前言:Hello大家好,我是小哥谈。注意力机制是近年来深度学习领域内的研究热点,可以帮助模型更好地关注重要的特征,从而提高模型的性能。在许多视觉任务中,输入数据通常由多个通道组成,例如图像中的RGB通道或视频中的时间序列帧。传统的卷积神经网络(CNN)在处理这些通道时通常是独立地对每个通道进行操作,忽略了通道之间的相互作用。CA注意力机制通过引入通道注意力来解决这个问题。它能够自动学习到不同通道之间的关联性和重要性,从而增强模型对输入数据的建模能力。具体来说,CA注意力机制通过计算每个通道的权重,使得模型能够更加关注重要的通道,并抑制不重要的通道。这样可以提高模型在处理多通道输入数据时的表达能力和性能。🌈
![]() 前期回顾:
前期回顾:
YOLOv5算法改进(1)— 如何去改进YOLOv5算法
YOLOv5算法改进(2)— 添加SE注意力机制
YOLOv5算法改进(3)— 添加CBAM注意力机制
目录
🚀1.论文
🚀2.CA注意力机制的原理及实现
🚀3.添加CA注意力机制的好处
🚀4.添加CA注意力机制的方法
💥💥步骤1:在common.py中添加CA模块
💥💥步骤2:在yolo.py文件中加入类名
💥💥步骤3:创建自定义yaml文件
💥💥步骤4:修改yolov5s_CA.yaml文件
💥💥步骤5:验证是否加入成功
💥💥步骤6:修改train.py中的'--cfg'默认参数
🚀5.添加C3_CA注意力机制的方法(在C3模块中添加)
💥💥步骤1:在common.py中添加CABottleneck和C3_CA模块
💥💥步骤2:在yolo.py文件里parse_model函数中加入类名
💥💥步骤3:创建自定义yaml文件
💥💥步骤4:验证是否加入成功
💥💥步骤5:修改train.py中的'--cfg'默认参数

🚀1.论文
目前,轻量级网络的注意力机制大都采用 SE 模块,仅考虑了通道间的信息,忽略了位置信息。尽管后来的 BAM 和 CBAM 尝试在降低通道数后通过卷积来提取位置注意力信息,但卷积只能提取局部关系,缺乏长距离关系提取的能力。为此,论文提出了新的高效注意力机制CA(coordinate attention),能够将横向和纵向的位置信息编码到 channel attention 中,使得移动网络能够关注大范围的位置信息又不会带来过多的计算量。🌴

论文题目:Coordinate Attention for Efficient Mobile Network Design
论文地址:https://arxiv.org/abs/2103.02907
代码实现:GitHub - houqb/CoordAttention: Code for our CVPR2021 paper coordinate attention
🚀2.CA注意力机制的原理及实现
CA(Channel Attention)注意力机制是一种在深度学习中常用的注意力机制之一,用于增强模型对于不同通道(channel)之间的特征关联性。📚
其原理如下:👇
(1)输入特征经过卷积等操作得到中间特征表示。
(2)中间特征表示经过两个并行的操作:全局平均池化和全局最大池化,得到全局特征描述。
(3)全局特征描述通过两个全连接层生成注意力权重。
(4)注意力权重与中间特征表示相乘,得到加权后的特征表示。
(5)加权后的特征表示经过适当的调整(如残差连接)后,作为下一层的输入。
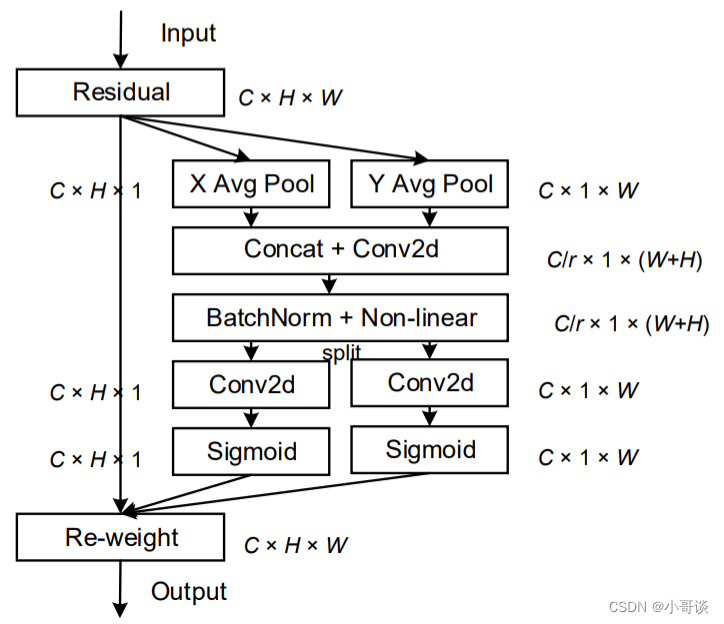
CA注意力的实现如图所示,可以认为分为两个并行阶段:
将输入特征图分别在为宽度和高度两个方向分别进行全局平均池化,分别获得在宽度和高度两个方向的特征图。假设输入进来的特征层的形状为[C, H, W],在经过宽方向的平均池化后,获得的特征层shape为[C, H, 1],此时我们将特征映射到了高维度上;在经过高方向的平均池化后,获得的特征层shape为[C, 1, W],此时我们将特征映射到了宽维度上。
然后将两个并行阶段合并,将宽和高转置到同一个维度,然后进行堆叠,将宽高特征合并在一起,此时我们获得的特征层为:[C, 1, H+W],利用卷积+标准化+激活函数获得特征。
之后再次分开为两个并行阶段,再将宽高分开成为:[C, 1, H]和[C, 1, W],之后进行转置。获得两个特征层[C, H, 1]和[C, 1, W]。
然后利用1x1卷积调整通道数后取sigmoid获得宽高维度上的注意力情况,乘上原有的特征就是CA注意力机制。✅
🚀3.添加CA注意力机制的好处
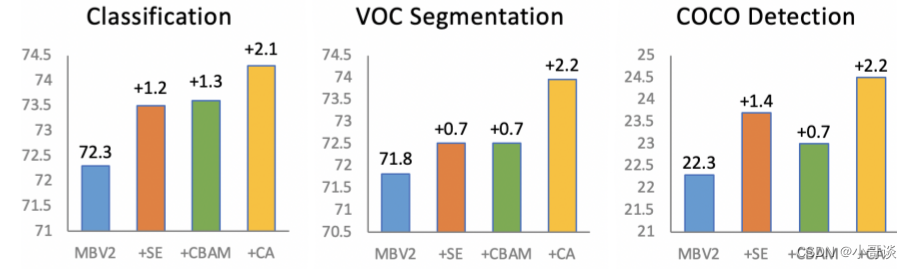
作者通过将位置信息嵌入到通道注意力中提出了一种新颖的移动网络注意力机制,将其称为“Coordinate Attention”。其为即插即用的注意力模块,能插入任何经典网络。🍉
加入CA注意力机制的好处包括:
(1)增强特征表达:CA注意力机制能够自适应地选择和调整不同通道的特征权重,从而更好地表达输入数据。它可以帮助模型发现和利用输入数据中重要的通道信息,提高特征的判别能力和区分性。
(2)减少冗余信息:通过抑制不重要的通道,CA注意力机制可以减少输入数据中的冗余信息,提高模型对关键特征的关注度。这有助于降低模型的计算复杂度,并提高模型的泛化能力。
(3)提升模型性能:加入CA注意力机制可以显著提高模型在多通道输入数据上的性能。它能够帮助模型更好地捕捉到通道之间的相关性和依赖关系,从而提高模型对输入数据的理解能力。
综上所述,加入CA注意力机制可以有效地增强模型对多通道输入数据的建模能力,提高模型性能和泛化能力。它在图像处理、视频分析等任务中具有重要的应用价值。🌿
🚀4.添加CA注意力机制的方法
💥💥步骤1:在common.py中添加CA模块
将下面的CA模块的代码复制粘贴到common.py文件的末尾。
# CA
class h_sigmoid(nn.Module):
def __init__(self, inplace=True):
super(h_sigmoid, self).__init__()
self.relu = nn.ReLU6(inplace=inplace)
def forward(self, x):
return self.relu(x + 3) / 6
class h_swish(nn.Module):
def __init__(self, inplace=True):
super(h_swish, self).__init__()
self.sigmoid = h_sigmoid(inplace=inplace)
def forward(self, x):
return x * self.sigmoid(x)
class CoordAtt(nn.Module):
def __init__(self, inp, oup, reduction=32):
super(CoordAtt, self).__init__()
self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.pool_w = nn.AdaptiveAvgPool2d((1, None))
mip = max(8, inp // reduction)
self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(mip)
self.act = h_swish()
self.conv_h = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
self.conv_w = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
def forward(self, x):
identity = x
n, c, h, w = x.size()
#c*1*W
x_h = self.pool_h(x)
#c*H*1
#C*1*h
x_w = self.pool_w(x).permute(0, 1, 3, 2)
y = torch.cat([x_h, x_w], dim=2)
#C*1*(h+w)
y = self.conv1(y)
y = self.bn1(y)
y = self.act(y)
x_h, x_w = torch.split(y, [h, w], dim=2)
x_w = x_w.permute(0, 1, 3, 2)
a_h = self.conv_h(x_h).sigmoid()
a_w = self.conv_w(x_w).sigmoid()
out = identity * a_w * a_h
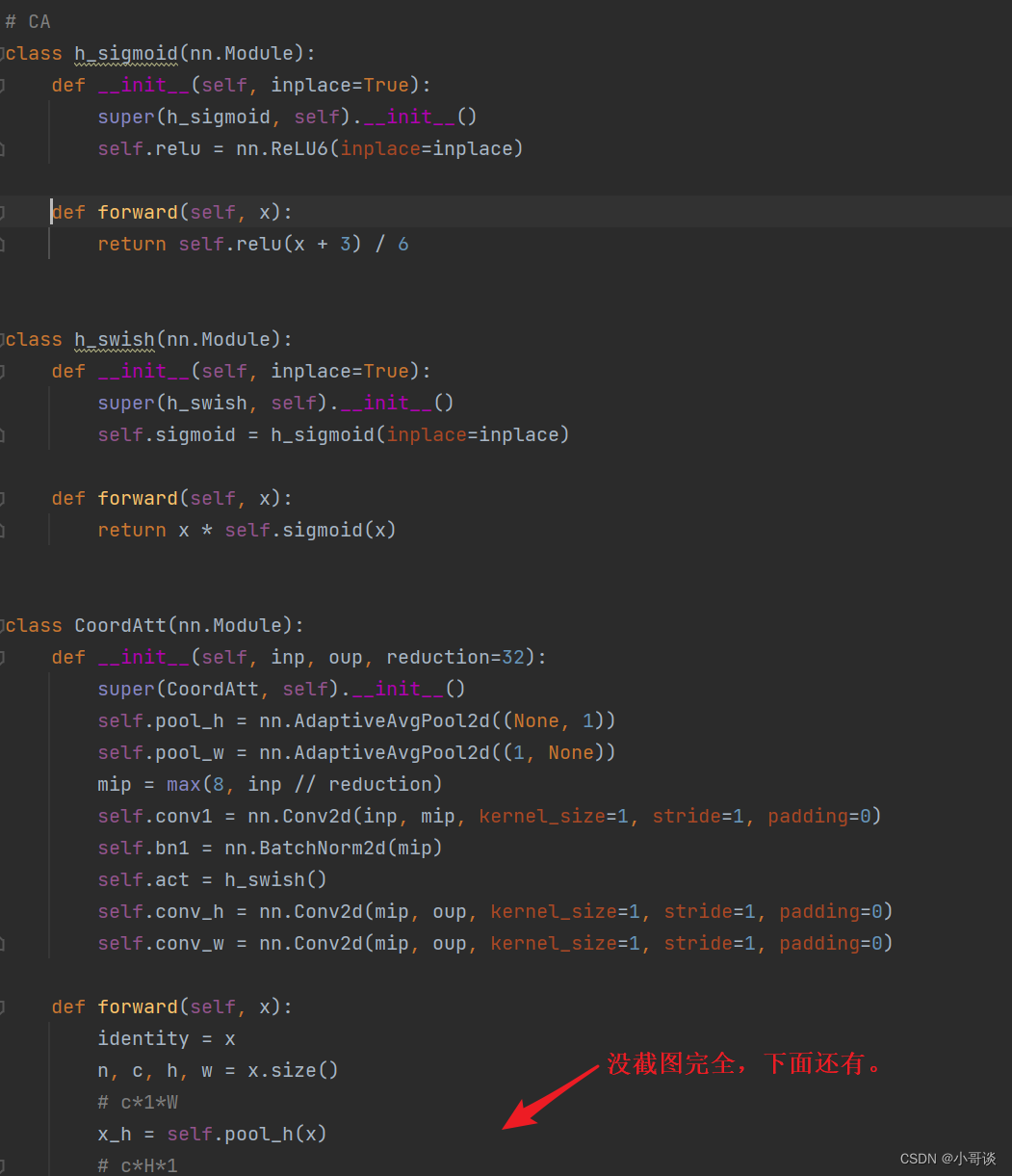
return out具体如下图所示:
💥💥步骤2:在yolo.py文件中加入类名
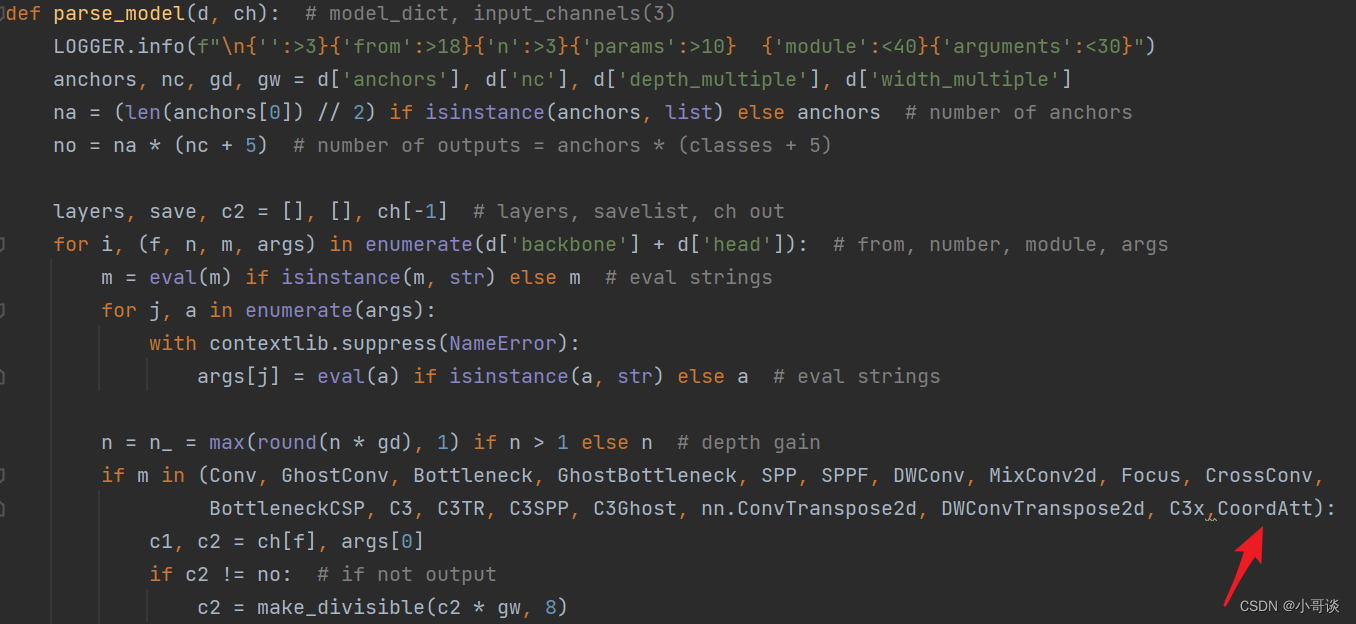
首先在yolo.py文件中找到parse_model函数,然后将 CoordAtt 添加到这个注册表里。
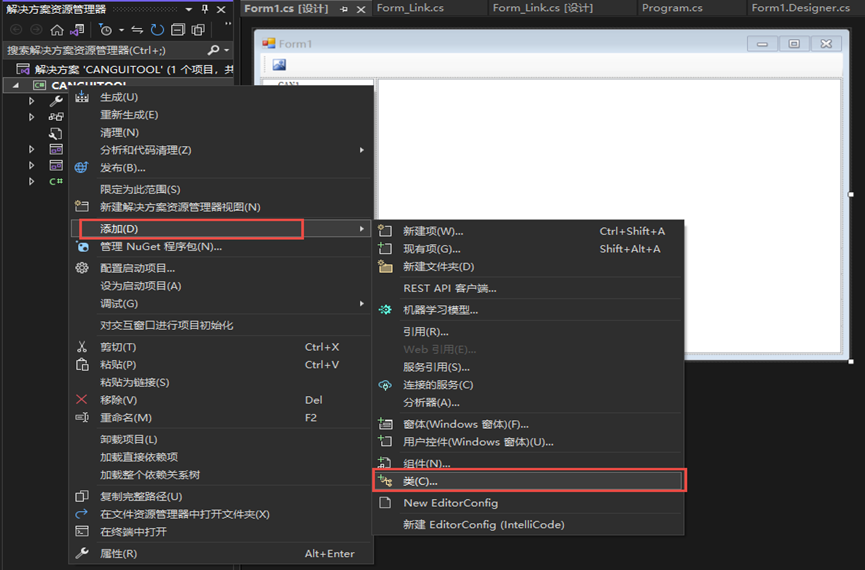
💥💥步骤3:创建自定义yaml文件
在models文件夹中复制yolov5s.yaml,粘贴并命名为yolov5s_CA.yaml。
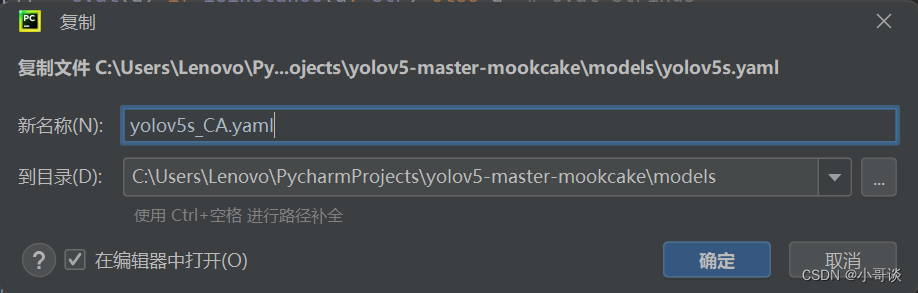
💥💥步骤4:修改yolov5s_CA.yaml文件
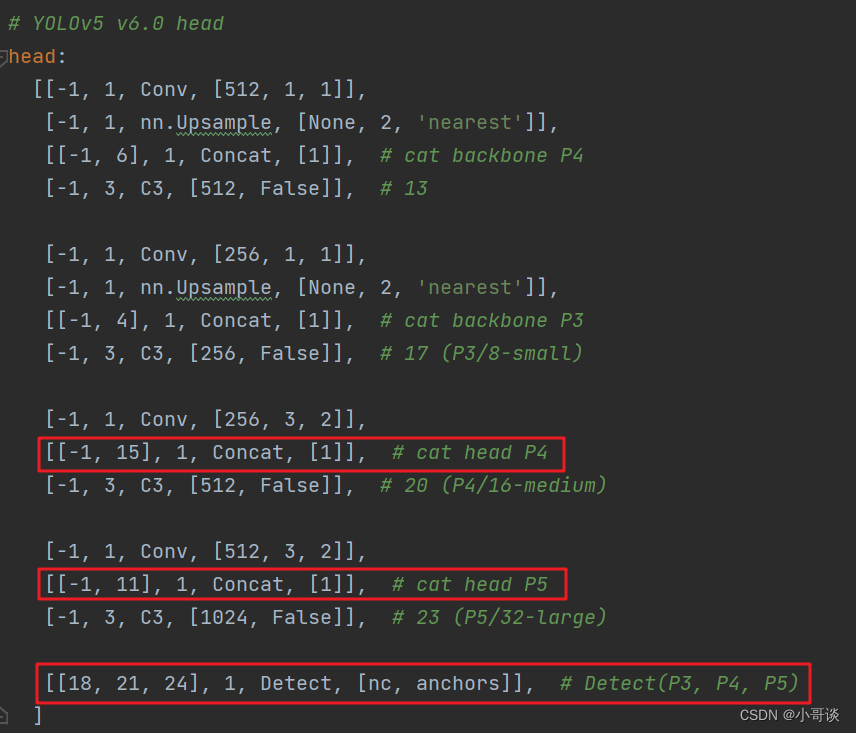
本步骤是修改yolov5s_CA.yaml,将CA模块添加到我们想添加的位置。在这里,我将[-1,1,CoordAtt,[1024]]添加到SPPF的上一层,即下图中所示位置。

说明:♨️♨️♨️
注意力机制可以加在Backbone、Neck、Head等部分,常见的有两种:一种是在主干的SPPF前面添加一层;二是将Backbone中的C3全部替换。不同的位置效果可能不同,需要我们去反复测试。
这里需要注意一个问题,当在网络中添加新的层之后,那么该层网络后面的层的编号会发生变化。原本Detect指定的是[17,20,23]层,所以,我们在添加了CA模块之后,也要对这里进行修改,即原来的17层,变成18层,原来的20层,变成21层,原来的23层,变成24层;所以这里需要改为[18,21,24]。同样的,Concat的系数也要修改,这样才能保持原来的网络结构不会发生特别大的改变,我们刚才把CA模块加到了第9层,所以第9层之后的编号都需要加1,这里我们把后面两个Concat的系数分别由[-1,14],[-1,10]改为[-1,15],[-1,11]。🌻
具体如下图所示:
💥💥步骤5:验证是否加入成功
在yolo.py文件里,将配置改为我们刚才自定义的yolov5s_CA.yaml。


然后运行yolo.py,得到结果。

找到了CA模块,说明我们添加成功了。🎉🎉🎉
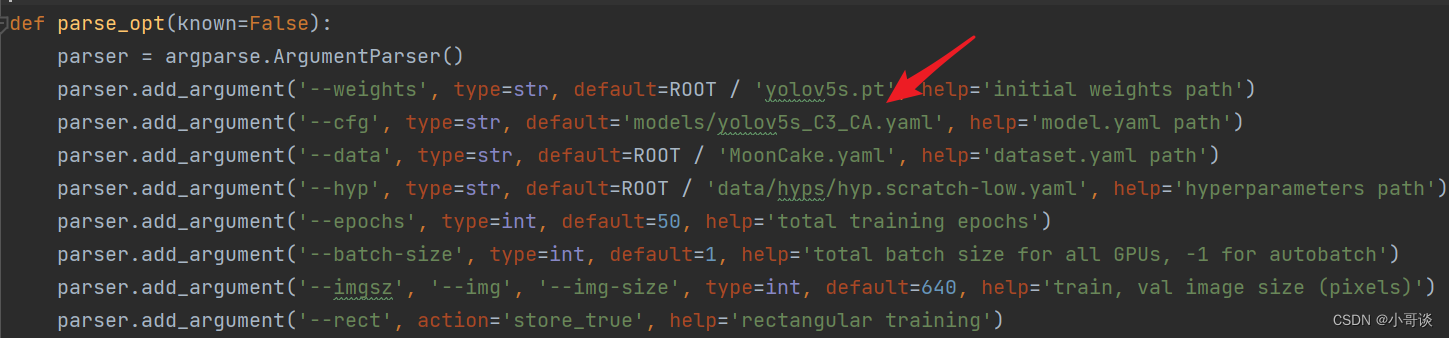
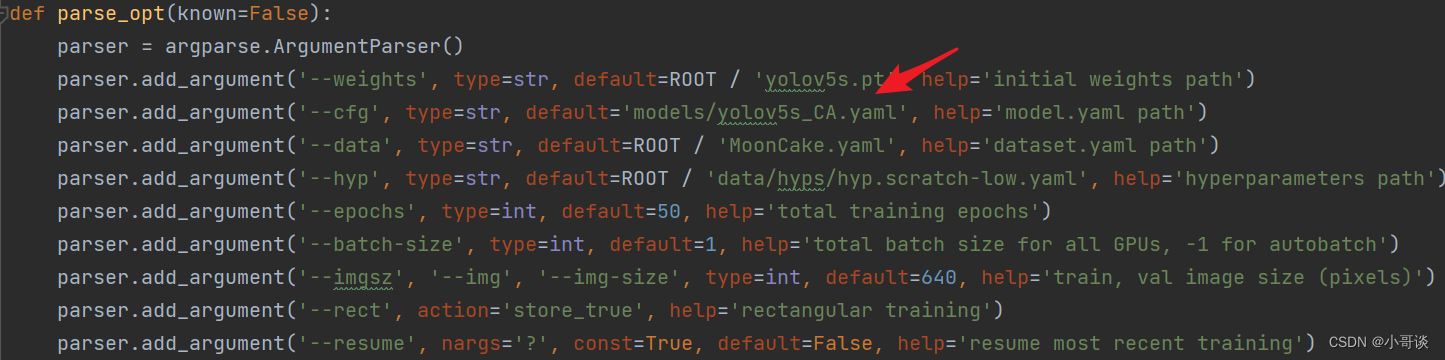
💥💥步骤6:修改train.py中的'--cfg'默认参数
在train.py文件中找到 parse_opt函数,然后将第二行'--cfg'的default改为 'models/yolov5s_CA.yaml',然后就可以开始进行训练了。🎈🎈🎈
🚀5.添加C3_CA注意力机制的方法(在C3模块中添加)
上面是单独添加注意力层,接下来的方法是在C3模块中加入注意力层。这个策略是将CA注意力机制添加到Bottleneck,替换Backbone中所有的C3模块。🌳
💥💥步骤1:在common.py中添加CABottleneck和C3_CA模块
将下面的代码复制粘贴到common.py文件的末尾。
# CA
class h_sigmoid(nn.Module):
def __init__(self, inplace=True):
super(h_sigmoid, self).__init__()
self.relu = nn.ReLU6(inplace=inplace)
def forward(self, x):
return self.relu(x + 3) / 6
class h_swish(nn.Module):
def __init__(self, inplace=True):
super(h_swish, self).__init__()
self.sigmoid = h_sigmoid(inplace=inplace)
def forward(self, x):
return x * self.sigmoid(x)
class CABottleneck(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5, ratio=32): # ch_in, ch_out, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c2, 3, 1, g=g)
self.add = shortcut and c1 == c2
# self.ca=CoordAtt(c1,c2,ratio)
self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.pool_w = nn.AdaptiveAvgPool2d((1, None))
mip = max(8, c1 // ratio)
self.conv1 = nn.Conv2d(c1, mip, kernel_size=1, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(mip)
self.act = h_swish()
self.conv_h = nn.Conv2d(mip, c2, kernel_size=1, stride=1, padding=0)
self.conv_w = nn.Conv2d(mip, c2, kernel_size=1, stride=1, padding=0)
def forward(self, x):
x1 = self.cv2(self.cv1(x))
n, c, h, w = x.size()
# c*1*W
x_h = self.pool_h(x1)
# c*H*1
# C*1*h
x_w = self.pool_w(x1).permute(0, 1, 3, 2)
y = torch.cat([x_h, x_w], dim=2)
# C*1*(h+w)
y = self.conv1(y)
y = self.bn1(y)
y = self.act(y)
x_h, x_w = torch.split(y, [h, w], dim=2)
x_w = x_w.permute(0, 1, 3, 2)
a_h = self.conv_h(x_h).sigmoid()
a_w = self.conv_w(x_w).sigmoid()
out = x1 * a_w * a_h
# out=self.ca(x1)*x1
return x + out if self.add else out
class C3_CA(C3):
# C3 module with CABottleneck()
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
super().__init__(c1, c2, n, shortcut, g, e)
c_ = int(c2 * e) # hidden channels
self.m = nn.Sequential(*(CABottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))💥💥步骤2:在yolo.py文件里parse_model函数中加入类名
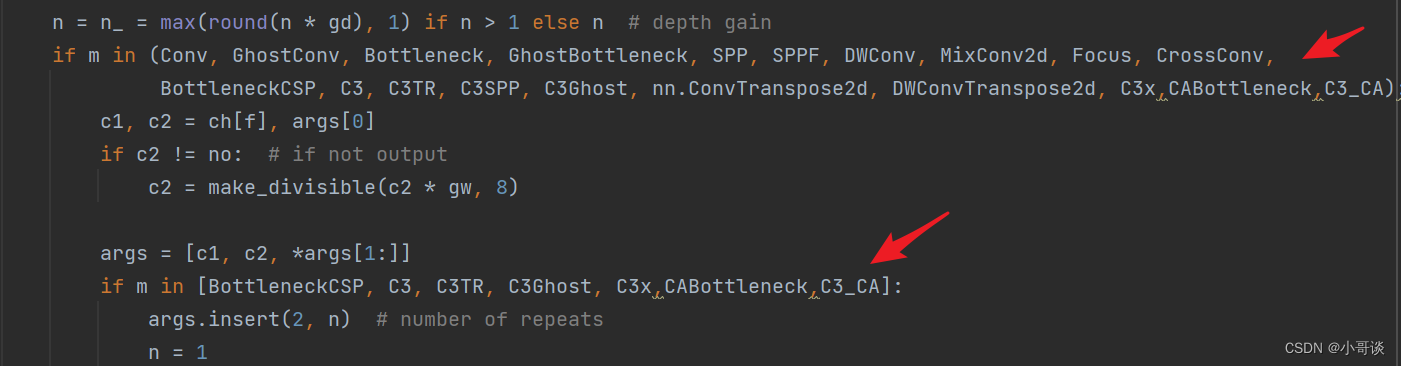
在yolo.py文件的parse_model函数中,加入CABottleneck、C3_CA这两个模块。
💥💥步骤3:创建自定义yaml文件
按照上面的步骤创建yolov5s_C3_CA.yaml文件,替换4个C3模块。

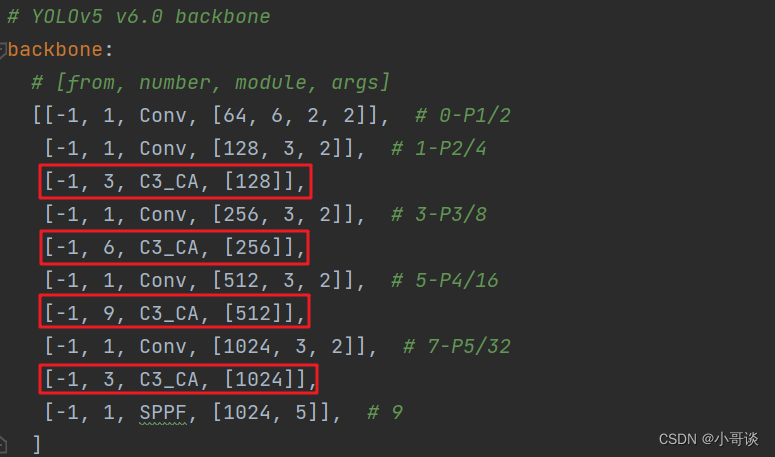
💥💥步骤4:验证是否加入成功
在yolo.py文件里配置刚才我们自定义的yolov5s_C3_CA.yaml,然后运行。
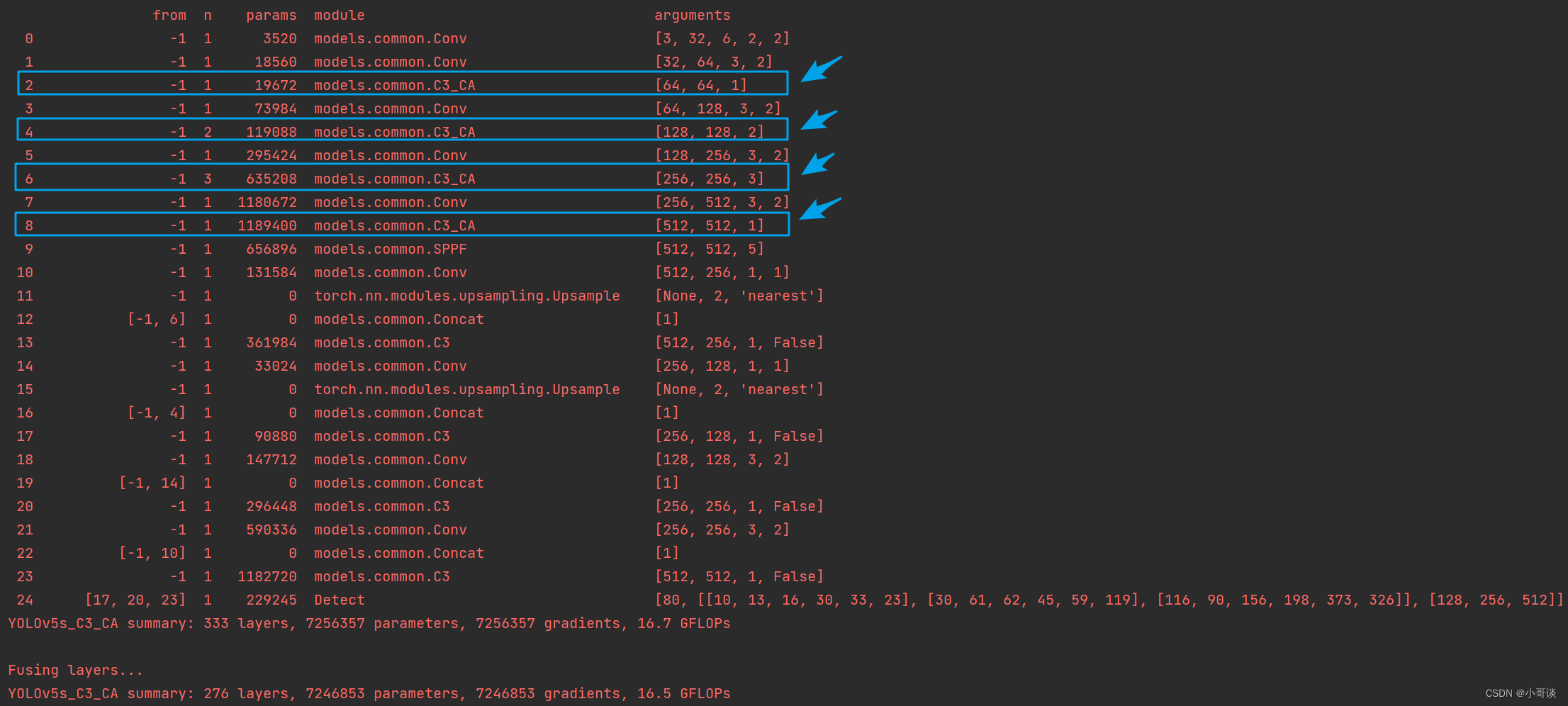
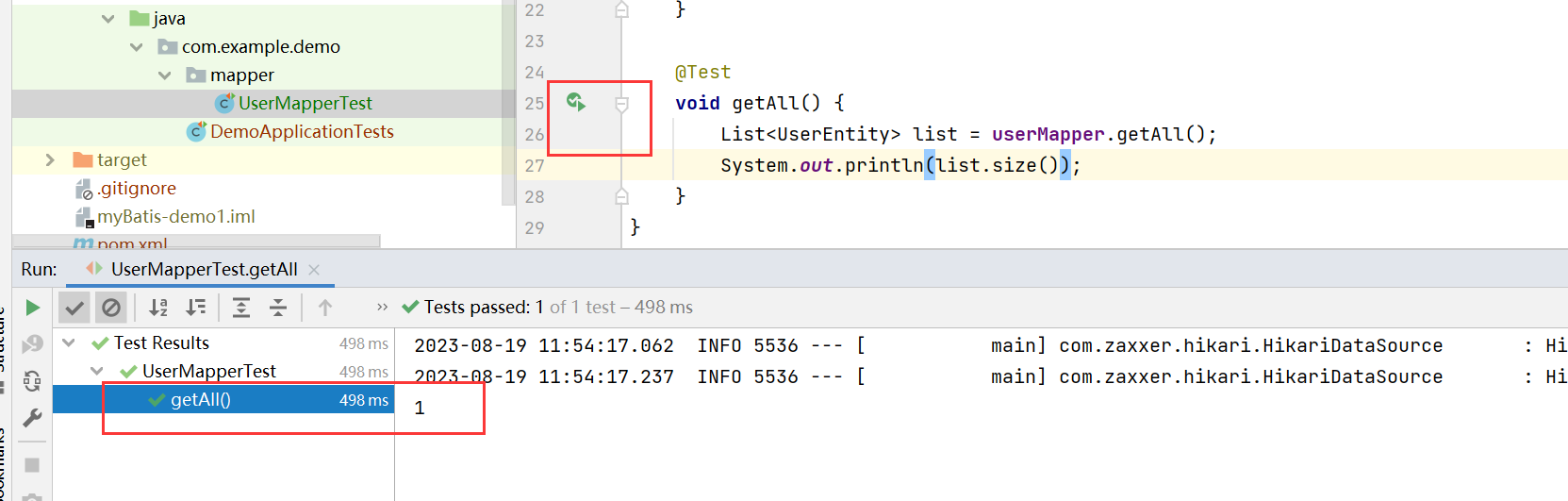
💥💥步骤5:修改train.py中的'--cfg'默认参数
在train.py文件中找到parse_opt函数,然后将第二行'--cfg'的default改为 'models/yolov5s_C3_CA.yaml',然后就可以开始进行训练了。🎈🎈🎈