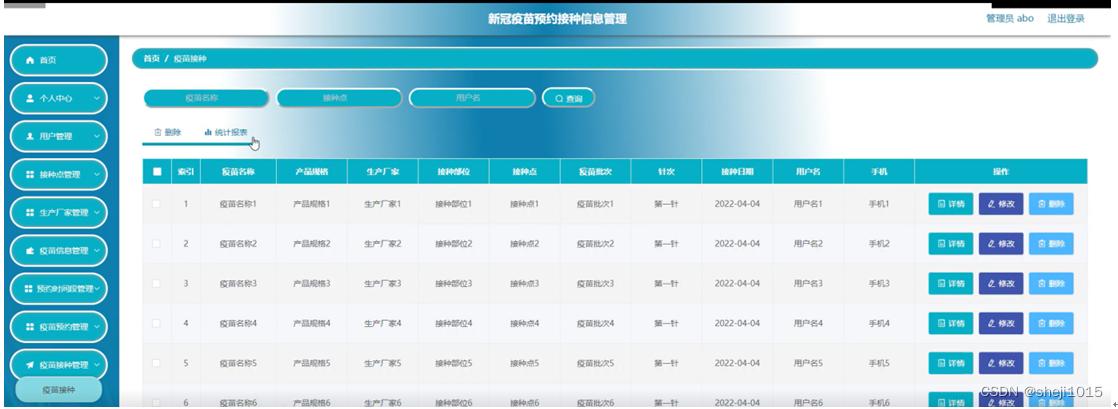
一、聚合查询(行与行之间的计算)
1.常见的聚合函数有:
| 函数 | 说明 |
| count | 查询到的数据的数量 |
| sum | 查询到的数据的总和(针对数值,否则无意义) |
| avg | 查询到的数据的平均值(针对数值,否则无意义) |
| max | 查询到的数据的最大值(针对数值,否则无意义) |
| min | 查询到的数据的最小值(针对数值,否则无意义) |
Select count(*) from student(统计行数)
Select count(1) from student(统计第一列数据的行数,如果有null则不算行数)
Select sum(math) from student(数学成绩总分)
Select sum(math) from student where math > 60(数学大于60的总分)
Select avg(math+chinese+english) from student(统计平均总分)
Select max(math) from student(数学最高分)
Select min(math) from student where math >60(数学大于60的最低分)
2.group by
select 中使用 group by 子句可以对指定列进行分组查询。使用 group by 进行分组查询时,select 指定的字段必须是“分组依据字段”,其他字段若想出现在select 中则必须包含在聚合函数中。
select column1, sum(column2), .. from table group by column1,column3;
//示例:查询每个角色的最高工资、最低工资和平均工资
Select role,max(salary),min(salary),avg(salary) from emp group by role;3.having
group by 子句进行分组以后,需要对分组结果再进行条件过滤时,不能使用 WHERE 语句,而需要用Having
//示例:显示平均工资低于1500的角色和它的平均工资
select role,avg(salary) from emp group by role having avg(salary)<1500; 关于分组查询指定条件有三种情况:
1.分组之前,指定条件(先筛选,再分组)用where
2.分组之后,指定条件(先分组,再筛选)用having
3.分组之前和分组之后都指定条件(先where后having)
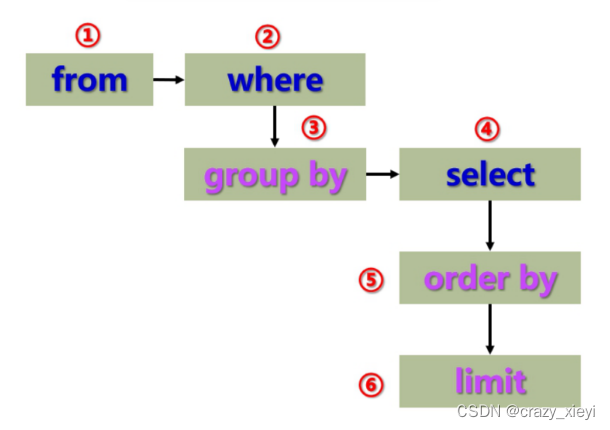
关于执行顺序:
二、联合查询(多表查询)
多表查询是对多张表的数据取笛卡尔积,笛卡尔积是通过排列组合算出来的,因此包含了很多无效数据,因此需要加上连接条件,用来筛选有效的数据。
1.进行联合查询的步骤:
1.首先计算笛卡尔积
2.引入连接条件(如:where student.id = score.student_id)
3.再根据需求,加入必要的条件(where where student.id = score.student_id and student.name=’xxx’)
4.去掉多余的列,只保留需要关注的列(select student.name,score.score from student,score where where student.id = score.student_id and student.name=’xxx’)
2.内连接(from,join on)
语法:
select 字段 from 表1 (as)别名1 [inner] join 表2 (as)别名2 on 连接条件 and 其他条件;
select 字段 from 表1 (as)别名1,表2 (as)别名2 where 连接条件 and 其他条件;
示例:查询“张三”同学的成绩
select sco.score from student as stu inner join score as sco on stu.id=sco.student_id
and stu.name='张三';或者
select sco.score from student as stu, score as sco where stu.id=sco.student_id and
stu.name='张三';3.外连接(left/right join on)
外连接分为左外连接和右外连接。如果联合查询,左侧的表完全显示我们就说是左外连接;右侧的表完全显示我们就说是右外连接。
语法:
左外连接,表1完全显示
select 字段名 from 表名1 left join 表名2 on 连接条件;
右外连接,表2完全显示
select 字段 from 表名1 right join 表名2 on 连接条件;
4.自连接
自连接是指在同一张表中连接自身进行查询。
示例:显示所有“数学”成绩比“语文”成绩高的学生成绩信息
先查询“数学”和“语文”课程的id
select id,name from course where name='数学' or name='语文';
数学id=1;
语文id=2;
再查询成绩表中,“数学”成绩比“语文”成绩 好的信息
select s1.* from score s1,score s2 where s1.student_id = s2.student_id and s1.score > s2.score and s1.course_id = 1 and s2.course_id = 2;5.子查询
子查询是指嵌入在其他sql语句中的select语句,也叫嵌套查询。
单行子查询:返回一行记录的子查询
select * from student where classes_id=(select classes_id from student where name=’张三’);多行子查询:返回多行记录的子查询
1.使用(not) in 关键字
使用 in
select * from score where course_id in (select id from course where
name='语文' or name='英文');
使用not in
select * from score where course_id not in (select id from course where
name!='语文' and name!='英文');
1.使用(not) exists 关键字
使用 exists
select * from score sco where exists (select sco.id from course cou
where (name='语文' or name='英文') and cou.id = sco.course_id);
使用 not exists
select * from score sco where not exists (select sco.id from course cou
where (name!='语文' and name!='英文') and cou.id = sco.course_id);
在from子句中使用子查询,把一个子查询当做一个临时表使用。(not)in是放在内存中的,如果查询的数据太大,内存中放不下,此时就需要使用(not)exists。exists本质上就是让数据库执行多个查询操作,并把结果放在磁盘中,因此对于exists来说,执行效率大大低于in,而且可读性也不是很好,这种比较适合处理一些特殊的场景。
6.合并查询
合并查询本质上就是把两个查询结果集合并成一个,但是要求这两个结果集的列一样,才能合并。即:
为了合并多个select的执行结果,可以使用集合操作符 union,union all。使用union和union all时,前后查询的结果集中,字段需要一致。
1.union关键字
用于取得两个结果集的并集。当使用该操作符时,会自动去掉结果集中的重复行。
示例:
select * from course where id<3 union select * from course where name='英文';
或者使用or来实现
select * from course where id<3 or name='英文’;
2.union all关键字
用于取得两个结果集的并集。当使用该操作符时,不会去掉结果集中的重复行。
示例:
可以看到结果集中出现重复数据
select * from course where id<3 union all select * from course where name='英文’;