【三维重建】【深度学习】NeRF代码Pytorch实现–数据加载(上)
论文提出了一种5D的神经辐射场来作为复杂场景的隐式表示,称为NeRF,其输⼊稀疏的多⻆度带pose的图像训练得到⼀个神经辐射场模型。简单来说就是通过输入同一场景不同视角下的二维图片和相机位姿,对场景进行三维隐式建模,并通过体素渲染方程实现了合成任意新视角下的场景图片。本篇博文将根据代码执行流程解析数据加载过程中具体的功能模块代码。
文章目录
- 【三维重建】【深度学习】NeRF代码Pytorch实现--数据加载(上)
- 前言
- load_llff_data
- _load_data
- _minify
- recenter_poses
- poses_avg
- viewmatrix
- 总结
前言
在详细解析NeuS网络之前,首要任务是搭建NeRF【win10下参考教程】所需的运行环境,并完成模型的训练和测试,展开后续工作才有意义。
本博文是对NeuS数据加载过程中涉及的部分功能代码模块进行解析,其他代码模块后续的博文将会陆续讲解。
博主将各功能模块的代码在不同的博文中进行了详细的解析,点击【win10下参考教程】,博文的目录链接放在前言部分。
load_llff_data
在run_nerf.py文件的train函数里被调用。
# 加载llff格式数据集
images, poses, bds, render_poses, i_test = load_llff_data(args.datadir, args.factor,
recenter=True, bd_factor=.75,
spherify=args.spherify)
load_llff_data在load_llff.py文件内,由于内容太多,博主将这个函数的代码分段进行讲解。_load_data加载数据集的图片、位姿和边界;recenter_poses对所有相机位姿进行旋转平移变换完成归一化。
# poses[3,5,N] N是数据集个数, 3×3是旋转矩阵R,3×1(第4列)是平移矩阵T,3×1(第5列)是h,w,f
# bds[2,N] 采样far,near信息,即深度值范围
# imgs[h,w,c,N]
poses, bds, imgs = _load_data(basedir, factor=factor) # factor=8 downsamples original imgs by 8x
print('Loaded', basedir, bds.min(), bds.max())
# 列变换 [x,y,z,t,whf]--->[y,-x,z,t,whf]
poses = np.concatenate([poses[:, 1:2, :], -poses[:, 0:1, :], poses[:, 2:, :]], 1) # [3,5,N]
# 变换维度:调换第-1轴到第0轴位置
poses = np.moveaxis(poses, -1, 0).astype(np.float32) # [N,3,5]
imgs = np.moveaxis(imgs, -1, 0).astype(np.float32) # [N,h,w,c]
images = imgs
bds = np.moveaxis(bds, -1, 0).astype(np.float32) # [N,2]
# 获得缩放因子,以bds.min为基准,有点类似归一化
sc = 1. if bd_factor is None else 1./(bds.min() * bd_factor)
# 对位姿的平移矩阵t进行缩放
poses[:, :3, 3] *= sc
# 对边界进行缩放
bds *= sc
# 计算pose的均值,将所有pose做个均值逆转换
if recenter:
poses = recenter_poses(poses)
其中以下代码段是为了完成位姿格式的转换。
# 列变换 [x,y,z,t,whf]--->[y,-x,z,t,whf]
poses = np.concatenate([poses[:, 1:2, :], -poses[:, 0:1, :], poses[:, 2:, :]], 1) # [3,5,N]
列变换后相机坐标系的示意图:

_load_data
加载数据集的resize后的图片(可选)、pose位姿和bds边界信息。其中_minify函数对原始图像进行resize操作。
def _load_data(basedir, factor=None, width=None, height=None, load_imgs=True):
# 存放数据集的位姿和边界信息(深度范围) [images_num,17] eg:[20,17]
poses_arr = np.load(os.path.join(basedir, 'poses_bounds.npy'))
# [images_num,17]--->[3,5,images_num] eg:[3,5,20]
# 3×3是旋转矩阵R,3×1(第4列)是平移矩阵T,3×1(第5列)是h,w,f
poses = poses_arr[:, :-2].reshape([-1, 3, 5]).transpose([1, 2, 0])
# bounds 边界(深度)范围[2,images_num] eg:[2,20]
bds = poses_arr[:, -2:].transpose([1, 0])
# 获取第一张图像的地址,图像必须是jpg或png格式
img0 = [os.path.join(basedir, 'images', f) for f in sorted(os.listdir(os.path.join(basedir, 'images'))) \
if f.endswith('JPG') or f.endswith('jpg') or f.endswith('png')][0]
# 获取图像shape[h,w,c]
sh = imageio.imread(img0).shape
# 文件名后缀:
sfx = ''
# 按照要求resize图像
# 下采样倍数
if factor is not None:
sfx = '_{}'.format(factor)
_minify(basedir, factors=[factor])
factor = factor
# 指定分辨率中的高度
elif height is not None:
# 计算出原始尺寸高度和指定高度的比值
factor = sh[0] / float(height)
# 按照比值计算出对应的宽度
width = int(sh[1] / factor)
# 指定分辨率的方式resize
_minify(basedir, resolutions=[[height, width]])
sfx = '_{}x{}'.format(width, height)
# 指定分辨率中的宽度
elif width is not None:
# 计算出原始尺寸高度和指定宽度的比值
factor = sh[1] / float(width)
# 按照比值计算出对应的高度
height = int(sh[0] / factor)
# 指定分辨率的方式resize
_minify(basedir, resolutions=[[height, width]])
sfx = '_{}x{}'.format(width, height)
else:
# 不进行尺寸上的任何处理
factor = 1
# 获取新尺寸图像的保存路径
imgdir = os.path.join(basedir, 'images' + sfx)
# 判断目录是否存在
if not os.path.exists(imgdir):
print(imgdir, 'does not exist, returning' )
return
# 获取所有新尺寸图像的文件路径
imgfiles = [os.path.join(imgdir, f) for f in sorted(os.listdir(imgdir)) if f.endswith('JPG') or f.endswith('jpg') or f.endswith('png')]
# 判断图片pose和新图片的数目是否一致
if poses.shape[-1] != len(imgfiles):
print('Mismatch between imgs {} and poses {} !!!!'.format(len(imgfiles), poses.shape[-1]) )
return
# 读取新图像的shape[h/factor,w/factor,c]
sh = imageio.imread(imgfiles[0]).shape
# 图像尺寸缩小了,相对于的w和h也要改变(替换)
poses[:2, 4, :] = np.array(sh[:2]).reshape([2, 1])
# 更新f值 f=f_ori/factor
poses[2, 4, :] = poses[2, 4, :] * 1./factor
# 只加载位姿和边界
if not load_imgs:
return poses, bds
# 加载图片
def imread(f):
if f.endswith('png'):
return imageio.imread(f, format="PNG-PIL", ignoregamma=True)
else:
return imageio.imread(f)
# 读取所有新图像并归一化
imgs = [imread(f)[..., :3]/255. for f in imgfiles]
# 拼接所有图像[h/factor,w/factor,c,images_num]
imgs = np.stack(imgs, -1)
print('Loaded image data', imgs.shape, poses[:,-1,0])
return poses, bds, imgs
poses位姿3×5矩阵的表示:
[
R
t
h
w
f
]
\left[ {\begin{array}{cc} R&t&{\begin{array}{cc} h\\ w\\ f \end{array}} \end{array}} \right]
Rthwf
R是旋转矩阵3×3,t是位移矩阵3×1,剩下的3×1就是图片尺寸和焦距。
_minify
根据下采样的倍数或者指定分辨率对原始图像进行resize操作,并以png格式保存到新的文件夹中。
def _minify(basedir, factors=[], resolutions=[]):
needtoload = False
# 按照下采样倍数
for r in factors:
# 判断本地是否已经存有下采样factors的图像
imgdir = os.path.join(basedir, 'images_{}'.format(r))
if not os.path.exists(imgdir):
needtoload = True
# 按照分辨率下采样
for r in resolutions:
# 判断本地是否已经存有对应具体分辨率的图像
imgdir = os.path.join(basedir, 'images_{}x{}'.format(r[1], r[0]))
if not os.path.exists(imgdir):
needtoload = True
# 如果有直接退出
if not needtoload:
return
# 如果没有需要重新加载
# 汇制命令语句(操作系统自带此功能)
from subprocess import check_output
# 获取原始图片的路径
imgdir = os.path.join(basedir, 'images')
# 获取所有图片地址,并排除其他非图像文件
imgs = [os.path.join(imgdir, f) for f in sorted(os.listdir(imgdir))]
imgs = [f for f in imgs if any([f.endswith(ex) for ex in ['JPG', 'jpg', 'png', 'jpeg', 'PNG']])]
imgdir_orig = imgdir.replace("\\", "/")
# 获得执行py文件当前所在目录
wd = os.getcwd()
for r in factors + resolutions:
# 下采样的倍数 int类型
if isinstance(r, int):
# 保存新尺寸图像的文件夹
name = 'images_{}'.format(r)
# resize的大小
resizearg = '{}%'.format(100./r)
# 指定分辨率 list类型
else:
name = 'images_{}x{}'.format(r[1], r[0])
resizearg = '{}x{}'.format(r[1], r[0])
# 新尺寸图像的保存路径
imgdir = os.path.join(basedir, name).replace("\\", "/")
if os.path.exists(imgdir):
continue
print('Minifying', r, basedir)
# 创建新尺寸图像的保存文件夹
os.makedirs(imgdir)
# 将原始图片拷贝到指定新尺寸图像的保存文件夹下
check_output('cp {}/* {}'.format(imgdir_orig, imgdir), shell=True)
# 获取图片的数据格式
ext = imgs[0].split('.')[-1]
# 绘制执行命令语句
args = ' '.join(['magick ', 'mogrify', '-resize', resizearg, '-format', 'png', '*.{}'.format(ext)])
# 切换到新尺寸图像的保存路径
os.chdir(imgdir)
# 对新尺寸图像的保存路径中的原始图片进行resize,并用png格式保存
check_output(args, shell=True)
# 切回当前执行py文件所在目录
os.chdir(wd)
# 因为新尺寸图像的保存路径下除了png格式的新尺寸图像,还有原始尺寸图像需要删除,要是原始图像也是png格式则直接覆盖
if ext != 'png':
check_output('rm {}/*.{}'.format(imgdir, ext), shell=True)
print('Removed duplicates')
print('Done')
recenter_poses
中心化相机位姿,即包括位置和朝向。
- poses_avg函数计算出所有相机的平均位姿。
- 相机的平均位姿的逆左乘所有相机位姿进行旋转平移变换完成归一化。
def recenter_poses(poses):
poses_ = poses+0 # [N,3,5]
# 作用是让平均相机位姿[3,4]变为[4,4]
bottom = np.reshape([0,0,0,1.], [1, 4]) # [1,4]
c2w = poses_avg(poses) # [3,4]
c2w = np.concatenate([c2w[:3, :4], bottom], -2) # [4,4]
# 作用是让所有相机位姿[3,4]变为[4,4]
# bottom[1,1,4]--->对bottom对应维度进行复制扩展[images_num,1,1]==>[1*N,1*1,4*1]
bottom = np.tile(np.reshape(bottom, [1, 1, 4]), [poses.shape[0], 1, 1]) # [N,1,4]
# poses shape [images_num,4,4]
poses = np.concatenate([poses[:, :3, :4], bottom], -2) # [N,4,4]
# 求c2w的逆矩阵,并与poses进行矩阵运算,目的是完成所有相机位姿的归一化
poses = np.linalg.inv(c2w) @ poses # [4,4]
# 用新的旋转矩阵R替换原始的旋转矩阵R
poses_[:, :3, :4] = poses[:, :3, :4] # [4,4]
# 对pose进行中心化处理
poses = poses_
return poses
代码的示意图如下图所示:

图中实线构成的坐标系是原始位姿,虚线构成的坐标系是经过旋转平移变换的,Pose_mean变换后的坐标系与世界坐标系是完全重合的。
相机的平均位姿的逆左乘相机的平均位姿产生的新的位姿(单位矩阵)是完全与世界坐标系重合的(原点和坐标轴都重合),那么利用同一个 旋转平移变换矩阵(相机的平均位姿的逆) 左乘所有的相机位姿是对所有的相机位姿做一个全局的旋转平移变换完成归一化,这样变换后的所有相机的平均位姿就处在世界坐标系的原点,所有光心的质心(平均位姿的光心)也由世界坐标系上的一个非原点转变成了原点。
平移矩阵t可以理解成光心,因为从原点平移t。
poses_avg
计算所有图片对应相机位姿的均值,即包括位置和朝向。
- 位置:对全部相机的中心求均值得到center。
- 朝向:所有相机的Z轴求和归一化平得到vec2(平均单位方向向量),:所有相机的Y轴求和得到up(主方向向量),通过viewmatrix函数得到全部相机的外参均值。
def poses_avg(poses):
# 获取图像的尺寸和焦距
hwf = poses[0, :3, -1:] # [3,1]
# 计算全部平移矩阵t的均值
center = poses[:, :3, 3].mean(0) # [N,3]
# 全部旋转矩阵R的第三列求和并归一化(方向向量相加再归一化等效于平均单位方向向量)
vec2 = normalize(poses[:, :3, 2].sum(0)) # [3]
# 全部旋转矩阵R的第二列求和(方向向量相加理解成所有方向向量的主方向向量)
up = poses[:, :3, 1].sum(0) # [3]
#
c2w = np.concatenate([viewmatrix(vec2, up, center), hwf], 1) # [3,5]
return c2w
代码的示意图如下图所示:

viewmatrix
构造相机矩阵的的函数,通过z轴的平均单位方向向量和y轴的主方向向量计算出x轴的单位方向向量,然后z轴的平均单位方向向量和x轴的单位方向向量计算出y轴的单位方向向量,最后xyz三轴的三维方向向量加上平均相机中心构造出所有相机的平均位姿。
def viewmatrix(z, up, pos):
# z轴平均单位方向向量
vec2 = normalize(z) # [3,1]
# y轴主方向向量
vec1_avg = up # [3,1]
# 计算出x的单位方向向量
vec0 = normalize(np.cross(vec1_avg, vec2)) # [3,1]
# 计算出y州的单位方向向量
vec1 = normalize(np.cross(vec2, vec0)) # [3,1]
m = np.stack([vec0, vec1, vec2, pos], 1) # [3,4]
return m
代码的示意图如下图所示:
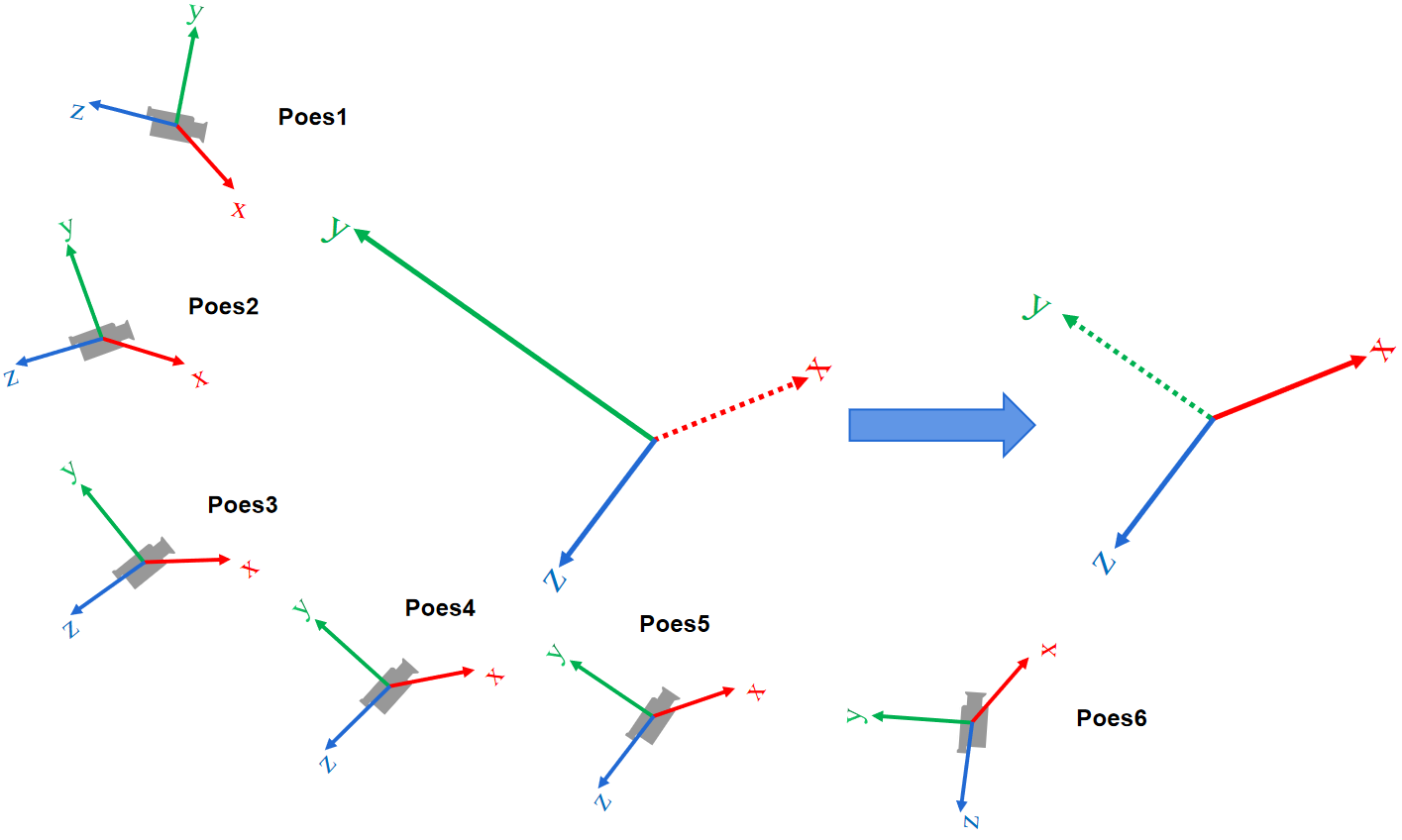
虚线表现计算出的新轴的单位方向向量,这里y轴为什么也要重新计算?有观点认为这是因为有可能原始的y并不与z互相垂直,存在计算误差?
总结
尽可能简单、详细的介绍数据加载过程中部分代码:_load_data加载数据和recenter_poses对所有相机位姿完成归一化。后续会讲解其他功能模块的代码。