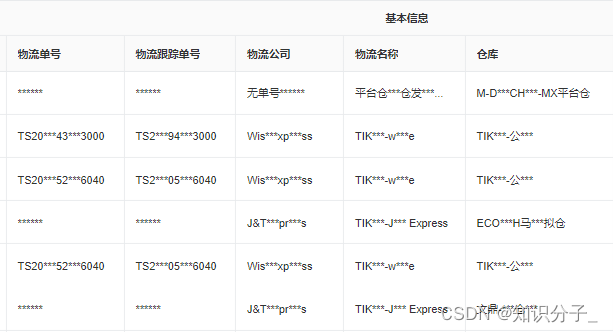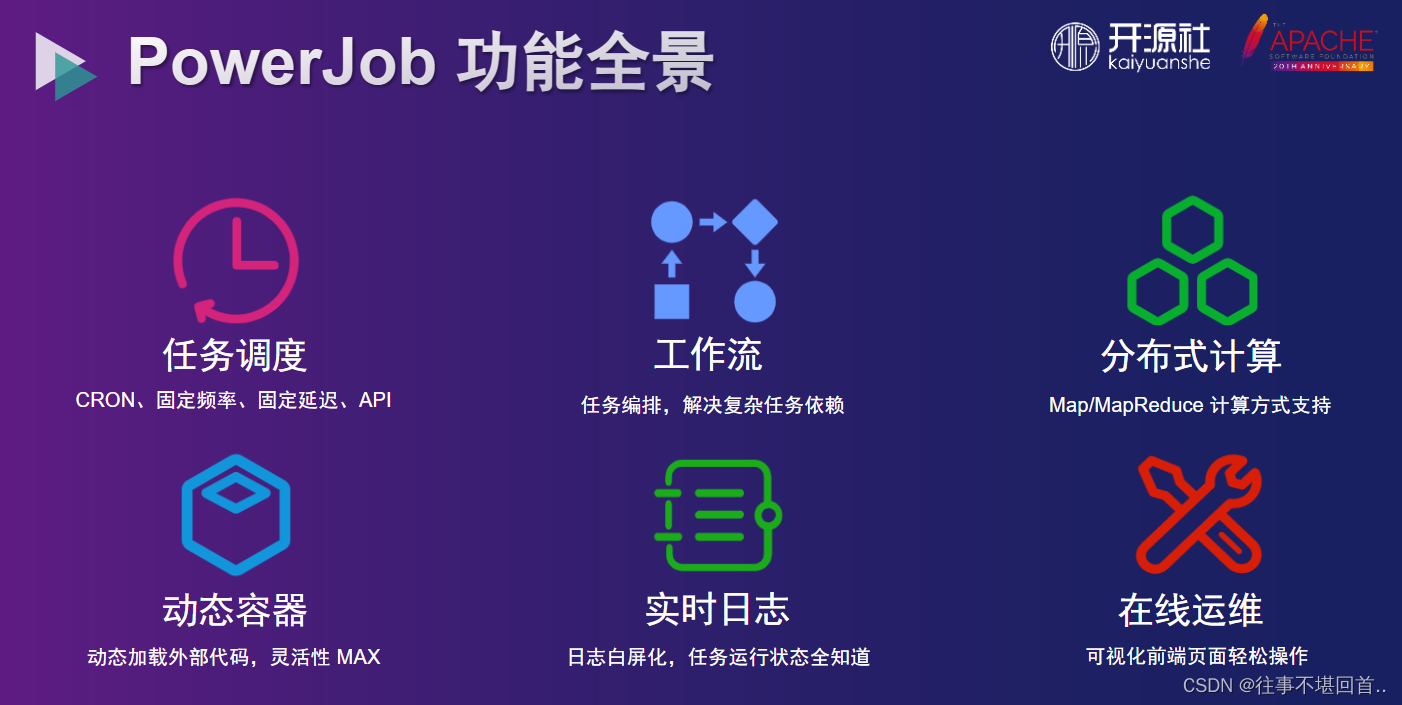
首先,本文中提到的server就是指powerjob-server模块(也就是powerJob的重点之一的调度服务)
一、初始化项目
1. PowerJob的下载 官方文档
2. 导入到IDEA中,下载依赖后,打开powerjob-server模块的application.properties
3.根据spring.profiles.active设置的环境 , 打开对应的application-xxx.properties文件修改数据源以及邮箱

4. 创建数据库
4.1 仅需要创建数据库:找到你的DB,运行 SQL CREATE DATABASE IF NOT EXISTS `powerjob-daily` DEFAULT CHARSET utf8mb4
---- postgre执行的是CREATE DATABASE "powerjob-product"
4.2 官方提示:如果你暂时没有可用的数据库进行测试,那么可以使用以下数据库配置来一键启动 server(仅限测试环境使用!):
spring.datasource.core.driver-class-name=org.h2.Driver
spring.datasource.core.jdbc-url=jdbc:h2:file:~/h2/powerjob-daily-test
spring.datasource.core.username=sa
spring.datasource.core.password=
二、启动powerjob-server调度服务器
5. 在子模块powerjob-server-starter中启动PowerJobServerApplication.java,成功后访问 http://127.0.0.1:7700/
6. 注册应用,应用名称与密码都输入powerjob-agent-test(可随意更改,但后续需要在worker模块启动之前更改properties对应的名字为刚刚注册的名字)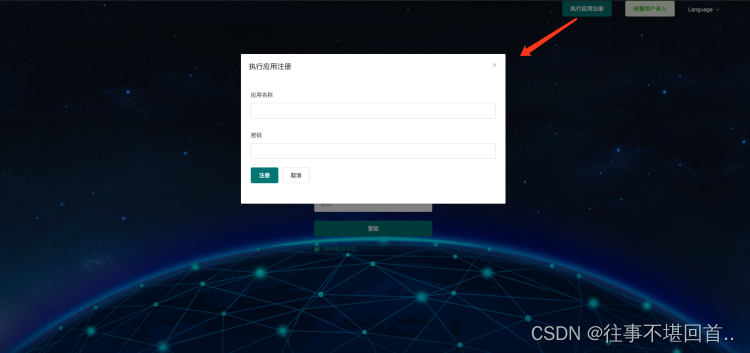
三、编写任务demo,并启动samples(也就是定时任务)
7. 进入示例工程(powerjob-worker-samples),修改 powerjob-worker-samples 的 application.properties,将 powerjob.worker.app-name 改为刚刚在控制台注册的名称
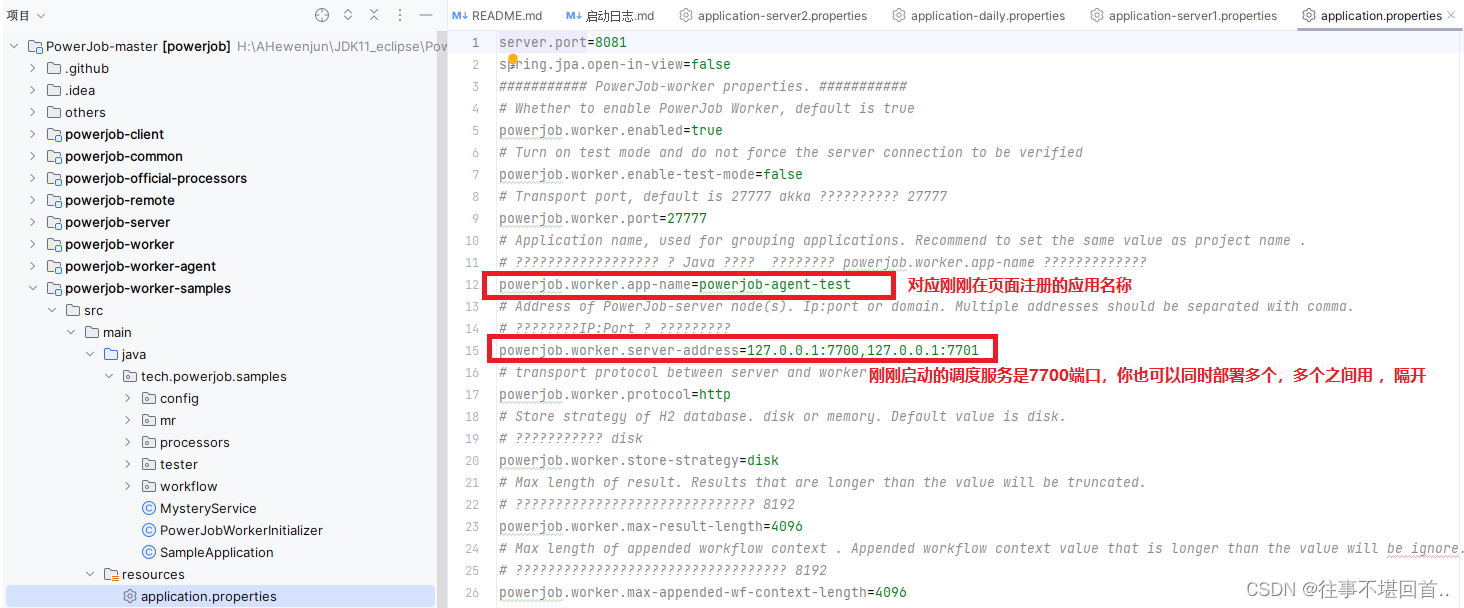
server.port=8081
spring.jpa.open-in-view=false
# akka 工作端口,可选,默认 27777
powerjob.worker.akka-port=27777
# 接入应用名称,用于分组隔离,推荐填写 本 Java 项目名称
powerjob.worker.app-name=powerjob-agent-test
# 调度服务器地址,IP:Port 或 域名,多值逗号分隔
powerjob.worker.server-address=127.0.0.1:7700,127.0.0.1:7701
# 持久化方式,可选,默认 disk
powerjob.worker.store-strategy=disk
# 任务返回结果信息的最大长度,超过这个长度的信息会被截断,默认 8192
powerjob.worker.max-result-length=4096
# 单个任务追加的工作流上下文最大长度,超过这个长度的会被直接丢弃,默认 8192
powerjob.worker.max-appended-wf-context-length=40968. 新建任务或使用已有的任务Demo
8.1 powerjob-worker-samples这个模块本身就继承了powerjob-worker模块,里面也定义了大量的任务Demo,一开始为了启动就直接任意使用一个demo进行测试
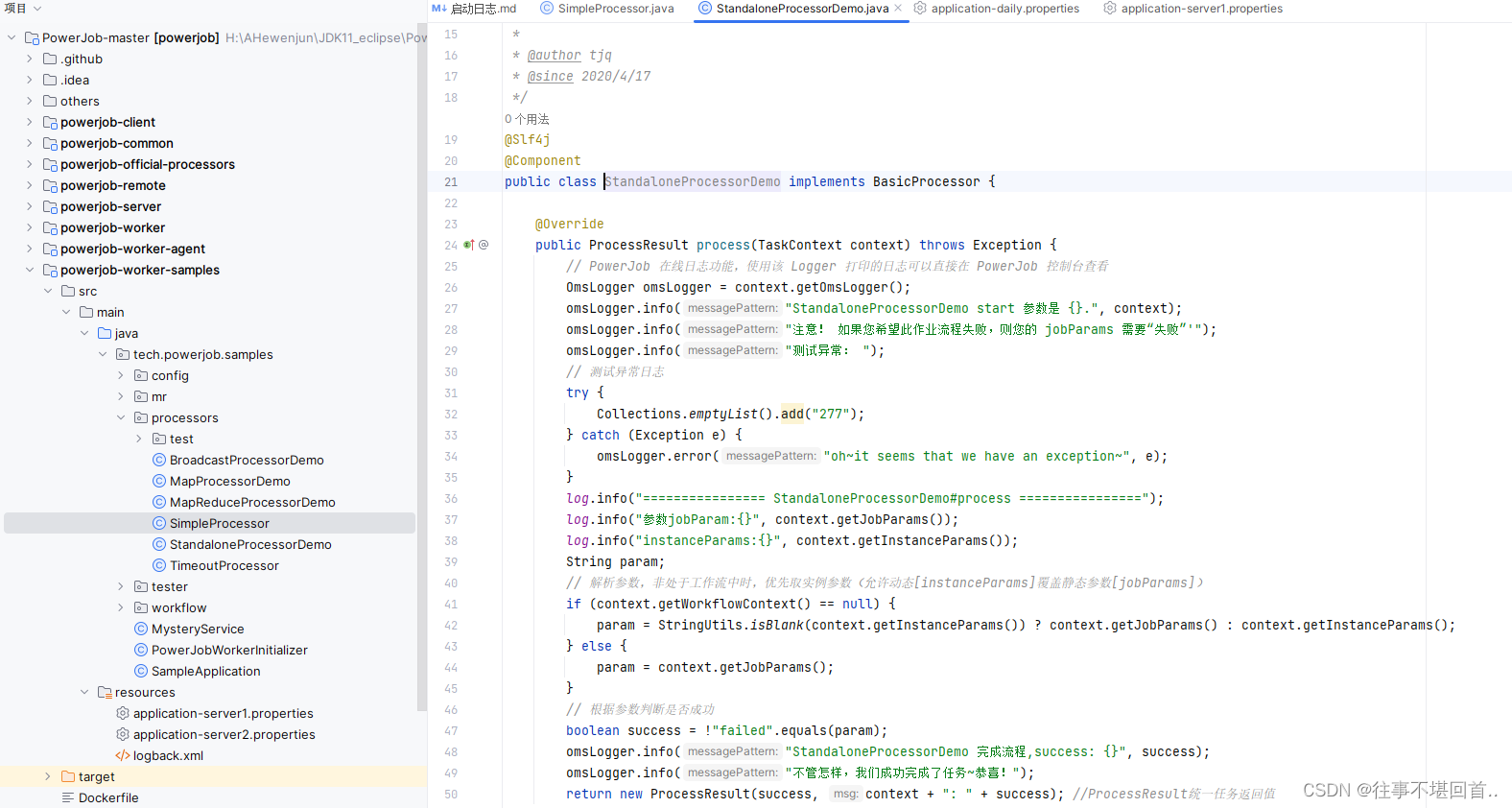
例如我使用StandaloneProcessorDemo.java,任意改了些中文日志,为了待会好看结果
8.2 如果不想使用已有的demo,也可以在samples模块随便找个地方新建类,只需要在新建的类上执行以下操作即可
8.2.1添加@Component注解以及implements 官方4种处理器即可,处理器内实现自己的定时任务逻辑
8.2.2 方法定义固定格式,参考以下(统一返回值为ProcessResult,统一方法名为process,统一入参TaskContext):
public ProcessResult process(TaskContext context)9. 启动示例程序,即直接运行主类 tech.powerjob.samples.SampleApplication,观察控制台输出信息,判断是否启动成功
四、单机任务的配置与运行
10. 调度服务器与示例工程都启动完毕后,再次前往Web页面( http://127.0.0.1:7700/ ),进入首页就能看到刚刚部署成功的worker-samples(执行器)
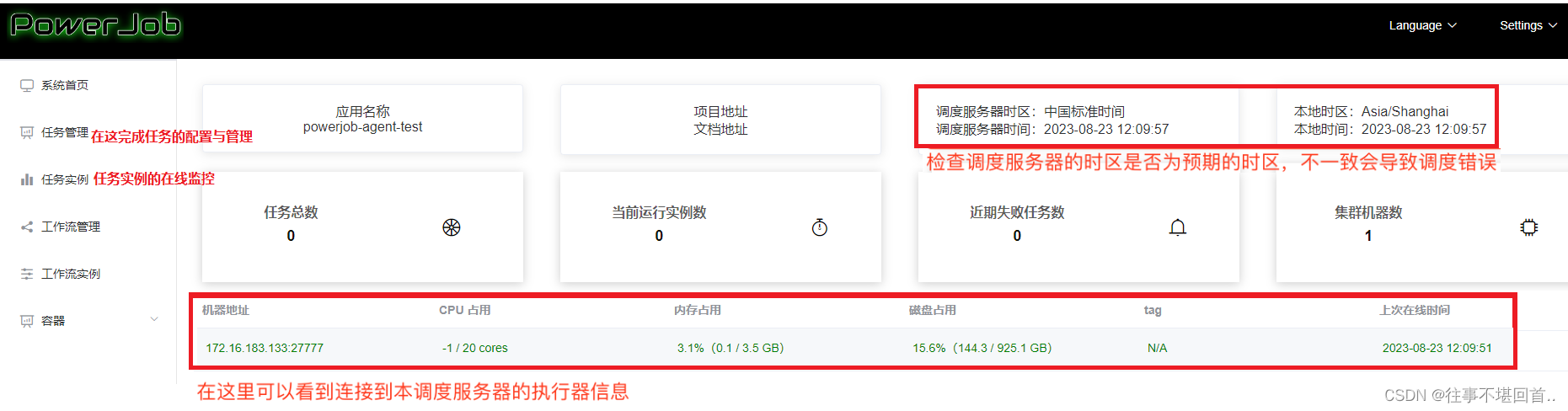
11. 点击任务管理 -> 新建任务(右上角),开始创建任务
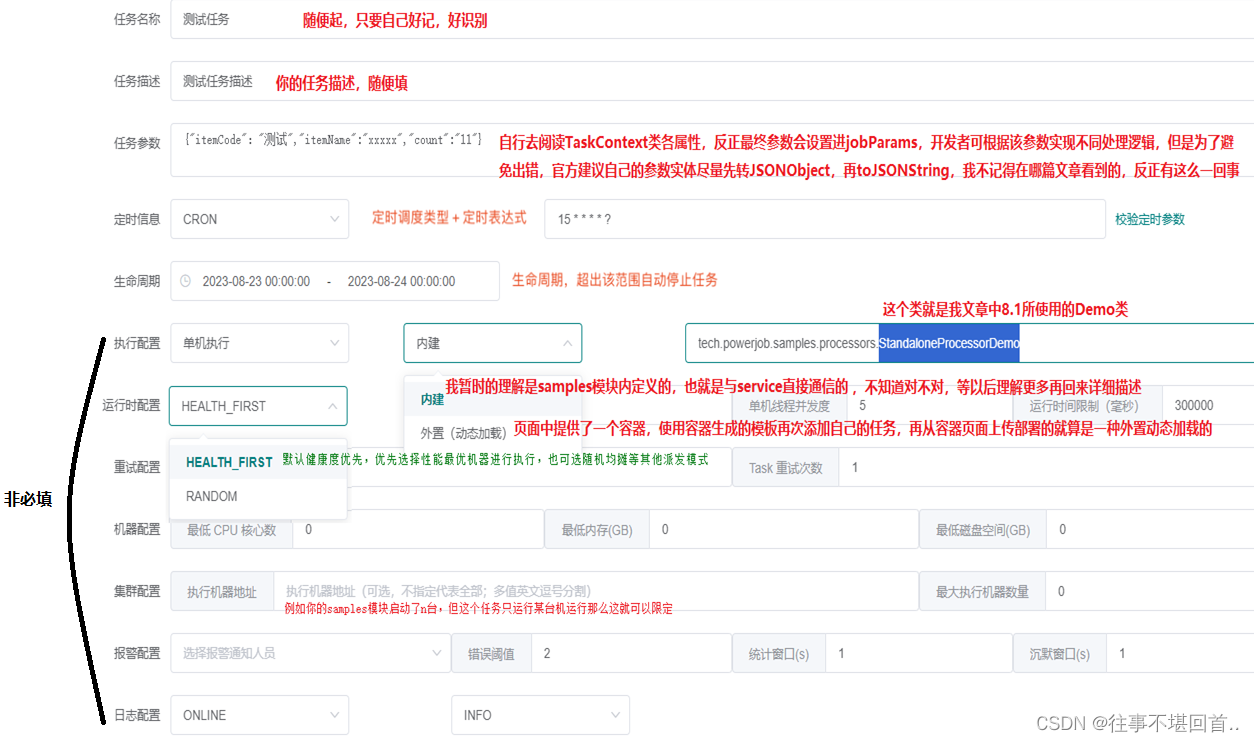
Powerjob的CRON模式下,时间轮是15秒扫描一次,cron表达式不能小于15秒。若低于15秒会按15秒运行,解决办法就是不用cron表达式,改用固定频率或固定延迟进行
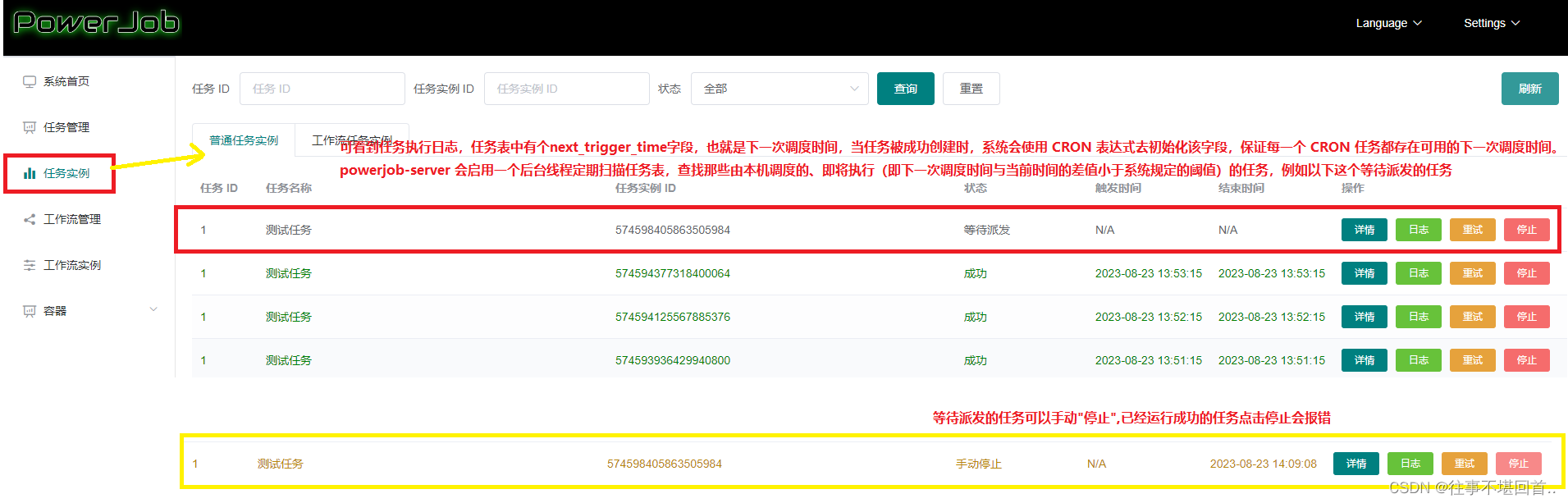
12. 保存后,在列表点击运行,我设置的是15秒运行一次,可以在任务实例中看到执行详情:

至此,简单的单机运行测试结束
五、广播执行模式的配置与运行
13. 在powerjob-worker-samples模块中把application.properties文件改名为application-worker1.properties,再复制一份修改为application-worker2.properties,worker2中server.port改成8082,powerjob.worker.port改成27778
14.启动2个powerjob-worker-samples服务
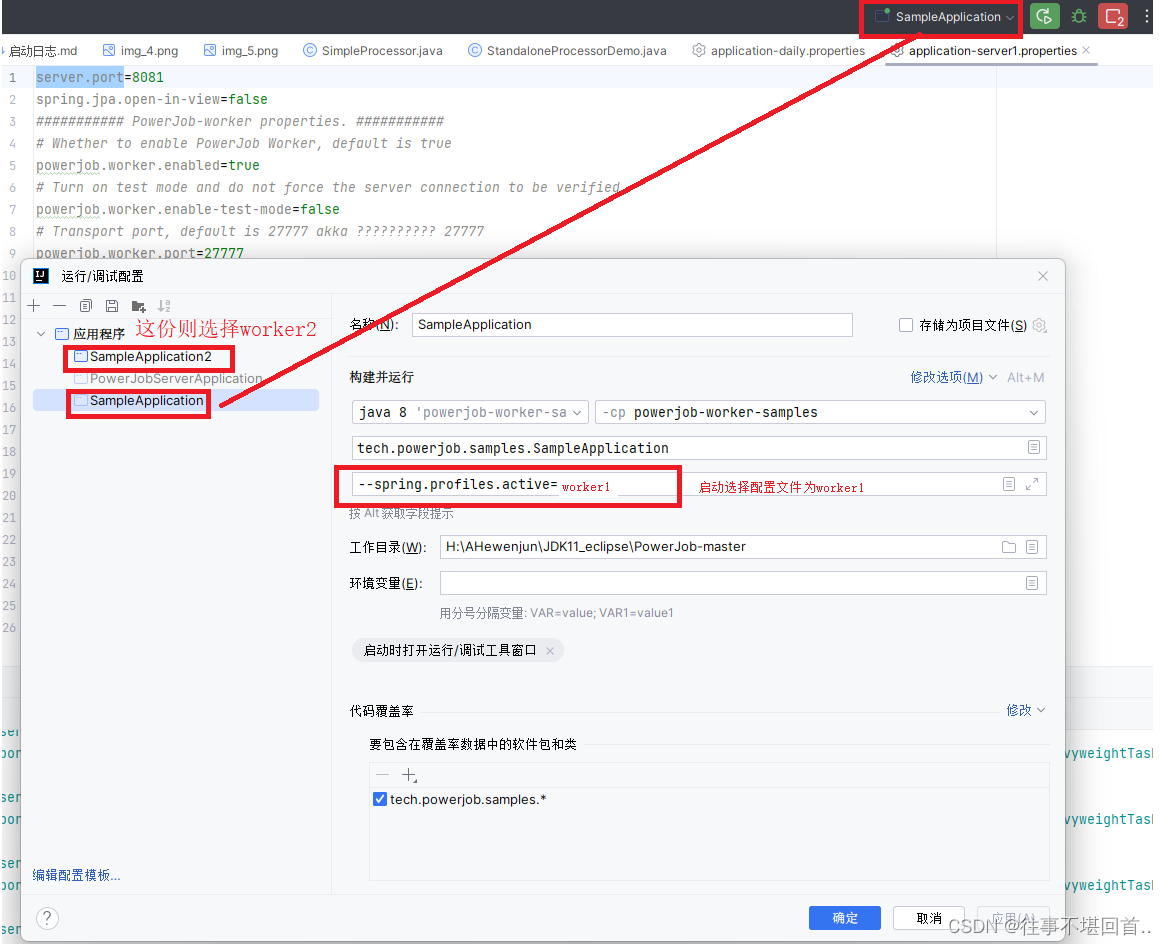

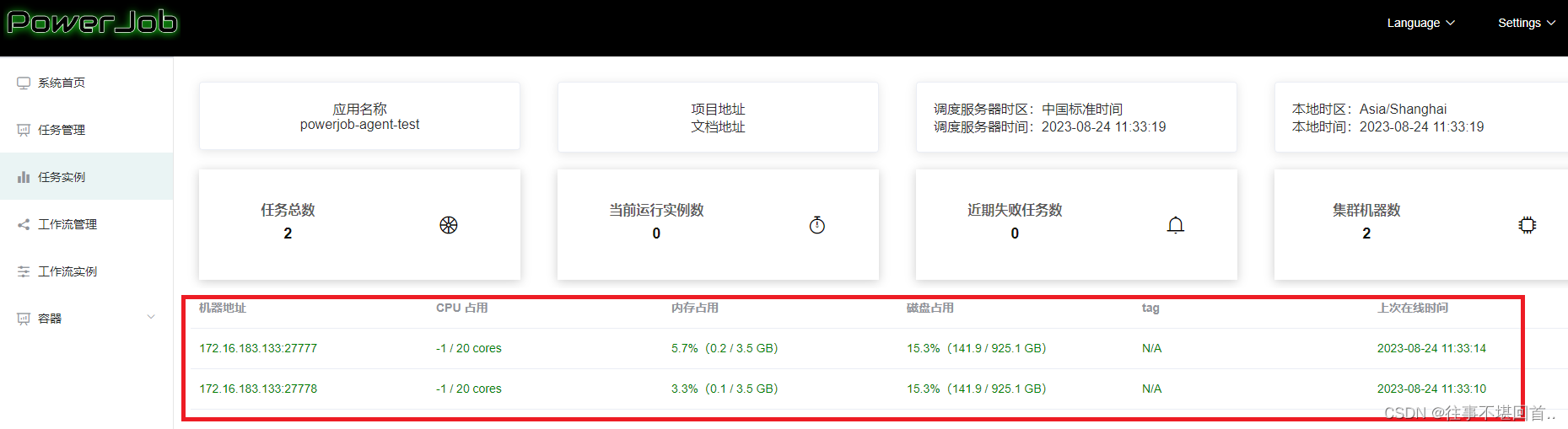
15.启动成功后,页面刷新就可以看到2个worker执行器了
16. 复制之前写好的单机执行任务,改成广播执行即可(理论上来说需要选择一个实现了BroadcastProcessor的处理Demo类,例如BroadcastProcessorDemo,但实际我最后运行没有任何问题,本身广播BroadcastProcessor就是在BasicProcessor单机的基础上添加了执行前后两个方法,不报错应该只是没有执行前后方法吧,暂不深究)
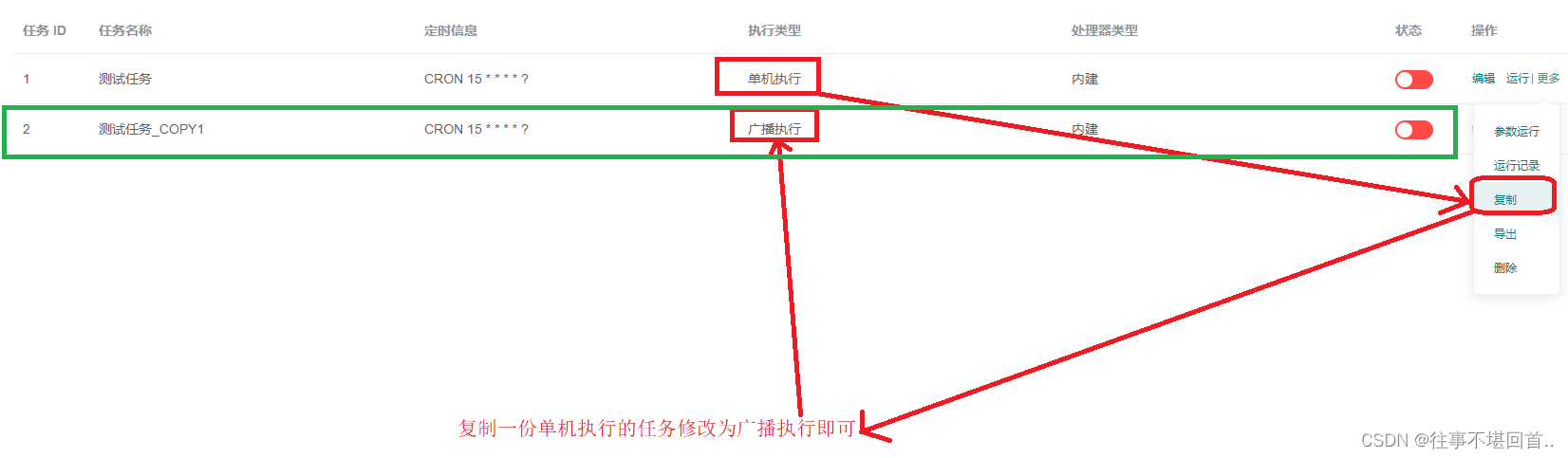
17.运行广播模式任务

终、官方描述与目前使用总结:
PowerJob的无锁化(目前已有的开源调度框架为了解决重复调度,大都使用各种锁)
引入分组依据 AppName,以应用集群作为 server 调度的单位。 每一个 worker 集群在运行时只会连接到某一台 server。 每一个 server 实例只会调度当前与自己保持心跳的 worker 关联的 AppName 下的所有任务。
PowerJob的高性能调度——时间轮
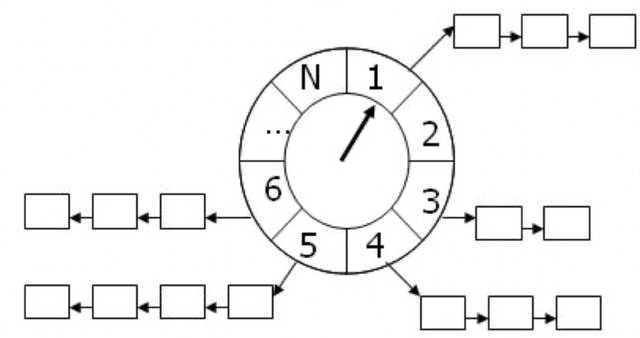
趣讲 PowerJob 超强大的调度层 ---故事
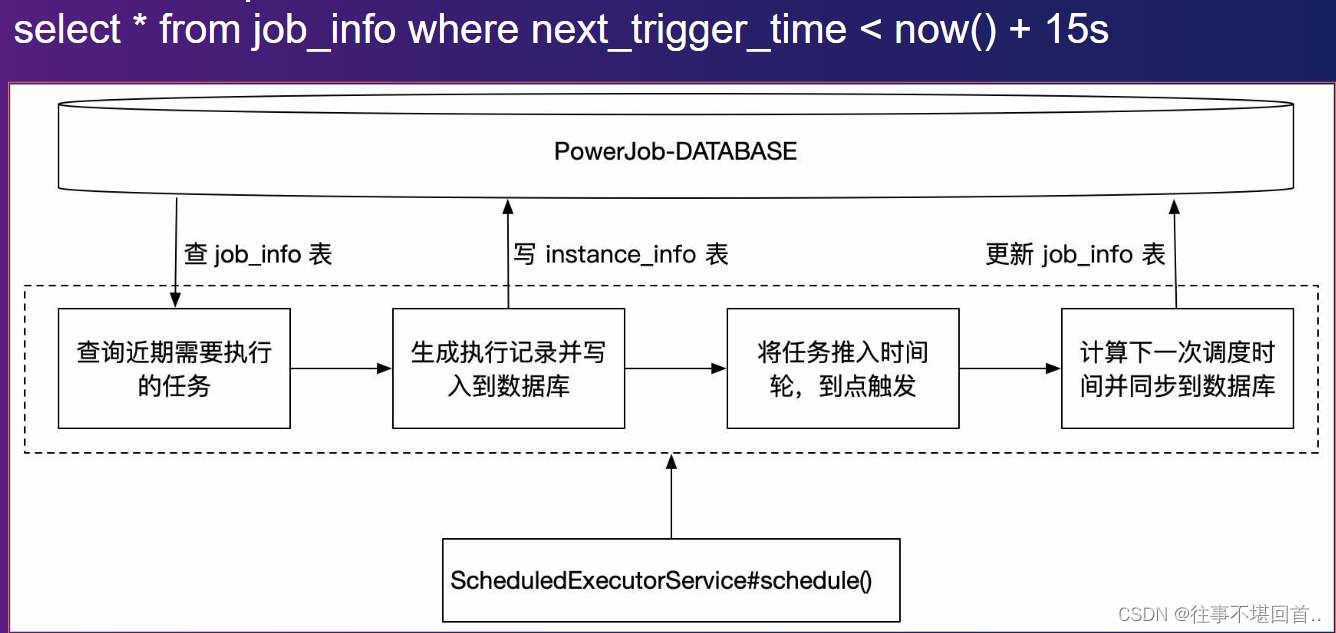
server会15秒扫描一次job_info表找到next_trigger_time在15秒之内的任务推进时间轮中,也就会在instance_info表中添加一条数据,页面状态:
官方提供的4种处理器:
1. 单机处理器(BasicProcessor)对应了单机任务,即某个任务的某次运行只会有某一台机器的某一个线程参与运算(也就是集群后也只有一台服务器会执行定时任务)。
--单机执行的策略下,server 会在所有可用 worker 中选取健康度最佳的机器进行执行。单机执行任务需要实现接口 BasicProcessor
2. 广播处理器(BroadcastProcessor)对应了广播任务,即某个任务的某次运行会调动集群内所有机器参与运算。
--广播处理器在BasicProcessor 的基础上额外增加了 preProcess 和 postProcess 方法,分别在整个集群开始之前/结束之后选一台机器执行相关方法
3. MapReduce 是最复杂也是最强大的一种执行器,它允许开发者完成任务的拆分,将子任务派发到集群中其他Worker 执行,是执行大批量处理任务的不二之选!实现 MapReduce 处理器需要继承 MapReduceProcessor类。
--- MapReduce 处理器(MapReduceProcessor)对应了 MapReduce 任务,在 Map 任务的基础上,增加了所有任务结束后的汇总统计
4. Map 处理器相当于 MapReduce 处理器的阉割版本(阉割了 reduce 方法)
○ 内置Java处理器
■ 方式一 -> 填写该处理器的全限定类名(eg, tech.powerjob.samples.processors.MapReduceProcessorDemo)
■ 方式二 -> 填写 IOC 容器的 bean 名称,比如 Spring 用户可填写 Spring Bean 名称(eg, 处理器使用注解 @Component(value = "powerJobProcessor"),则控制台可填写 powerJobProcessor)
■ 方式三 -> 方法级注解,非 MapReduce 任务可直接使用注解 @PowerJobHandler 将某个方法转化为 PowerJob 任务,并设置唯一入参 TaskContext注入上下文,具体参考代码
@Component(value = "springMethodProcessorService")
public class SpringMethodProcessorService {
/**
* 处理器配置方法1: 全限定类名#方法名,比如 tech.powerjob.samples.tester.SpringMethodProcessorService#testEmptyReturn
* 处理器配置方法2: SpringBean名称#方法名,比如 springMethodProcessorService#testEmptyReturn
* @param context 必须要有入参 TaskContext,返回值可以是 null,也可以是其他任意类型。正常返回代表成功,抛出异常代表执行失败
*/
@PowerJobHandler(name = "testEmptyReturn")
public String testEmptyReturn(TaskContext context) {
OmsLogger omsLogger = context.getOmsLogger();
omsLogger.warn("测试日志");
return "响应结果,正常返回视为执行成功,抛出异常视为执行失败"
}
}
○ Java容器 -> 填写容器ID#处理器全限定类名(eg,1#cn.edu.zju.oms.container.ContainerMRProcessor)
○ SHELL、Python、SQL 、HTTP 等任务的执行:点击查看官方处理器的使用教程
● 运行配置
○ 派发策略:默认健康度优先,优先选择性能最优机器进行执行,可选随机均摊等其他派发模式
○ 最大实例数:该任务同时执行的数量,0 代表不限制实例数量
○ 单机线程并发数:该实例执行过程中每个 Worker 使用的线程数量(MapReduce 任务生效,其余无论填什么,都只会使用必要的线程数)
○ 运行时间限制:限定任务的最大运行时间,超时则视为失败,单位毫秒,0 代表不限制超时时间(不建议不限制超时时间)。
● 重试配置:
○ Instance 重试次数:实例级别,失败了整个任务实例重试,会更换 TaskTracker(本次任务实例的Master节点),代价较大,大型Map/MapReduce慎用。
○ Task 重试次数:Task 级别,每个子 Task 失败后单独重试,会更换 ProcessorTracker(本次任务实际执行的 Worker 节点),代价较小,推荐使用。
○ 注:请注意同时配置任务重试次数和子任务重试次数之后的重试放大,比如对于单机任务来说,假如任务重试次数和子任务重试次数都配置了 1 且都执行失败,实际执行次数会变成 4 次!推荐任务实例重试配置为 0,子任务重试次数根据实际情况配置。
● 机器配置:用来标明允许执行任务的机器状态,避开那些摇摇欲坠的机器,0 代表无任何限制。
○ 最低 CPU 核心数:填写浮点数,CPU 可用核心数小于该值的 Worker 将不会执行该任务。
○ 最低内存(GB):填写浮点数,可用内存小于该值的 Worker 将不会执行该任务。
○ 最低磁盘(GB):填写浮点数,可用磁盘空间小于该值的 Worker 将不会执行该任务。
● 集群配置
○ 执行机器地址,指定集群中的某几台机器执行任务
■ IP模式:多值英文逗号分割,如192.168.1.1:27777,192.168.1.2:27777。常用于 debug 等场景,需要指定特定机器运行。
■ TAG 模式:通过 PowerJobWorkerConfig#tag将执行器打标分组后,可在控制台通过 tag 指定某一批机器执行。常用于分环境分单元执行的场景。如某些任务需要屏蔽安全生产环境(tag 设置为环境标),某些任务只需要在特定单元执行(tag 设置单元标)
○ 最大执行机器数量:限定调动执行的机器数量
● 报警配置:选择任务执行失败后报警通知的对象,需要事先录入。
● 日志配置:可使用控制台配置调整 Job 使用的 Logger 及 LogLevel
○ 支持 SERVER(服务端日志,默认)、LOCAL(本地日志)、STDOUT(系统输出)、NULL(空实现)4种 LogType
○ 支持 DEBUG、INFO、WARN、ERROR、OFF 5种级别控制
○ 使用建议:初期调试可使用 SERVER 日志,后续功能稳定后改为 LOCAL,并调高日志级别,降低通讯压力,消除性能瓶颈问题
以上可见PowerJob重点分为调度服务(powerjob-server)、执行器(powerjob-worker)两部分,而刚刚启动的powerJob-worker-samples本身就是基于powerjob-worker的一些任务实现也就是一些任务案例、Demo,我们只是把任务写在samples然后启动程序后,在web进行任务调度,实际这个samples模块可以是任何其他模块,只要这个模块的pom.xml依赖powerjob-worker,任务类实现4大处理器即可
server与worker之间使用HTTP+JSON进行通信
powerjob-server:调度中心,整个公司内部统一部署,负责任务管理和调度【承担任务派发(调度)、后续状态检测、Web服务(也就是我们访问的可视化页面)】
powerjob-worker:执行器,提供单机执行、广播执行和分布式计算等功能(执行任务)
powerjob-client:可选组件,OpenAPI 客户端(也就是官方提供的各处理器不符合你的业务逻辑,那么就可以使用官方提供的api扩展)