目录
2.2 分仓、权限与依赖问题
2.3 基于 Git 进行多仓管理
Git submodule
Git subtree
Script/CMake
Git-Repo
Conan
本文来自
武让 极狐GitLab 高级解决方案架构师
🌟 前一篇文章,作者介绍了嵌入式开发场景的代码管理特点与诉求,以及该场景下的代码管理工具与方式之 SVN 与 Git。前情回顾 👉 嵌入式开发场景下的代码管理方案(上)
本文承上启下,将介绍嵌入式开发场景的代码管理分仓、权限与依赖问题,以及基于 Git 的多仓管理。
2.2 分仓、权限与依赖问题
在上文中我已经简单介绍了 SVN 和 Git 在分仓模式和权限管理上的一些区别,简单来说:
-
SVN 支持目录授权,常用于大仓模式;
-
Git 仅支持仓库授权,常用于分仓模式,也支持大仓模式。
这本是一个简单的选择题:要么留在 SVN,保留现有的目录授权模式;要么使用 Git 分仓,权限也落在不同的仓库上;要么使用 Git 大仓,权限就控制在整个仓库上;直到另一个需求打破了这个平衡:代码复用。
做过 C/C++ 且又做过 Java、Python、Node 等语言开发的技术人员常常会感叹 C/C++ 缺少好的包管理工具,羡慕 Java 有 Maven、Python 有 Pip、Node 有 Npm,而 C/C++ 一直深陷 DLL 地狱、代码版本与交付版本不一致、重复造轮子等各式各样依赖问题的泥潭,不可自拔。
首先 C/C++ 由于其语言特性,构建时常常是系统底层相关,所以打包时需要考虑操作系统、体系架构、编译器版本、构建类型等一系列因素。
且需要关注一些包自身的属性:纯头文件库、静态库还是动态库,以及包的构建参数(比如优化级别、是否开启 exception 和 rtti 的编译选项等),还有指定裁剪性(特性宏)等配置。
另外,由于 C/C++ 的标准库(glibc 和 libstdc++)存在版本兼容性问题,以及 C++ 存在 ABI 兼容性问题,这会让包的版本管理超越语义化版本(SemVer)所能解决的问题范围,导致包的创建者需要在发包的时候为包的兼容性做更多的考虑。
最后,由于 C/C++ 语言在语法上缺乏包级别的模块化机制,会让包的符号冲突以及依赖解决变得困难。如果还不够,再加上交叉编译的场景,绝对会让一个通用 C/C++ 包管理器的复杂度超过其它任何语言。
包管理器的目的就是对包进行版本控制,解决项目间的依赖问题,也能从根本上解决代码复用的问题。但由于 C/C++ 包管理器的复杂度,导致 C/C++ 开发人员在过去很长一段时间内没有包管理工具可用。在这样的背景下,大家对于 C/C++ 的代码复用发展出了很多模式:
-
基于代码文件目录划分
项目划分好模块,定义好自己的目录,协商出一个 Common 目录作为公共的头文件目录,然后对不同的开发人员分配不同的目录权限就可以分工协作了。
看起来是不是非常眼熟,这就是 SVN 的使用方式。然而这个 Common 目录可能又需要被另一个项目 B 所引用,那么项目 B 整个代码也加进这个代码库。最后所有的模块都耦合到一起,代码库膨胀的很快,导致严重的性能问题。
-
基于代码复用工具划分
由于 SVN 性能问题,很多开发者开始尝试迁移到 Git,把代码分不到不同的代码库中。但由于没有包管理工具,嵌入式的项目需要先将项目关联的代码库拉到一起,然后再构建。而 Git 本身不提供仓库之间的关联关系,这就对分库之后的聚合管理提出了需求。后来出现了 git submodule、git subtree、git repo 等工具,就是为了解决分仓后,如何把项目再聚合出来,从而实现项目管理和代码复用。
但这些都是在代码文件级别的复用,增加了管理的复杂度。
-
基于 CMake
一些构建工具的发展,为 C/C++ 的代码复用引入了更好的方式。例如 CMake 从 3.0 版本开始被称之为“Modern CMake”,是因为它引入了 target 的概念,以及基于 target 建立起了构建的依赖可见性和传播控制机制。这些都更好的支持了代码在构建上的模块化,借助 CMake 的 ExternalProject 和 find_package 特性,使得我们可以从指定的 http 或者 git 分支下载、构建、安装和引用代码库。
但是这种复用方式,对于间接依赖的管理仍旧是不足的,没有办法做到全链条的依赖解析、依赖追溯、冲突判决,以及基于变更进行最小范围的重构建和发布管理。
-
基于包管理工具
解铃还须系铃人,问题发展到最后还是回到问题本身,C/C++ 没有好的包管理工具,那就做一个。
Conan 是一款出色的开源 C/C++ 包管理器。它吸收了很多现代化包管理器的设计思想,探索解决通用 C/C++ 包管理器的各种挑战。它需要使用 Python 进行配置,目前在国内的普及度还不算高,相关的文档教程也不是很齐全,相对来说有一定的门槛,但 Conan 可以说是目前 C/C++ 唯一可用的包管理工具,也可能是真正的破局者。
这就是为什么一些软件企业从 SVN 迁移到 Git 没有那么大阻力,而从事嵌入式开发的企业则不同的原因。归根到底是 C/C++ 缺乏好的依赖管理手段,而企业、管理者、开发人员一直都面临代码复用这个问题,并希望通过从 SVN 迁移到 Git 来解决这个问题。但显然这个问题仅依靠 SVN 或者 Git 自身是无法解决的。
2.3 基于 Git 进行多仓管理
既然 Git 现在是代码管理的主流方案,并且依靠 Git 自身无法解决分仓后的多仓管理问题和代码复用问题,那就需要借助一些其他的工具和方法,其实都是上文中提到过的。虽然这些工具和方法本身不够完善,但对于处于不同阶段不同场景的企业和用户,可以有个参考,毕竟软件世界没有银弹。
Git submodule
Git submodule 可以让一个 Git 仓库作为另一个仓库的子目录,从而实现在一个代码库中引用其他的代码库进行复用。
Git submodule 的特点如下:
-
在主库中通过
git submodule add <子库 git 地址>命令实现引用子库代码; -
在主库中通过
.gitmodule文件来记录主库和子库的引用关系。

-
主库只是引用了子库的 SHA,并没有直接拷贝子库代码,所以子库的代码变更内容在主库上不可见,只是在本地拉取时将对应的子库拉取到本地。所以在 Git 服务器上看不到完整的项目代码,这也意味着无法实现对于整个项目的代码评审。


-
Clone 主库不会自动 Clone 子库,除非在 Clone 主库时:
执行
git submodule update;执行
git clone --recursive;添加 Git 全局配置
git config --global submodule.recurse true。 -
子库
commit/push也需要在主库pull/commit/push,容易遗忘导致代码未同步或者主库关联了旧的子库:可在主库执行
git submodule foreach 'git pull origin master'更新所有子库;由于该问题导致主库、子库在解决冲突、切换分支时变得非常复杂,且容易出错。
个人不建议在实际项目中使用 Git submodule,除非能有效解决以上问题,或者可在少量的项目中进行试用再进行决策。
Git subtree
Git subtree 与 Git submodule 功能类似,但目前 Git subtree 在开发人员中的呼声高于 Git submodule。
Git subtree 的特点如下:
-
在主库中通过
git subtree add --prefix=<主库子目录> <子库git地址> <子库分支>命令实现引用子库代码。
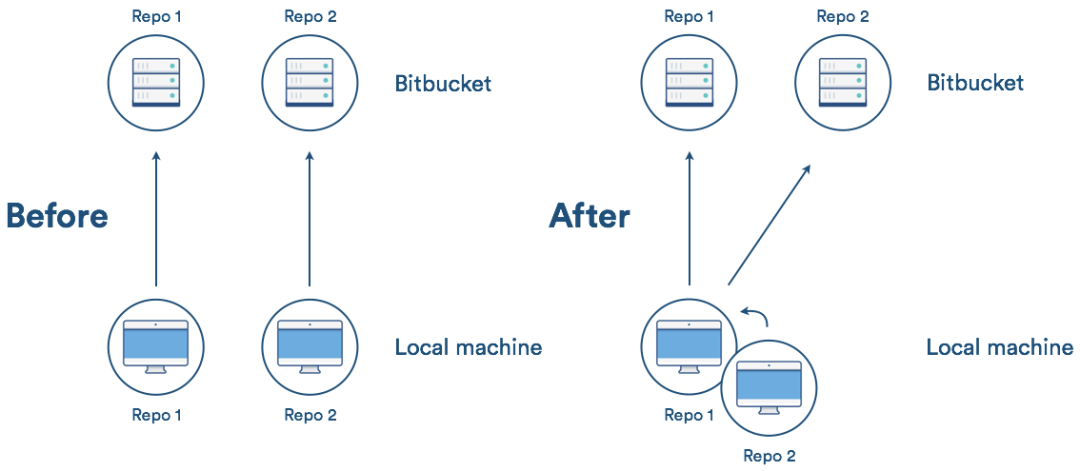
-
主库拷贝了子库的代码,所以在 Git 服务器上可以看到完整的项目代码,也可以实现整个项目的代码评审。所以
Git submodule is Link, Git subtree is Copy. 也意味着 Git subtree 的性能略差,会增加主库的大小。

-
无法通过默认的 Git 命令将主库的代码变更同步到子库,需要适应新的工作流。
# 添加子库
git subtree add --prefix=<主库子目录> <子库git地址> <子库分支>
# 从子库中拉取
git subtree pull --prefix=<主库子目录> <子库git地址> <子库分支>
# 推送到子库
git subtree push --prefix=<主库子目录> <子库git地址> <子库分支>
-
可通过一些工具和方法简化工作流:
-
设置 Git别名以简化操作:
# 在 .gitconfig 文件中添加
[alias] gits = subtree
# 然后执行命令
gits add --prefix=<主库子目录> <子库git地址> <子库分支>2. 设置子库为主库的远端别名以简化操作:
# 添加子库为主库的remote别名
git remote add -f subA <subA>.git
# 然后执行命令
git subtree add --prefix=A subA master
git subtree pull --prefix=A subA master
3. 使用第三方工具git-subrepo。
个人建议可以在依赖场景不复杂的中小型项目中使用 Git subtree,以避免性能问题,它的体验和工作方式相对比较友好。
Script/CMake
最简单的办法往往最有效,通过脚本来拉取或者相关子库的代码,将脚本放在主库中,按需执行,比如拉取相关子库代码:
git clone -b <子库A分支> <子库A git地址> <本地目录A>
git clone -b <子库B分支> <子库B git地址> <本地目录B>或者通过 CMake 的 FetchContent 来实现,可以参考《C++ 工程依赖管理新方向:CMake & Git | KC 的废墟堆》,基于 FetchContent 可以再封装一套脚本。
个人建议也是可以在依赖场景不复杂的中小型项目中使用,比较轻量和灵活,但有一定的技术门槛,甚至需要专人来做,这对做传统嵌入式开发的团队是个挑战。
Git-Repo
Git-Repo 是 Google 开源的一款 Git 客户端工具,是为了搭配 Google 开源的代码管理工具 Gerrit 进行使用,而 Gerrit 是为了管理 Android 的开源项目 AOSP 而设计的。
Google 是为数不多的坚持大仓模式(Monorepo)的巨头公司,AOSP 也是一个大型项目,一个项目包含了数百个代码库,彼此之间存在依赖关系。所以为了更好的管理这些仓库,Google 形成了自己独特的 AOSP 工作流,Gerrit 通过一个项目清单 Manifest.xml 来组织仓库关系,Git-Repo 就可以通过 Manifest.xml 来实现代码的批量拉取和推送。
Git-Repo 和 Gerrit 主要是解决了多仓管理的问题,除了对仓库进行批量操作,Gerrit 还支持跨代码库进行评审,所以 AOSP 从流程到系统到工具都是相辅相成的。Git-Repo 可以在一定程度上解决代码复用问题,不过 Gerrit 本身不是商业化产品,没有厂商技术支持,且 Gerrit 的用户体验较差,复杂度较高,所以当嵌入式项目使用 AOSP 专用的工具,又显得有点水土不服。
借鉴 Git-Repo 和 Manifest.xml 的思想,阿里使用 Golang 重写了一个 Git-Repo-Go 工具,可以在 GitLab/极狐GitLab、GitHub 等以 Git 为底层的代码管理系统上获得 Git-Repo 批量操作代码库的体验。
但是上文中也提到,Git-Repo 和 Gerrit 是相辅相成的,Gerrit 支持跨代码库进行代码评审,支持更丰富的权限管理模式,为多仓下的代码管理和评审提供了基础。而 GitLab/极狐GitLab、GitHub 等代码管理系统目前还是以分仓模式为主,原生不提供这种业务功能,所以导致 Git-Repo-Go 仅仅是实现了 Git-Repo 的部分功能,这时不免怀疑这么折腾为啥不直接用 Gerrit。
Conan
终极方案,如果项目依赖相对复杂,需要在项目级别进行代码评审,且要考虑依赖解析、循环依赖、依赖追踪等问题,那么以上工具方案都不用考虑了,它们都无法从根本上解决问题,所以 Conan 这个工具必须死磕下来,不管是头文件、静态库还是动态库的管理,Conan 都能在一定程度上满足,虽然它本身具备一定的复杂性,但目前没有更好的路可以走了。
当然如果愿意快速解决问题,知名制品库厂商 JFrog 提供了 Conan Center 以及相关解决方案,我就不多打广告了。如果愿意折腾,Conan 本身开源,且可以通过 SonaType 的开源制品库 Nexsus 实现,这也变相提供了另一种“低成本”的方案。
💡 后续推送剧透:围绕企业对于嵌入式开发场景的诉求,极狐GitLab 提供了一整套解决方案,可以较好的解决嵌入式开发场景下的种种问题,下期将为你介绍。
欢迎订阅关注~