基于数据分析的震源属性识别模型构建与震级预测问题的研究

问题一:
解题思路:
第一部:
对数据进行一个处理,将数据进行分类,求出数据中的最大值,最小值,极差,方差等等一系列特征数据。,将天然的地震和非天然的地震数据融合到一块儿。做好对应的标记是哪一个附件,哪一个站台,并打上标签。
生成CSV文件的形式
第二部:
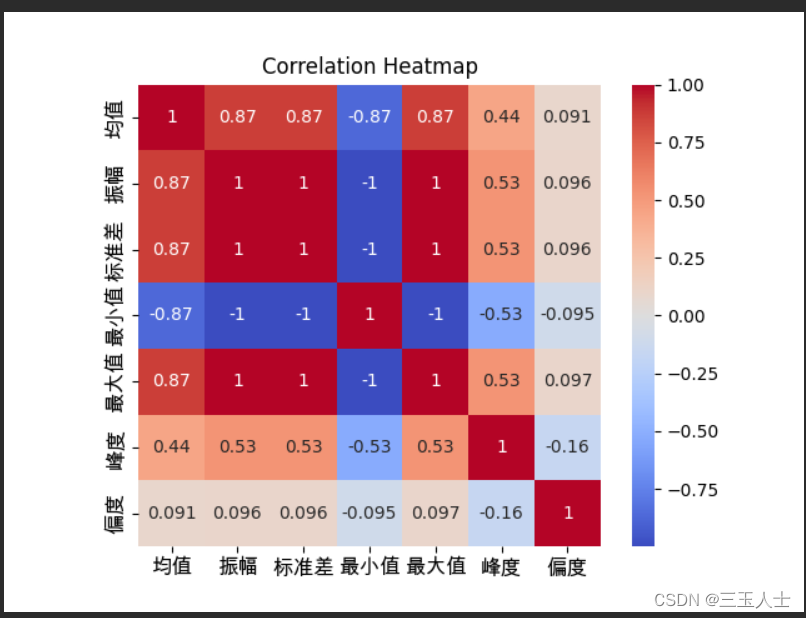
将特征数据进行一个回归分析,在构成相关性的热力统计图。具体分析哪些特征数值与天然地震和非天然地震相关,寻找关键数据。
第三部:
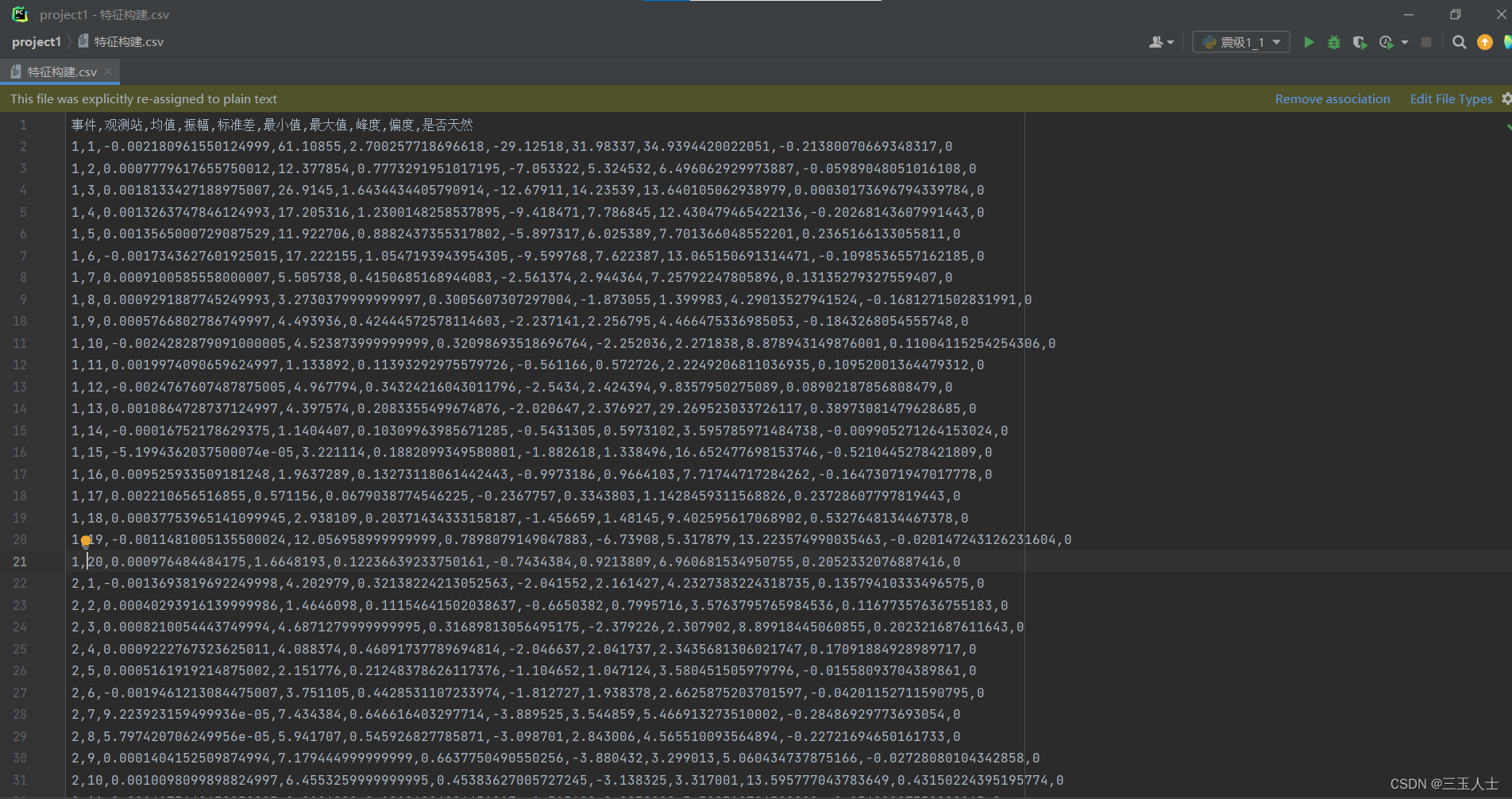
通过网上查阅资料,并且利用之前学过的人工智能方面的知识,列如:决策树,随机森林,线性回归等算法,读取数据,划分训练集和测试集
最终,建立模型。
第四部:进行算法的优化。
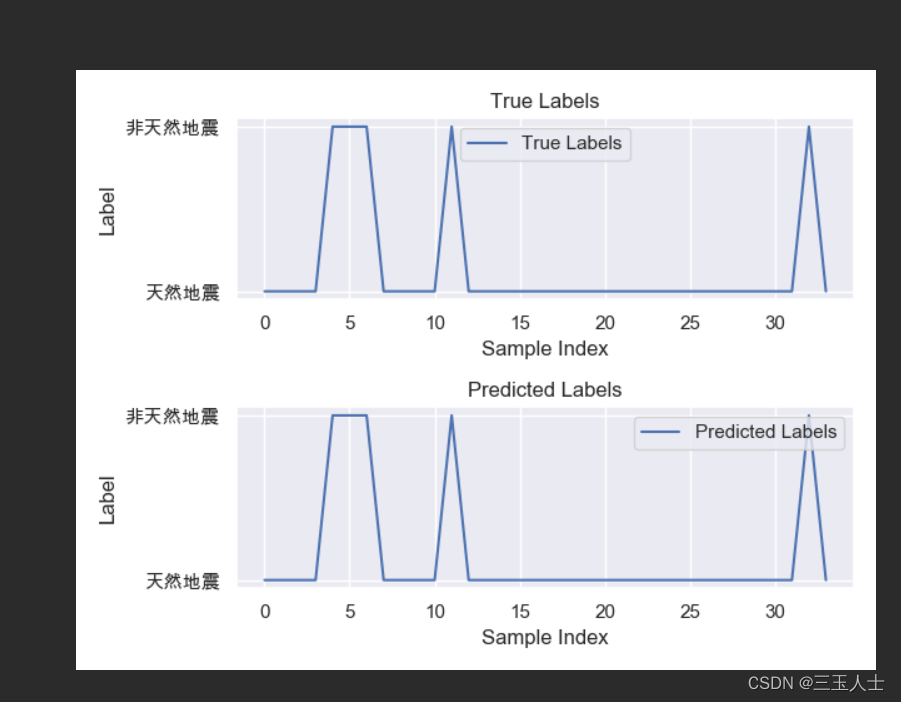
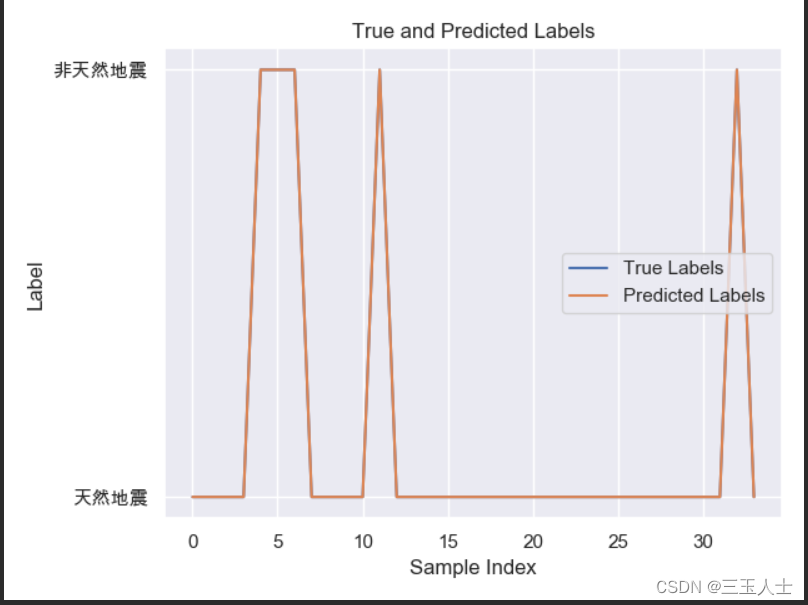
总结
我们首先根据附件中的数据,初步判断出这是一个数据分析的题目,用创建svm分类器的方法来进行数据分析。首先是读取相关数据,然后转换数据和标签为numpy数组,接着划分训练集和测试集,接着创建出svm分类器然后利用fit方法对该模型进行训练接着进行对该模型的预测
答案内容:
预测的标签 = sign(w^T * 地震波数据 + b)
需要注意的是,具体的权重向量(w)和偏置项(b)是在模型训练过程中通过最优化算法得到的,由输入数据和标签决定。
问题二:
解题思路:
第一部:
由于第一问通过建立的模型来初步对地震类型进行分类,考虑到地震波的振幅大小、波形特征与震级有显著关联。所以主要用线性回归模型来预测地震事件的地震震级。首先将训练集数据读取并处理然后,利用X_train和y_train训练线性回归模型。
第二部:
接下来,读取测试集数据并处理成特性矩阵X_test。最后,使用训练好的模型对X_test进行预测,得到n道地震震级的预测结果y_pred。
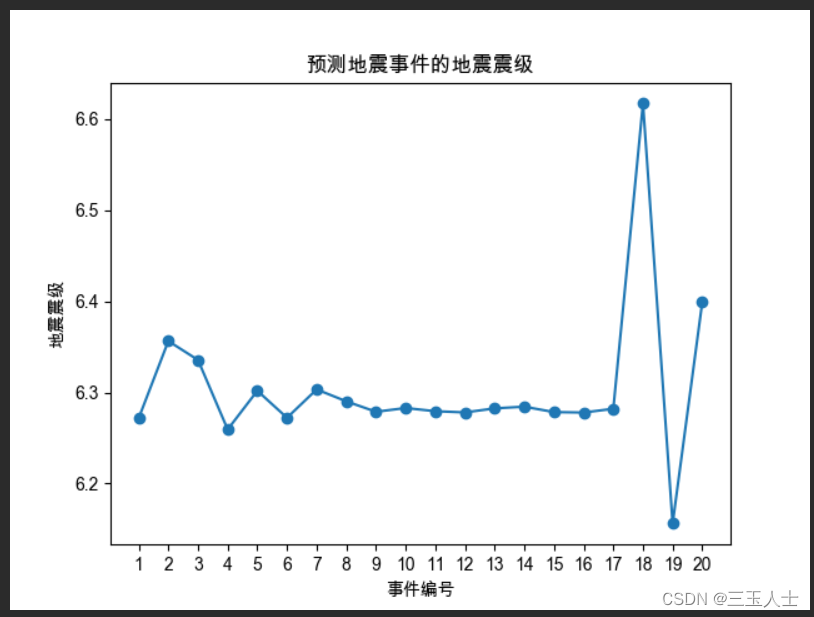
答案内容:
此代码使用了线性回归模型(Linear Regression)来预测地震事件的震级。线性回归模型的公式是:
y = w^T * x + b
其中,y是预测的地震震级,x是输入的地震波数据,w是模型的权重向量,b是偏置项。
使用LinearRegression()函数创建了一个线性回归模型,通过fit()函数对训练集数据进行训练,然后使用predict()函数对测试集数据进行预测。
折线图展示了预测地震事件的地震震级,x轴是事件的编号,y轴是地震震级。
问题三:
解题思路:
第一部:
我们首先使用Pandas库读取CSV文件中的数据。然后,我们使用LabelEncoder对分类变量进行标签编码。
第二部:
接下来,我们准备了自变量X和因变量y。然后,我们使用train_test_split函数将数据集拆分为训练集和测试集。
第三部:
然后,我们构建了一个线性回归模型并使用训练集数据对其进行拟合。
第四部:
最后,我们使用测试集数据进行了预测,并计算了预测结果与真实值之间的均方根误差(RMSE)作为模型的评估指标。
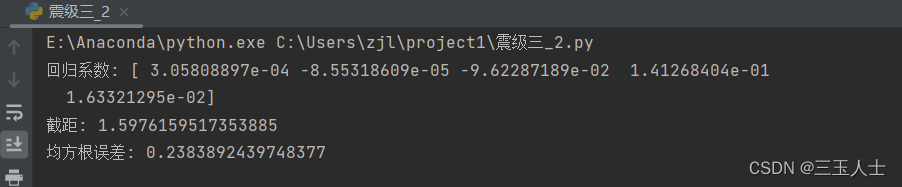
答案内容:
震级 = 截距 + w1 * 库深/m + w2 * 库容 + w3 * 断层类型 + w4 * 构造活动/基本烈度 + w5 * 岩性
其中,
截距是 model.intercept_ 的值,
w1 ~ w5 是 model.coef_ 的值对应的系数。