1 intro
- 时间序列领域预训练模型/foundation 模型的研究还不是很多
- 主要挑战是缺乏大量的数据来训练用于时间序列分析的基础模型
- ——>论文利用预训练的语言模型进行通用的时间序列分析
- 为各种时间序列任务提供了一个统一的框架

- 论文还调查了为什么从语言领域预训练的Transformer几乎不需要任何改动就可以适应时间序列分析
- —预训练Transformer中的自注意模块通过训练获得了执行某些非数据相关操作的能力
- 这些操作与输入模式上的主成分分析(PCA)密切相关
2 模型
2.1 模型架构

- 利用自然语言处理预训练的Transformer的参数进行时间序列分析
- 重点关注GPT-2模型
- 还尝试了其他模型,如BERT和BEiT,以进一步证明跨领域知识传递的通用性存在于广泛的预训练模型中
2.1.1 冻结的预训练块
- 由于自注意层和前馈神经网络(FFN)包含了来自预训练语言模型的大部分学习知识,因此我们选择在微调时冻结他们
2.1.2 位置嵌入和层归
- 为了以最小的努力增强下游任务,我们微调了位置嵌入和layer normalization层
- layer normalization 计算均值和方差也是用神经网络计算的,所以也需要微调
- 机器学习笔记:神经网络层的各种normalization_relu 和 batchnorm的神经元数目一样吗_UQI-LIUWJ的博客-CSDN博客
2.1.3 输入embedding
- 重新设计和训练输入嵌入层,以将NLP预训练模型应用于各种任务和新的模态
- 将时间序列数据投影到特定预训练模型所需的维度
- 使用linear probing
2.1.4 归一化
- 数据归一化对于各种模态的预训练模型至关重要
- 除了预训练LM中使用的Layer Normalization外,还加入了一个简单的数据归一化块,即反向实例归一化(reverse instance norm)
- 简单地使用均值和方差对输入时间序列进行归一化,然后将它们添加回输出中
2.1.5 patching
- 为了提取局部语义信息,论文利用分块(Patching)
- 通过聚合相邻的时间步骤来形成一个基于Patch的Token
- 在normalization 后进行patching
4 实验
4.1 主要结论
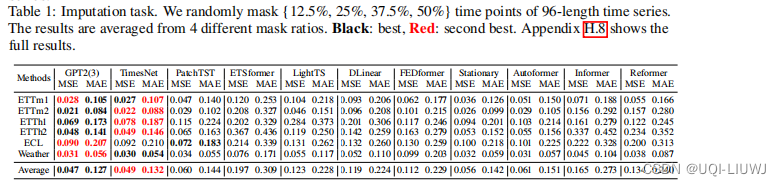
4.2 补全

4.3 分类

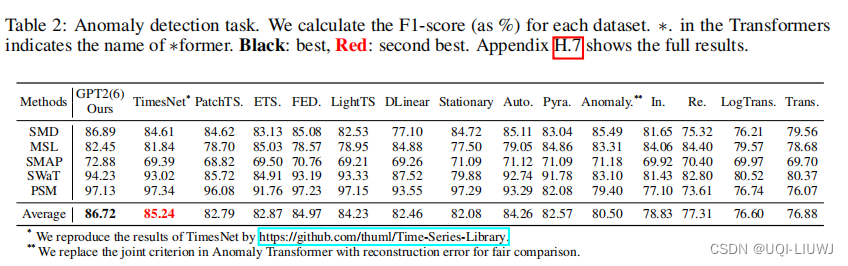
4.4 异常检测
4.5 长期预测

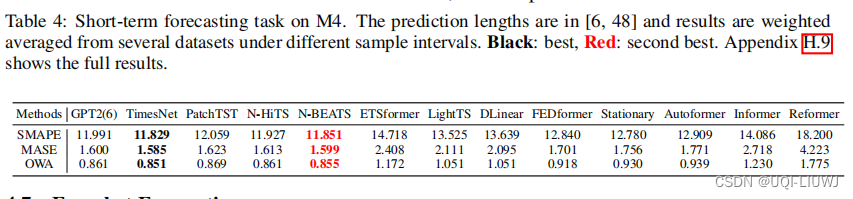
4.6 短期预测
4.7 few shot 预测
只使用很少的一部分训练数据(10%,5%)

4.8 zero-shot 预测
在A数据集上训练,在B数据集上测试

5 消融实验
5.1 模型的选择
- 分析了GPT2层数和微调参数的选择。
- 附录H中的结果表明,与完整或少量层数相比,具有6层的GPT2是一个合理的选择,并且部分冻结可以避免灾难性遗忘,使微调能够在不过拟合的情况下进行。
5.2 预训练的有效性
- GPT2(6)在时间序列任务中表现优于GPT2(0)和GPT2随机初始化
- ——>具有预训练参数的GPT2可以在时间序列任务上取得改进
- 此外,GPT2(6)的表现也优于GPT2非冻结,表明部分冻结也有所帮助。
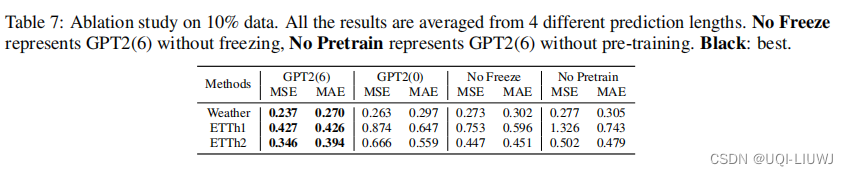
- 附录H.2中的结果显示,随机初始化的GPT2(6)在冻结情况下表现不佳,预训练知识对于时间序列任务至关重要。
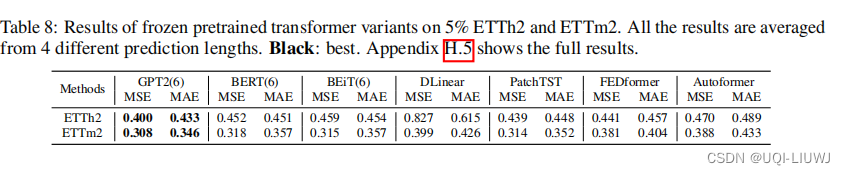
6 预训练模型在跨领域知识转移方面的普遍性
- 对BERT和图像预训练领域的BEiT进行了实验
- 知识转移的能力不仅限于基于GPT2的预训练语言模型
7 预训练模型中的Transformer和PCA 对应
证明略