等词嵌入技术有本质区别。在这类方法中,词向量是作为预训练语言模型的副产品而生成的。这些模型包括长短时记忆(LSTM)、门控循环单元(GRU)或者更先进的架构如Transformer。
语言模型的主要任务是给定一个词序列,预测下一个词。这种预测是基于整个词序列的上下文信息。在训练过程中,模型学习到的词向量能够捕捉到丰富的语义和语法信息。
ELMo(Embeddings from Language Models)和BERT(Bidirectional Encoder Representations from Transformers)是两个典型的基于语言模型的词向量生成方法。
优点:
- 能捕捉更丰富、更复杂的语义信息,包括词义消歧。
- 由于是基于完整的上下文进行预测,所生成的词向量通常更为准确。
- 适用于各种NLP任务,包括但不限于文本分类、命名实体识别和问答系统。
缺点:
- 计算复杂度高,需要更多的计算资源。
- 由于模型架构的复杂性,需要有一定的专业知识来进行调优。
基于语言模型的词向量因其高度的灵活性和准确性在许多NLP应用中得到了广泛应用。
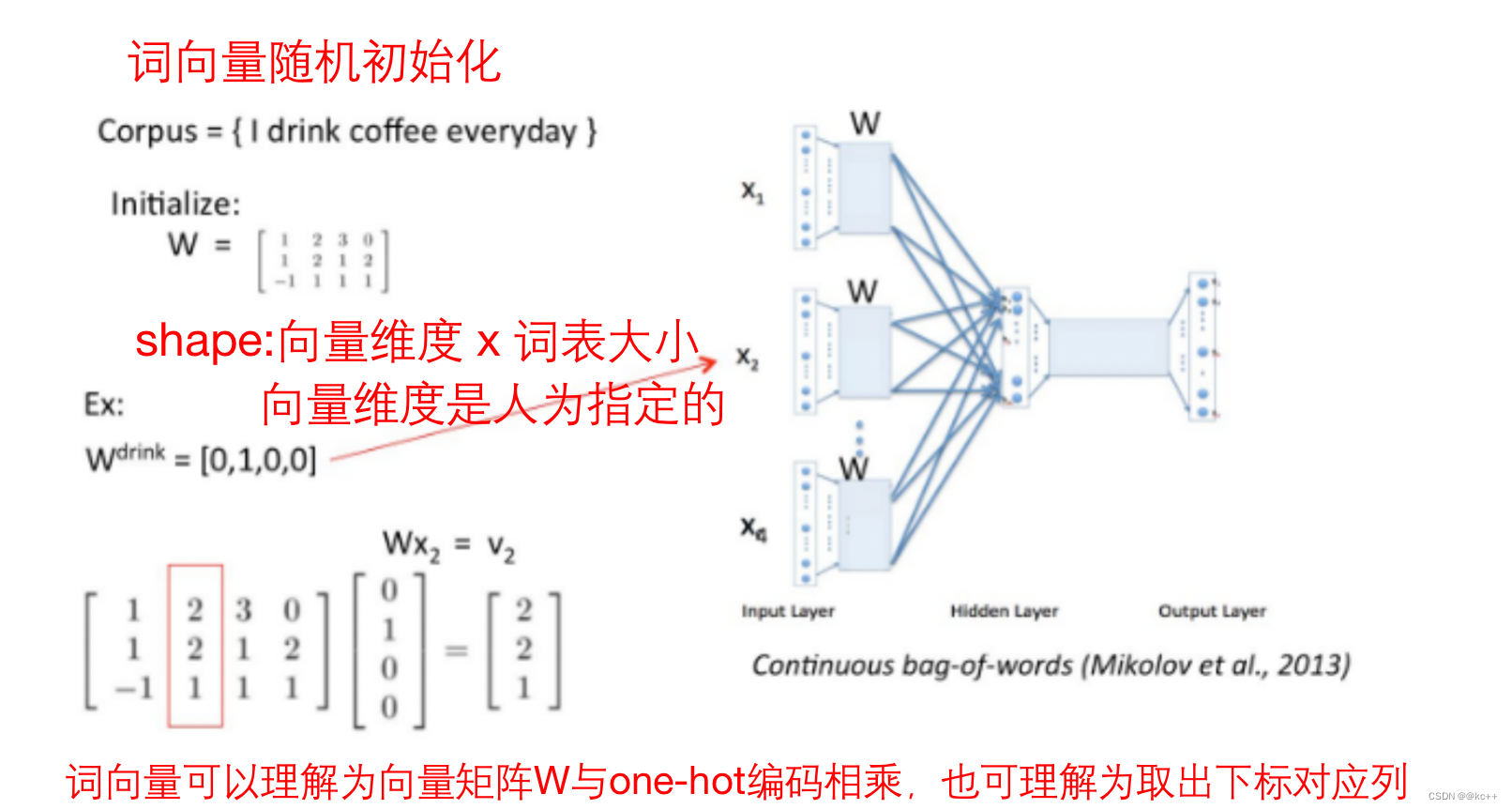
4 词向量 - word2vec基于窗口
4.1 词向量-如何训练
做出假设:
如果两个词在文本中出现时,它的前后出现的词相似,则这两个词语义相似。
如:

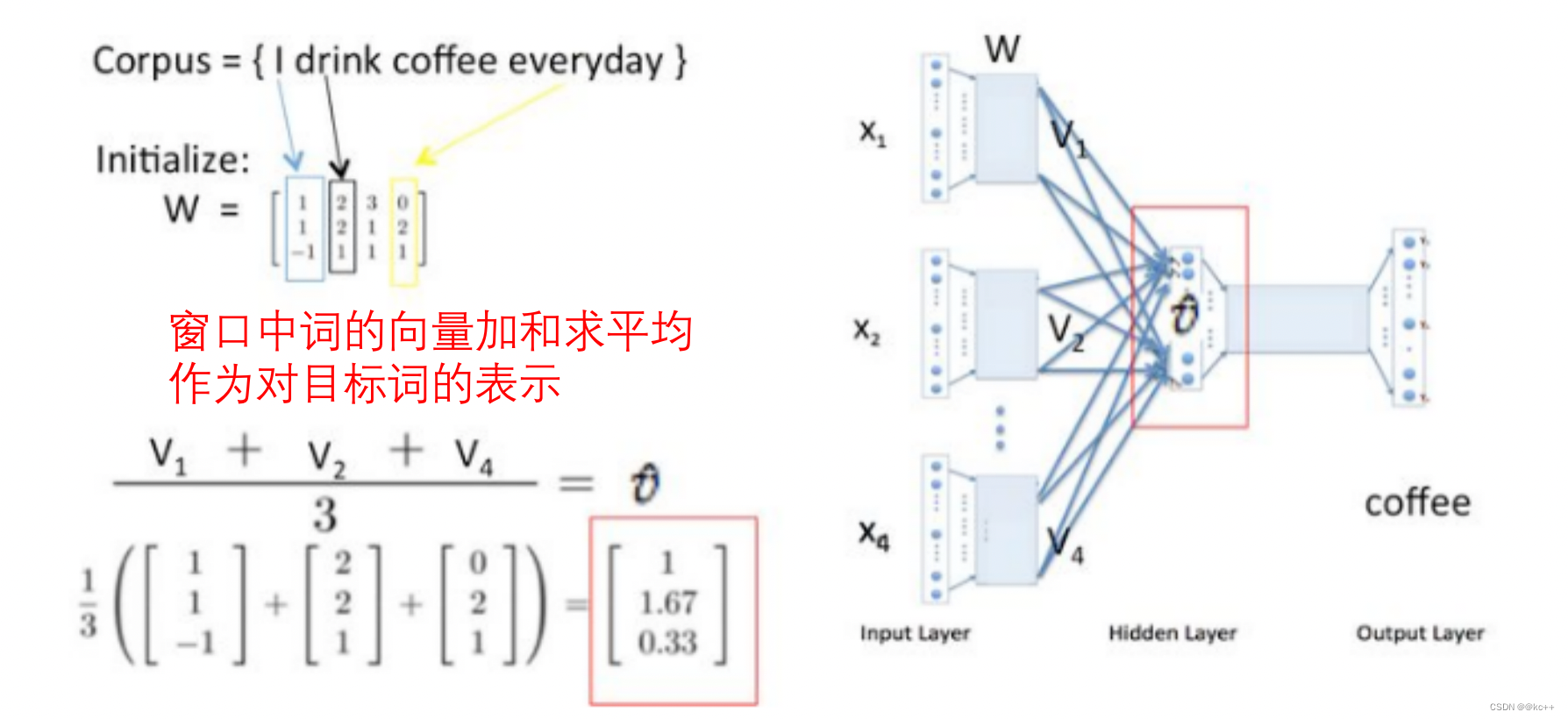
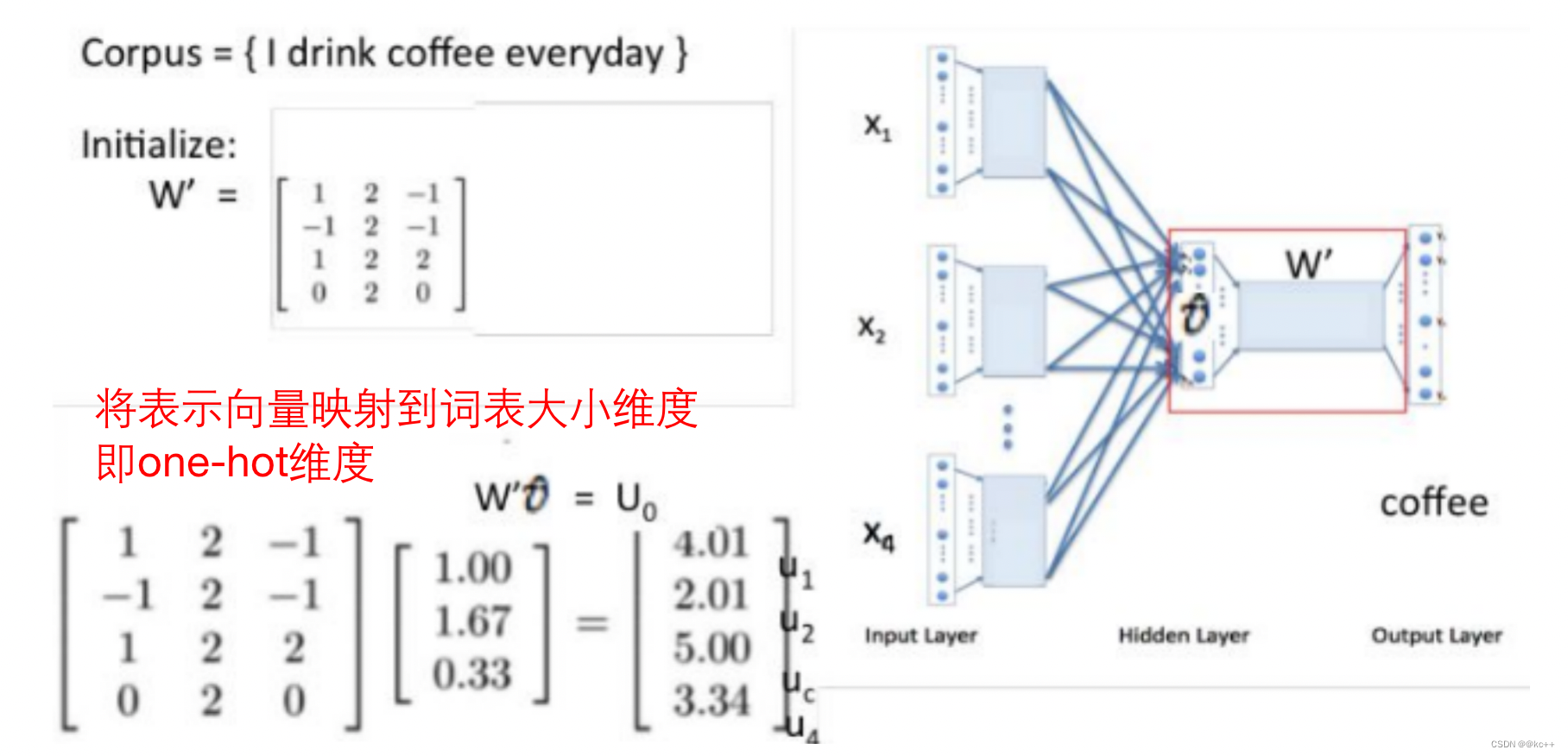
基于前述思想,我们尝试用窗口中的词(或者说周围词)来表示(预测)中间词
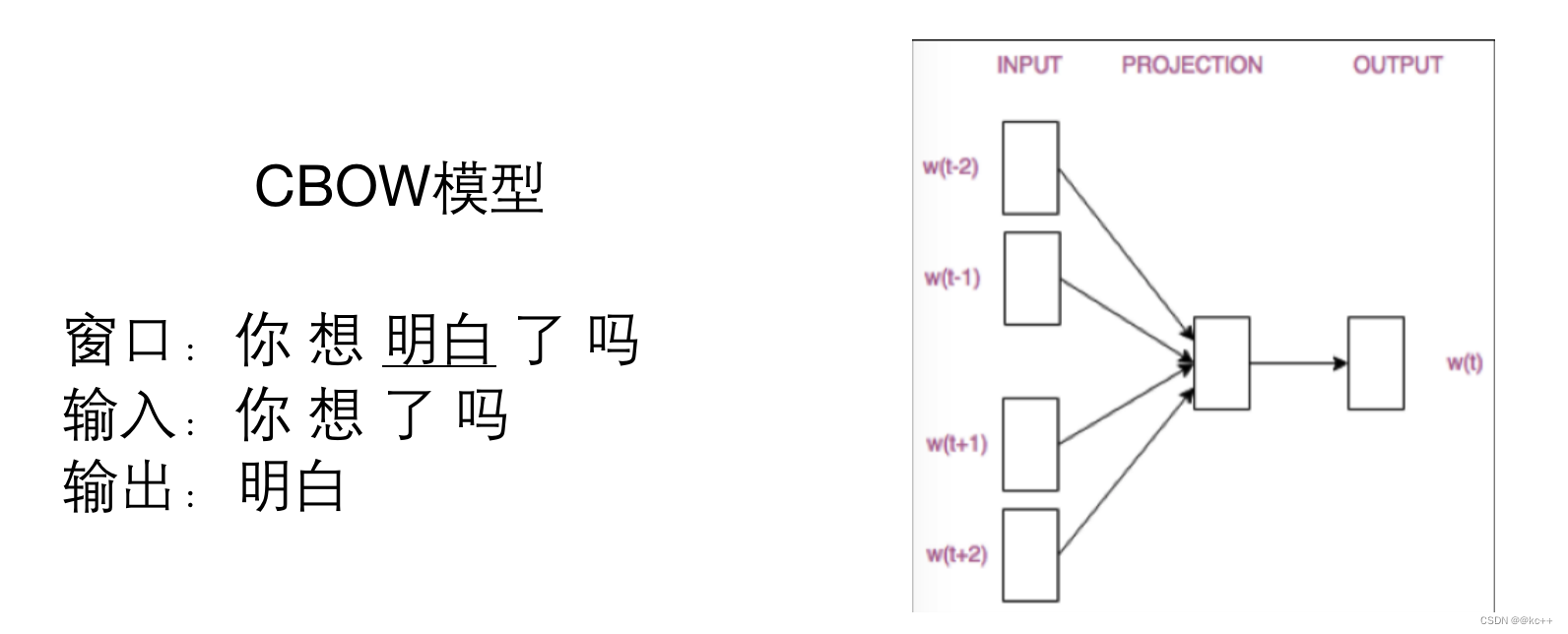
或用中间词来表示周围词
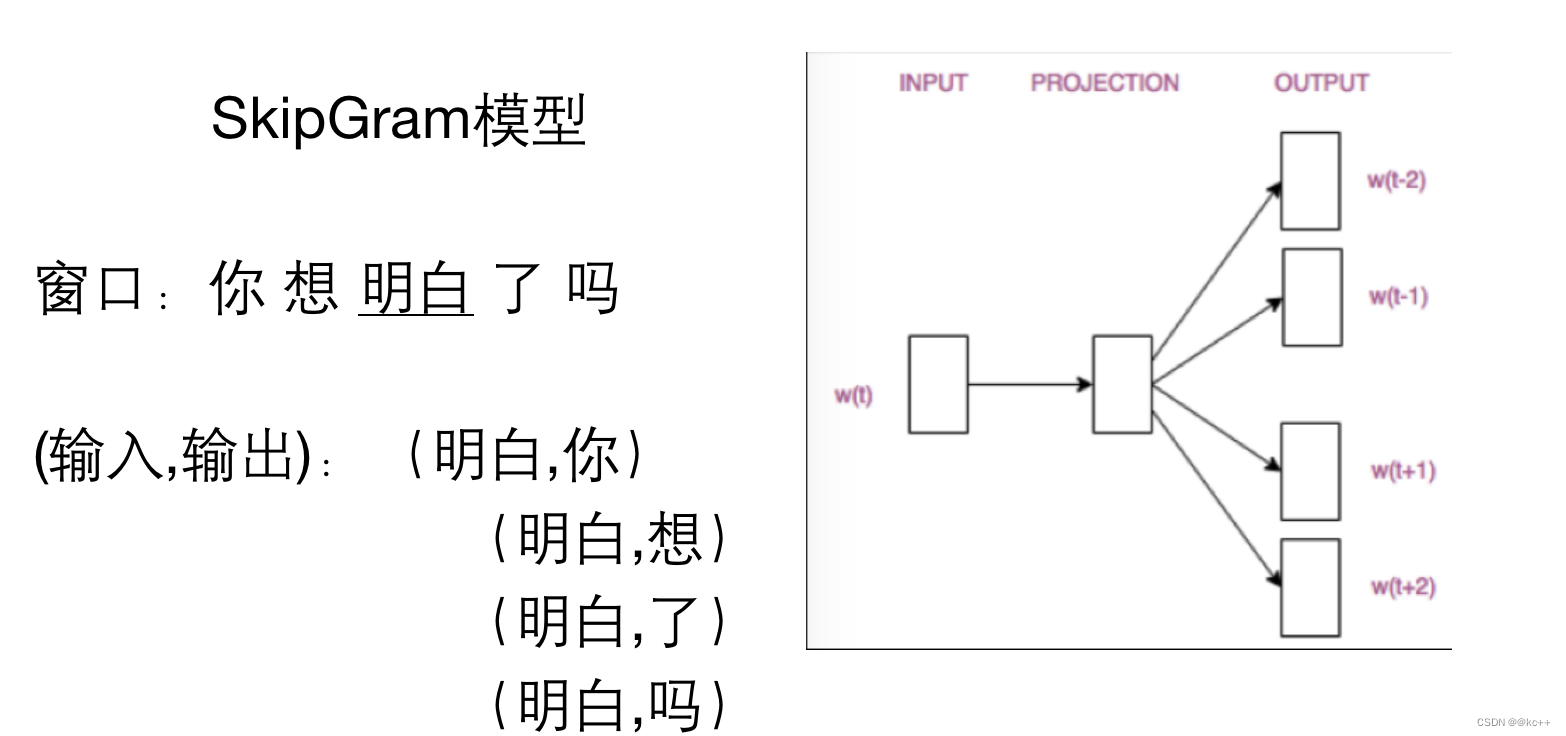
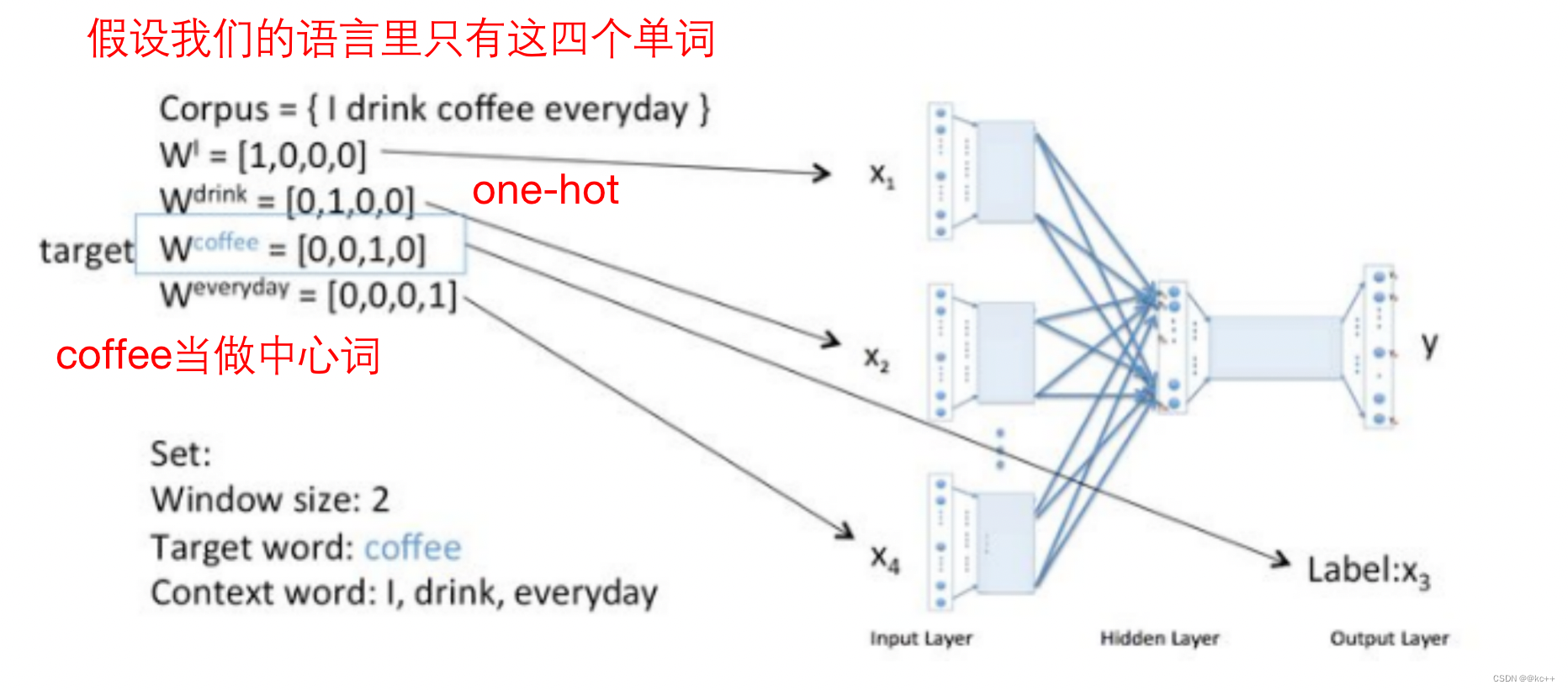
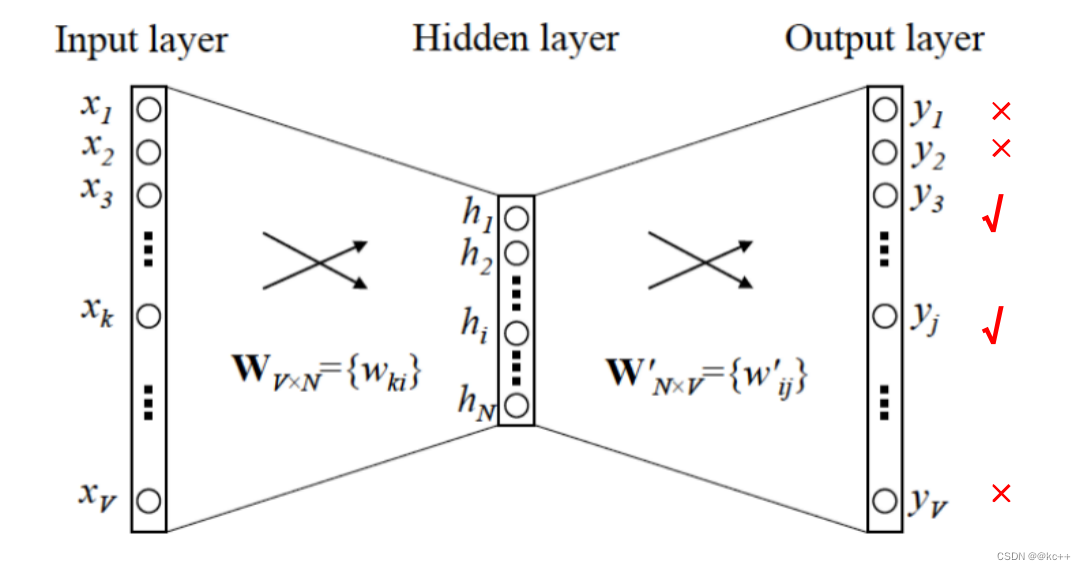
词向量-训练的问题
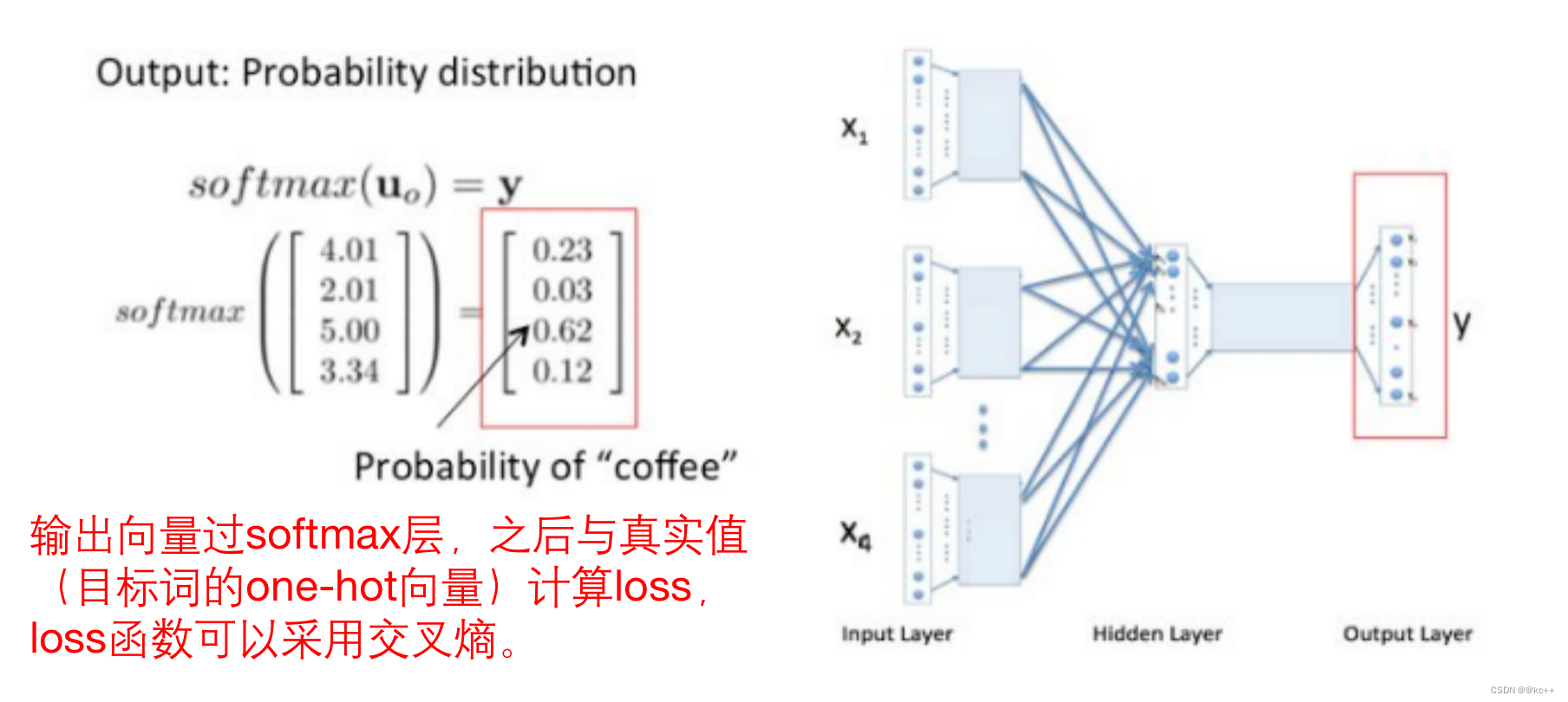
- 输出层使用one-hot向量会面临维度灾难,因为词表可能很大。
- 收敛速度缓慢
代码
cbow.py
#coding:utf8
import torch
import torch.nn as nn
import numpy as np
"""
基于pytorch的词向量CBOW
模型部分
"""
class CBOW(nn.Module):
def __init__(self, vocab_size, embedding_size, window_length):
super(CBOW, self).__init__()
self.word_vectors = nn.Embedding(vocab_size, embedding_size)
self.pooling = nn.AvgPool1d(window_length)
self.projection_layer = nn.Linear(embedding_size, vocab_size)
def forward(self, context):
context_embedding = self.word_vectors(context)
context_embedding = self.pooling(context_embedding.transpose(1, 2)).squeeze()
pred = self.projection_layer(context_embedding)
return pred
vocab_size = 8 #词表大小
embedding_size = 4 #人为指定的向量维度
window_length = 4 #窗口长度
model = CBOW(vocab_size, embedding_size, window_length)
#假如选取一个词窗口【1,2,3,4,5】·
context = torch.LongTensor([[1,2,4,5]])
pred = model(context) #训练目标是输出3
print("预测值:", pred)
print("词向量矩阵")
print(model.state_dict()["word_vectors.weight"])
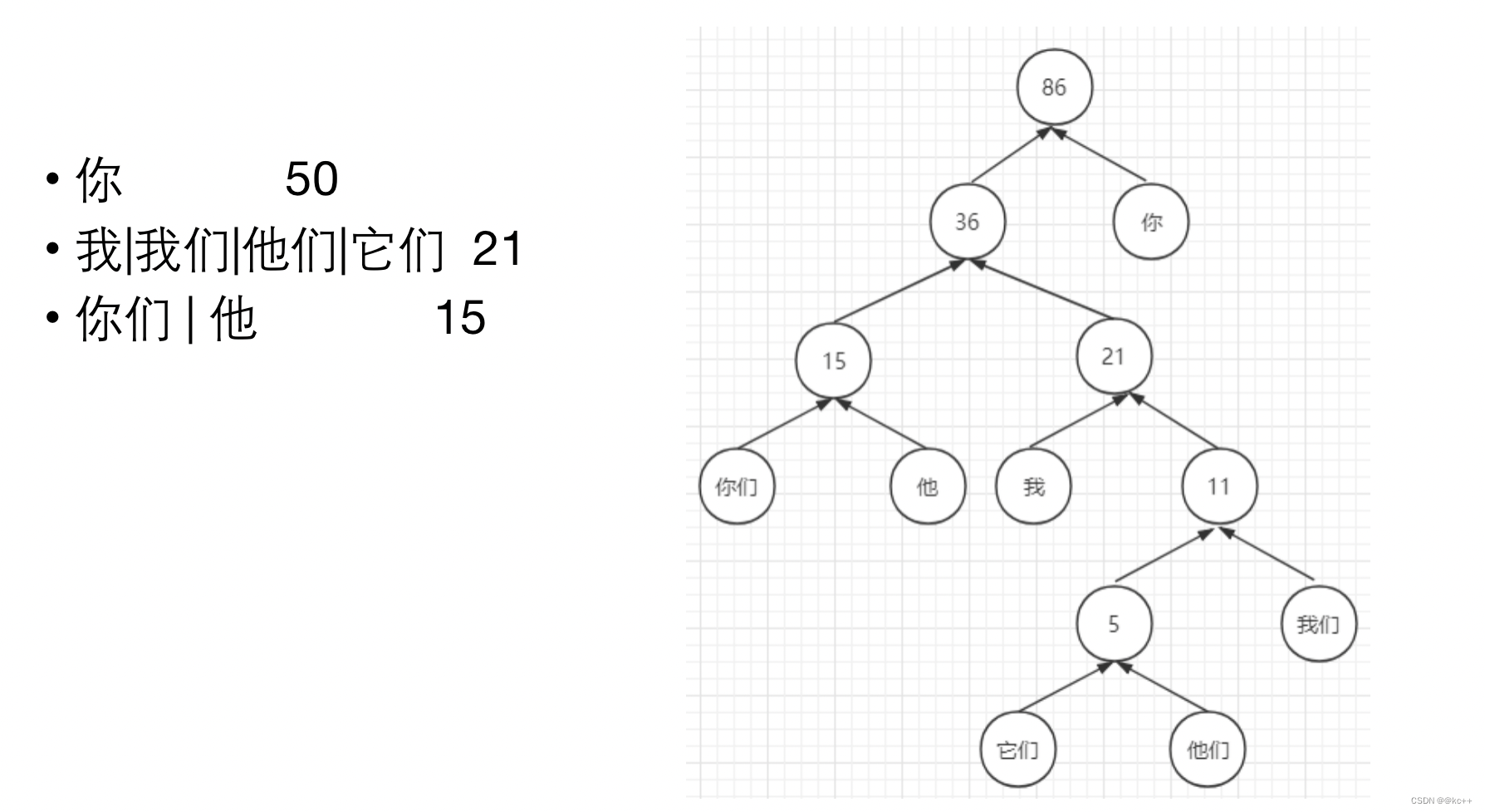
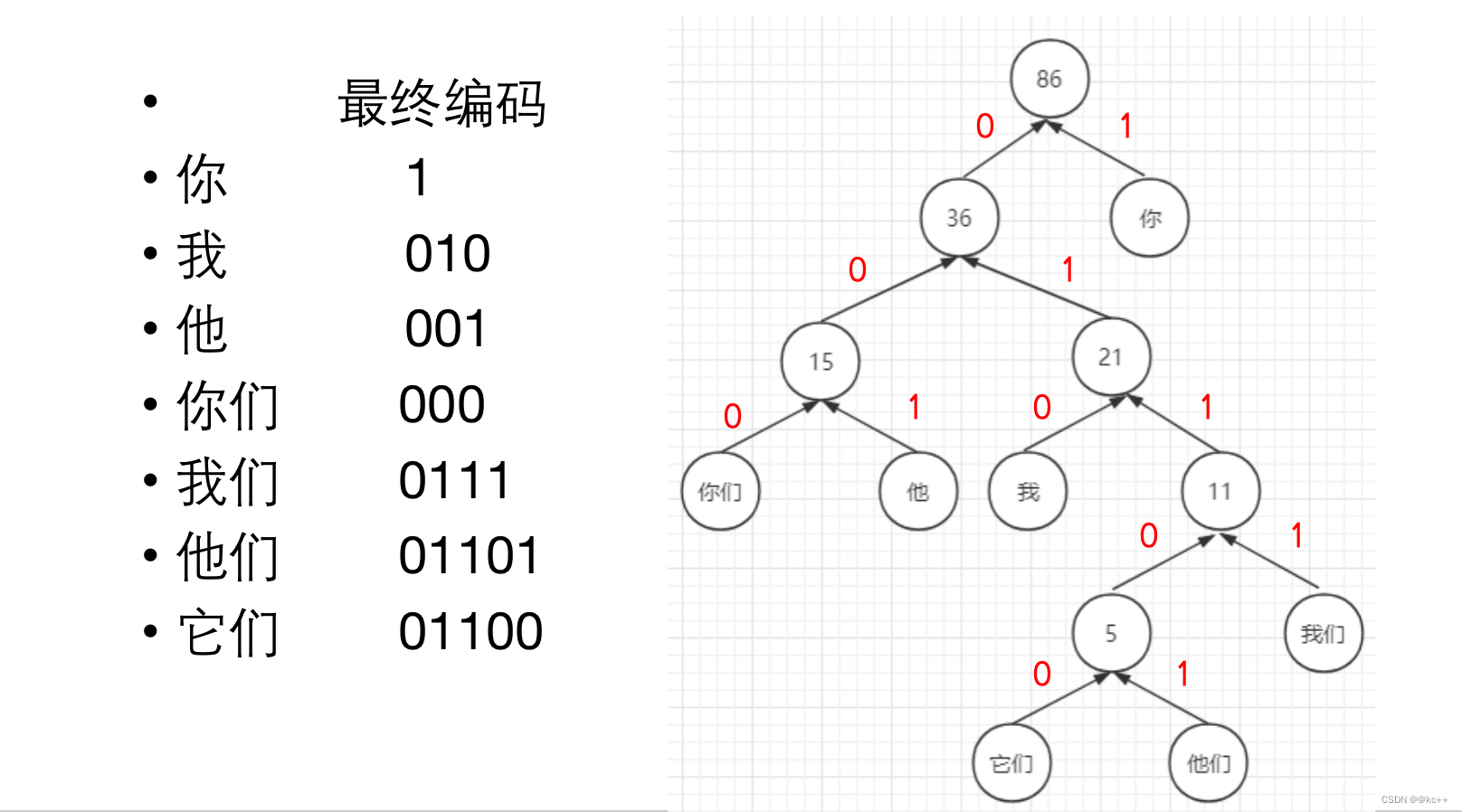
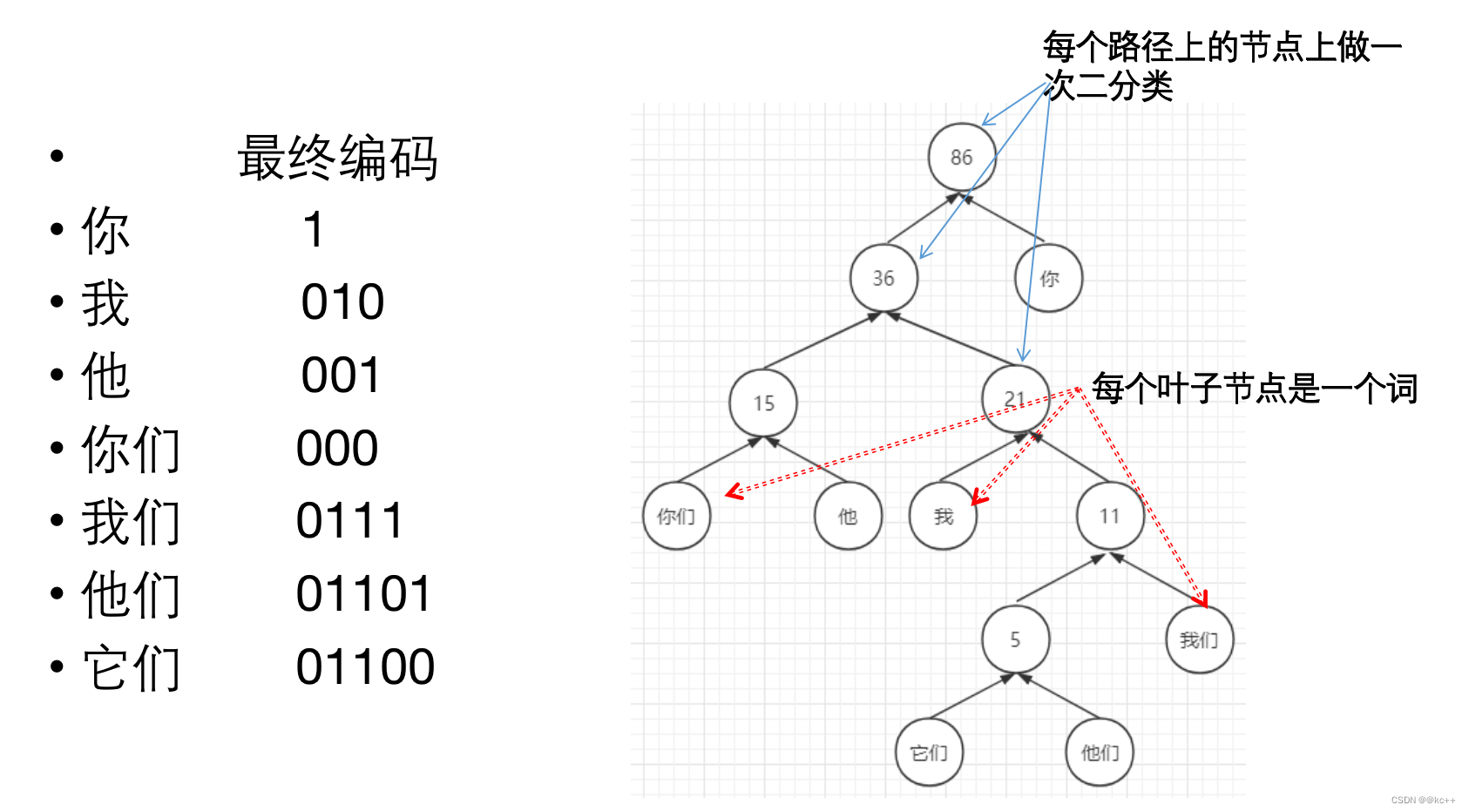
5. Huffman树
对所有词进行二进制编码,使其符合以下特点
- 不同词编码不同
- 每个词的编码不会成为另一个词编码的前缀,即如果某个词编码为011,则不能有词的编码是0111或0110或011001等
- 构造出的词编码总体长度最小,且越高频词编码越短

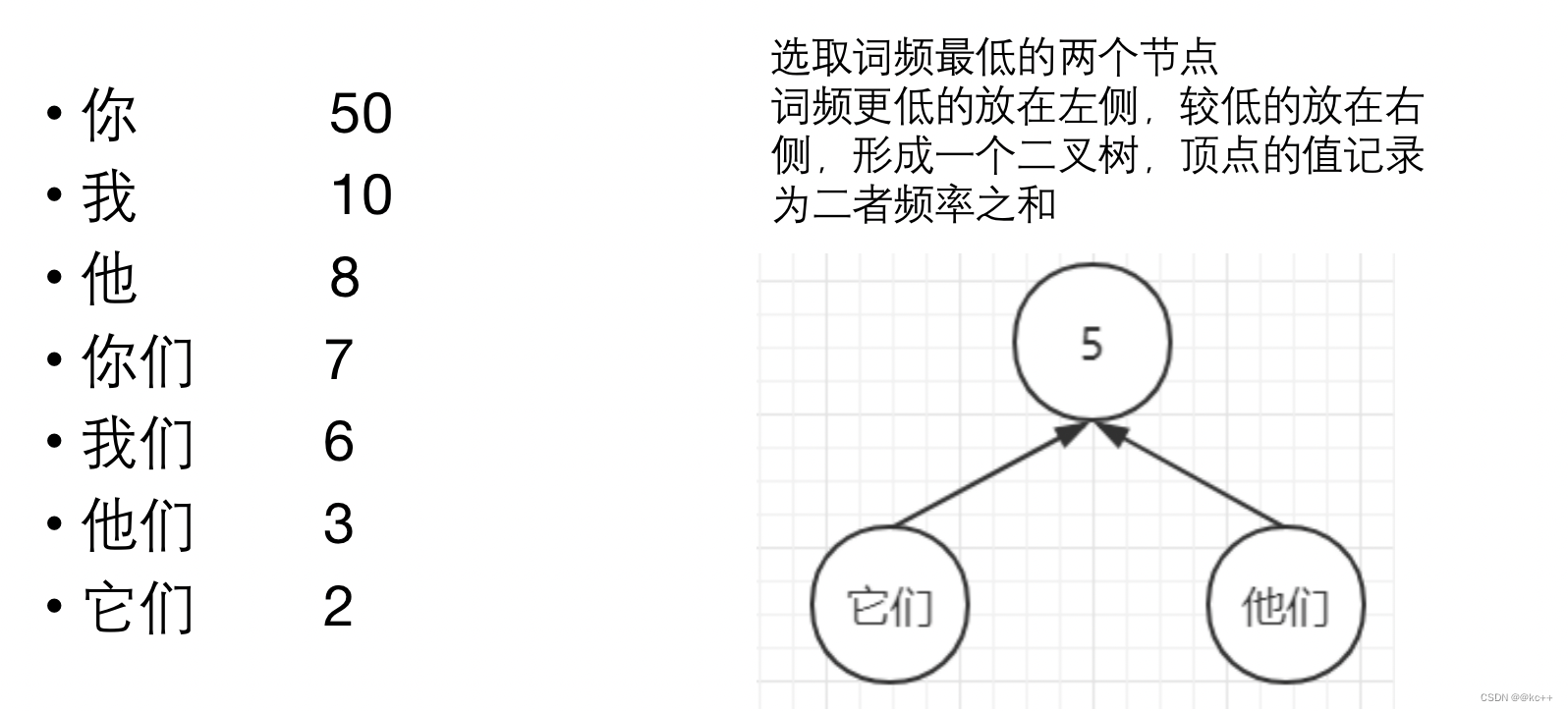
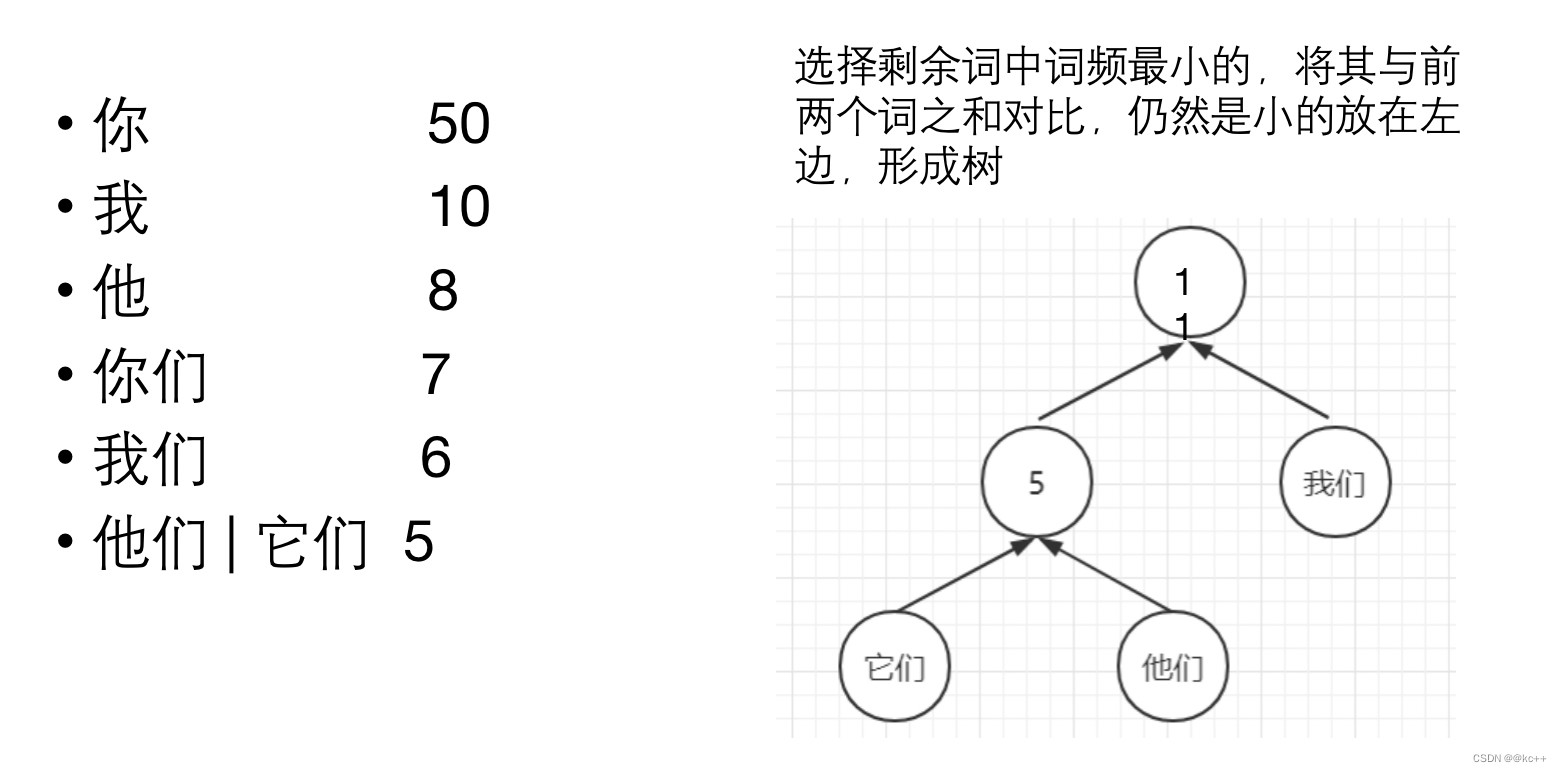
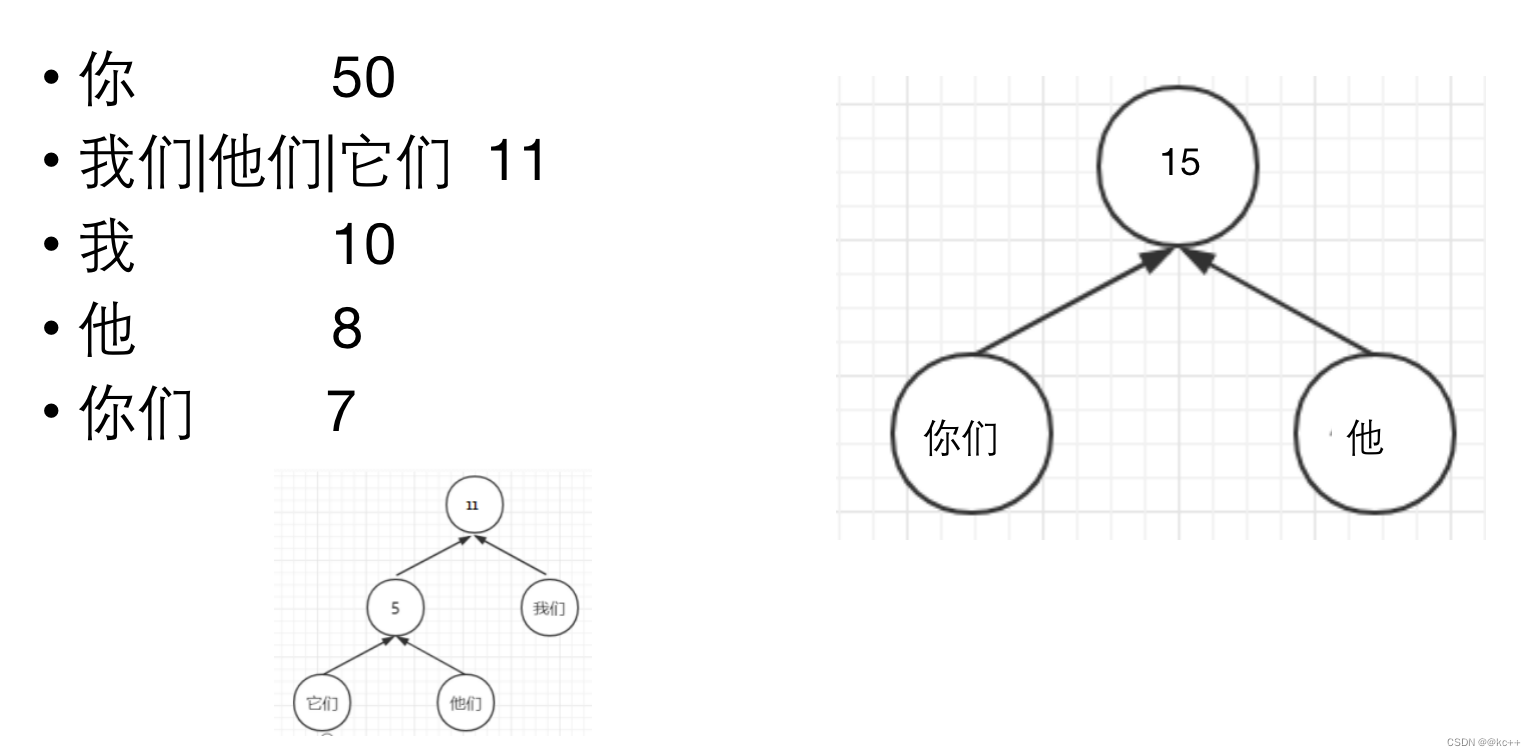
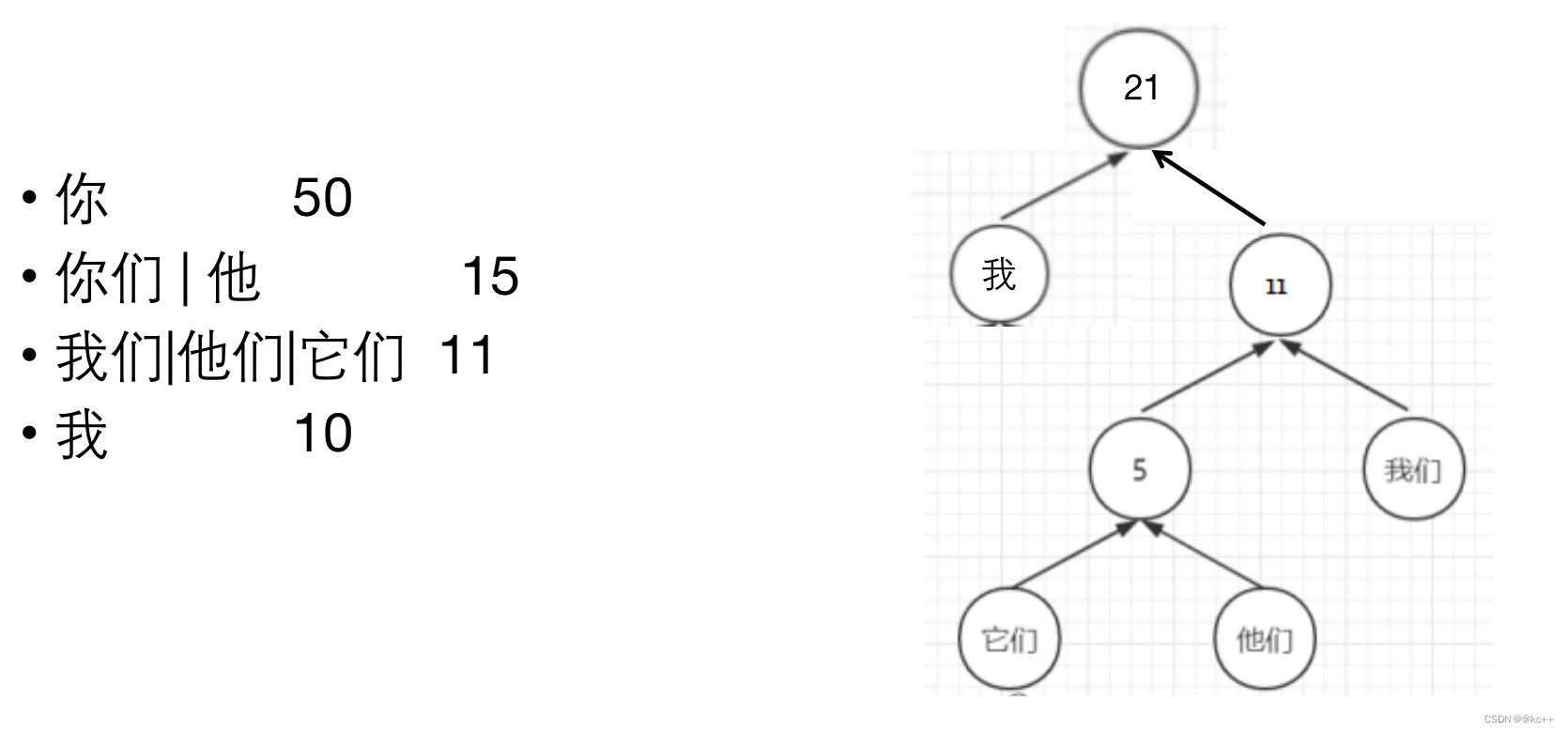

代码
"""
构建霍夫曼树
"""
class HuffmanNode:
def __init__(self, word_id, frequency):
self.word_id = word_id # 叶子结点存词对应的id, 中间节点存中间节点id
self.frequency = frequency # 存单词频次
self.left_child = None
self.right_child = None
self.father = None
self.Huffman_code = [] # 霍夫曼码(左1右0)
self.path = [] # 根到叶子节点的中间节点id
class HuffmanTree:
def __init__(self, wordid_frequency_dict):
self.word_count = len(wordid_frequency_dict) # 单词数量
self.wordid_code = dict()
self.wordid_path = dict()
self.root = None
unmerge_node_list = [HuffmanNode(wordid, frequency) for wordid, frequency in
wordid_frequency_dict.items()] # 未合并节点list
self.huffman = [HuffmanNode(wordid, frequency) for wordid, frequency in
wordid_frequency_dict.items()] # 存储所有的叶子节点和中间节点
# 构建huffman tree
self.build_tree(unmerge_node_list)
# 生成huffman code
self.generate_huffman_code_and_path()
def merge_node(self, node1, node2):
sum_frequency = node1.frequency + node2.frequency
mid_node_id = len(self.huffman) # 中间节点的value存中间节点id
father_node = HuffmanNode(mid_node_id, sum_frequency)
if node1.frequency >= node2.frequency:
father_node.left_child = node1
father_node.right_child = node2
else:
father_node.left_child = node2
father_node.right_child = node1
self.huffman.append(father_node)
return father_node
def build_tree(self, node_list):
while len(node_list) > 1:
i1 = 0 # 概率最小的节点
i2 = 1 # 概率第二小的节点
if node_list[i2].frequency < node_list[i1].frequency:
[i1, i2] = [i2, i1]
for i in range(2, len(node_list)):
if node_list[i].frequency < node_list[i2].frequency:
i2 = i
if node_list[i2].frequency < node_list[i1].frequency:
[i1, i2] = [i2, i1]
father_node = self.merge_node(node_list[i1], node_list[i2]) # 合并最小的两个节点
if i1 < i2:
node_list.pop(i2)
node_list.pop(i1)
elif i1 > i2:
node_list.pop(i1)
node_list.pop(i2)
else:
raise RuntimeError('i1 should not be equal to i2')
node_list.insert(0, father_node) # 插入新节点
self.root = node_list[0]
def generate_huffman_code_and_path(self):
stack = [self.root]
while len(stack) > 0:
node = stack.pop()
# 顺着左子树走
while node.left_child or node.right_child:
code = node.Huffman_code
path = node.path
node.left_child.Huffman_code = code + [1]
node.right_child.Huffman_code = code + [0]
node.left_child.path = path + [node.word_id]
node.right_child.path = path + [node.word_id]
# 把没走过的右子树加入栈
stack.append(node.right_child)
node = node.left_child
word_id = node.word_id
word_code = node.Huffman_code
word_path = node.path
self.huffman[word_id].Huffman_code = word_code
self.huffman[word_id].path = word_path
# 把节点计算得到的霍夫曼码、路径 写入词典的数值中
self.wordid_code[word_id] = word_code
self.wordid_path[word_id] = word_path
# 获取所有词的正向节点id和负向节点id数组
def get_all_pos_and_neg_path(self):
positive = [] # 所有词的正向路径数组
negative = [] # 所有词的负向路径数组
for word_id in range(self.word_count):
pos_id = [] # 存放一个词 路径中的正向节点id
neg_id = [] # 存放一个词 路径中的负向节点id
for i, code in enumerate(self.huffman[word_id].Huffman_code):
if code == 1:
pos_id.append(self.huffman[word_id].path[i])
else:
neg_id.append(self.huffman[word_id].path[i])
positive.append(pos_id)
negative.append(neg_id)
return positive, negative
def main():
words = "你 我 他 你们 我们 他们 它们"
freqs = "50 10 8 7 6 3 2"
word_to_id = dict((word, i) for i, word in enumerate(words.split()))
print(word_to_id)
word_frequency = dict((word_to_id[x], int(y)) for x, y in zip(words.split(), freqs.split()))
tree = HuffmanTree(word_frequency)
word_code = dict((word, tree.wordid_code[word_to_id[word]]) for word in words.split())
print(word_code)
if __name__ == '__main__':
main()
6. 负采样-negative sampling
词向量训练最终采取softmax作为激活函数,得到预测词的分布
于一个数组V
如果V中元素很多,则该计算非常耗时
反向传播时,所有权重一起更新非常耗时
替代方案
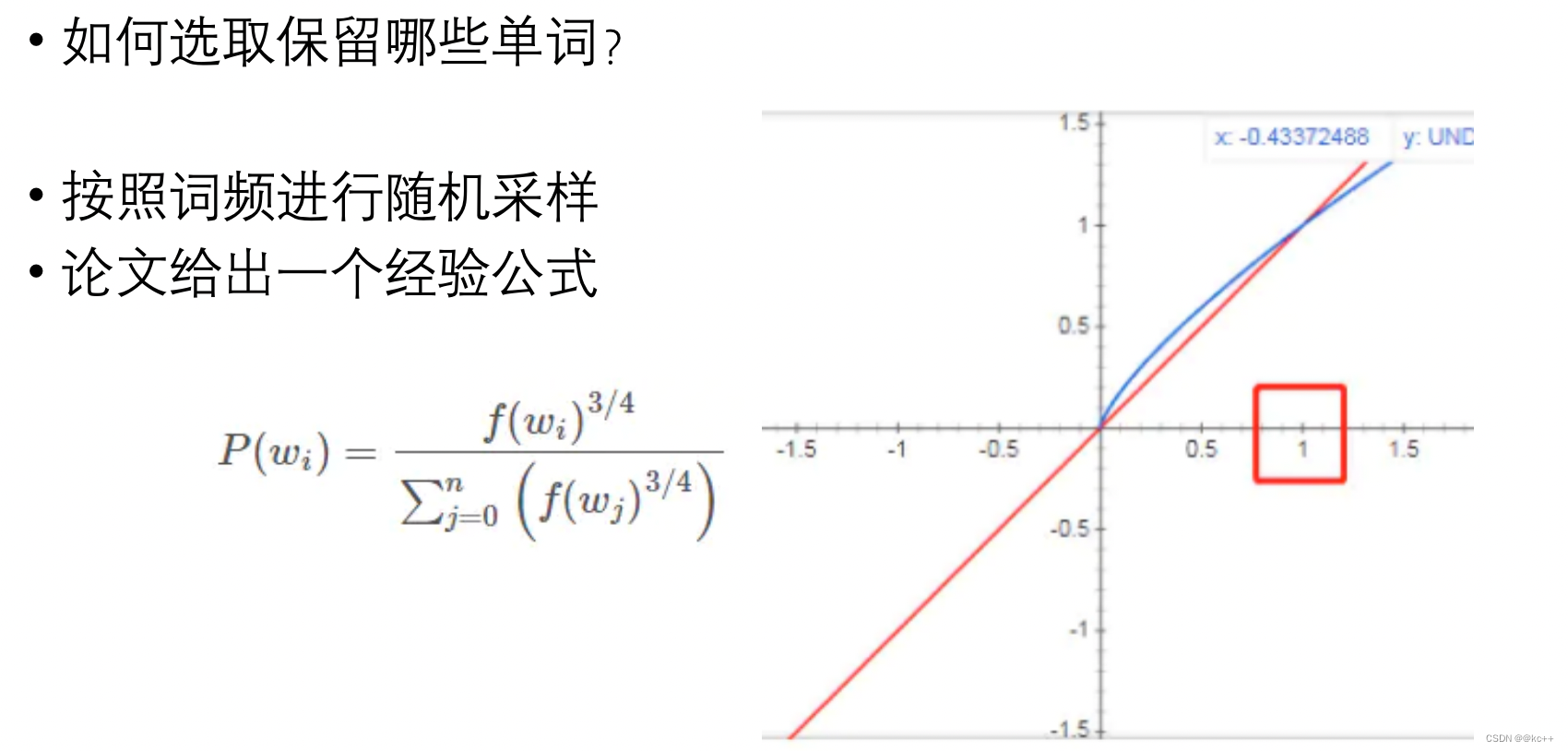
不再计算所有词的概率,只挑选某些词计算其概率
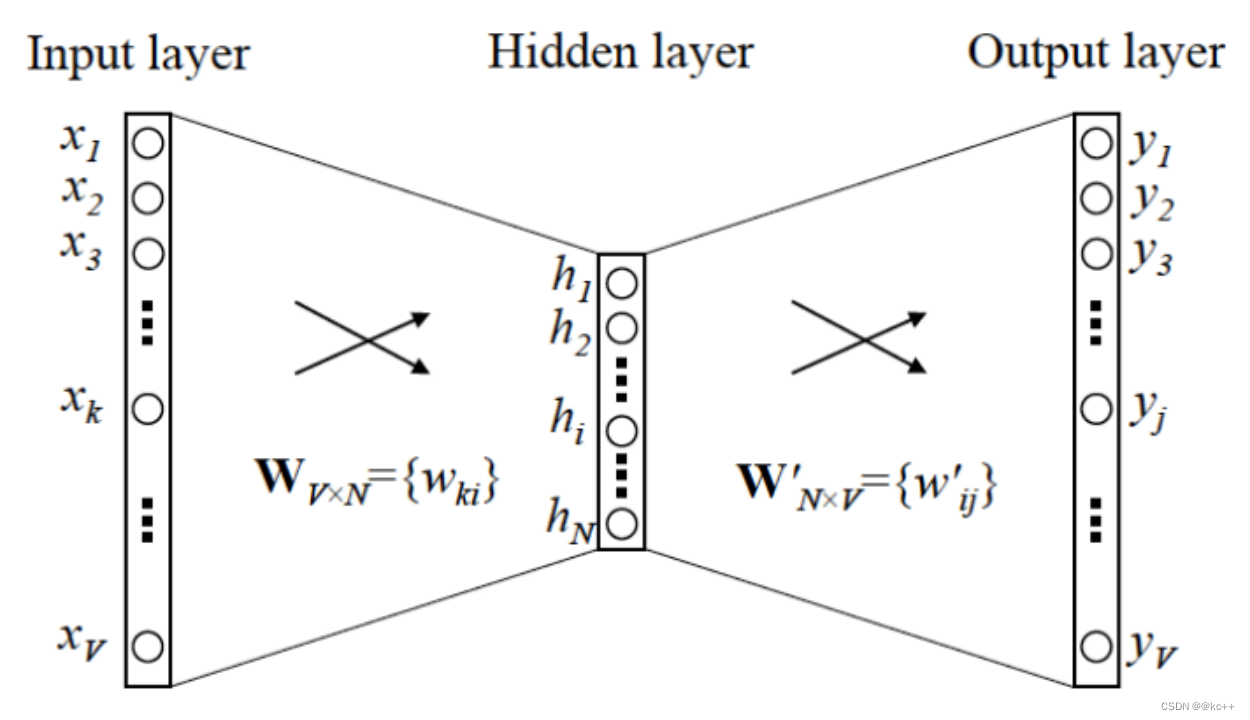
使用sigmoid函数逐个计算概率,代替softmax
只更新选择的部分词的权重矩阵
7. Glove基于共现矩阵
7.1 Glove词向量
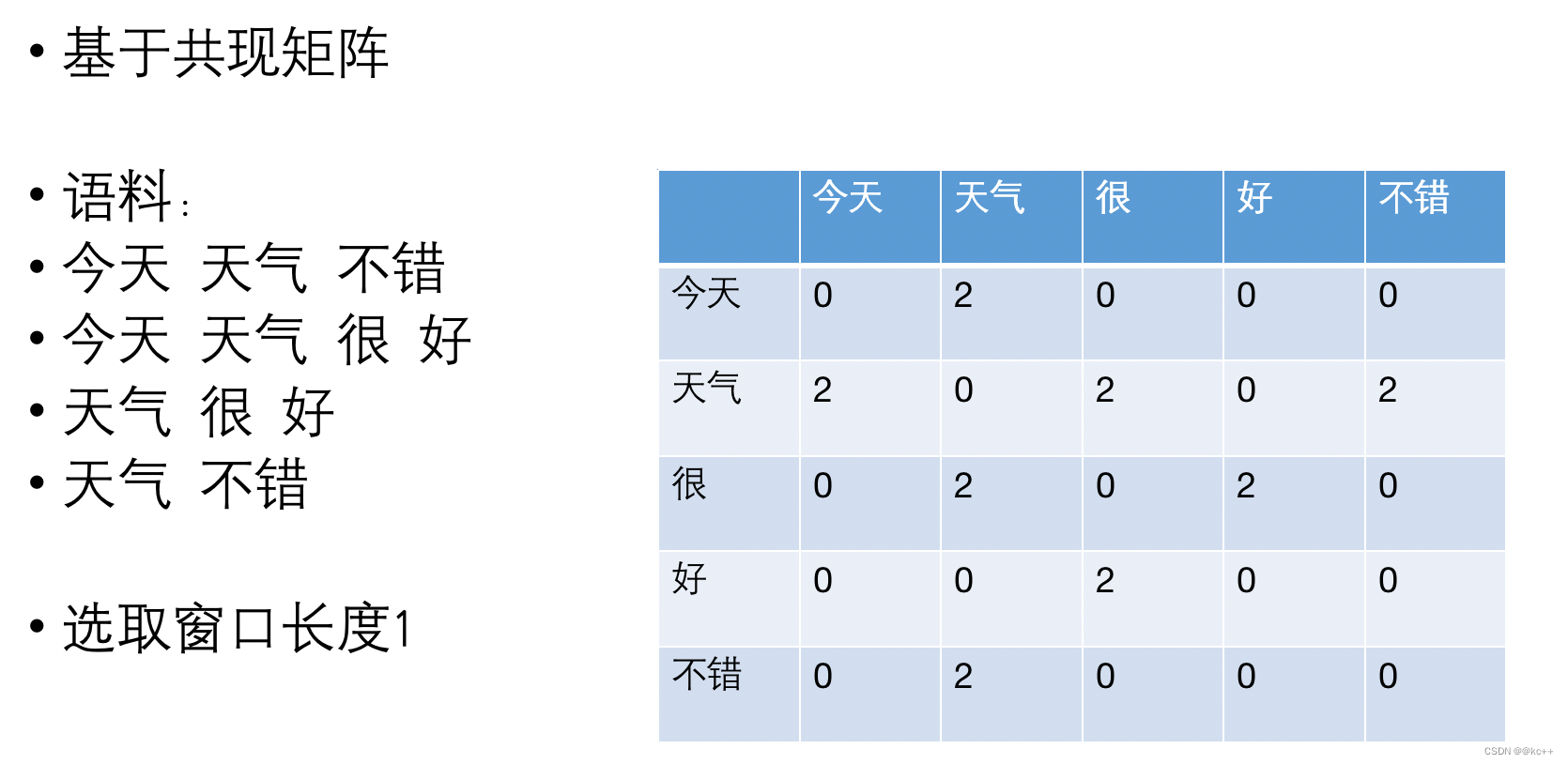
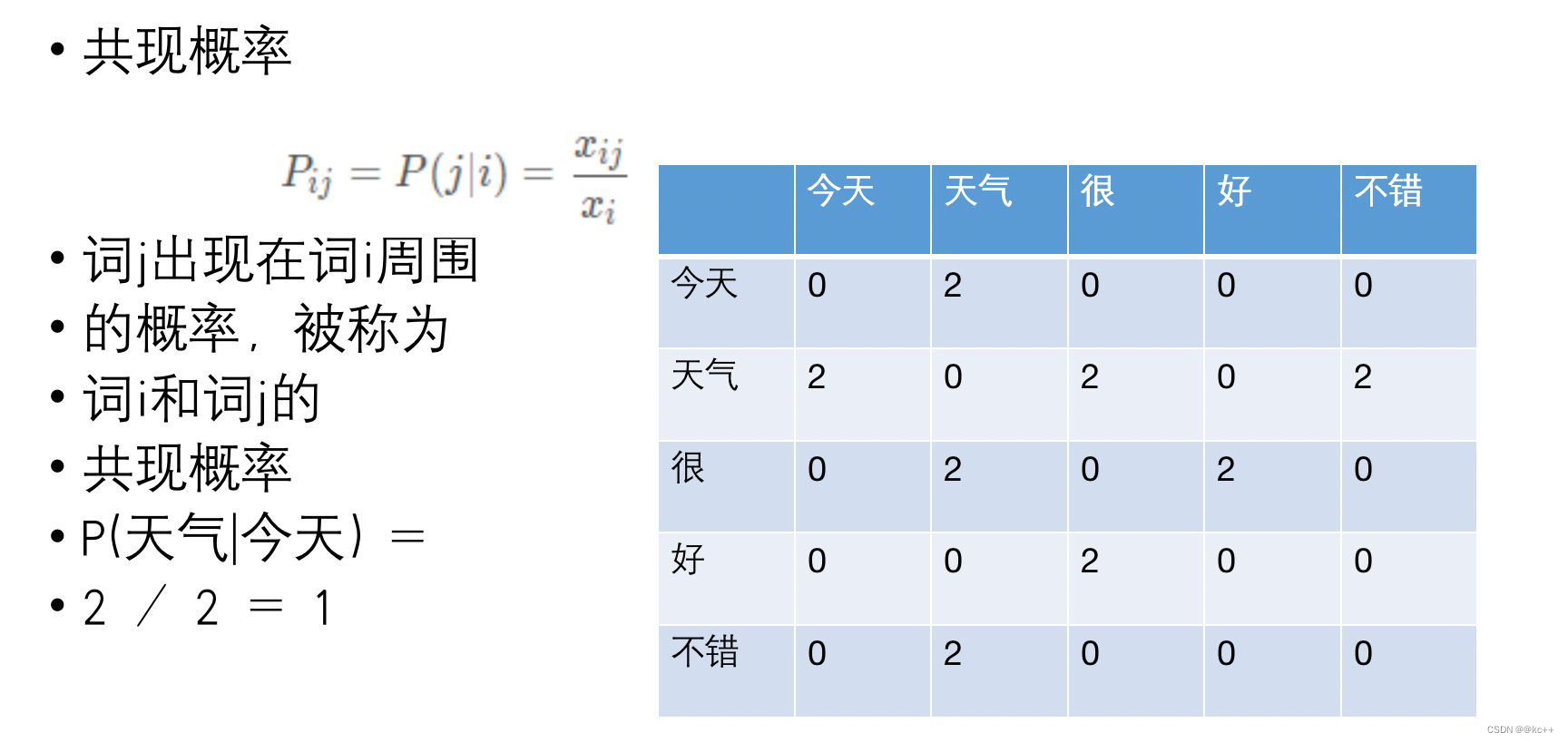
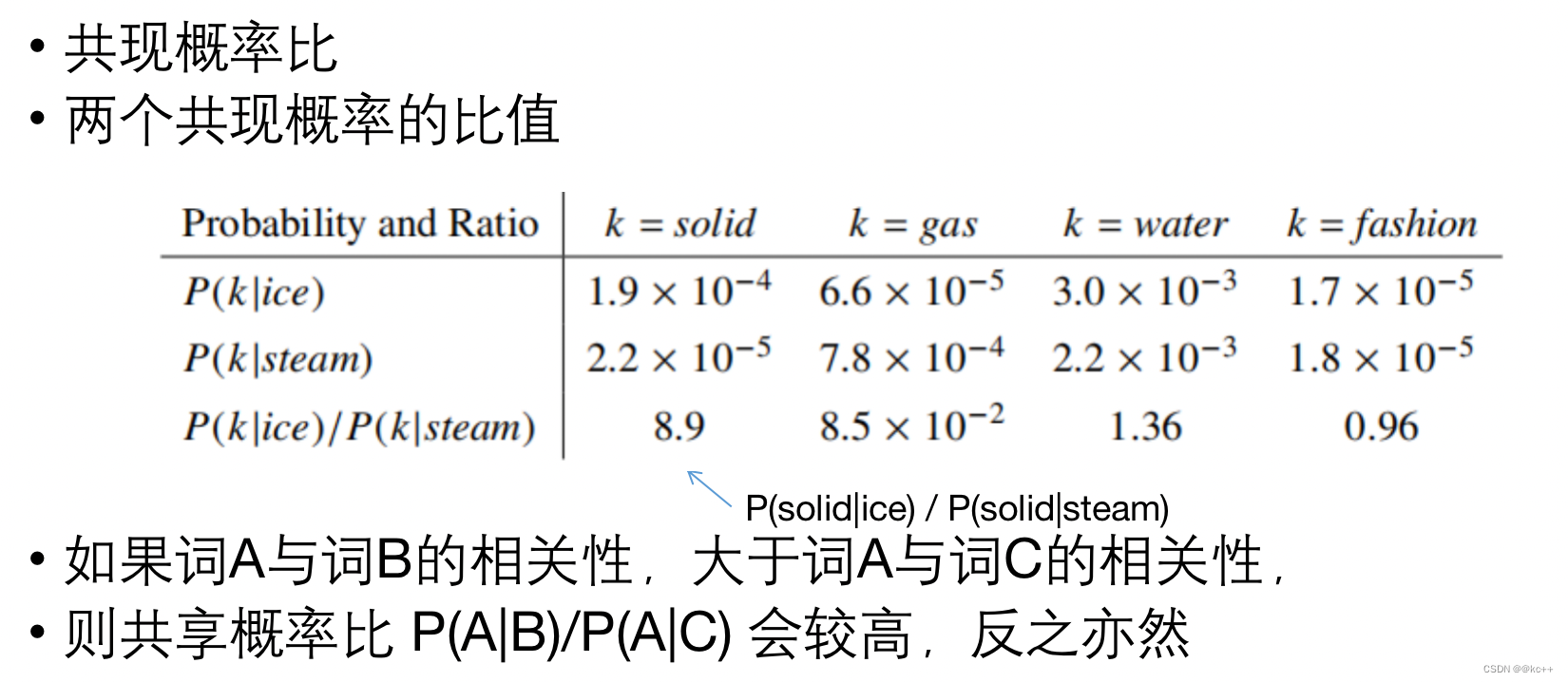
- 问题转化:
- 给定三个词的词向量,Va, Vb, Vc三者的通过某个函数映射后,其比值应接近ABC的共现概率比
- 即目标为找到向量使得 f(Va, Vb, Vc) = P(A|B)/P(A|C)
- 预测数值,属于回归问题, 损失函数使用均方差
- f的设计论文中给出的是f(Va, Vb, Vc) = (Va - Vb )·Vc
7.2 Glove对比word2vec
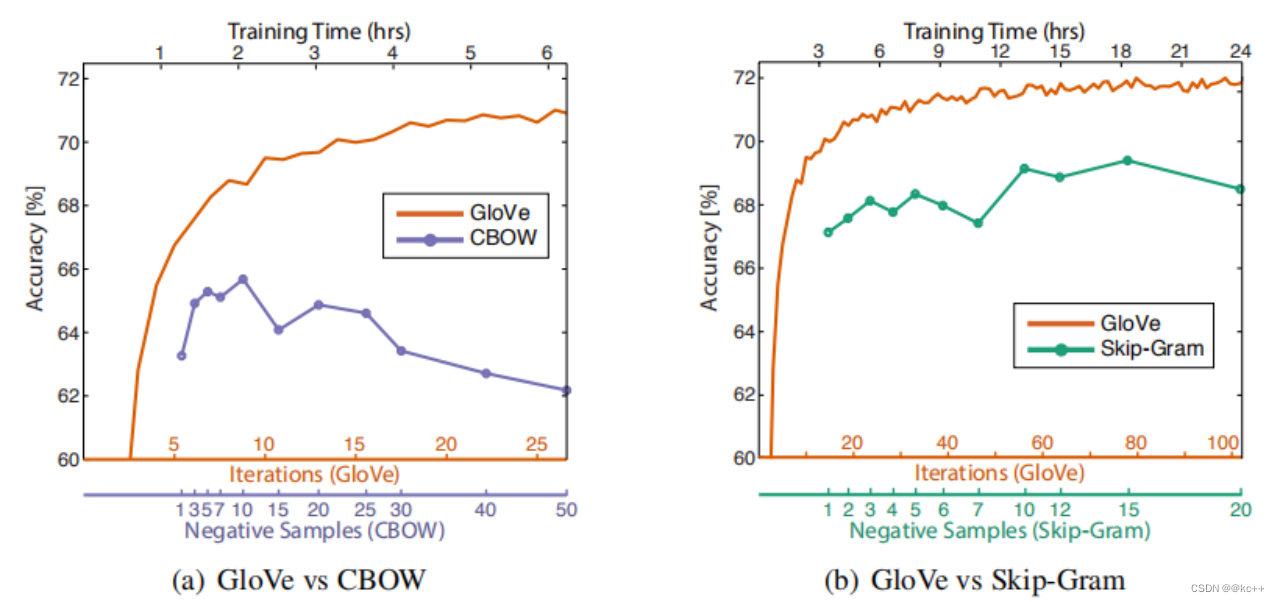
Glove通过共现矩阵,让模型看到了整个文本的信息,而word2vec模型一直在看某个窗口
8. 词向量训练总结
- 根据词与词之间关系的某种假设,制定训练目标
- 设计模型,以词向量为输入
- 随机初始化词向量,开始训练
- 训练过程中词向量作为参数不断调整,获取一定的语义信息
- 使用训练好的词向量做下游任务
词向量存在的问题:
- 词向量是“静态”的。每个词使用固定向量,没有考虑前后文
- 一词多义的情况。西瓜 - 苹果 - 华为
- 影响效果的因素非常多
维度选择、随机初始化、skip-gram/cbow/glove、分词质量、词频截断、未登录词、窗口大小、迭代轮数、停止条件、语料质量等 - 没有好的直接评价指标。常需要用下游任务来评价
9. 词向量应用
9.1词向量应用-寻找近义词

9.2 词向量应用-句向量或文本向量
- 将一句话或一段文本分成若干个词
- 找到每个词对应的词向量
- 所有词向量加和求平均或通过各种网络模型,得到文本向量
- 使用文本向量计算相似度或进行聚类等
9.3 词向量应用-KMeans
- 随机选择k个点作为初始质心
- repeat
- 将每个点指派到最近的质心,形成k个簇
- 重新计算每个簇的质心
- until
- 质心不发生变化
代码
kmeans.py
import numpy as np
import random
import sys
'''
Kmeans算法实现
原文链接:https://blog.csdn.net/qingchedeyongqi/article/details/116806277
'''
class KMeansClusterer: # k均值聚类
def __init__(self, ndarray, cluster_num):
self.ndarray = ndarray
self.cluster_num = cluster_num
self.points = self.__pick_start_point(ndarray, cluster_num)
def cluster(self):
result = []
for i in range(self.cluster_num):
result.append([])
for item in self.ndarray:
distance_min = sys.maxsize
index = -1
for i in range(len(self.points)):
distance = self.__distance(item, self.points[i])
if distance < distance_min:
distance_min = distance
index = i
result[index] = result[index] + [item.tolist()]
new_center = []
for item in result:
new_center.append(self.__center(item).tolist())
# 中心点未改变,说明达到稳态,结束递归
if (self.points == new_center).all():
sum = self.__sumdis(result)
return result, self.points, sum
self.points = np.array(new_center)
return self.cluster()
def __sumdis(self,result):
#计算总距离和
sum=0
for i in range(len(self.points)):
for j in range(len(result[i])):
sum+=self.__distance(result[i][j],self.points[i])
return sum
def __center(self, list):
# 计算每一列的平均值
return np.array(list).mean(axis=0)
def __distance(self, p1, p2):
#计算两点间距
tmp = 0
for i in range(len(p1)):
tmp += pow(p1[i] - p2[i], 2)
return pow(tmp, 0.5)
def __pick_start_point(self, ndarray, cluster_num):
if cluster_num < 0 or cluster_num > ndarray.shape[0]:
raise Exception("簇数设置有误")
# 取点的下标
indexes = random.sample(np.arange(0, ndarray.shape[0], step=1).tolist(), cluster_num)
points = []
for index in indexes:
points.append(ndarray[index].tolist())
return np.array(points)
x = np.random.rand(100, 8)
kmeans = KMeansClusterer(x, 10)
result, centers, distances = kmeans.cluster()
print(result)
print(centers)
print(distances)
word2vec_kmeans.py
#!/usr/bin/env python3
#coding: utf-8
#基于训练好的词向量模型进行聚类
#聚类采用Kmeans算法
import math
import re
import json
import jieba
import numpy as np
from gensim.models import Word2Vec
from sklearn.cluster import KMeans
from collections import defaultdict
#输入模型文件路径
#加载训练好的模型
def load_word2vec_model(path):
model = Word2Vec.load(path)
return model
def load_sentence(path):
sentences = set()
with open(path, encoding="utf8") as f:
for line in f:
sentence = line.strip()
sentences.add(" ".join(jieba.cut(sentence)))
print("获取句子数量:", len(sentences))
return sentences
#将文本向量化
def sentences_to_vectors(sentences, model):
vectors = []
for sentence in sentences:
words = sentence.split() #sentence是分好词的,空格分开
vector = np.zeros(model.vector_size)
#所有词的向量相加求平均,作为句子向量
for word in words:
try:
vector += model.wv[word]
except KeyError:
#部分词在训练中未出现,用全0向量代替
vector += np.zeros(model.vector_size)
vectors.append(vector / len(words))
return np.array(vectors)
def main():
model = load_word2vec_model("model.w2v") #加载词向量模型
sentences = load_sentence("titles.txt") #加载所有标题
vectors = sentences_to_vectors(sentences, model) #将所有标题向量化
n_clusters = int(math.sqrt(len(sentences))) #指定聚类数量
print("指定聚类数量:", n_clusters)
kmeans = KMeans(n_clusters) #定义一个kmeans计算类
kmeans.fit(vectors) #进行聚类计算
sentence_label_dict = defaultdict(list)
for sentence, label in zip(sentences, kmeans.labels_): #取出句子和标签
sentence_label_dict[label].append(sentence) #同标签的放到一起
for label, sentences in sentence_label_dict.items():
print("cluster %s :" % label)
for i in range(min(10, len(sentences))): #随便打印几个,太多了看不过来
print(sentences[i].replace(" ", ""))
print("---------")
if __name__ == "__main__":
main()
KMeans优点:
- 速度很快,可以支持很大量的数据
- 样本均匀特征明显的情况下,效果不错
KMeans缺点:
人为设定聚类数量
初始化中心影响效果,导致结果不稳定
对于个别特殊样本敏感,会大幅影响聚类中心位置
不适合多分类或样本较为离散的数据
KMeans一些使用技巧:
- 先设定较多的聚类类别
- 聚类结束后计算类内平均距离
- 排序后,舍弃类内较低的类别
- 计算距离时可以尝试欧式距离、余弦距离或其他距离
- 短文本的聚类记得先去重,以及其他预处理
10. 词向量总结
- 质变:将离散的字符转化为连续的数值
- 通过向量的相似度代表语义的相似度
- 词向量的训练基于很多不完全正确的假设,但是据此训练的词向量是有意义的
- 使用无标注的文本的一种好方法