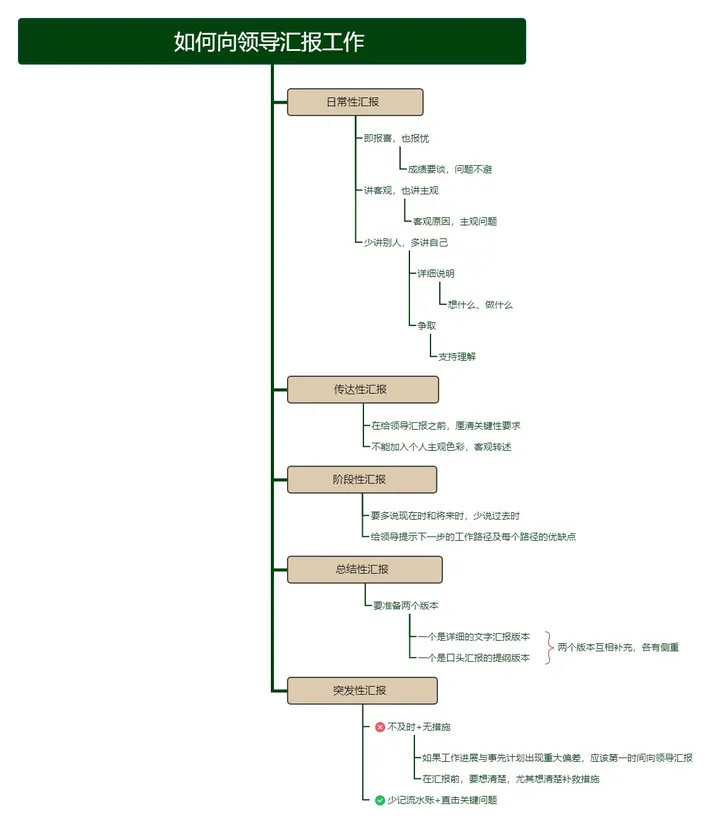
数据加载
数据加载:将RGB的图像数据变成可以计算的tensor。需要的步骤有:
- 定义一个图片转tensor的转换器(transform)
- 定义一个继承自Dataset的myDataSet类,在此类的__getitem__(self, index)中完成一张图片变成一个tensor的转换
- 生成一个DataLoader对象,并将一个myDataSet对象传入DataLoader构造器。
- 通过语句for batch_x,batch_y in dataLoader:… 进行数据的加载
加载数据
transforms
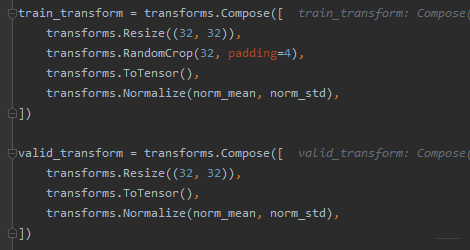
transforms.Compose方法是将一系列的transforms方法进行有序的组合包装,具体实现的时候,依次的用包装的方法对图像进行操作。
transforms.RandomCrop方法对图像进行裁剪(这个在训练集里面用,验证集就用不到了)
transforms.ToTensor方法是将图像转换成张量,同时会进行归一化的一个操作,将张量的值从0-255转到0-1
transforms.Normalize方法是将数据进行标准化


在transforms中转化为.ToTensor()【该数据增强能把输入的数据格式(numpy.ndarray或者PIL Image)转成tensor格式,输入的shape会从[H, W, C]变成]C, H, W],输入的数值范围会从[0, 255]变成[0, 1]】
进入该类下,进入.to_tensor()

如果图像是数据类型是torch.ByteTensor要除以255,(RGB范围0~255?)

PILImage->numpy->tensor
image = Image.open(image_path) # 读取图片
image = np.array(image, dtype=np.float32) # PILImage->numpy 输出(h,w,c)
image /= 255.0 # 网络输入需要归一化
image = np.transpos e(image, (2, 0, 1)) # np下维度转换使用transpose
image = torch.from_numpy(image) # numpy->tensor
print(image.shape)
输出
torch.Size([3, 575, 551]) # (c,h,w)
PILImage->tensor
image = Image.open(image_path) # 读取图片
image = transforms.ToTensor()(image) # PILImage->tensor
# image = torch.Tensor.permute(image, (0, 1, 2)) # tensor下维度转换
print(image.shape)
使用torchvision下transforms依赖包,一步到位。
在第二行中,集成处理了以下步骤:
1,img.tobytes() 将图片转化成内存中的存储格式
2,torch.BytesStorage.frombuffer(img.tobytes() ) 将字节以流的形式输入,转化成一维的张量
3,对张量进行reshape
4,对张量进行permute(2,0,1)
5,将当前张量的每个元素除以255
6,输出张量
第三行备注的那句,是在tensor下如果想要转换维度使用的代码。跟之前numpy下不同。
系统学习Pytorch笔记三:Pytorch数据读取机制(DataLoader)与图像预处理模块(transforms)
PILImage和tensor转换
PIL包中图像的mode参数——pic.mode
为什么一些机器学习模型需要对数据进行归一化?
深度学习中数据到底要不要归一化?实测数据来说明!
深度学习模型学习的是一种end-to-end的映射关系,存在一个尺度问题,如果只对X或者Y做预处理,会使得两端的空间(指的是特征空间)差异变大,需要学习的映射就会变得更加的隐晦。而同时对X和Y进行预处理,压缩了这种特征空间的变异性,所以使得要被学习到的映射变得简单了,或者说变的更加的“可视化”。


![[Linux]进程状态](https://img-blog.csdnimg.cn/img_convert/614aa0b42da3b307584a75d3f2bdc117.png)