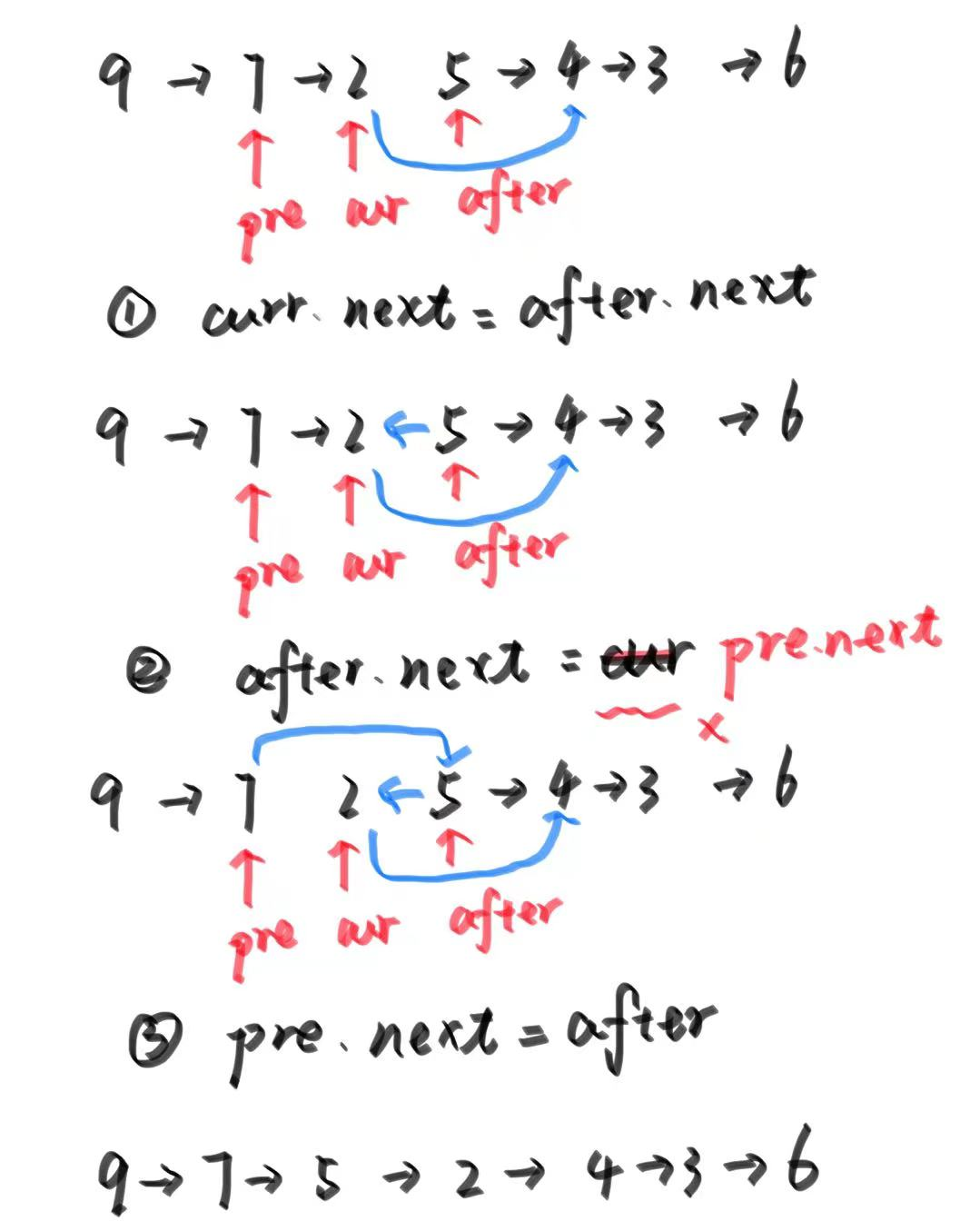任务介绍
该项目基于DROW3和DR-SPAAM模型,实现了实时的2D激光雷达行人检测。 主要处理流程为:输入预处理后的激光雷达点云序列(帧)->行人检测模型推理->行人检测模型后处理->检测结果输出及可视化。
由于二维距离数据信息量低,使用二维激光雷达进行人员检测是一项具有挑战性的任务。为了缓解激光雷达点稀疏引起的问题,目前最先进的方法是融合以前的多次扫描,并使用联合扫描执行检测。这种向后看的融合的缺点是所有扫描都需要显式地对齐,而必要的对齐操作会使整个管道更加昂贵——通常对于现实应用程序来说太昂贵了。人检测网络,它使用一种替代策略来结合不同时间获得的扫描。我们的方法,距离鲁棒空间注意和自回归模型(DR-SPAAM),遵循了一个前瞻性的范式。它将来自骨干网的中间特征保留为模板,并在新的扫描可用时周期性地更新模板。更新后的特征模板依次用于检测当前场景中的人员。DR-SPAAM是一种基于深度学习的人检测器,可以检测从激光扫描仪获得的二维距离序列中的人。它可以基于其空间相似性模块生成简单的轨迹小波。
本案例主要介绍如何利用获取的基于MindSpore框架的2d激光雷达行人检测(包括数据集和模型代码),在MindStudio中进行模型的转换和MindX SDK的开发部署。参照此案例,可以实现模型在昇腾设备上的部署。
主要难点:由于该模型的输入为序列,输出后无法做到与真实图像进行对比,只能进行精度的验证。
环境配置
整个开发环境的搭建主要分为两部分:服务器端开发环境安装和配置、本地开发环境的安装和配置。一般来说,服务器端的环境配置工作都提前完成了(比如CANN和MindX SDK的安装),因此本文主要以Windows环境为例,介绍本地开发环境安装和配置的流程。
需要注意的是,关于CANN和MindX SDK的安装,网上的教程比较多,对于第一次接触的开发者来说,容易搞混的是服务器端和本地的安装教程。服务器端都是Linux操作系统,MindX SDK可以通过图形界面方式在线或离线安装,也可以通过命令行方式进行离线安装,CANN只能通过命令行方式安装;本地端我们使用的是Windows,一般都是通过MindStudio的图形界面将服务器端的CANN和MindX SDK同步到本地。
对于DROW3和DR-SPAAM模型或者其他的模型,本地环境的搭建和配置应该如按如下流程:MindStudio软件安装——SSH远程连接——CANN配置——推理源码和数据准备——昇腾工程转换——MindX SDK配置
MindStudio软件安装
介绍
MindStudio是一套基于华为自研昇腾AI处理器开发的AI全栈开发工具平台,其功能涵盖面广,可以进行网络模型训练、移植、应用开发、推理运行及自定义算子开发等多种任务。就使用而言,整体界面风格和python开发常用的PyCharm相似。熟悉PyCharm工具的开发者使用MindStudio进行开发能够很快上手。
安装
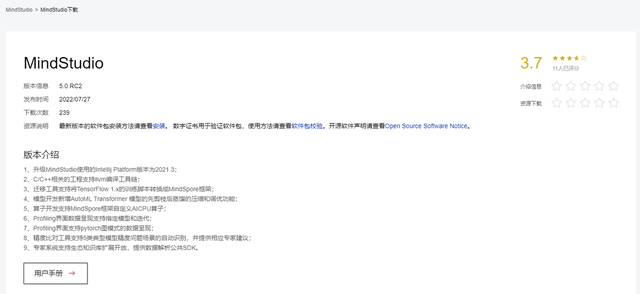

MindStudio的安装已经在其官网上的用户手册中有了详细介绍。作者使用的操作系统为window 10,点击下载上图中的exe或zip文件进行安装。注意一下MindStudio和CANN的版本对应关系:在MindStudio下载界面的最下面的版本配套中就说明了当前MindStudio版本对应的CANN版本。
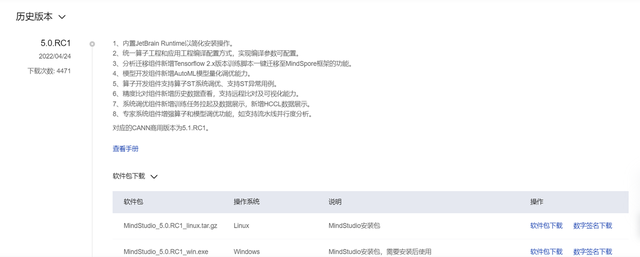
笔者在安装的时候MindStudio的版本已经更新到了5.0.RC2,但是需要安装旧的5.0.RC1版本,可以在下载页面的历史版本中找到。
Python版本问题: 由于需要使用MindX SDK的功能,必须使用3.9版本的python。故需要确保python版本是否正确。
SSH连接
安装了MindStudio以后就要进行SSH连接,目的是将本地的软件与服务器进行连接。点击File->Settings->Tools->SSH Configurations,选择+号添加新的SSH配置。
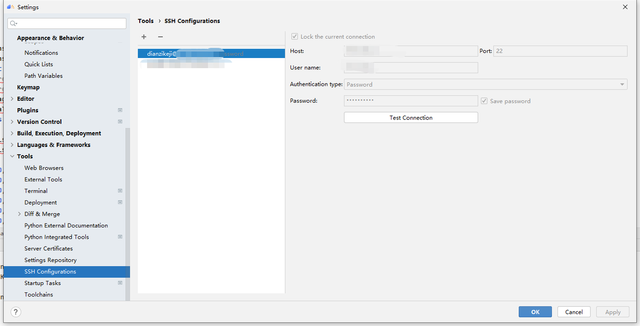
将服务器IP地址、端口、密码或密钥文件填入,点击Test Connection,提示连接成功即可。
这里需要注意的是授权类型有两种,一种是密码,一种是密钥文件,本文选择使用.pem格式密钥文件。服务器地址、密码或密钥文件可通过华为云申请试用或购买获得。

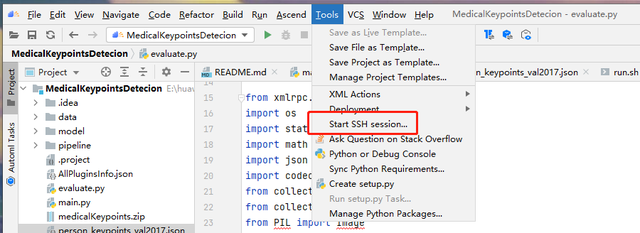
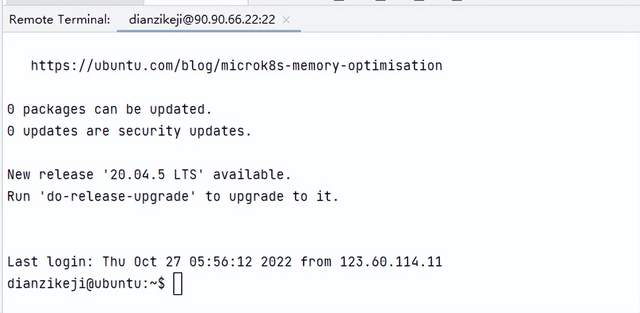
配置好了SSH以后,点击Tools-->Start SSH Session,即可连接服务器端。MindStudio在界面正下方会弹出Remote Terminal,就可以输入各种命令操作远端服务器了。
CANN配置
CANN介绍
CANN(Compute Architecture for Neural Networks)是华为公司针对AI场景推出的异构计算架构,通过提供多层次的编程接口,支持用户快速构建基于昇腾平台的AI应用和业务。
CANN 配置
在Windows上配置CANN,实际上是使用MindStudio把服务器端的安装包同步到本地。进入File->Settings-> Appearance & Behavior ->System Settings->CANN页面,点击右边的change CANN,在弹出的对话框中填写服务器端的CANN的地址。我们的MindStudio版本是5.0.RC1,因此CANN的版本需要安装5.1.RC1。然后就等待软件将服务器端的CANN同步到本地。

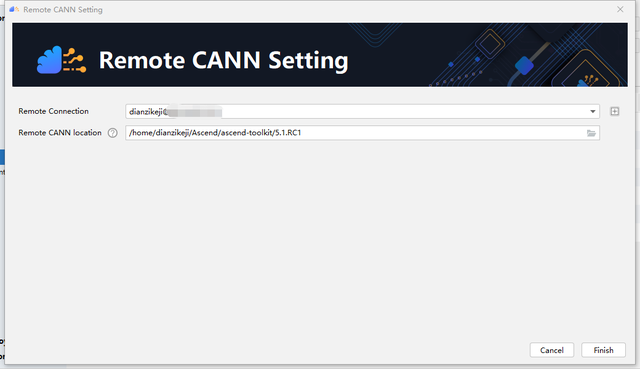

需要注意的是,在MindStudio中,如果没有安装CANN,是不能够将下载的源码转换为Ascend Project的。点击Ascend->Convert to Ascend Project,会提示没有安装CANN,无法转换。

这一步是安装MindX SDK的前提,否则在Settings中左边的菜单栏就不会有MindX SDK选项。在完成了CANN安装以后,可以点击Ascend->Convert to Ascend Project,进行工程转换的操作了。
推理源码和数据准备
介绍
上面我们介绍了如何正确安装和运行MindStudio工具。接下来准备模型转换和SDK开发所需要用到的数据。主要包括:模型推理代码、预训练模型、数据集。
模型推理代码
这里提供了全模型的网盘链接,可以直接下载。网盘内容如下图。链接:
https://pan.baidu.com/s/1F0QymfjGXsxEPKNhGlYKZg?pwd=9u0b 提取码:9u0b 。

本项目一共有两个模型及两个数据集。其中,DROWv2文件夹下为小数据集(已在网盘链接中DROWv2文件夹内提供),另一个数据集JackRobbot数据量较大,在这里没有使用,提供下载链接供开发者使用:
https://jrdb.stanford.edu/
图中,LaserDet文件夹下存放各种执行所需的脚本文件。Pipelines为需要调用的所对应的4个pipeline文件。主函数为release_lidar_main.py。具体细节可参考README.
接下来大致介绍release_lidar_main.py的主体流程。
1)输入类型是 2D LIDAR 每一帧的数据。对于DROW3 类型数据集,raw格式为在cononical坐标下的LiDAR 点云,每个文件为一个单控的序列,每个序列内包含多个帧。对于IRDB类型数据集,点云提供了主要的信息,同时增加了基于图像标注的伪标签。对于原始输入文件需要被提前处理成符合模型输入的格式。
数据预处理的流程主要写于
LaserDet/srcs/drow_handle.py(jrdb_handle.py)内。

2)通过调用MindX SDK 提供的buffer解码插件mxpi_buffer,解码后获取模型推理过程的输入数据。然后调用MindX SDK的mxpi_tensorinfer插件,将解码后的数据输入DROW3/DR_SPAAM模型进行推理。下图为输入与输出的调用代码段。
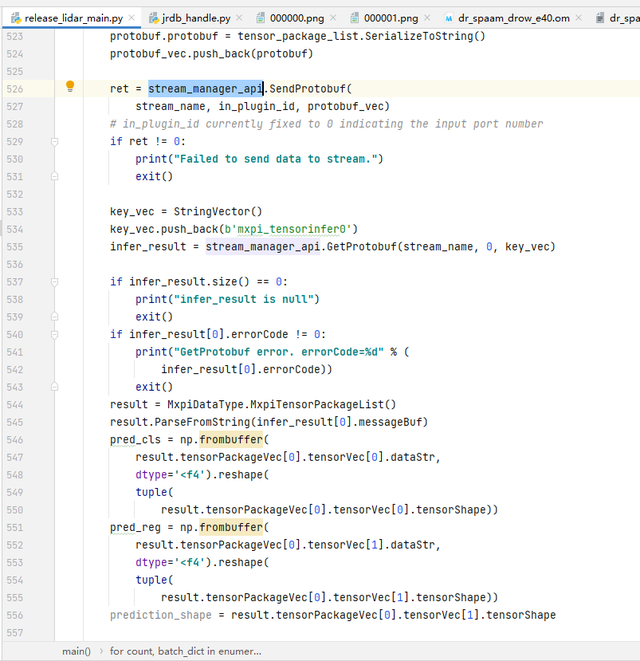
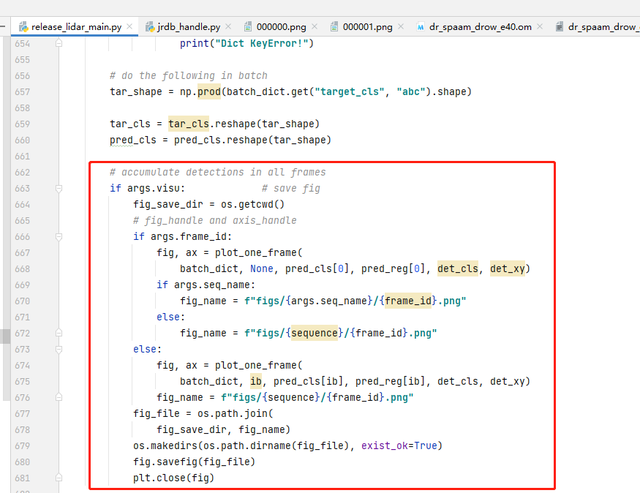
3)待数据推理完毕后,进行数据的后处理,检测输出结果需要进行坐标变换,由canonical转换为global坐标,再由global坐标转换为XY坐标,如果检测的两点之间距离过近,则认为是重复点,取均值保留。输出所有检测结果,并可视化。下图为可视化的部分代码。
预训练模型
在SDK推理阶段需要使用已完成训练后生成的模型文件,后缀为.onnx。

为了方便大家使用,上述源码链接中models文件夹内已包含了预训练模型。文件名格式为“模型名_数据集名_epoch数.onnx”。读者可按照自己所需要的onnx进行测试。
上传远端服务器
点击Tools-->Deployment-->upload上传准备好的代码、模型和数据集到远端服务器,此过程需要花费比较长的时间,需要耐心等待。如果因网络问题传输失败,重新upload即可覆盖原来的文件。这里需要注意的是,如果upload单个文件反复提示失败,可能需要检查一下服务器的硬盘空间是否已满,如果已满,需要整理一下服务器的存储空间,尽可能多空出一些空间来。

这里我们以远端服务器地址
/home/dianzikeji/MindStudio-WorkSpace/2D-LIDAR_1aa03018/为例进行后续的讲解,假设所有的代码和数据集已经上传至这个目录下了。
昇腾工程转换
介绍
相比于PyCharm,MindStudio增加了对华为昇腾系列芯片相关的开发支持,所以在MindStudio中创建的工程可以简单分为昇腾工程和非昇腾工程,其中昇腾工程特指需要昇腾芯片的相关工程,包括训练,推理,算子开发等等。特别的,MindStudio还支持非昇腾项目到昇腾项目的一键转换,方便其他IDE项目的转移。本项目是在昇腾310推理服务器上实现基于MindSpore 框架编写的DROW3和DR-SPAAM模型的部署推理,因此需要将代码转换为为昇腾工程。
工程转换
在源码和数据集都下载好的前提下,直接在MindStudio中点击左上角的file->open 打开之前下载下来的模型代码文件夹。工程界面和目录如下:

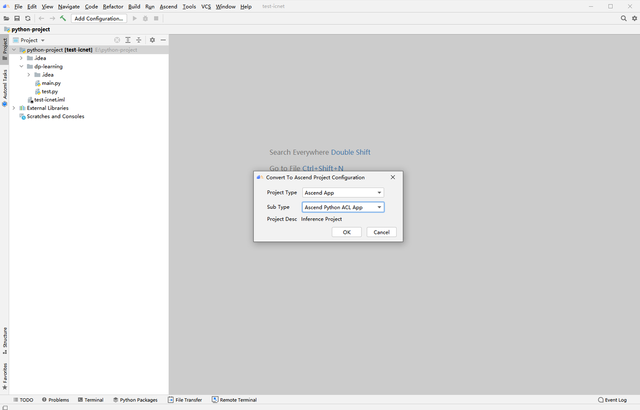
目前工程只是一个非昇腾工程,单击菜单栏 “Ascend > Convert To Ascend Project”。弹出如下窗口。这里针对该项目,Project Type选择Ascend App,Sub Type选择Ascend Python ACL App。如下图
完成工程转换后,可以看到在菜单栏多出了一栏蓝色的图标,是MindStudio为昇腾系列所特别支持的开发功能。

我们也可以通过Ascend下拉菜单查看这些功能, 下面列出了我们用到的一些功能模块。
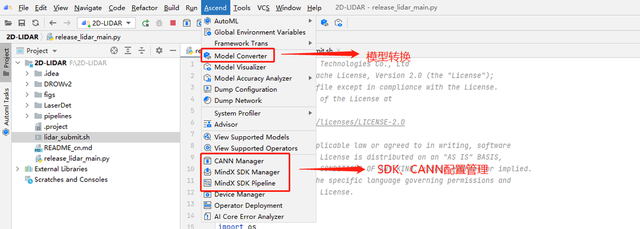
MindX SDK配置
MindX SDK介绍
MindX SDK提供昇腾AI处理器加速的各类AI软件开发套件(SDK),提供极简易用的API,加速AI应用的开发。

应用开发旨在使用华为提供的SDK和应用案例快速开发并部署人工智能应用,是基于现有模型、使用pyACL提供的Python语言API库开发深度神经网络应用,用于实现目标识别、图像分类等功能。
通过MindStudio实现SDK应用开发分为基础开发与深入开发,通常情况下用户关注基础开发即可,基础开发主要包含如何通过现有的插件构建业务流并实现业务数据对接,采用模块化的设计理念,将业务流程中的各个功能单元封装成独立的插件,通过插件的串接快速构建推理业务。
MindX SDK配置
和上面的CANN类似,SDK的配置指的是从服务器端将安装好的mxManufacture 或者是mxVision同步到本地(这两者的差异似乎并不是特别大,很类似)。本文中使用的是mxVision 3.0.RC1。具体的配置方法如下:
进入File->Settings-> Appearance & Behavior ->System Settings->MindX SDK页面,在右边点击Install SDK,

填写远端CANN位置,同上一步;填写远端SDK的位置
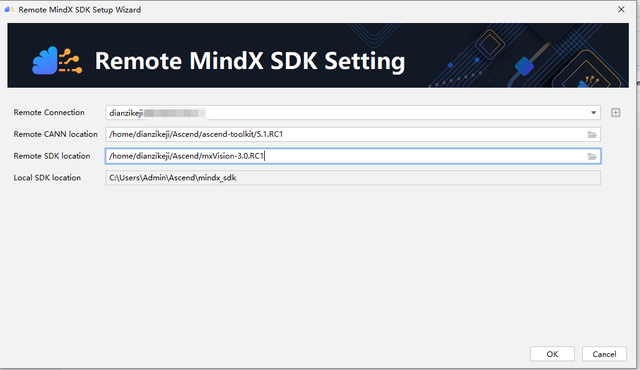
需要注意mxVision的位置,如果该文件夹下还有其他同名文件夹mxVision-3.0.RC1,需要选到最底层的mxVision-3.0.RC1。否则会报错。
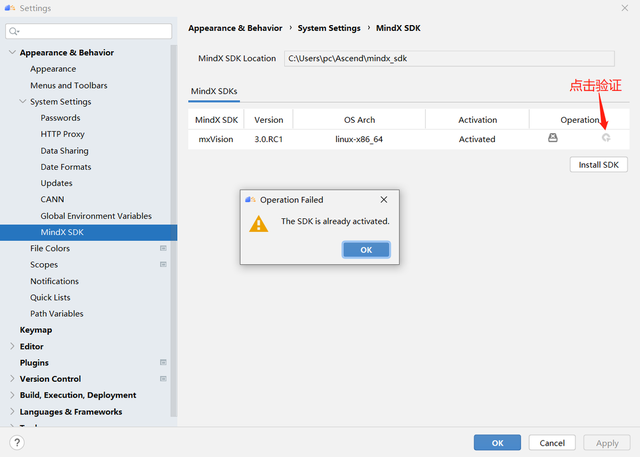
最后等待SDK同步,点击如下按钮可以验证是否已经成功配置了SDK:
任务运行
本章的工作是介绍如何使用MindStudio成功运行推理任务,有了上面的准备工作,下面的任务就变得比较直观了。MindStudio中的MindX SDK提供了多种可视化的操作,让一些需要代码编辑的工作通过可视化配置界面完成。本部分工作主要包括:模型转换——验证数据路径表生成——图像预处理——Pipeline编写——推理验证。
注意:由于本项目共包含两个模型与两个数据集,故共四种推理形式。由于其执行过程基本类似,在此只展示其中一种(即在drow数据集下进行DR_SPAAM模型的推理),读者可按照自己所需修改部分操作即可。
模型转换
介绍
2.4.3节提到我们已经下载了一个onnx文件,这是训练完成以后的模型,可用于模型推理。在昇腾硬件平台实际部署时,需要使用工具将此文件转换为昇腾硬件平台支持的、后缀为.om的文件。模型转换可以通过两种方式:一是代码的方式进行,在远端服务器运行atc命令即可;二是通过MindStudio的可视化操作界面进行转换。本文重点介绍可视化界面配置转换的方法。
界面配置方式
点击Ascend->Model Converter
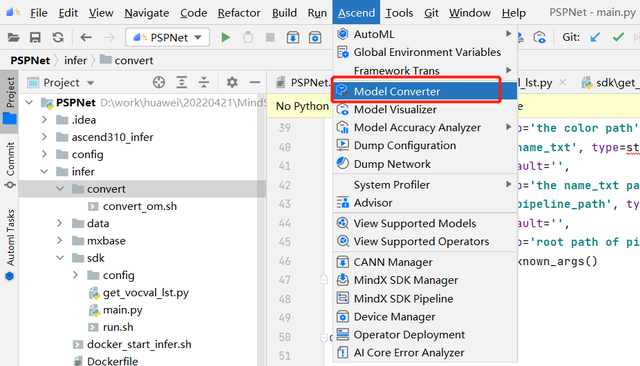
进入到配置界面,其中Model file 可以选择本地的模型文件也可以选择服务器端的模型文件,如果选择了本地的呢,需要耐心等待本地端的模型文件上传至服务器。Target SoC Version选择默认的Ascend310即可。Output Path默认是不用选的,默认生成在服务器端和onnx文件同路径,如果点击选择的话,则只能选择本地路径存储生成的om文件。
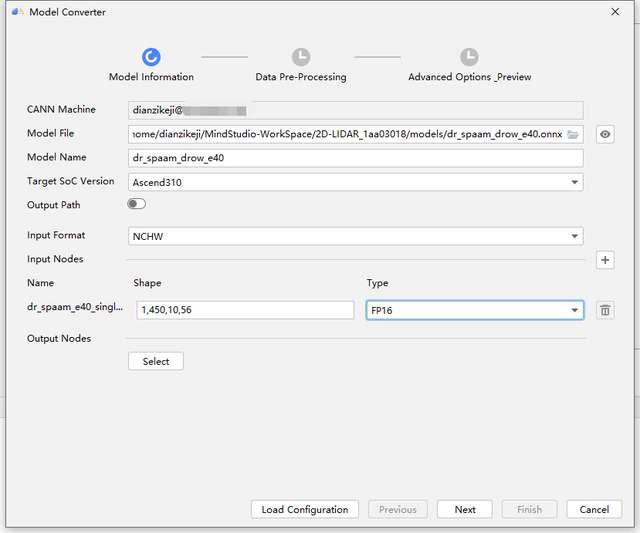
点击Next,进入到配置界面,这里也显示了实际使用到的各种命令,是一样的。我们全部选择默认即可。
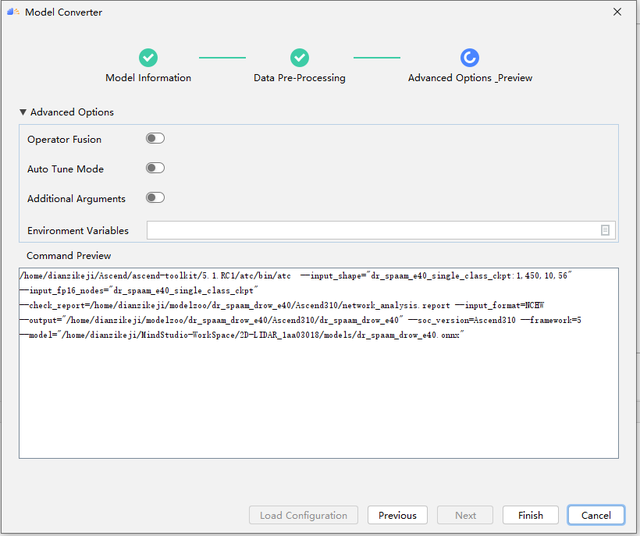
点击Finish 则系统进入到模型转换当中,右下角显示模型转换中

等待一段时间则在对话框中显示模型转换已成功。转换后的模型路径可见:

需要注意的是,如果output path不选择默认,则需要指定本地存储路径,MindStudio直接将模型转换到本地。
转换成功后会在下方出现Model converted successfully.的绿色字体。
MindStudio提供了模型可视化功能,双击om文件,如下图所示,可以查看模型结构:
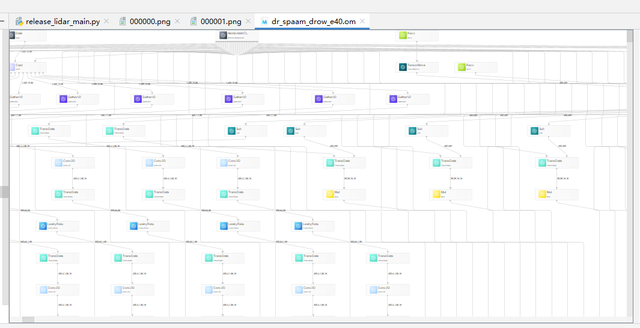
说明:需要注意的是,因为该模型数据无法使用aipp完成,所以我们将数据预处理部分直接放到了main.py中,因此在ATC模型转换时并未包含AIPP部分的参数设置。
pipeline编写
Pipeline编写可以采用直接编写代码方式或者界面配置方式。
代码方式
由于没有使用插件进行数据预处理与后处理,因此pipeline的编写就比较简单,调用发送数据插件appsrc、推理插件mxpi_tensorinfer、输出插件appsink进行编排即可,代码见pipeline文件夹内。
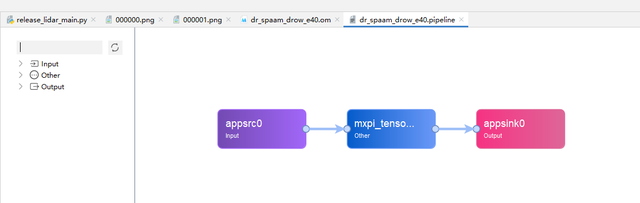
界面配置方式
也可以直接使用MindX SDK的可视化操作界面拖拽各种插件进行组合。在成功连接远端服务器的前提下,首先点击Ascend->MindX SDK Pipeline
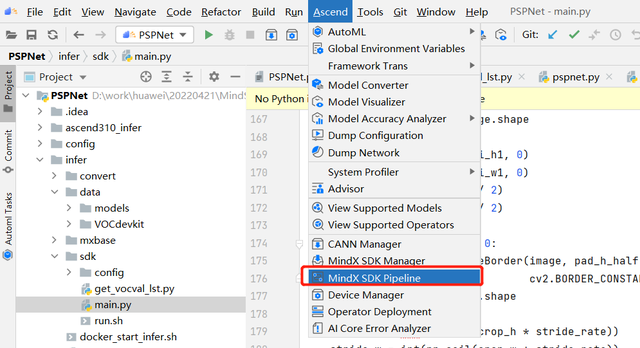
MindStudio将打开名为new.pipeline的可视化编排窗口,并且在pipeline文件的左边出现Input、Other、Output三个选项,我们可以点击三个选项,选择需要的组件拖拽到右边图形界面框中进行组合。发送数据插件appsrc在Input选项中、推理插件mxpi_tensorinfer在Other选项中、输出插件appsink在Output选项中。
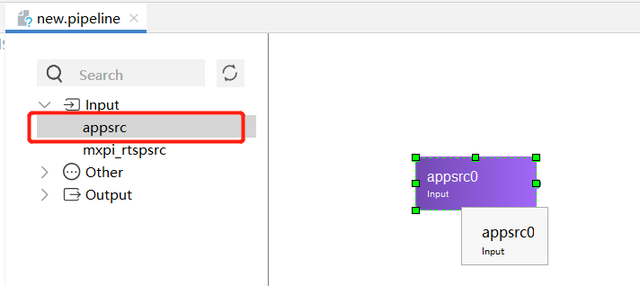


三个组件选择好了以后,拖拽箭头将其连接起来,双击mxpi_tensorinfer组件可以对其参数进行设置,这里主要是填入我们的om模型路径。编辑好了以后,点击保存并重新命名即可。

推理验证
推理验证可以使用命令行方式或者界面配置方式。
命令行方式
由于需要指定的参数比较多,我们采用脚本文件.sh的方式在验证数据集中执行推理验证任务。需要执行的脚本名为lidar_submit.sh,需按照脚本中需要的信息在命令中进行填写。
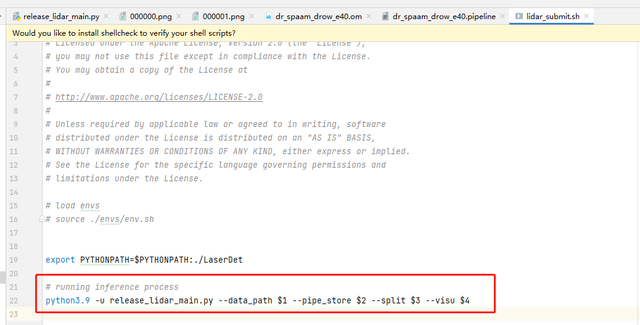
命令样式如下:
bash lidar_submit.sh --data_path $1 --pipe_store $2 --split $3 --visu $4
具体的参数说明如下:
表1 参数说明
| 参数 | 说明 |
| data_path | 数据集路径。 |
| pipe_store | Pipeline路径。 |
| split | 数据集拆分(test/val) |
| Visu | 是否需要可视化(True/False) |
命令示例如下:
bash lidar_submit.sh ./DROWv2 ./pipelines/drow3_drow_e40.pipeline test False

界面配置方式
界面配置方式是MindStudio的特色,点击工程->Edit Configurations,
弹出Run/Debug Configurations配置对话框,设置可执行文件路径Executable,即脚本lidar_submit.sh的本地路径,此外还需要在command arguments里填写需要的指令,填完后点击OK。

返回主页面点击运行图标即可运行。

注意这时需要将所有的代码、数据集重新同步到远端服务器(不管之前有没有同步过,会覆盖服务器端原来的文件夹),因此将耗费相当多的时间,如果涉及到代码调试,笔者推荐还是以命令行的方式进行推理验证。

数据同步到服务器端后,开始执行推理任务。

推理结束后会得到如下结果。
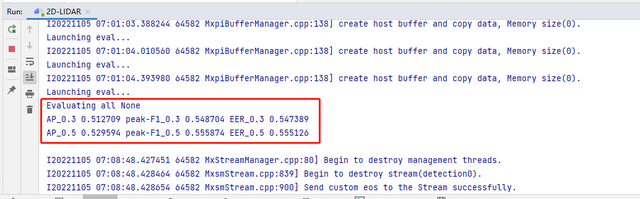
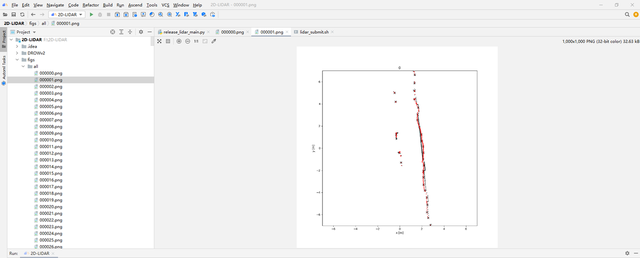
如果command arguments的最后一项visu选择True,会在figs文件夹下生成对应数据集的可视化图片。
FAQ
CANN版本和MindX SDK版本需要单独下载么?
如果需要在远端服务器上进行安装,则需要,如果是只需要配置本地端,则不需要。通过MindStudio可以同步到本地。
开发过程中遇到难题如何求助
可以登录MindStudio官方论坛,发帖提问,同时论坛里也有很多开发者分享的案例,可能对大家有所帮助。另外,在CSDN、B站、gitee、华为云上也有很多资源可以检索查找。当然更直接的办法是百度各种关键词。
第2章开头提到了“服务器端都是Linux操作系统,MindX SDK可以通过图形界面方式在线或离线安装“,这个功能如何实现?
从官网下载安装
MindStudio_5.0.RCX_linux.tar.gz文件,并完成此文件在服务器端的解压缩和安装。本地端使用Xshell远程连接到服务器(请注意本地端的MindStudio远程连接功能无法启动远程服务器端的图形界面功能,必须使用Xshell),找到~/MindStudio/bin目录中的MindStudio.sh文件,运行如下命令启动图形界面:
bash MindStudio.sh
此过程中可能提示需要安装Xmanager。启动服务器端的MindStudio,并打开服务器端的工程,和本地端的界面类似。
最后就可以使用此图形界面进行MindX SDK的安装了,方式同2.6节。
![[附源码]Python计算机毕业设计高校教务管理系统Django(程序+LW)](https://img-blog.csdnimg.cn/2f8537bff50a4b24afd61e2ca8e6d550.png)