阅读目录
- Golang 数据类型介绍
- 整型
- 特殊整型
- unsafe.Sizeof 查看内存所占用大小
- int 不同长度直接的转换
- 数字字面量语法(Number literals syntax)(了解)
- 浮点型
- 布尔值
- 字符串
- 字符串转义符
- 多行字符串
- 字符串的常用操作
- 修改字符串
- byte 和 rune 类型
Golang 数据类型介绍
Go 语言中数据类型分为:基本数据类型和复合数据类型。
基本数据类型有:
整型、浮点型、布尔型、字符串。
复合数据类型有:
数组、切片、结构体、函数、map、通道(channel)、接口等。
整型
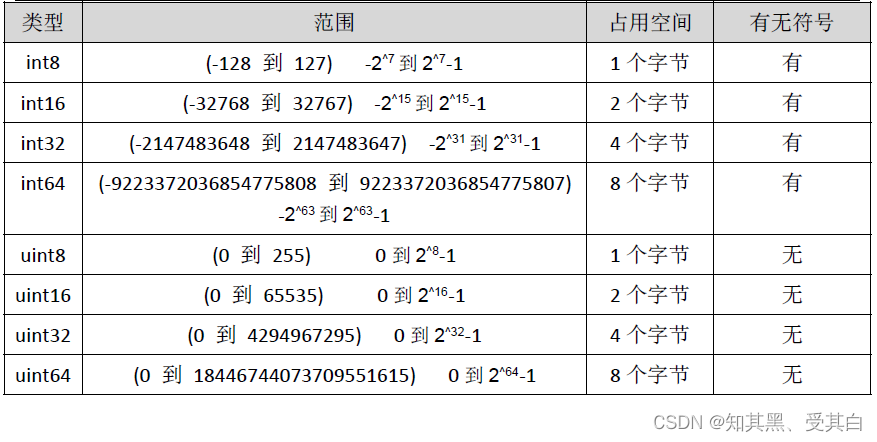
整型分为以下两个大类:
- 有符号整形按长度分为:
int8、int16、int32、int64 - 对应的无符号整型:
uint8、uint16、uint32、uint64
关于字节:字节也叫 Byte,是计算机数据的基本存储单位。
- 8bit(位)=1Byte(字节) 1024Byte(字节)=1KB
- 1024KB=1MB
- 1024MB=1GB
- 1024GB=1TB
在电脑里一个中文字是占两个字节的。
一个汉字 = 2字节,
中文标点占三个字节,
一个英文字母占一个字节,
英文标点占一个字节。
1字节(Byte)=8字位=8个二进制数。
特殊整型
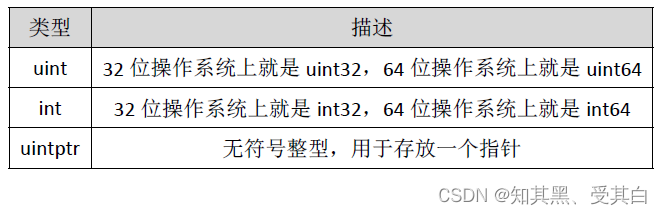
注意: 在使用 int 和 uint 类型时,不能假定它是32 位或64 位的整型,而是考虑 int 和 uint 可能在不同平台上的差异。
注意事项:实际项目中整数类型、切片、map 的元素数量等都可以用 int 来表示。在涉及到二进制传输、为了保持文件的结构不会受到不同编译目标平台字节长度的影响,不要使用 int 和 uint。
package main
import (
"fmt"
)
func main() {
var num int64
num = 123
fmt.Printf("值:%v 类型%T", num, num)
// 值:123 类型int64
}
unsafe.Sizeof 查看内存所占用大小
unsafe.Sizeof(n1) 是 unsafe 包的一个函数,可以返回 n1 变量占用的字节数。
package main
import (
"fmt"
"unsafe"
)
func main() {
var a int8 = 120
fmt.Printf("%T\n", a)
fmt.Println(unsafe.Sizeof(a))
/*
running...
int8
1
*/
}
int 不同长度直接的转换
package main
import (
"fmt"
)
func main() {
var num1 int8
num1 = 127
num2 := int32(num1)
//值:127 类型int32
fmt.Printf("值:%v 类型%T", num2, num2)
}
数字字面量语法(Number literals syntax)(了解)
Go1.13 版本之后引入了数字字面量语法,这样便于开发者以二进制、八进制或十六进制浮点数的格式定义数字,例如:
v := 0b00101101, 代表二进制的 101101,相当于十进制的 45。v := 0o377,代表八进制的 377,相当于十进制的 255。v := 0x1p-2,代表十六进制的 1 除以 2²,也就是0.25。而且还允许我们用 _ 来分隔数字,比如说:
v := 123_456 等于123456。
我们可以借助 fmt 函数来将一个整数以不同进制形式展示。
package main
import "fmt"
func main() {
// 十进制
var a int
a = 10
fmt.Printf("%d \n", a) // 10
fmt.Printf("%b \n", a) // 1010 占位符%b 表示二进制
// 八进制以0 开头
var b int
b = 077
fmt.Printf("%o \n", b) // 77
// 十六进制以0x 开头
var c int
c = 0xff
fmt.Printf("%x \n", c) // ff
fmt.Printf("%X \n", c) // FF
fmt.Printf("%d \n", c) // 255
}
浮点型
Go 语言支持两种浮点型数:float32 和 float64。这两种浮点型数据格式遵循 IEEE 754 标准:
float32 的浮点数的最大范围约为3.4e38,可以使用常量定义:math.MaxFloat32。
float64 的 浮点数的最大范围约为 1.8e308,可以使用一个常量定义:math.MaxFloat64。
打印浮点数时,可以使用 fmt 包配合动词 %f,代码如下:
package main
import (
"fmt"
"math"
)
func main() {
fmt.Printf("%f\n", math.Pi) //默认保留6 位小数
fmt.Printf("%.2f\n", math.Pi) //保留2 位小数
}
Go 语言中浮点数默认是 float64。
num := 1.1
//值:1.1--类型:float64
fmt.Printf("值:%v--类型:%T", num, num)
Golang 中 float 精度丢失问题。
几乎所有的编程语言都有精度丢失这个问题,这是典型的二进制浮点数精度损失问题,在定长条件下,二进制小数和十进制小数互转可能有精度丢失。
d := 1129.6
fmt.Println((d * 100)) //输出:112959.99999999999
var d float64 = 1129.6
fmt.Println((d * 100)) //输出:112959.99999999999
m1 := 8.2
m2 := 3.8
// 期望是4.4,结果打印出了4.399999999999999
fmt.Println(m1 - m2)
使用第三方包来解决精度损失问题:https://github.com/shopspring/decimal
Golang 科学计数法表示浮点类型
num8 := 5.1234e2 // ? 5.1234 * 10 的2 次方
// ? 5.1234 * 10 的2 次方shift+alt+向下的箭头
num9 := 5.1234E2
// ? 5.1234 / 10 的2 次方0.051234
num10 := 5.1234E-2
fmt.Println("num8=", num8, "num9=", num9, "num10=", num10)
布尔值
Go 语言中以 bool 类型进行声明布尔型数据,布尔型数据只有 true(真)和 false(假)两个值。
注意:
1、 布尔类型变量的默认值为false。
2、Go 语言中不允许将整型强制转换为布尔型.
3、布尔型无法参与数值运算,也无法与其他类型进行转换。
package main
import (
"fmt"
"unsafe"
)
func main() {
var b = true
fmt.Println(b, "占用字节:", unsafe.Sizeof(b))
// true 占用字节: 1
}
字符串
Go 语言中的字符串以原生数据类型出现,使用字符串就像使用其他原生数据类型(int、bool、float32、float64 等)一样。
Go 语言里的字符串的内部实现使用UTF-8 编码。
字符串的值为双引号 (") 中的内容,可以在Go 语言的源码中直接添加非ASCII 码字符,例如:
s1 := "hello"
s2 := "你好"
字符串转义符
Go 语言的字符串常见转义符包含回车、换行、单双引号、制表符等,如下表所示。
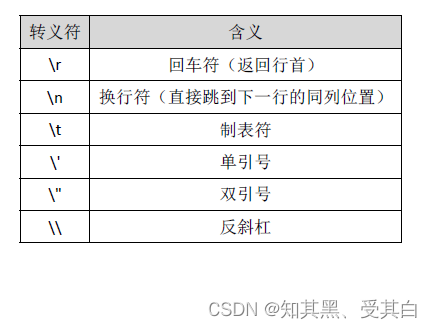
举个例子,我们要打印一个Windows 平台下的一个文件路径:
package main
import (
"fmt"
)
func main() {
fmt.Println("str := \"c:\\Code\\demo\\go.exe\"")
//str := "c:\Code\demo\go.exe"
}
多行字符串
Go 语言中要定义一个多行字符串时,就必须使用反引号字符:
s1 := `第一行
第二行
第三行`
fmt.Println(s1)
反引号间换行将被作为字符串中的换行,但是所有的转义字符均无效,文本将会原样输出。
字符串的常用操作
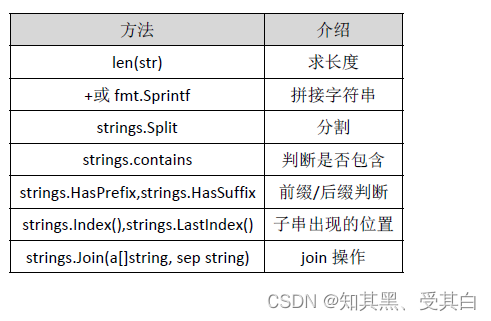
len(str)求字符串的长度。
var str = "this is str"
fmt.Println(len(str))
拼接字符串。
var str1 = "你好"
var str2 = "golang"
fmt.Println(str1 + str2)
var str3 = fmt.Sprintf("%v %v", str1, str2)
fmt.Println(str3)
strings.Split 分割字符串。
var str = "123-456-789"
var arr = strings.Split(str, "-")
fmt.Println(arr)
拼接字符串,
var str = "this is golang"
var flag = strings.Contains(str, "golang")
fmt.Println(flag)
判断首字符尾字母是否包含指定字符。
var str = "this is golang"
var flag = strings.HasPrefix(str, "this")
fmt.Println(flag)
var str = "this is golang"
var flag = strings.HasSuffix(str, "go")
fmt.Println(flag)
判断字符串出现的位置。
var str = "this is golang"
var index = strings.Index(str, "is") //从前往后
fmt.Println(index)
var str = "this is golang"
var index = strings.LastIndex(str, "is") //从后网前
fmt.Println(index)
Join 拼接字符串。
var str = "123-456-789"
var arr = strings.Split(str, "-")
var str2 = strings.Join(arr, "*")
fmt.Println(str2)
修改字符串
要修改字符串,需要先将其转换成[]rune 或[]byte,完成后再转换为string。无论哪种转换,都会重新分配内存,并复制字节数组。
// 遍历字符串
package main
import "fmt"
func changeString() {
s1 := "big"
// 强制类型转换
byteS1 := []byte(s1)
byteS1[0] = 'p'
fmt.Println(string(byteS1))
s2 := "白萝卜"
runeS2 := []rune(s2)
runeS2[0] = '红'
fmt.Println(string(runeS2))
}
func main() {
changeString()
// pig
// 红萝卜
}
byte 和 rune 类型
组成每个字符串的元素叫做“字符”,可以通过遍历字符串元素获得字符。字符用单引号 (’) 包裹起来,如:
package main
import "fmt"
func main() {
a := 'a'
b := '0'
//当我们直接输出byte(字符)的时候输出的是这个字符对应的码值
fmt.Println(a)
fmt.Println(b)
//如果我们要输出这个字符,需要格式化输出
fmt.Printf("%c--%c", a, b)
//%c 相应Unicode 码点所表示的字符
}
字节(byte):是计算机中数据处理的基本单位,习惯上用大写 B 来表示,1B(byte,字节)= 8bit(位)字符:是指计算机中使用的字母、数字、字和符号一个汉子占用3 个字节一个字母占用一个字节。
a := "m"
fmt.Println(len(a)) //1
b := "张"
fmt.Println(len(b)) //3
Go 语言的字符有以下两种:
1、uint8 类型,或者叫 byte 型,代表了ASCII 码的一个字符。
2、rune 类型,代表一个UTF-8 字符。
当需要处理中文、日文或者其他复合字符时,则需要用到 rune 类型。rune 类型实际是一个 int32。
Go 使用了特殊的 rune 类型来处理Unicode,让基于 Unicode 的文本处理更为方便,也可以使用 byte 型进行默认字符串处理,性能和扩展性都有照顾。
// 遍历字符串
package main
import "fmt"
func main() {
s := "hello 张三"
for i := 0; i < len(s); i++ {
//byte
fmt.Printf("%v(%c) ", s[i], s[i])
}
fmt.Println()
for _, r := range s {
//rune
fmt.Printf("%v(%c) ", r, r)
}
fmt.Println()
}

因为UTF8 编码下一个中文汉字由3 个字节组成,所以我们不能简单的按照字节去遍历一个包含中文的字符串,否则就会出现上面输出中第一行的结果。
字符串底层是一个byte 数组,所以可以和[ ]byte 类型相互转换。字符串是不能修改的字符串是由 byte 字节组成,所以字符串的长度是 byte 字节的长度。
rune 类型用来表示utf8 字符,一个rune 字符由一个或多个byte 组成。
rune 类型实际是一个int32
c3 := "营"
c4 := '营'
fmt.Printf("C3 的类型%T--C4 的类型%T", c3, c4)
//C3 的类型string--C4 的类型int32