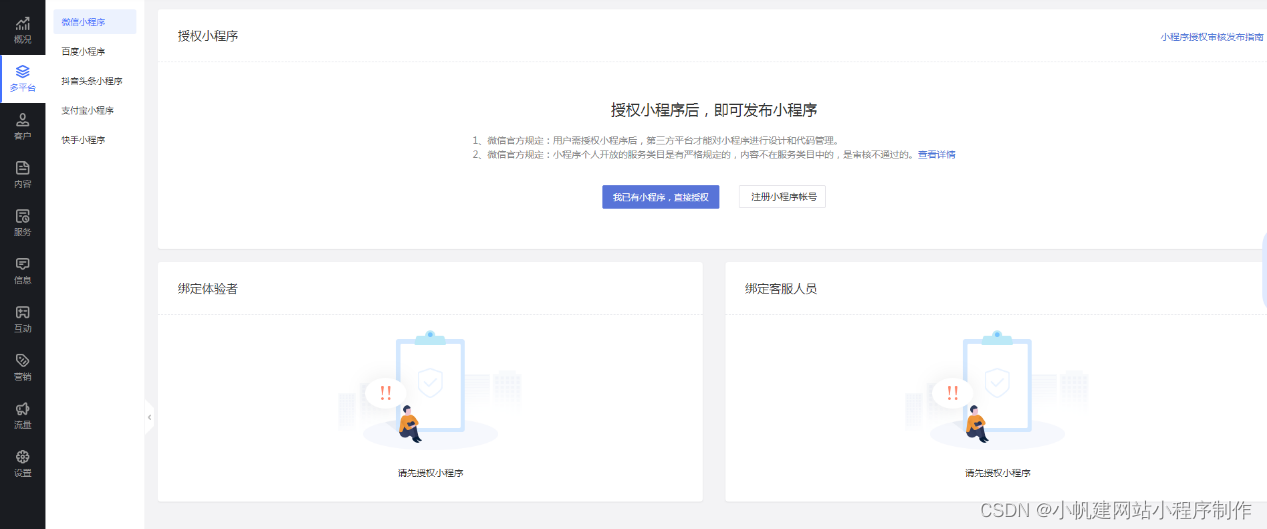
Kibana 是一个有用的工具,用于监控应用程序和服务以确保它们在指定的服务级别目标内运行。 服务质量指标 (SLI) 是服务的可衡量方面,例如错误代码和延迟。 服务质量目标 (SLO) 定义应用程序或服务预期如何按照 SLI 衡量的方式执行,并在某种程度上设置服务正常运行时间和可用性目标。 随着应用程序生成的日志记录和指标数据的增长,对 Elasticsearch 集群处理 SLI 数据聚合的需求也在增长。
如果你曾经为高度密集的指标数据集组装过 SLO 仪表板,你可能已经知道集群上由数百万事件支持的 SLI 可视化是多么繁重,因为每个仪表板可视化都针对支持索引执行一个或多个聚合。 例如,一种这样的聚合可能会显示指定时间间隔内按响应代码分组的 HTTP 错误数。 另一个可能聚合代理日志以显示随时间推移的后端请求延迟。
Elasticsearch transforms 可用于为 SLO 仪表板预聚合 SLI 指标,例如 HTTP 响应代码。 转换对现有索引的查询,然后将汇总数据写入可供可视化使用的较小索引,从而允许快速检索聚合数据,而无需搜索整个数据集。
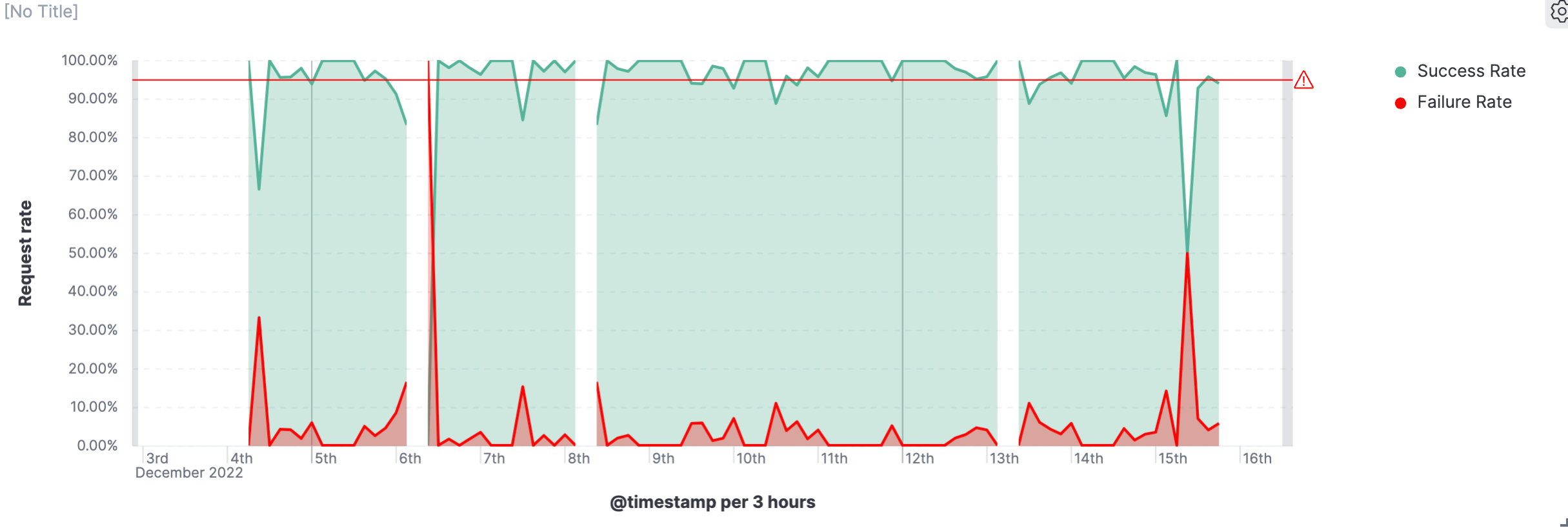
在下图,我们展示了所有 HTTP 请求成功及失败的几率。根据我们的 SLO 定义,我们可以在下图中很容易看出来那些时候 SLO 是低于我们的目标的。
在今天的展示中,我将以最新的 Elastic Stack 8.5.2 来进行展示。
准备数据
我们以 Kibana 自带的 web log 数据为例来进行展示:

这样,我们就向 Elasticsearch 写入了一个叫做 kibana_sample_data_logs 的索引。
创建 transform
我们将使用 pivot transform 来对 kibana_sample_data_logs 进行聚合。我们按照如下的步骤来做:

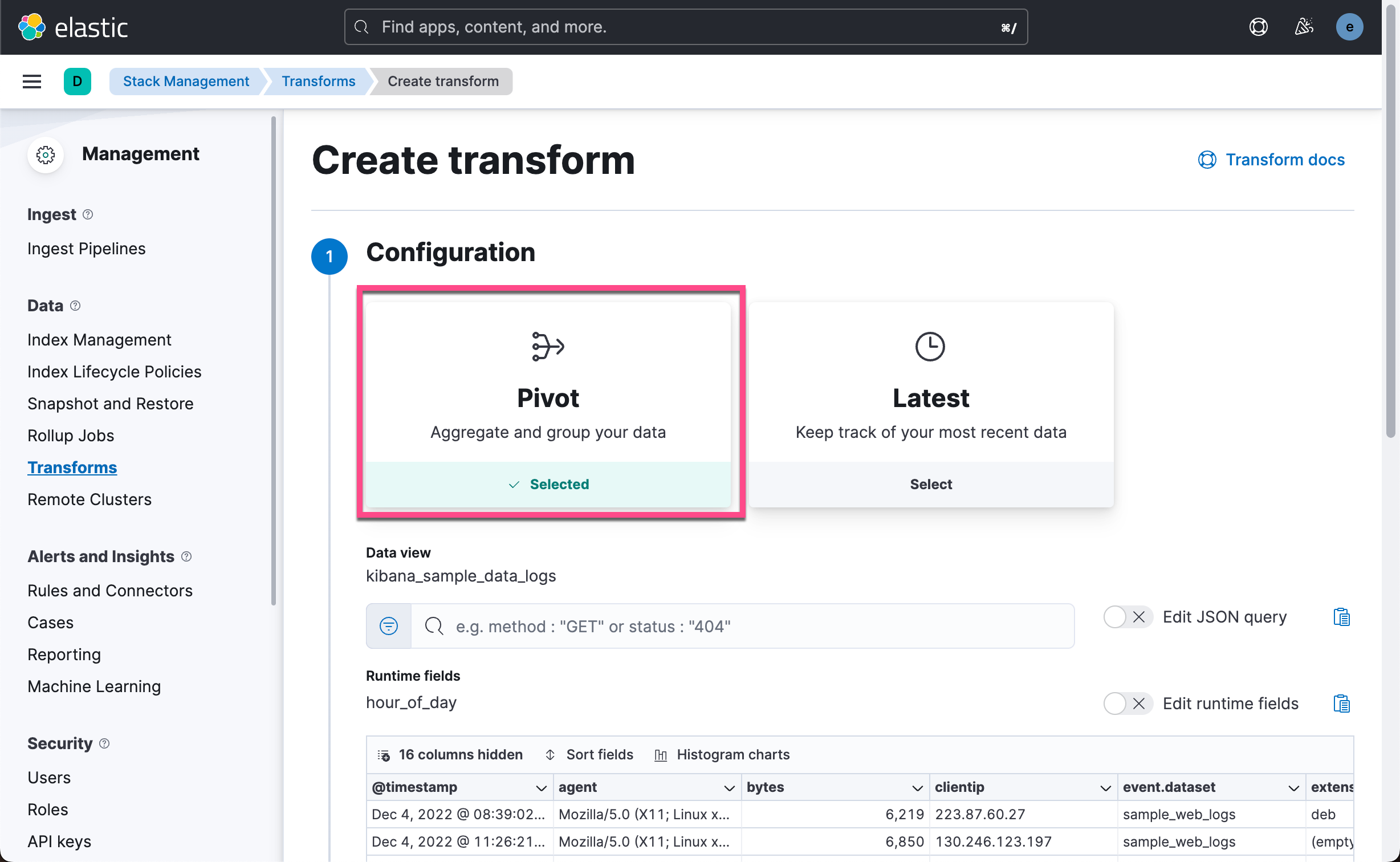

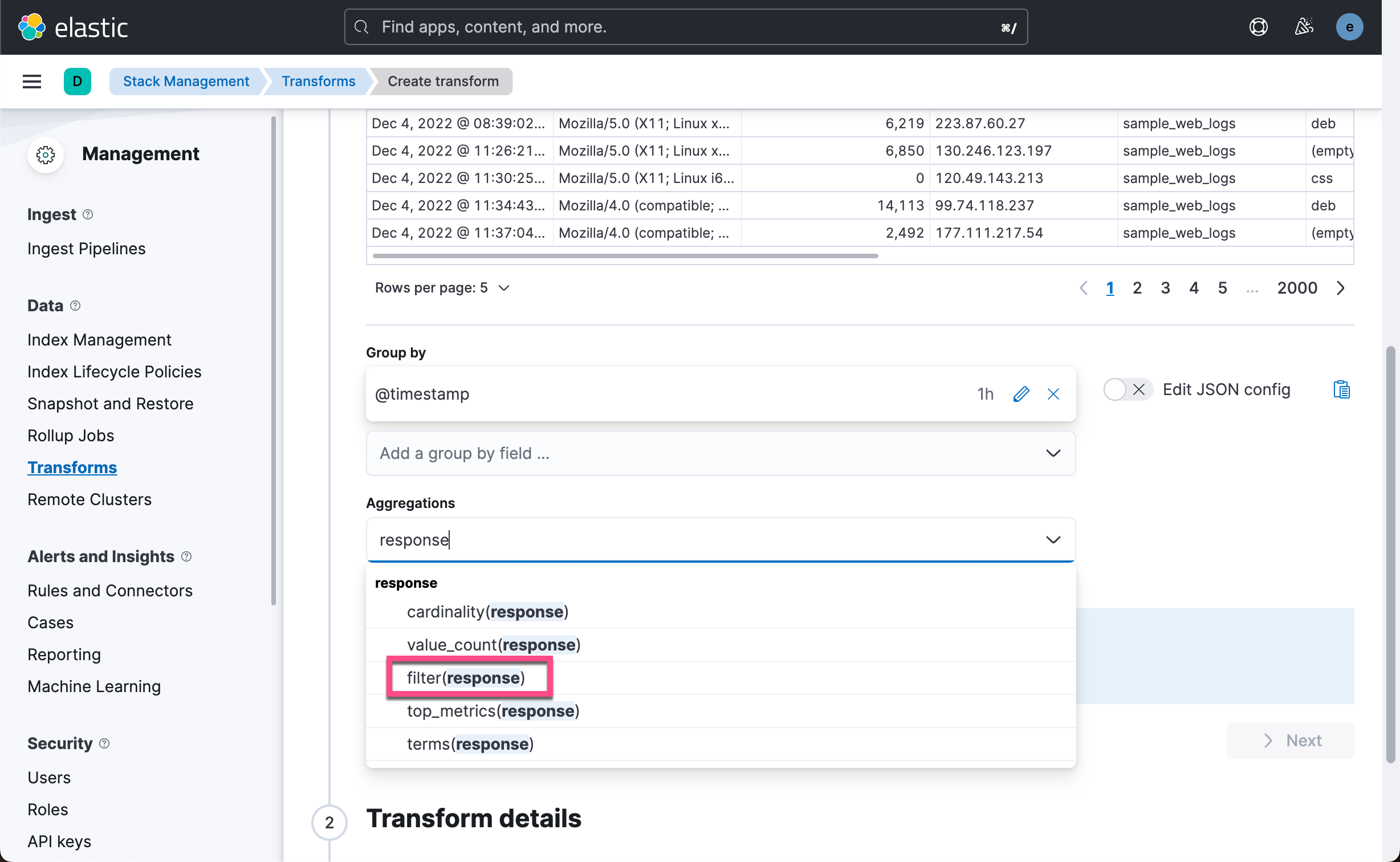
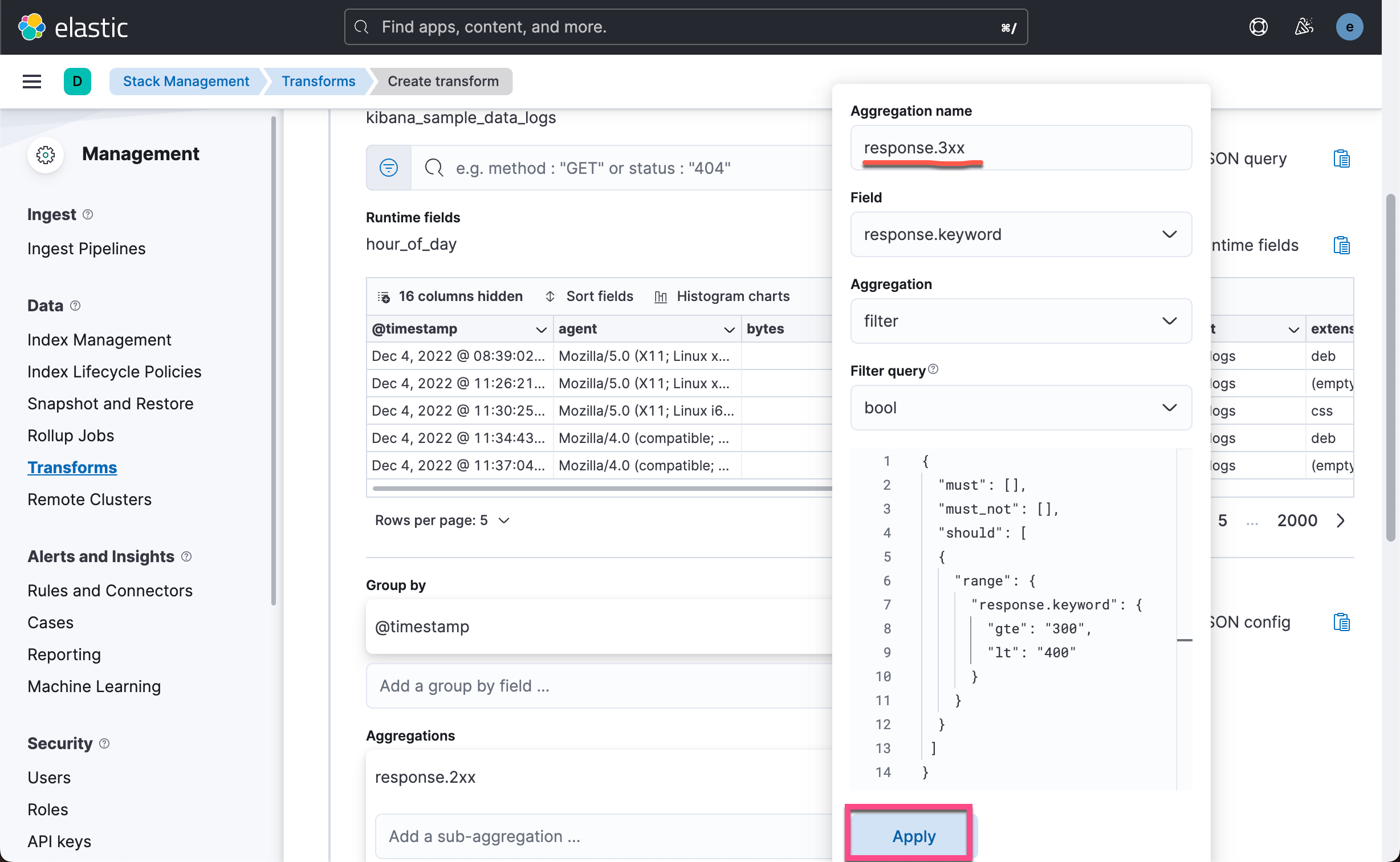
接下来,我们将定义要执行的聚合并发送到 transform 目标索引。 点击 Add an aggregation …,然后键入 response 以过滤选择框。 点击 filter(response)
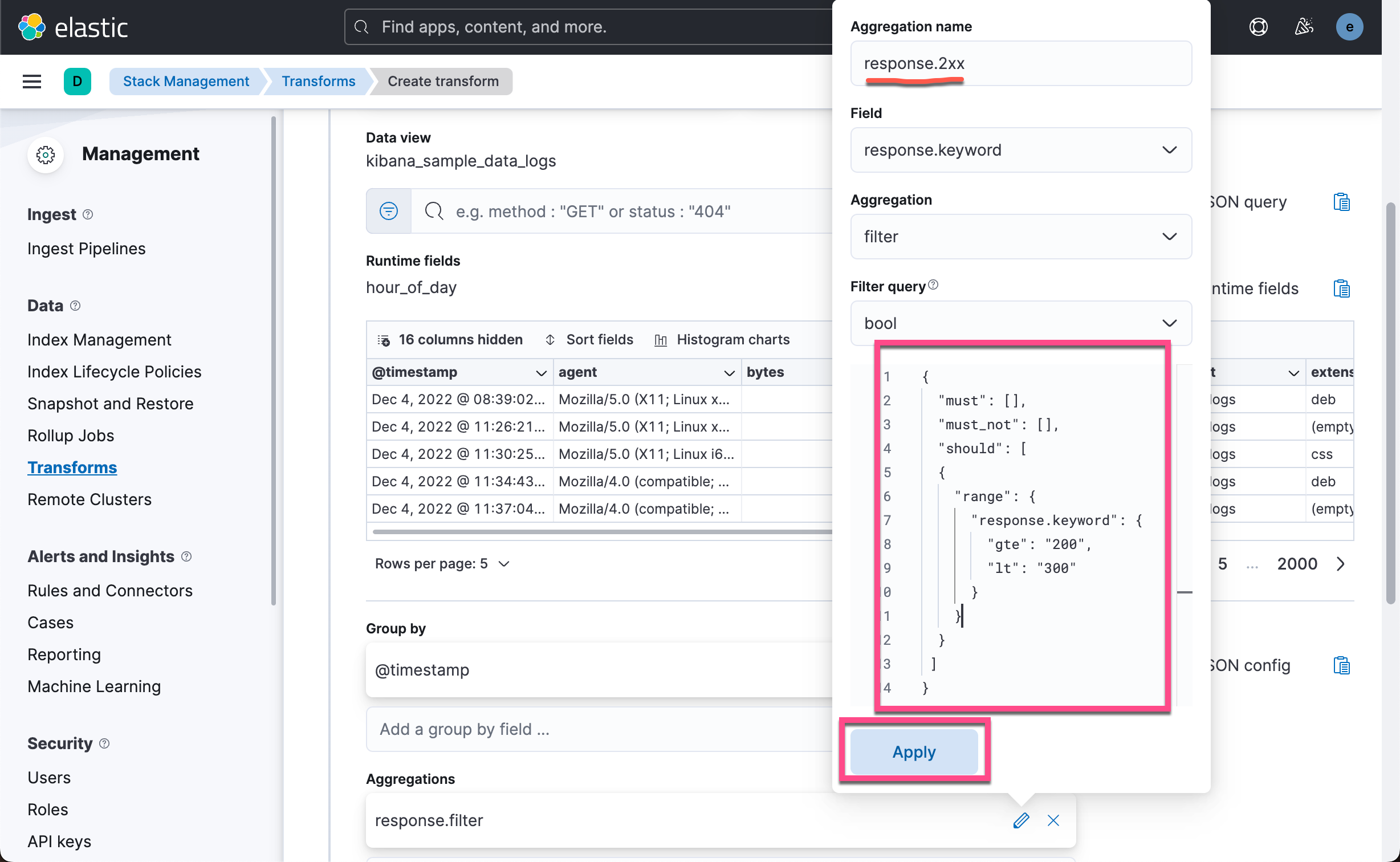
我们在上面的框中输入如下的查询:
{
"must": [],
"must_not": [],
"should": [
{
"range": {
"response.keyword": {
"gte": "200",
"lt": "300"
}
}
}
]
}
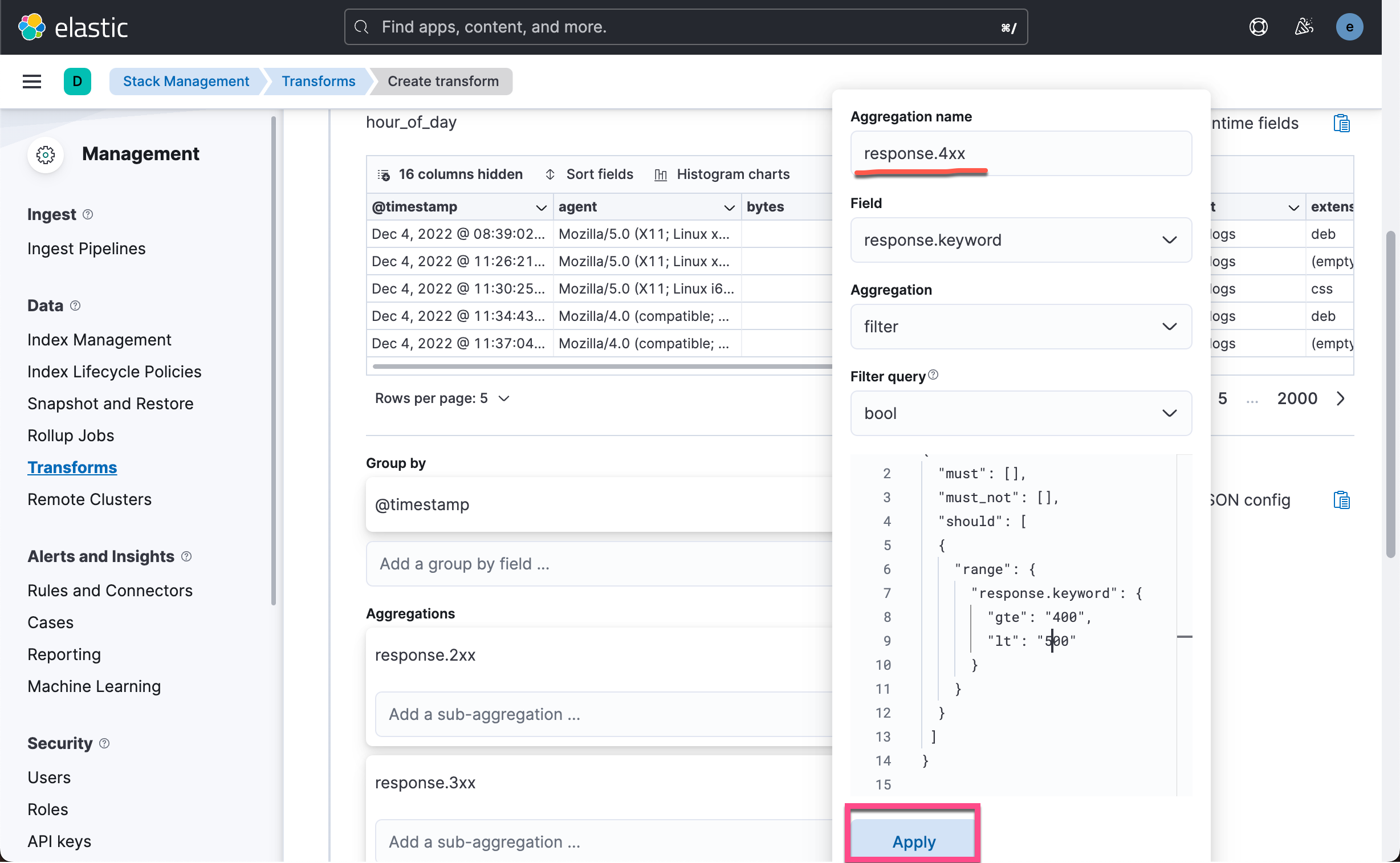
我们再点击上面的 Add an aggregation ... 如法炮制,创建如下的几个聚合:
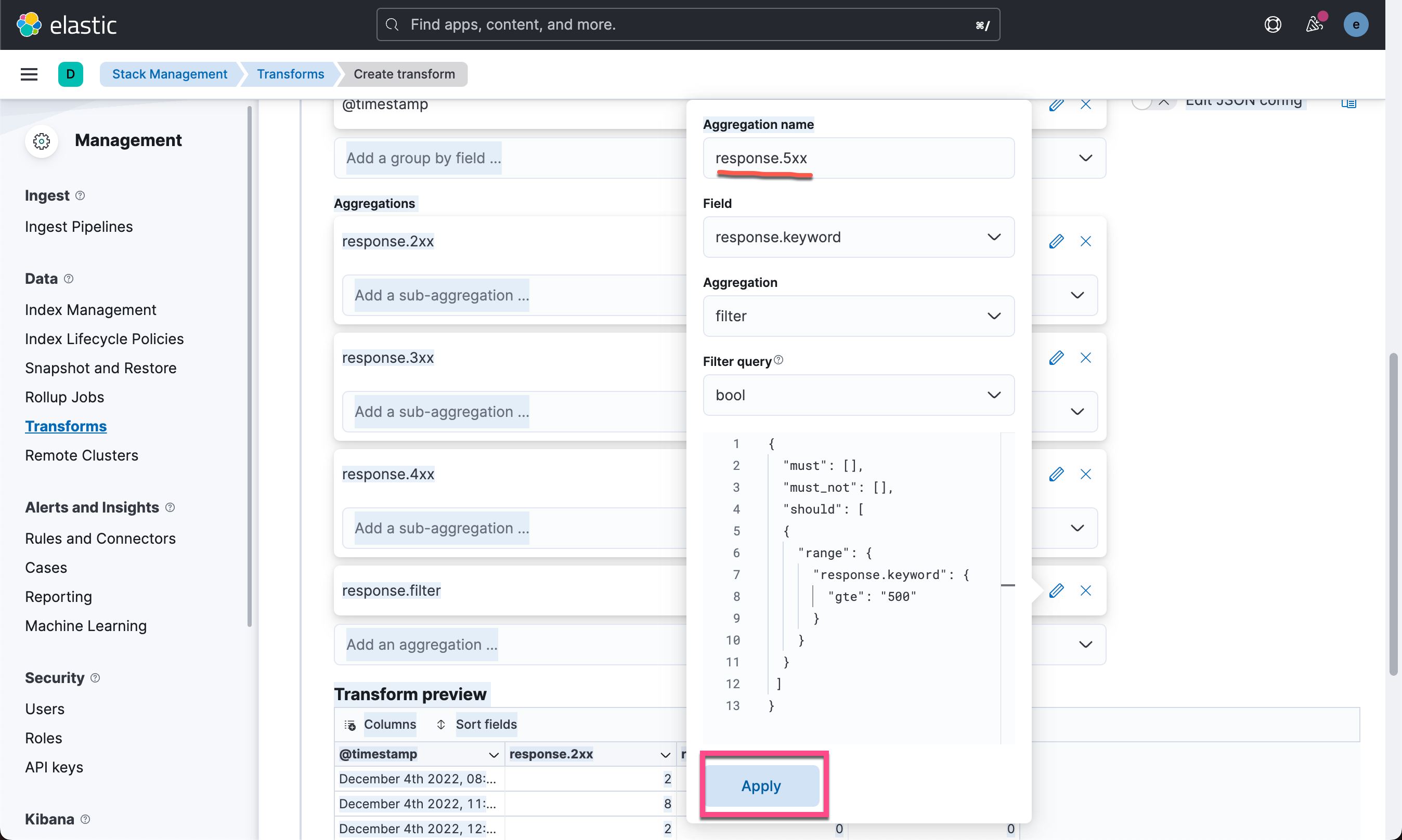
最后,让我们为所有响应代码再添加一个聚合。 在 response.keyword 字段上使用 value count 聚合并将聚合命名为 response.total。 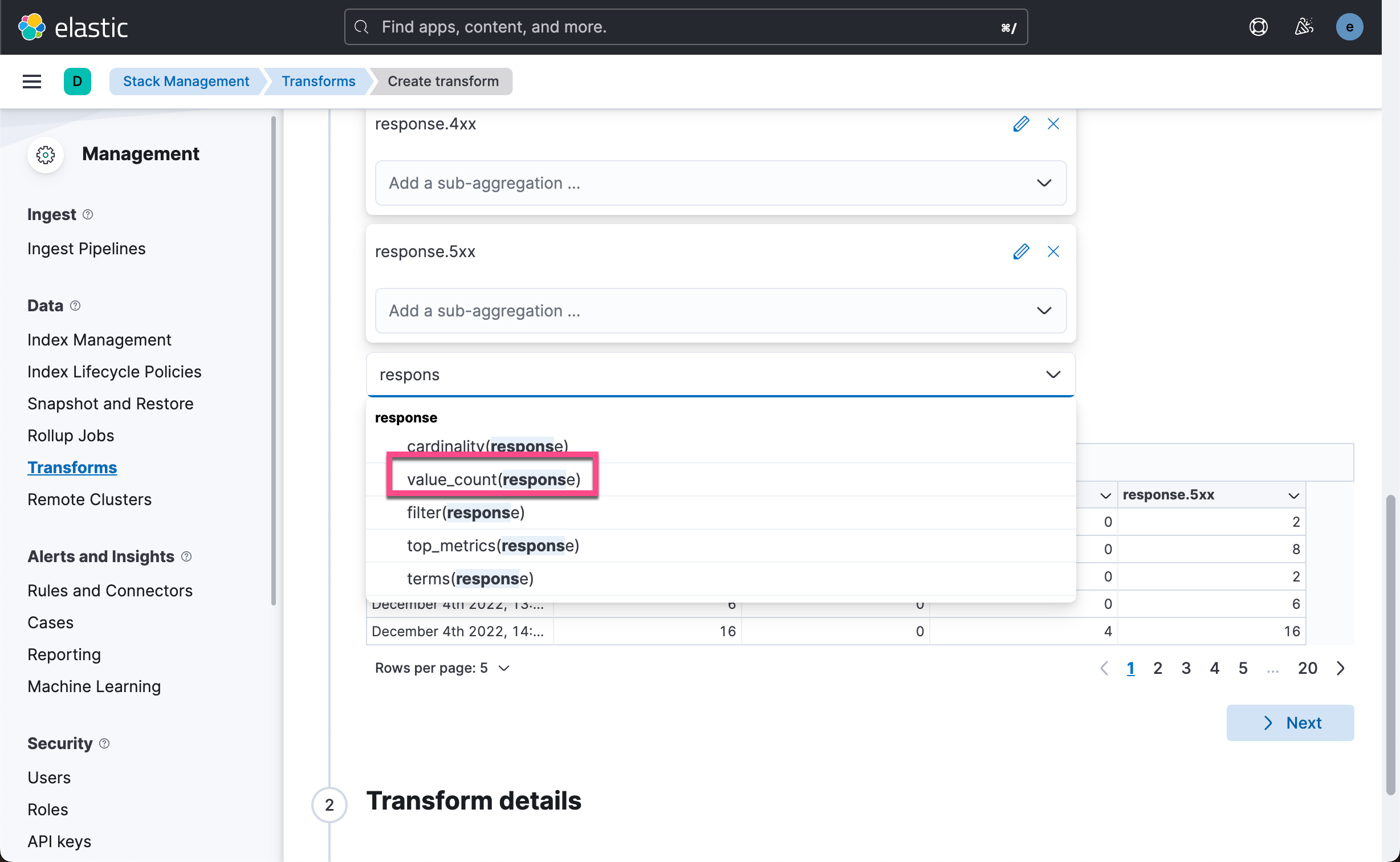

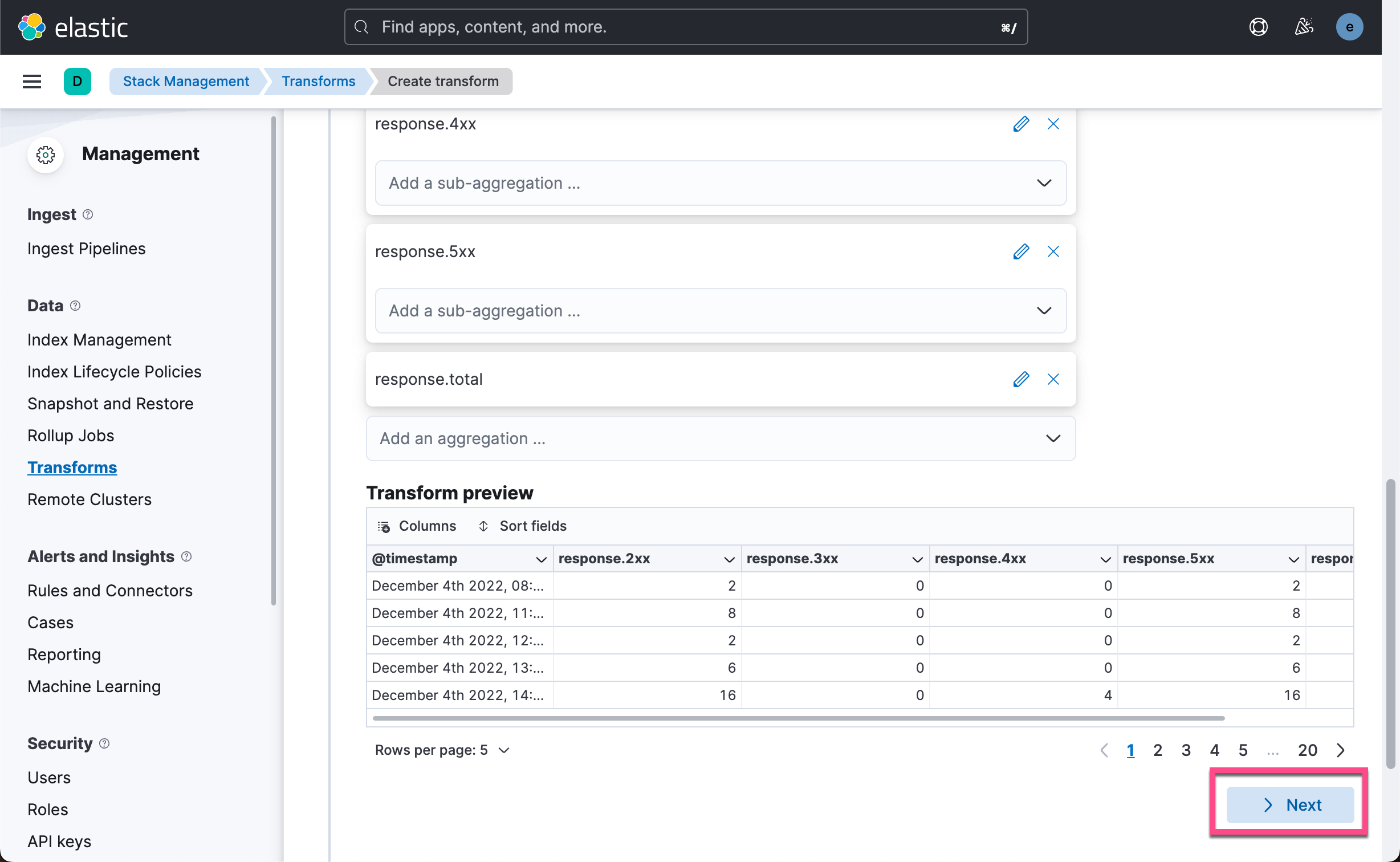
通过按日期分组的五个聚合,transform 预览应包含六个字段。 预览显示了一个数据示例,在执行转换时,这些数据将被索引到目标转换索引。 如果预览看起来不错,请单击 Next。
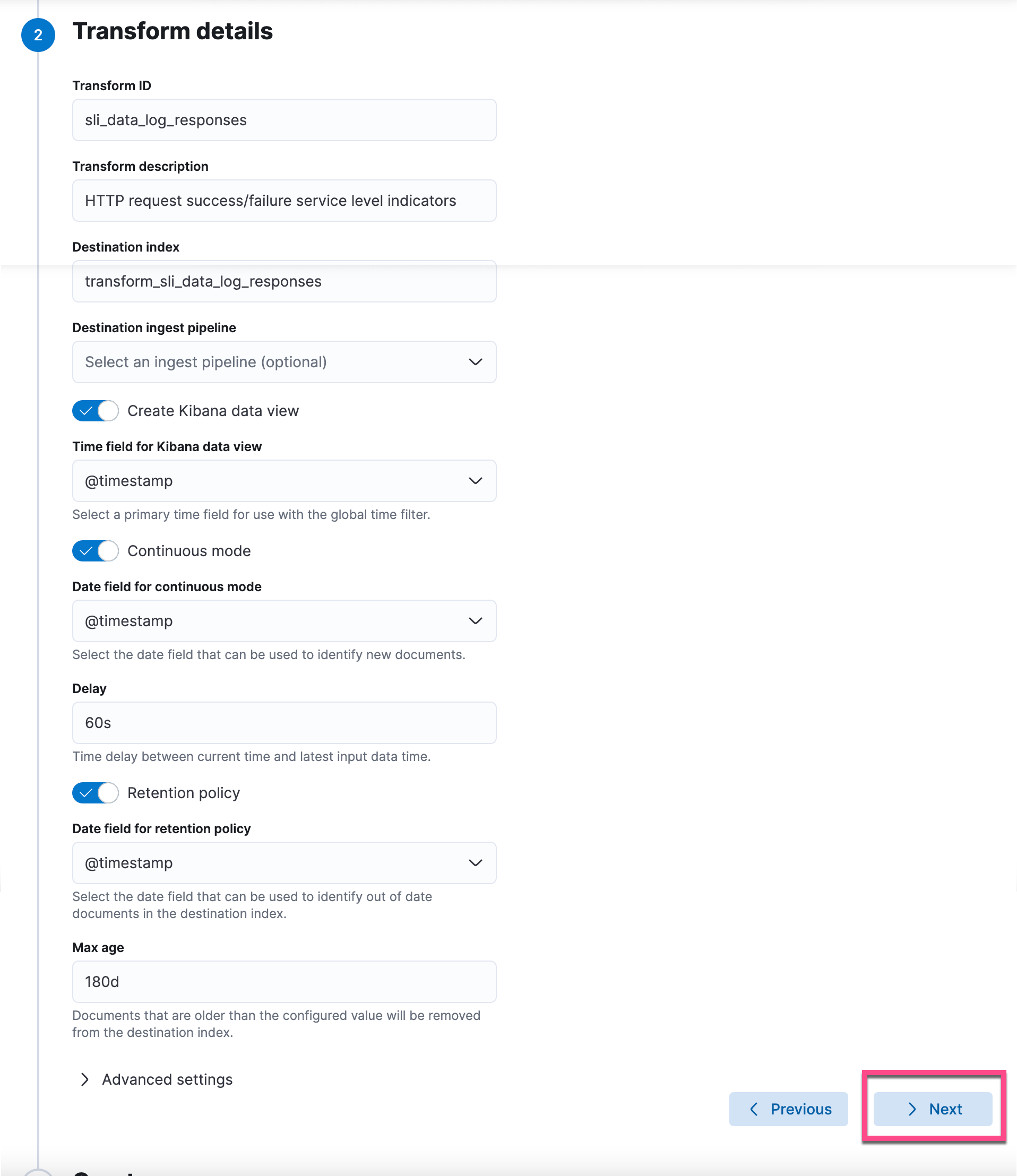

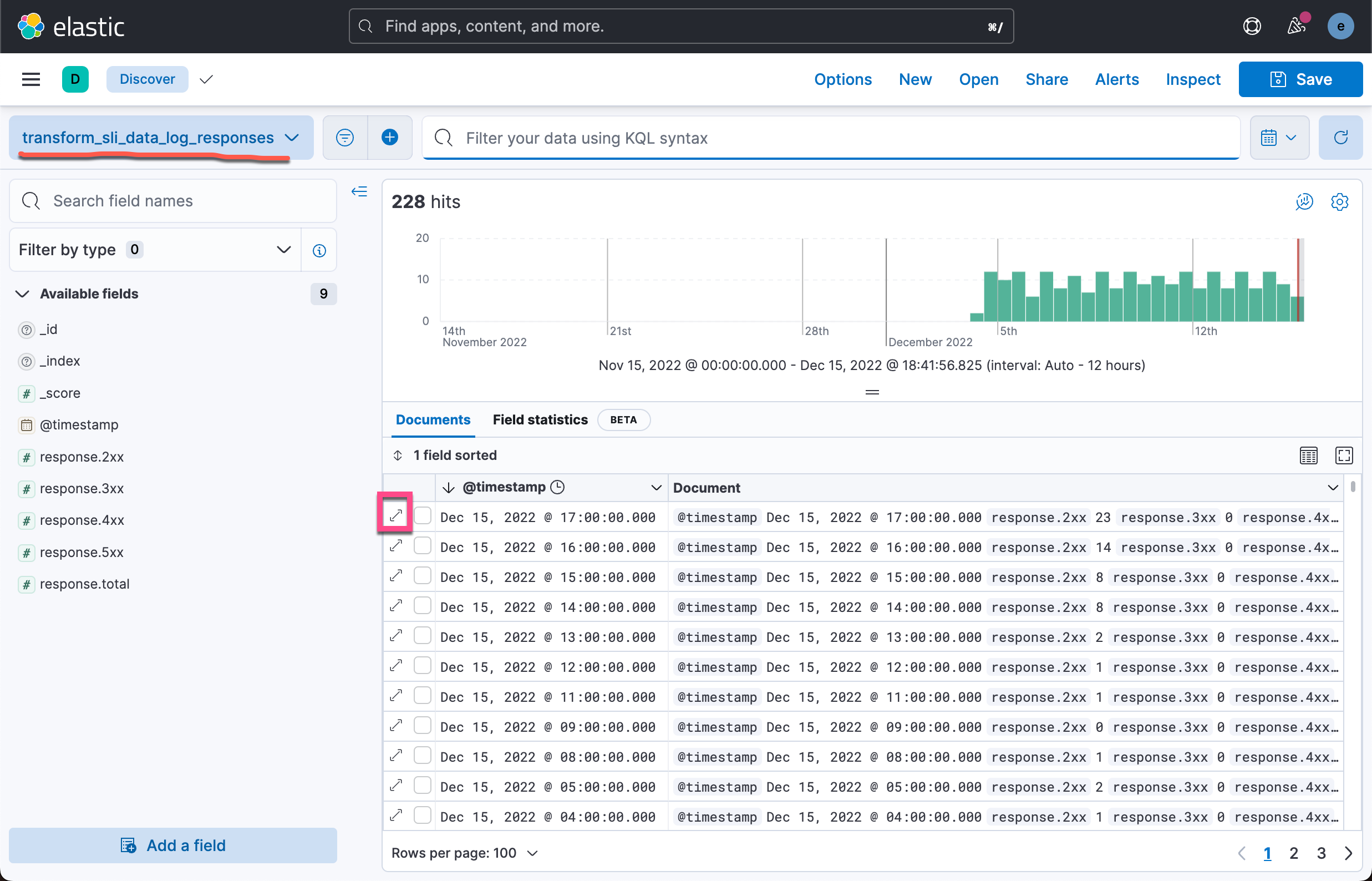

我们可以看到按照每个小时得出来的 response 代码的统计情况。
可视化
我们按照如下的步骤来进行可视化:

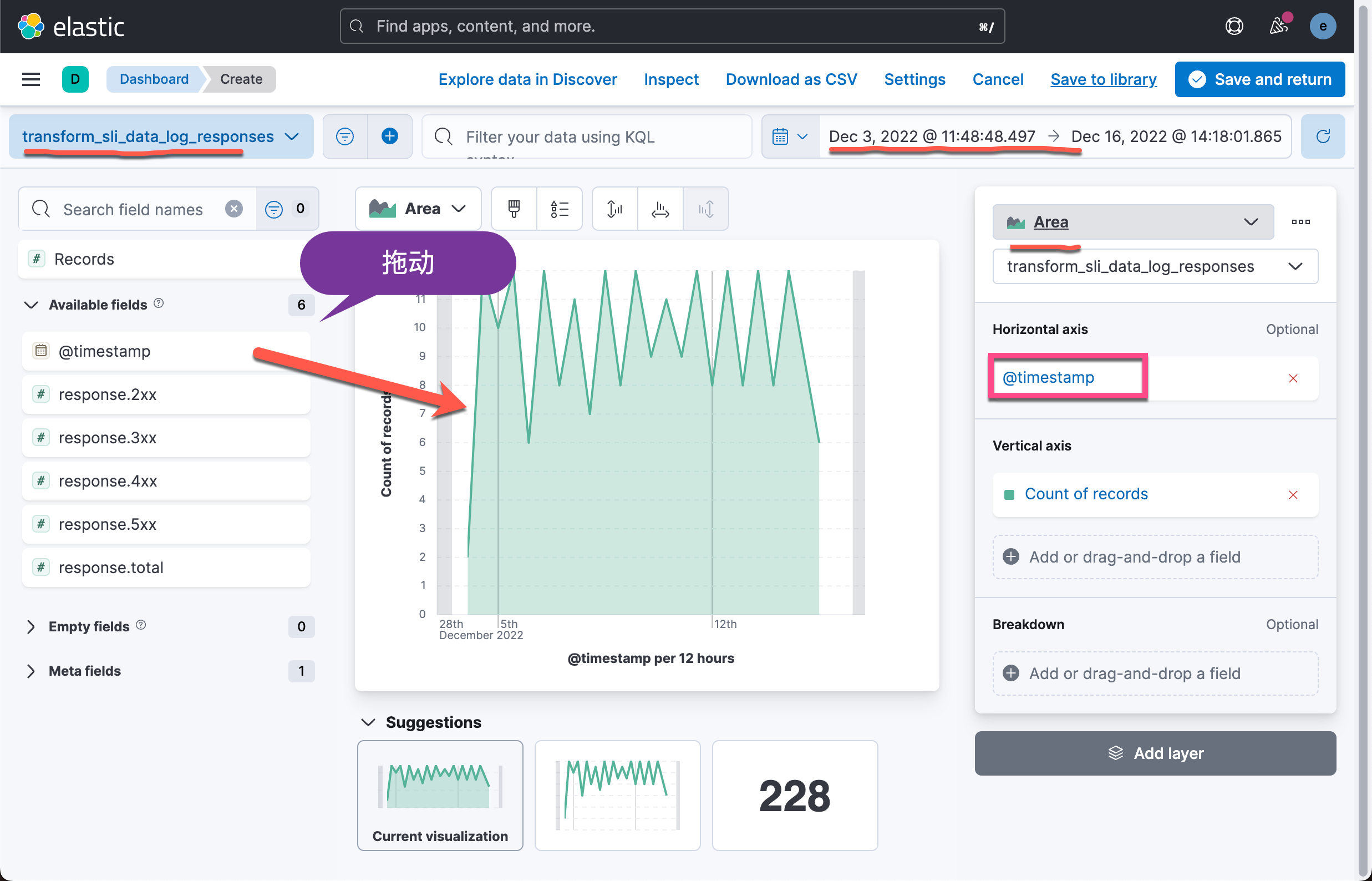
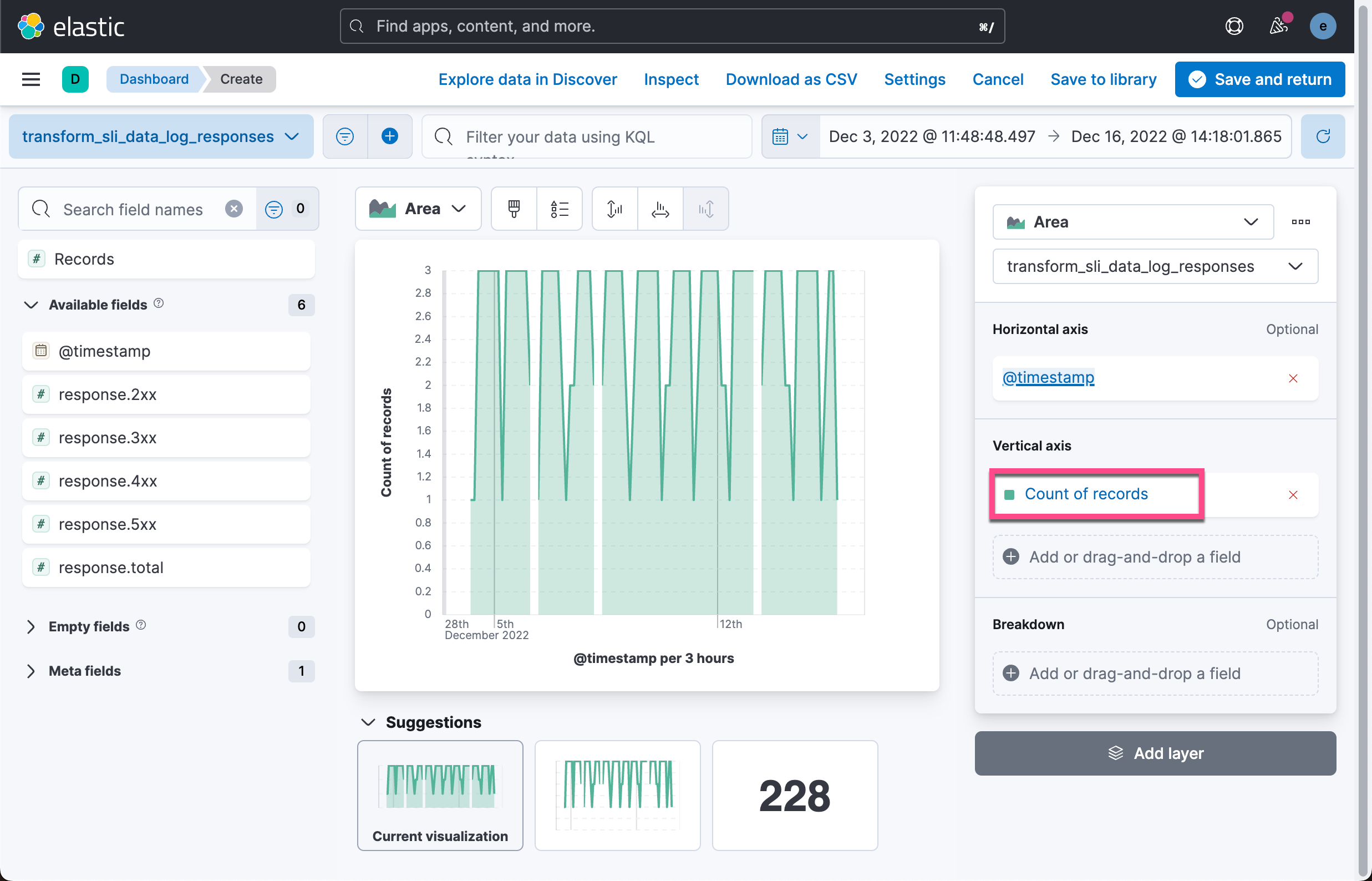
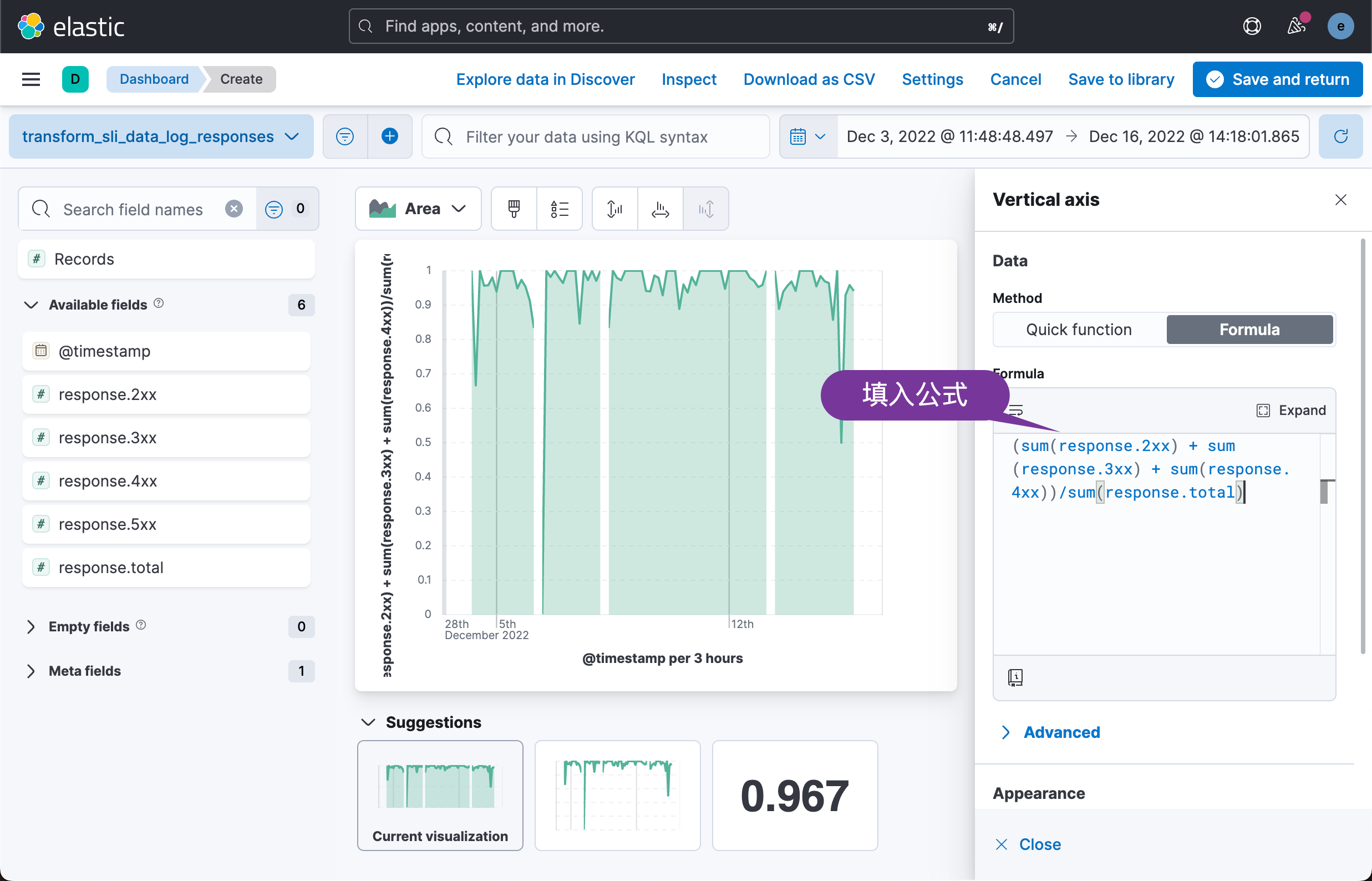
在上面,我们填入请求成功的公式:
(sum(response.2xx) + sum(response.3xx) + sum(response.4xx))/sum(response.total)
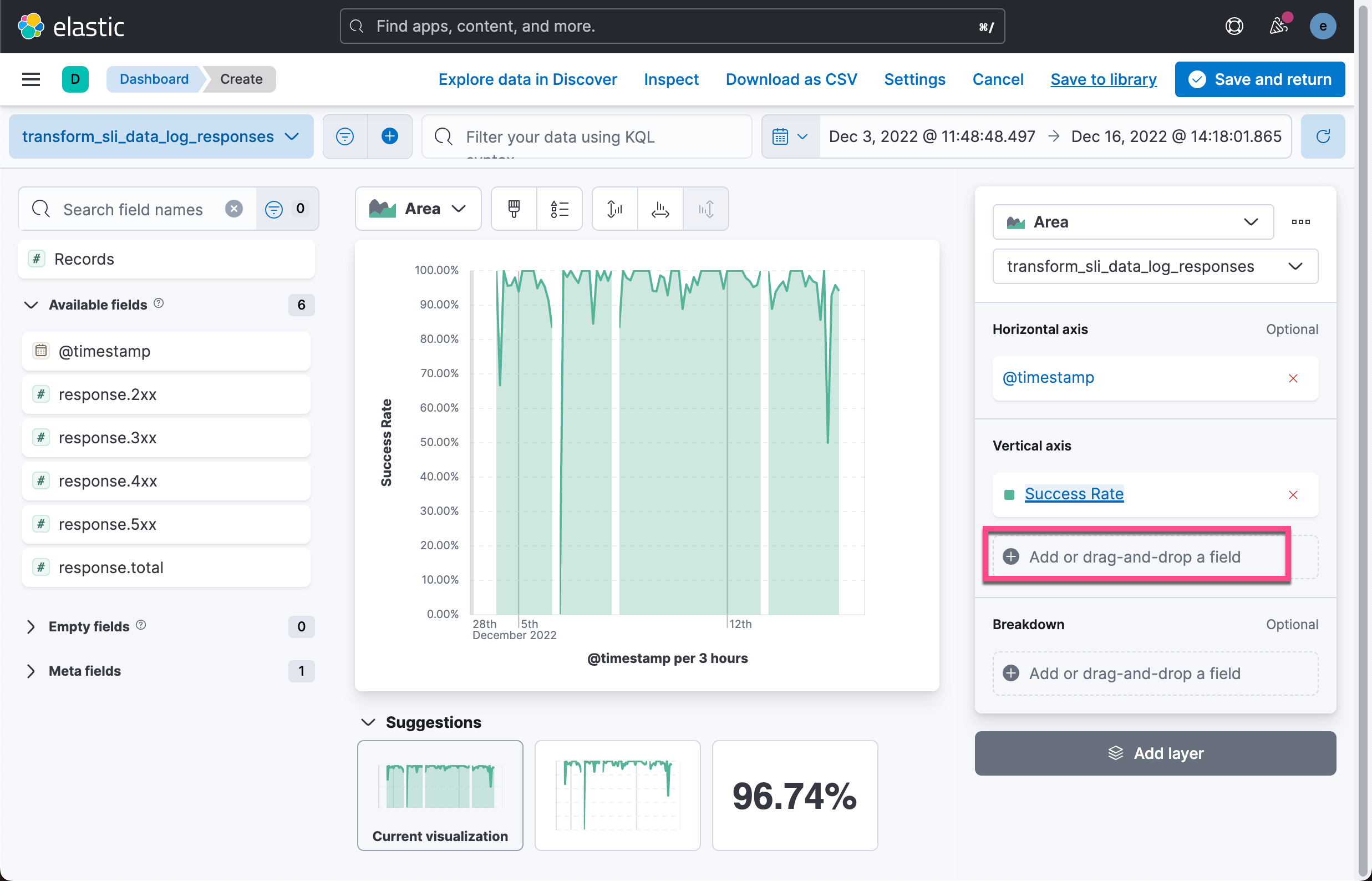
我们接下来为可视化再添加一个 Vertical axis:
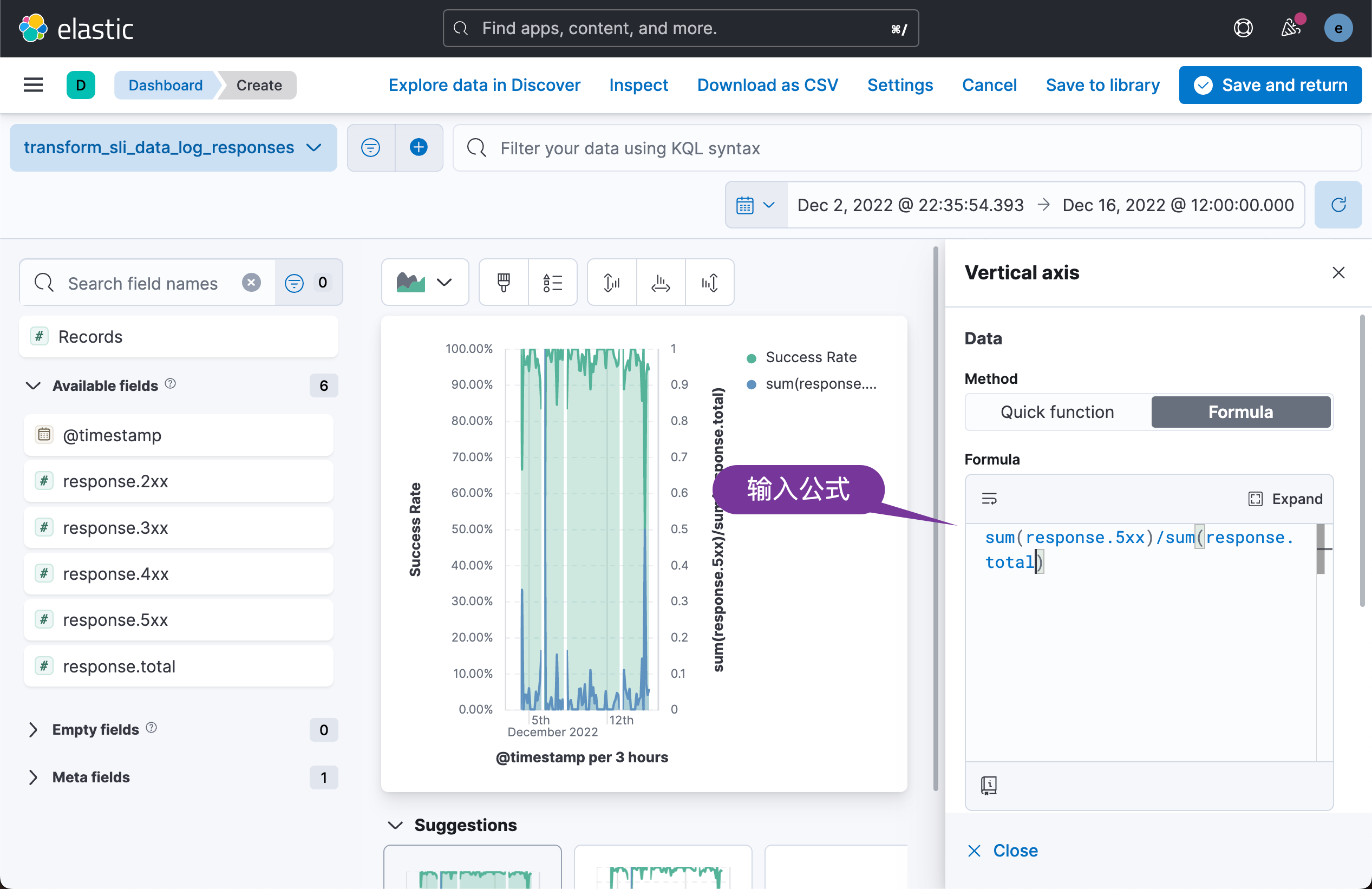
这次我们使用的公式是:
sum(response.5xx)/sum(response.total) 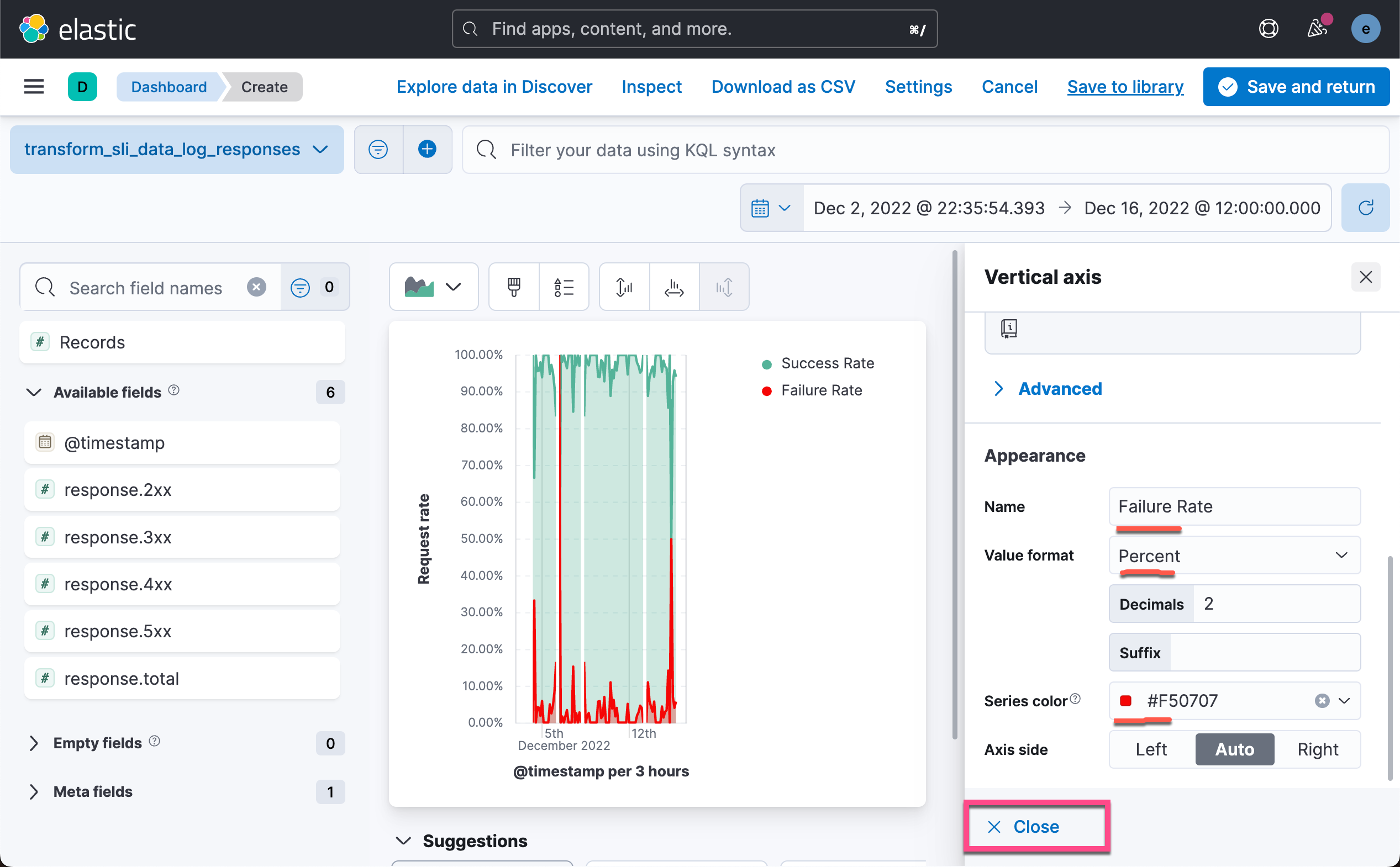

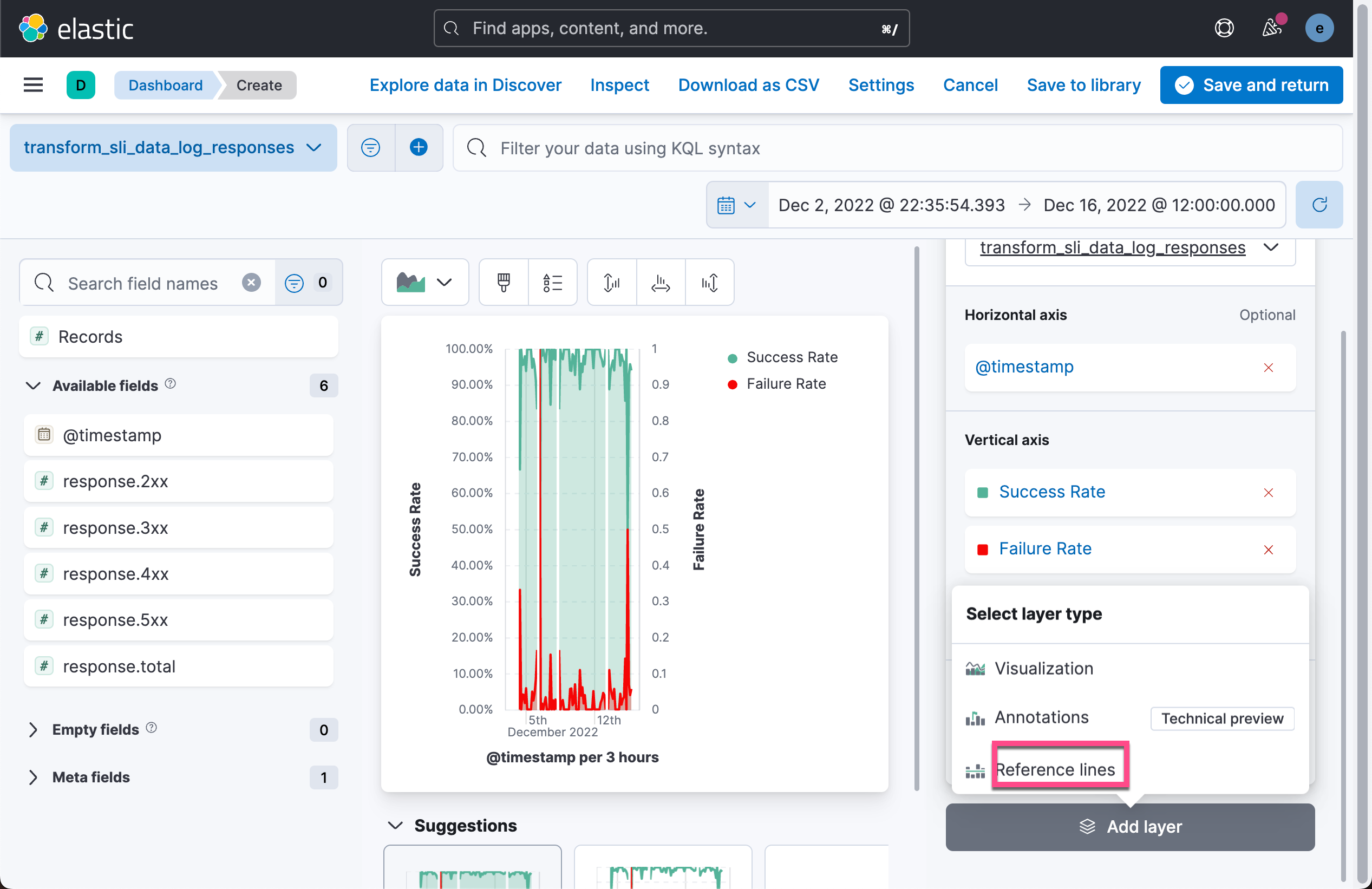
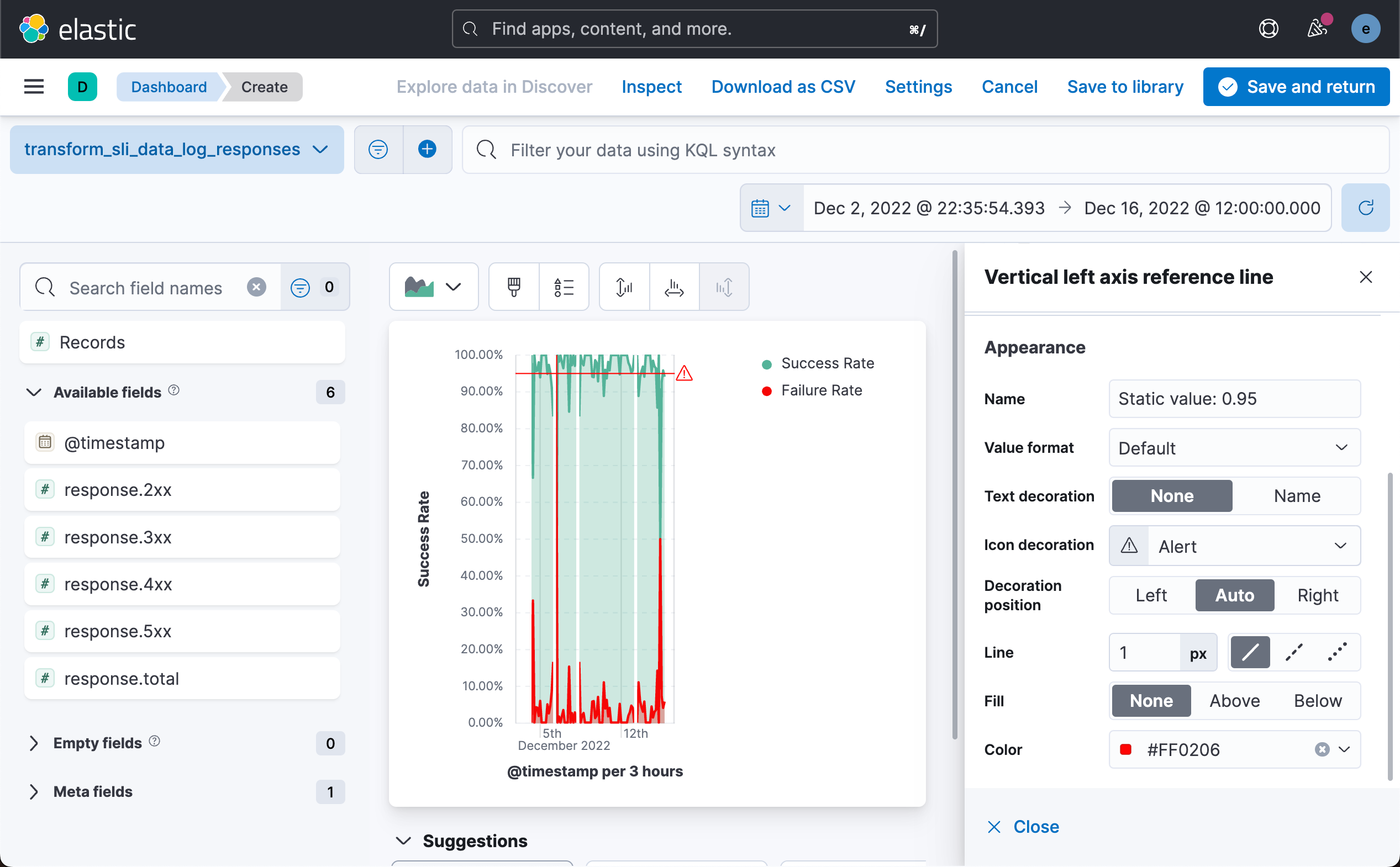
接下来,我们为可视化添加一个图层。我们想设置一个阈值作为我们的 SLO 目标线。我们按照如下的步骤来进行操作:


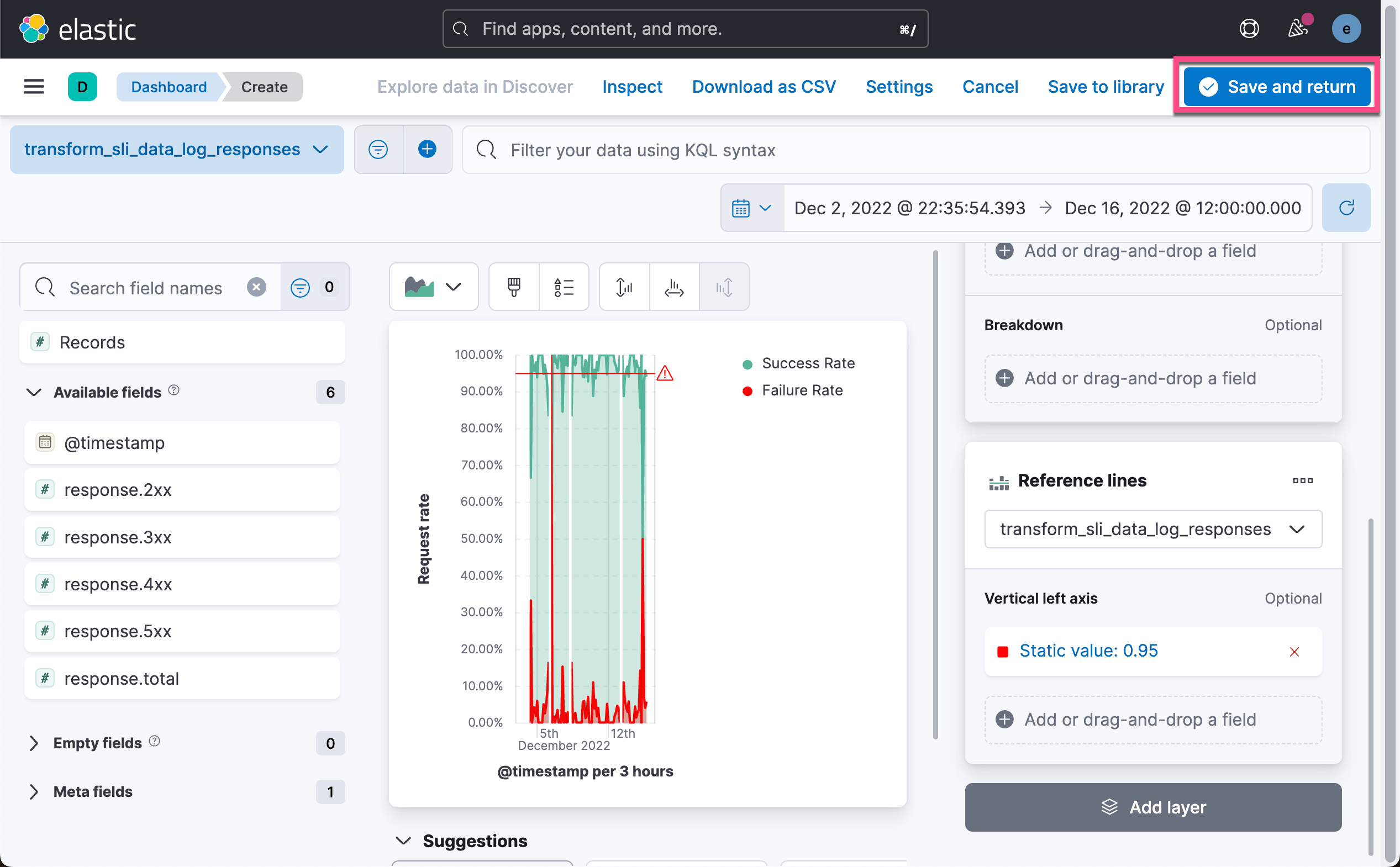
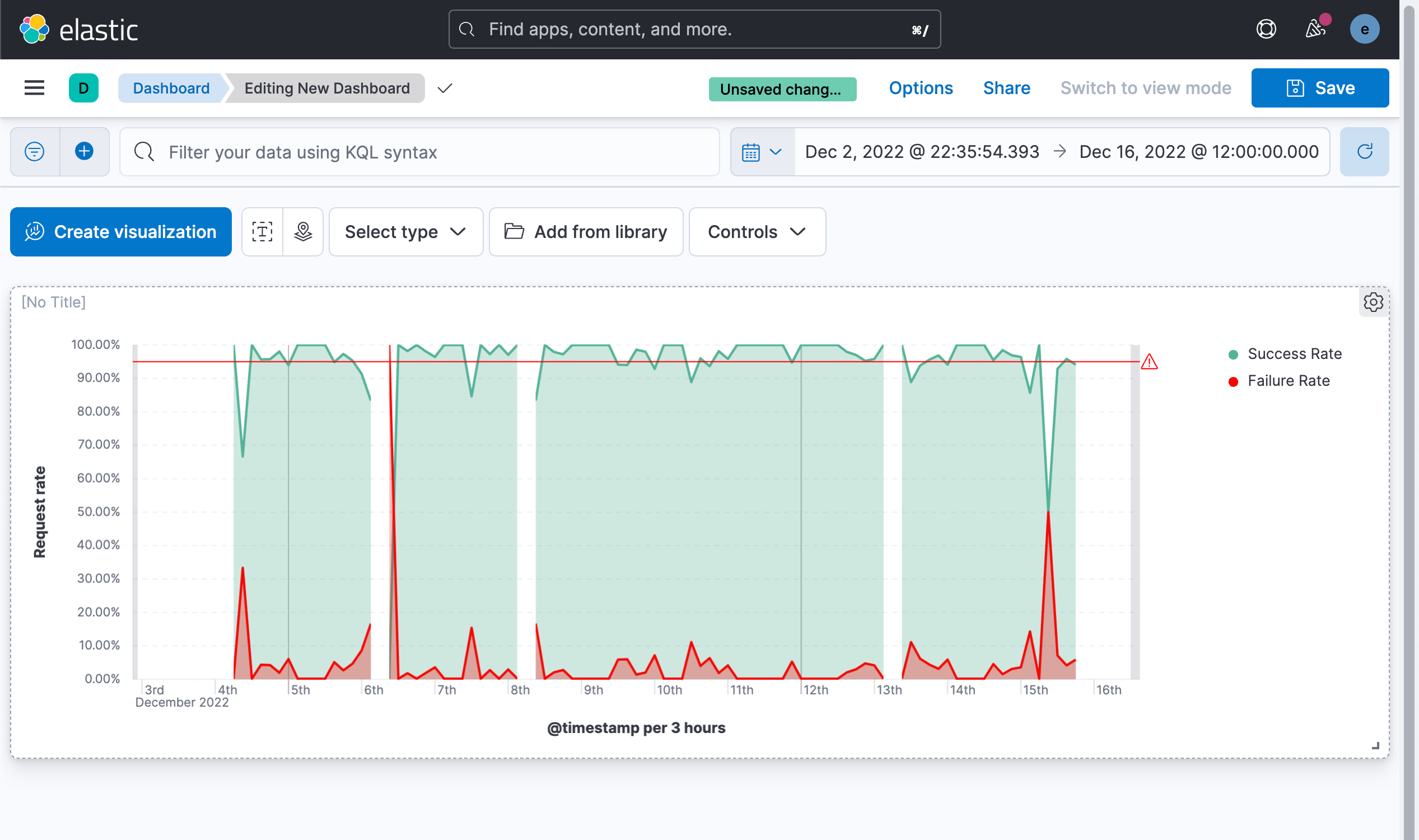
这样就得到了我们最终的可视化图。 从图中可以看出来,请求成功率超过 95% 的时间区域的分布以及请求失败的时间范围、