最近,AI 图像生成十分火热,当我们给它一个文本提示(text prompt)时,它将返回与文本匹配的图像,从而生成各种我们想要的图像。除了根据文本生产图像以外,它还可以用于图像修复、图像绘制、图像替换等,这极大地改变了人们图像创作的方式。

SD模型简介
Stable Diffusion 是 CompVis、Stability AI 和 LAION 等公司研发的一个高性能文生图(text to image)模型,除了根据文本生产图像以外,它还可以用于替换、更改图像。和普通的扩散模型相比,SD 模型生成的图像质量更高、运行速度更快,并且相对来说消耗的资源以及内存占用更小,可以说是 AI 图像生成领域的一个里程碑,让普通用户高效率地生成图像成为可能。
同时,SD 模型也因为其开源性而最为著名。它的模型和代码是开源的,而且训练数据 LAION-5B 也是开源的。SD 在开源90天 github 仓库就收获了33K的 stars ,可见这个模型有多么受人们欢迎。
SD模型的基础结构原理
作为扩散模型的改进版本,SD 模型通过引入隐向量空间解决了扩散模型的速度瓶颈,除了可专门用于文生图任务,还可以用于图生图、特定角色刻画,甚至是超分或者上色任务。以最常用的文生图为例,SD 模型的基础结构原理如下:
下图是一个基本的文生图流程,把中间的 SD 结构看成一个黑盒,那黑盒输入是一个文本串“paradise(天堂)、cosmic(广阔的)、beach(海滩)”,通过 SD 技术,输出了最右边符合输入要求的生成图片,图中产生了蓝天白云和一望无际的广阔海滩。

SD 模型的核心思想是,由于每张图片满足一定规律分布,利用文本中包含的这些分布信息作为指导,把一张纯噪声的图片逐步去噪,就能生成一张跟文本信息匹配的图片。
那么,如何把人类输入的文字串转换成机器能理解的数字信息,再转换为生成的图片呢?
Step 1 :信息转换就用到了文本编码器 text encoder(蓝色模块)。
它可以把文字转换成计算机能理解的某种数学表示,它的输入是文本串,输出是一系列具有输入文字信息的语义向量。有了这个语义向量,就可以作为后续图片生成器 image generator(粉色模块+黄色模块)的一个控制输入,这也是 stable diffusion 技术的核心模块。
Step 2:图片生成器 image generator的第一步是 图片信息生成器(粉色模块),这也是SD模型和普通扩散模型的区别所在,也是性能提升的关键。
图片信息生成器的输入输出均为低维图片向量,同时文本编码器的语义向量作为图片信息生成器的控制条件,把图片信息生成器输出的低维图片向量进一步输入到后续的图片解码器(黄色)生成图片。
Step 3:图片解码器(黄色模块)是图片生成器 image generator的第二步。
将图片信息生成器的低维空间向量(粉色 4*4 方格)输入到图片解码器,通过升维放大可得到一张完整图片。由于输入到图片信息生成器时做了降维,因此需要增加升维模块,也是获得一张生成图片的最终步骤。
那么在扩散过程中发生了什么?扩散过程发生在图片信息生成器中,把初始纯噪声隐变量输入到 Unet 网络后结合语义控制向量,重复 30~50 次来不断去除纯噪声隐变量中的噪声,并持续向隐向量中注入语义信息,就可以得到一个具有丰富语义信息的隐空间向量(右下图深粉方格)。采样器负责统筹整个去噪过程,按照设计模式在去噪不同阶段中动态调整 Unet 去噪强度。
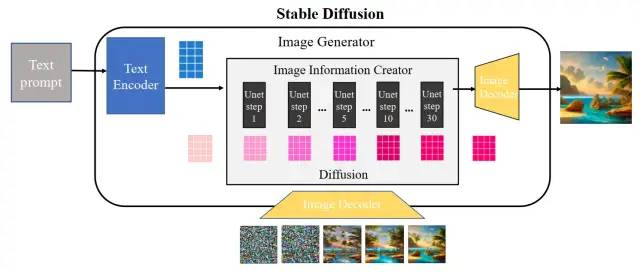
如上图所示,通过把初始纯噪声向量和最终去噪后的隐向量都输到后面的图片解码器,观察输出图片区别。从图中可以看出,纯噪声向量由于本身没有任何有效信息,解码出来的图片也是纯噪声;而迭代 50 次去噪后的隐向量已经耦合了语义信息,解码出来也是一张包含语义信息的有效图片。


SD模型与验证图片的结合
SD 模型引入了稳定扩散技术,使得模型在训练过程中更加稳定、高效。这一结构让 SD 模型能够产生高度复杂的验证码图片,它突破了传统验证码系统中存在的诸多问题,如易受攻击、低效率、难以调优等,为验证码系统带来了革命性的变化。
更安全
以光影文字为例,SD 光影文字是一种比艺术二维码更抗识别的艺术图,主要由 Stable Diffusion 的 ControlNet 插件制作而成。我们将光影文字应用于文字点选验证,它能让文字笔画很含糊,通常生成是错误的文字但真人能识别出来,而识别模型却因为笔画错误或精准度低而无法识别,从而使黑产的识别模型产生视觉偏差,无法通过验证。


例 1 为极验将光影文字应用于验证码中的示例。放大来看,“冰”、“拿”、“铁”三个字都由白云与建筑物的光影虚幻而成,虽然不影响真人的肉眼判断,但黑产的识别模型却因为笔画错误而无法正确识别,从而无法通过验证。

在例 2 中,真人很容易分辨出验证答案为:“曲奇”、“黑森林”、“果冻”、“蓝莓”,而黑产的识别模型捕捉到的却是一些背景中的错误元素。由于 SD 光影能够和底图完美融合,通过光影偏差、重叠、错位等方式与正确的字产生偏差,因此能够让黑产模型判断失误,从而无法正常识别验证图片。我们共测试了5000张 SD 光影图片,发现模型识别的失败率高达99.74%。
利用 AIGC 构建验证码图片的最大难点是在保证图片准确、可控的同时,增加验证码的复杂度,以抵御黑产的各种自动化攻击。传统的验证码系统往往通过简单的字符扭曲、背景干扰等手段来增加难度,但这种方法很容易被智能算法攻破,一旦黑产通过大量机器学习训练出了识别模型,就能轻松破解。而 SD 模型通过稳定扩散技术,能够生成高质量、高难度的验证码图片,利用视觉偏差提升了黑产模型识别的难度,有效地解决了安全难题。
更美观
SD 模型采用了先进的人工智能生成对抗网络(AIGC),利用 SD 模型生成的验证图片是传统验证的一大革新,在更高效防御黑产攻击的同时,也具备出色的真实感与视觉美观,与传统验证码相比色彩鲜明、分辨率高,带来了更好的用户体验。下图为极验利用 SD 光影文字融合生成图片的过程,通过一步步调节参数来寻找安全效果与用户体验的最佳平衡。

极验 CEO 吴渊曾指出:“人机验证码设计的难点在于,在最大限度的阻止机器脚本攻击的同时,还需要兼顾正常用户的体验度。” 在这个基础上,极验验证码首创八种行为验证模式,包括滑块拼图验证、文字点选验证、图片识别验证、语音播报验证等。现在,我们利用 SD 模型将 AIGC 与文字点选验证结合,发现用户很喜欢这种创新的验证方式。 AI 生成的图片更生动有趣、轮廓和图标元素更清晰,用户平均3秒内就能通过验证,是传统验证码四分之一都不到的时间。
更高效
相比传统验证码需要人为地设计、产出图片,SD 模型只需要输入原始的文本提示,就能快速得到任何我们想要的验证图片,大大节省了图片设计的人力与时间成本,提高了图像生成的效率。
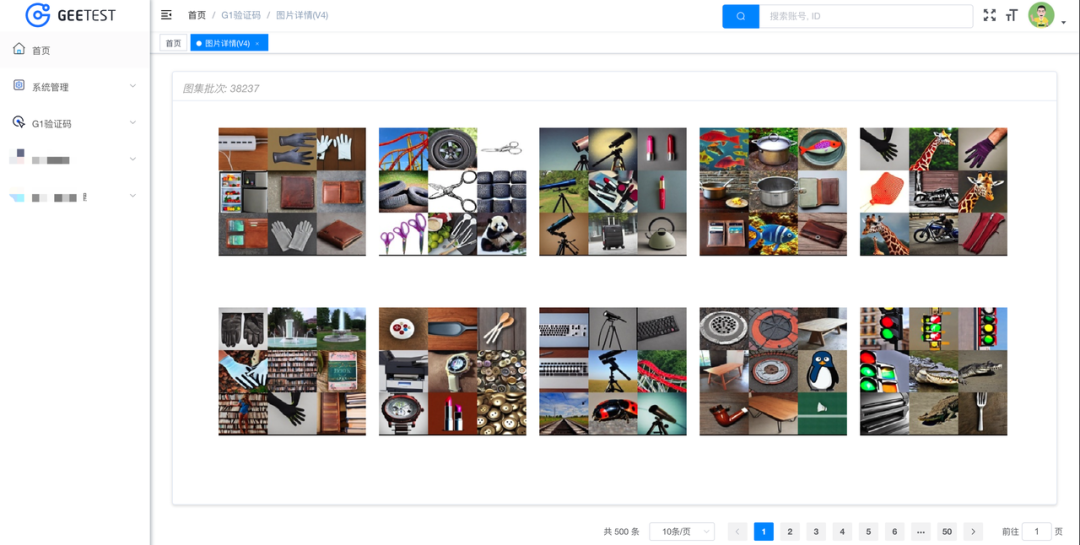
极验的第四代适应型验证,首次开发了一套图集自动更新系统,通过制作生成模板,高效高频地更新验证资源,使得黑产无法再通过穷举法破解验证码。目前,极验在不断探索 AIGC 与验证码结合的艺术创作的同时,也正在尝试解决高质量批量生成图像的问题,图像生成的速率提升了30%。下图为极验在短时间内利用 SD 模型生成的部分验证码图片示例:

经过大量实验和验证,SD 模型与验证图片结合的效果得到了充分证实。与传统的验证码系统相比,SD 模型在安全性、准确性和用户体验方面均表现出色。同时,SD 模型在生成验证码图片的速度上也有了显著的提升,大大提高了验证码系统的响应效率。结合稳定扩散技术和生成对抗网络,SD 模型生成的验证码图片难以被黑产现有的攻击手段破解。这种高度的安全性使得 SD 模型在人机识别领域具备了广泛的应用前景。
利用SD模型构建验证码的技术突破
SD 模型将“图像生成”过程转换为逐渐去除噪声的“扩散”过程,整个过程从随机高斯噪声开始,经过训练逐步去除噪声,直到不再有噪声,最终输出更贴近文本描述的图像。这个过程的缺点是去噪过程的时间和内存消耗都非常大,尤其是在生成高分辨率图像时。大批量素材生成涉及到计算资源投入产出比问题,以及后续 gpu 资源的调度和扩展。
因此,这里我们有三个诉求:
(1)模型服务化,尤其是涉及到大模型,必然会存在 gpu 的调用,这部分资源在云上成本比较高。
(2)在初期,为了把控一次性投入,希望即能使用到 gpu 资源又能按量付费,避免昂贵的月租,提高资源利用率。
(3)模型服务代码量尽可能小,且便于横向扩展。
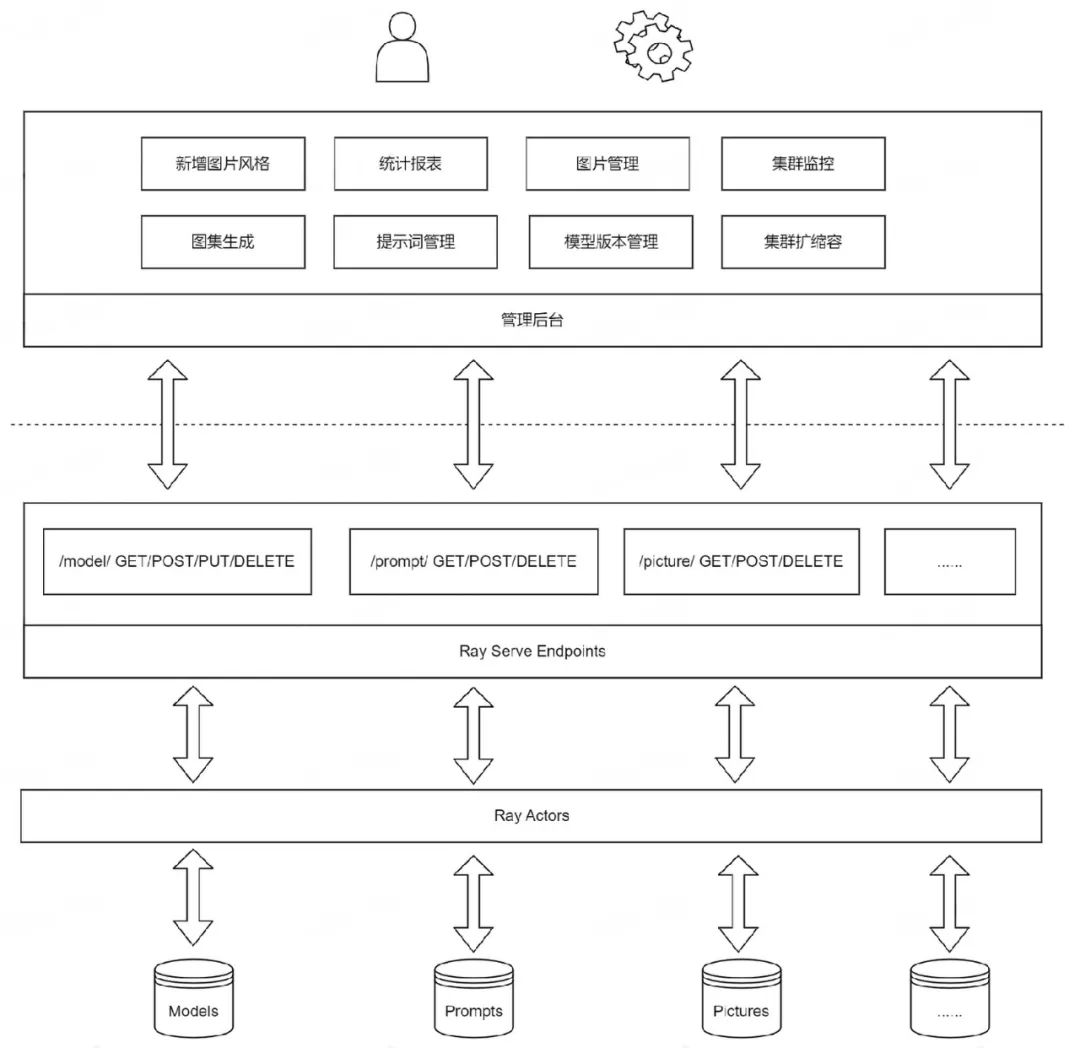
为此我们基于 Ray 和 K8s 构建了如下的模型服务:
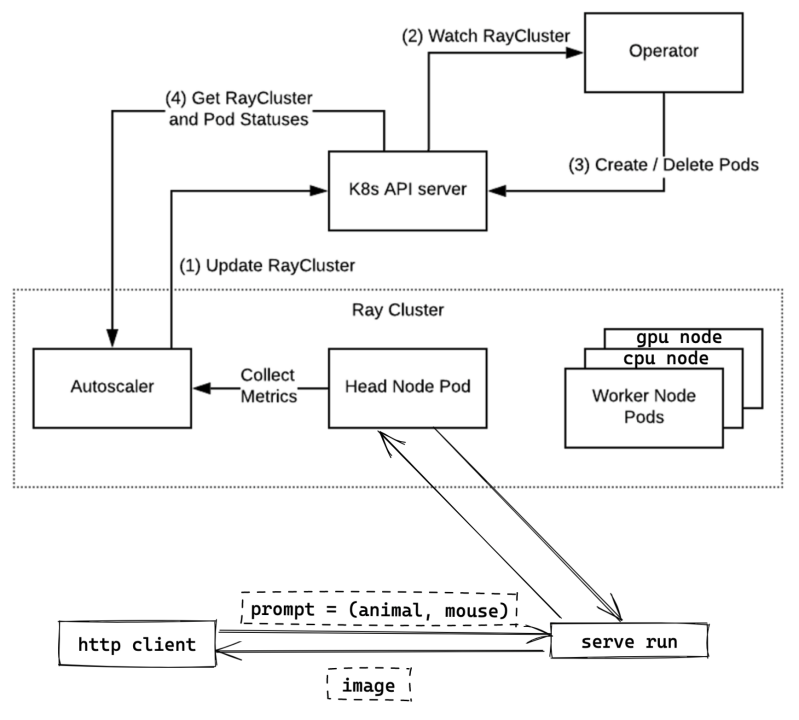
通过上图所示架构,我们可以以最小的代码量来部署一个模型服务,极大减少了内存和计算成本。
同时,针对图集的批量管理和生成,我们基于 ray.serve 和 SD 模型架构建了一系列的图集相关功能接口,用于提示词库的管理和图片流水线式自动化生成。
结语:与 DALL·E 和 Midjourney 相比,SD 模型最大的优势是开源,这就意味着它的的潜力巨大、发展飞快。目前,SD 模型已经与很多工具和平台进行了集成,且可用的预训练模型数量众多。正是由于社区的活跃,使得 SD 模型在各种风格的图像生成上都有着出色的表现。
SD 技术也是人机识别模型的一次重大创新,通过引入稳定扩散技术,结合生成对抗网络,实现了高度复杂、真实感强的验证码图片生成,有效地提高了验证码系统的安全性、响应效率和用户体验。未来,SD 技术将为各个领域的安全保障带来革命性的变化,我们对其发展前景充满期待。