原始套接字提供普通的TCP和UDP套接字不具备的以下3个能力:
1.有了原始套接字,进程可以读写ICMPv4、IGMPv4、ICMPv6等分组。例如,ping程序就使用原始套接字发送ICMP回射请求并接收ICMP回射应答。多播路由守护程序mrouted也使用原始套接字发送和接收IGMPv4分组。
这个能力还使得使用ICMP或IGMP的应用作为用户进程处理内核不认识的ICMP消息,而不用往内核中添加编码,例如路由器发现守护程序(Solaris 2.x上名为in.rdisc),它处理内核不认识的两个ICMP消息(路由器通告和路由器征求)。
2.进程可以读写内核不处理其协议字段的IPv4数据报。IP首部中8位IPv4协议字段中,大多数内核仅处理该字段为1(ICMP)、2(IGMP)、6(TCP)、17(UDP)的数据报,但为该字段定义的值还有不少,IANA的Protocol Numbers列出了所有取值,例如,OSPF路由协议既不使用TCP,也不使用UDP,而是通过收发协议字段为89的IP数据报而直接使用IP,实现OSPF的gated守护进程必须使用原始套接字读写这些IP数据报,因为内核不知道如何处理协议字段值为89的IPv4数据报。这个能力也延续到IPv6。
3.进程可用IP_HDRINCL套接字选项自行构造IPv4首部。
创建一个原始套接字的步骤:
1.把第2个参数指定为SOCK_RAW调用socket函数,以创建一个原始套接字,第3个参数通常不为0,例如,可用以下代码创建一个IPv4原始套接字:
int sockfd;
sockfd = socket(AF_INET, SOCK_RAW, protocol);
其中protocol参数是形如IPPROTO_xxx的某个常值,定义在netinet/in.h头文件中,如IPPROTO_IGMP。需要清楚的是,该头文件中定义了协议名并非意味着内核必然支持该协议。
只有超级用户才能创建原始套接字,这样可以防止普通用户往网络写它们自行构造的IP数据报。
2.可以在这个原始套接字上开启IP_HDRINCL套接字选项,开启时,不使用内核的IP头部信息,而是让应用程序控制IP数据包的头部信息:
const int on = 1;
if (setsockopt(sockfd, IPPROTO_IP, IP_HDRINCL, &on, sizeof(on)) < 0) {
// 出错处理
}
3.可以在这个原始套接字上调用bind,但比较少见,bind函数仅设置本地地址,因为原始套接字不存在端口号的概念。就输出而言,调用bind设置的是从这个原始套接字发送的所有数据报的源地址(在IP_HDRINCL套接字选项未开启的前提下),如果不调用bind,内核就把源IP地址设置为外出接口的主IP地址。
4.可以在这个原始套接字上调用connect,但比较少见,connect函数仅设置外出地址,因为原始套接字不存在端口号的概念。就输出而言,调用connect后我们可以把sendto函数改为write或send函数,因为目的IP地址已经指定了。
原始套接字的输出有以下规则:
1.普通输出通过调用sendto或sendmsg并指定目的IP地址完成。如果套接字已经连接,则也可调用write、writev、send。
2.如果IP_HDRINCL套接字选项未开启,那么进程让内核所发送的数据位于IP首部之后,内核将构造IP首部,并把它置于来自进程的数据之前。内核把所构造IPv4首部的协议字段设置成来自socket函数的第3个参数。
3.如果IP_HDRINCL套接字选项已开启,那么进程让内核所发送的数据是包括IP首部的整个IP数据报,进程调用输出函数写出的数据量包含IP首部的大小。整个IP首部由进程构造,但:
(1)IPv4首部中的标识字段(即每个IP数据报有的唯一的标识符,IP层维护一个计数器,每产生一个数据报,计数器就加1,然后赋给整个标识字段)可置0,从而让内核设置该值。
(2)IPv4首部校验和字段总是由内核计算并存储。
(3)IPv4选项字段是可选的。
4.内核会对超出外出接口MTU的原始分组执行分片。
原始套接字的文档中说明,如果内核提供某个协议,就要为该协议对应的原始套接字提供同样的接口(即处理原始套接字的方式要与其对应的协议的处理方式一致),这意味着某些原始套接字的处理是依赖于OS内核的,特别是IP首部字段的字节序,许多源自Berkeley的内核中,除了ip_len(整个IP数据报的长度字段)和ip_off(分片偏移字段,用于指示当前分片相对于原始数据报的起始位置的偏移量,以8字节为单位)字段采用主机字节序外,其他字段都采用网络字节序;但在Linux上,所有字段都采用网络字节序。
IP_HDRINCL套接字选项随4.3 BSD Reno引入,在此之前,应用进程想要自行构造IP首部需要使用Van Jacobson为支持traceroute而于1988年给出的一个内核补丁,该补丁要求应用进程指定第3个协议参数为IPPROTO_RAW调用socket创建一个原始套接字,IPPROTO_RAW的值为255,它是一个保留值,不允许作为IP首部中的协议字段出现。
在原始套接字上执行输入和输出的函数属于内核中最简单的一些函数,例如,在TCPv2中,原始套接字上的输入和输出函数各自约需40行C代码,而TCP的输入函数约需2000行,TCP的输出函数约需700行。
我们就IP_HDRINCL套接字选项的讲解针对的是4.4 BSD,更早的版本(如Net/2)在开启该选项后内核会在IP首部中填写更多字段。
对于IPv4,计算并设置IPv4首部之后的下一层首部的校验和是用户进程的责任,例如,在即将介绍的我们的ping程序中,我们必须在调用sendto前计算ICMPv4校验和并将它存入ICMPv4首部。
IPv6原始套接字与IPv4相比有以下差异(RFC 3542):
1.通过IPv6原始套接字发送和接收的协议首部中的所有字段均采用网络字节序。
2.IPv6不存在与IPv4的IP_HDRINCL套接字选项类似的东西,通过IPv6原始套接字无法读入或写出包含IPv6首部和任何扩展首部的IPv6分组。IPv6首部的几乎所有字段以及所有扩展首部都可以通过套接字选项或辅助数据由应用进程指定或获取。如果应用进程需要读入或写出完整的IPv6数据报,就必须使用数据链路访问。
3.IPv6原始套接字的校验和处理与IPv4不同。
对于ICMPv6原始套接字,内核总是计算并存储ICMPv6首部中的校验和,这不同于ICMPv4原始套接字,即ICMPv4首部中的校验和必须由应用进程自行计算并存储。ICMPv6与ICMPv4不同,ICMPv6的校验和中包含一个伪首部,该伪首部中的字段之一是源IPv6地址,而应用通常让内核选择该值,与其让应用进程为了计算校验和而不得不自行选择一个地址,不如由内核计算校验和更容易。
对于其他IPv6原始套接字(即不是由IPPROTO_ICMPV6为第3个参数调用socket创建的那些原始套接字),进程可以使用一个套接字选项告知内核是否计算并存储其校验和,且验证接收分组中的校验和。该选项默认是禁止的,通过把它的值设为某个非负值可开启该选项:
int offset = 2;
if (setsockopt(sockfd, IPPROTO_IPV6, IPV6_CHECKSUM, &offset, sizeof(offset)) < 0) {
// 出错处理
}
以上代码开启指定套接字上的校验和,且告知内核这个16位的校验和字段的偏移量,上例中为自应用数据开始处起偏移2个字节。可把偏移量设为-1来禁止该选项。一旦开启,内核将为该套接字上发送的外出分组计算并存储校验和,且为该套接字接收的外来分组验证校验和。
内核把哪些接收到的IP数据报传递到原始套接字遵循以下规则:
1.接收到的UDP分组和TCP分组绝不传递到原始套接字,如果一个进程想读取含有UDP分组或TCP分组的IP数据报,它就必须在数据链路层读取这些分组。
2.大多数ICMP分组在内核处理完其中的ICMP消息后传递到原始套接字。源自Berkeley的实现把除回射请求、时间戳请求、地址掩码请求外的其他接收到的ICMP分组传递给原始套接字,这3类ICMP消息由内核处理。
3.所有IGMP分组在内核处理完其中的IGMP消息后传送到原始套接字。
4.内核不认识协议字段的所有IP数据报都传到原始套接字。内核对这些分组执行的唯一处理是针对某些IP首部字段的最小验证(IP版本、IPv4首部校验和、首部长度、目的IP地址)。
5.如果某个数据报以片段形式到达,在它的所有片段均到达且重组出该数据报之前,不传递任何片段到原始套接字。
当内核有一个需传递到原始套接字的IP数据报时,它将检查所有进程上的所有原始套接字,以寻找所有匹配的套接字,每个匹配的套接字都将被递送一个该IP数据报的副本。内核对每个原始套接字执行以下3个测试,只有全部通过,内核才把收到的数据报递送到这个套接字:
1.如果创建这个原始套接字时指定了非0协议参数(socket函数的第3个参数),那么接收到的数据报的协议字段必须匹配该值,否则该数据报不递送到这个套接字。
2.如果这个原始套接字已由bind函数绑定了某本地IP地址,那么接收到的数据报的目的IP地址必须匹配这个绑定地址,否则该数据报不递送到这个套接字。
3.如果这个原始套接字已由connect函数指定了某个外来地址,那么接收到的数据报的源IP地址必须匹配这个已连接地址,否则该数据报不递送到这个套接字。
如果一个原始套接字创建时的协议参数为0,且既未对它调用过bind,也未对它调用过connect,那么该套接字将接收可由内核传递到原始套接字的所有原始数据报的一个副本。
无论何时往一个原始IPv4套接字递送一个接收到的数据报,传递到该套接字所在进程的都是包括IP首部在内的完整数据报。但对于IPv6原始套接字,传递到该套接字的只是扣除了IPv6首部和所有扩展首部的净荷。
在传递给IPv4的首部中,ip_len(长度字段,该字段原本是收到的IP数据报的总长度,此处被改为扣除IP首部后的净荷长度)、ip_id(标识字段)、ip_off(分片偏移字段)采用主机字节序,其余字段采用网络字节序。Linux上所有字段均保持网络字节序。
正如早先所提,定义原始套接字的目的在于提供一个访问某个协议的接口,因此这些字段的内容取决于OS内核。
前面提过,在原始IPv6套接字上收取的数据报中所有字段均保持网络字节序。
原始ICMPv4套接字可以收到内核接收到大多数ICMPv4消息。而ICMPv6在功能上是ICMPv4的超集,它把ARP和IGMP的功能也包含在内,因此相比原始ICMPv4套接字,原始ICMPv6套接字可能会收取多得多的分组,但使用原始套接字的应用大多仅关注所有ICMP消息的某个小子集。
为了缩减由内核通过原始ICMPv6套接字传递到应用进程的分组数量,有以下过滤器。原始ICMPv6套接字使用level参数为IPPROTO_ICMPV6且optname参数为ICMP6_FILTER的setsockopt和getsockopt函数来设置和获取,对应的值的类型为cmp6_filter结构,该类型定义在头文件netinet/icmp6.h中。
以下6个宏用于操作icmp6_filter结构:

这些宏的filt参数是指向某个icmp6_filter变量的指针,其中前4个宏修改该变量,后两个宏查看该变量。msgtype参数的取值在0~255之间,用来指定ICMP消息类型。
SETPASSALL宏指定所有消息类型都传递到应用进程;SETBLOCKALL宏则指定不传递任何消息类型。创建ICMPv6原始套接字后的默认设置是允许所有ICMPv6消息类型传递到该应用进程。
SETPASS宏允许某个指定消息类型到应用进程的传递;SETBLOCK宏阻止某个指定消息类型的传递。如果指定的消息类型被过滤器允许传递,则WILLPASS宏就返回1,否则返回0;如果指定的消息类型被过滤器阻止传递,则WILLBLOCK宏就返回1,否则返回0。
只想接收ICMPv6路由通告消息的程序的片段:
struct icmp6_filter myfilt;
fd = Socket(AF_INET6, SOCK_RAW, IPPROTO_ICMPV6);
// 先阻止所有消息类型的传递(因为默认允许所有消息类型的传递)
ICMPV6_FILTER_SETBLOCKALL(&myfilt);
// 只允许路由器通告消息的传递
ICMPV6_FILTER_SETPASS(ND_ROUTER_ADVERT, &myfilt);
Setsockopt(fd, IPPROTO_ICMPV6, ICMP6_FILTER, &myfilt, sizeof(myfilt));
尽管上例设置了只允许路由器通告消息的传递,但该应用也要做好会收到所有消息类型的准备,因为socket和setsockopt调用之间到达的任何ICMPv6消息都将被添加到接收队列中,ICMP6_FILTER套接字选项仅仅是一个优化措施。
我们接下来开发一个同时支持IPv4和IPv6的ping程序版本,我们不直接提供它的公开可得版本的源码的原因有两个:
1.公开可得的ping程序支持太多选项,我们查看ping程序的目的是了解网络编程概念和技巧,而非被众多选项分散了注意力。我们的ping程序版本仅支持1个选项,篇幅约公开可得版本的五分之一。
2.公开可得版本仅支持IPv4。
ping程序的操作非常简单,往某个IP地址发一个ICMP回射请求,该节点以一个ICMP回射应答作为响应。IPv4和IPv6都支持这两种ICMP消息,以下是这两种ICMP消息的格式:
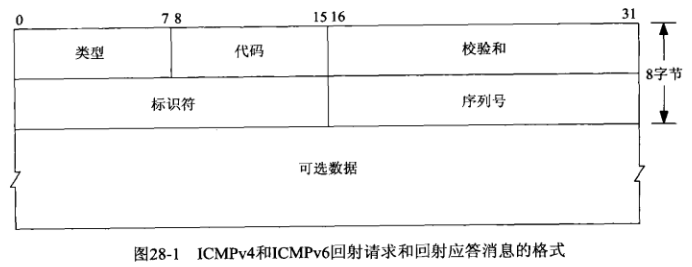
在我们的ping程序中,我们把标识符字段设为ping进程的进程ID,且为每个发出去的分组递增序列号字段。我们把分组发送时刻的8字节时间戳存放在可选数据字段中。ICMP规则要求在回射应答中返回来自回射请求的标识符、序列号、可选数据字段。在回射请求中存放时间戳可以让我们在收到回射应答时计算RTT。
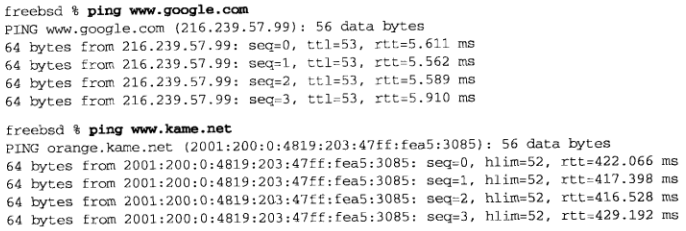
下图是我们的ping程序运行的两个例子,第一个使用IPv4,第二个使用IPv6,我们把该程序的设置用户id设为root,因为创建原始套接字需要超级用户特权:
下图是构成我们的ping程序的各个函数及其调用关系:
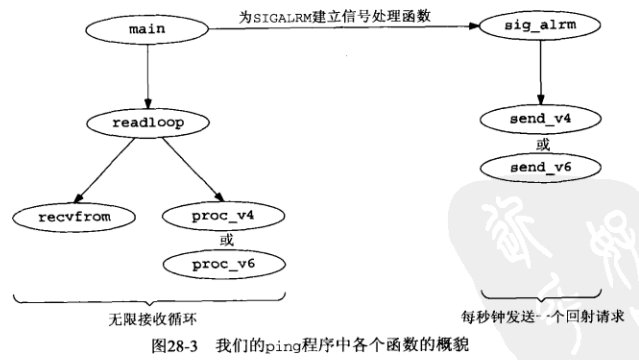
程序分为两大部分,一部分在一个原始套接字上读入收到的每个分组,显示ICMP回射应答,另一部分每隔1秒发送一个ICMP回射请求,第二部分由SIGALRM信号每秒驱动一次。
以下是所有程序文件都包含的头文件ping.h:
#include "unp.h"
#include <netinet/in_systm.h>
#include <netinet/ip.h>
#include <netinet/ip_icmp.h>
#define BUFSIZE 1500
/* globals */
char sendbuf[BUFSIZE];
int datalen; /* # bytes of data following ICMP header */
char *host;
int nsent; /* add 1 for each sendto() */
pid_t pid; /* our PID */
int sockfd;
int verbose;
/* function prototypes */
void int_v6(void);
void proc_v4(char *, ssize_t, struct msghdr *, struct timeval *);
void proc_v6(char *, ssize_t, struct msghdr *, struct timeval *);
void send_v4(void);
void send_v6(void);
void readloop(void);
void sig_alrm(int);
void tv_sub(struct timeval *, struct timeval *);
// 使用proto结构处理IPv4和IPv6之间的差异
struct proto {
void (*fproc)(char *, ssize_t, struct msghdr *, struct timeval *);
void (*fsend)(void);
void (*finit)(void);
struct sockaddr *sasend; /* sockaddr{} for send, from getaddrinfo */
struct sockaddr *sarecv; /* sockaddr{} for receiving */
socklen_t salen; /* length of sockaddr{}s */
int icmpproto; /* IPPROTO_xxx value for ICMP */
} *pr;
#ifdef IPV6
#include <netinet/ip6.h>
#include <netinet/icmp6.h>
#endif
main函数:
#include "ping.h"
// 为IPv4和IPv6各分配一个proto结构,其中的套接字地址结构指针成员均初始化为空指针
// 因为我们还不知道最终要使用的是IPv4还是IPv6
struct proto proto_v4 = {proc_v4, send_v4, NULL, NULL, NULL, 0, IPPROTO_ICMP};
#ifdef IPV6
struct proto proto_v6 = {proc_v6, send_v6, init_v6, NULL, NULL, 0, IPPROTO_ICMPV6};
#endif
// 把跟随回射请求的可选数据字段数据量设为56字节
// 由此会产生84字节的IPv4数据报(20字节IPv4首部和8字节ICMP首部)
// 或104字节IPv6数据报(40字节IPv6首部和8字节ICMP首部)
// 随同某个回射请求发送的可选数据字段必须在对应的回射应答中返送回来
// 我们在可选数据字段的前8个字节中存放回射请求发送时刻的时间戳,然后收到回射应答时就可计算RTT
int datalen = 56; /* data that goes with ICMP echo request */
int main(int argc, char **argv) {
int c;
struct addrinfo *ai;
char *h;
opterr = 0; /* don't want getopt() writing to stderr */
// 本程序只支持-v命令行选项,它使我们显示接收到的大多数ICMP消息
// 如果没有-v选项,我们将只显示属于本ping进程的ICMP回射应答
while ((c = getopt(argc, argv, "v")) != -1) {
switch (c) {
case 'v':
++verbose;
break;
case '?':
err_quit("unrecognized option: %c", c);
}
}
if (optind != argc - 1) {
err_quit("usage: ping [ -v ] <hostname>");
}
host = argv[optind];
pid = getpid() & 0xffff; /* ICMP ID field is 16 bits */
// 建立SIGALRM信号处理函数,该信号一经启动将每秒产生一次,导致每秒发送一个ICMP回射请求
Signal(SIGALRM, sig_alrm);
// host参数是一个主机名或IP地址数串,我们使用自定义的host_serv函数处理它
// 返回的addrinfo结构中含有协议族(AF_INET或AF_INET6)
ai = Host_serv(host, NULL, 0, 0);
h = Sock_ntop_host(ai->ai_addr, ai->ai_addrlen);
printf("PING %s (%s): %d data bytes\n", ai->ai_canonname ? ai->ai_canonname : h, h, datalen);
/* initialize according to protocol */
// 根据addrinfo结构中的协议族字段,初始化全局变量指针pr,让它指向正确的proto结构
if (ai->ai_family == AF_INET) {
pr = &proto_v4;
#ifdef IPV6
} else if (ai->ai_family == AF_INET6) {
pr = &proto_v6;
// 如果host_serv函数返回的是IPv4映射的IPv6地址,就报错
// 这样的地址尽管是一个IPv6地址,但发送出去的却是IPv4分组,这种情况我们可以直接改用IPv4地址
if (IN6_IS_ADDR_V4MAPPED(&(((struct sockaddr_in6 *)ai->ai_addr)->sin6_addr))) {
err_quit("connot ping IPv4-mapped IPv6 address");
}
#endif
} else {
err_quit("unknown address family %d", ai->ai_family);
}
// 把由getaddrinfo函数分配套接字地址结构用于发送目的地址
pr->sasend = ai->ai_addr;
// 分配一个同样大小的套接字地址结构用于接收
pr->sarecv = Calloc(1, ai->ai_addrlen);
pr->salen = ai->ai_addrlen;
readloop();
exit(0);
}
readloop函数:
#include "ping.h"
void readloop(void) {
int size;
char recvbuf[BUFSIZE];
char controlbuf[BUFSIZE];
struct msghdr msg;
struct iovec iov;
ssize_t n;
struct timeval tval;
sockfd = Socket(pr->sasend->sa_family, SOCK_RAW, pr->icmpproto);
// 设置进程有效用户id为实际用户id,本程序的可执行文件的设置用户id为root
// 创建原始套接字需要超级用户特权,既然套接字已经建立,该进程就可以放弃这个特权了
// 从而防止程序中潜在的漏洞被攻击者利用
setuid(getuid()); /* don't need special permissions any more */
// 如果所用协议有一个初始化函数,则调用它
if (pr->finit) {
(*pr->finit)();
}
// 设置套接字接收缓冲区大小,此值应该比默认设置大
// 用户可能对IPv4广播地址或某个多播地址执行ping,这样可能会产生大量应答
// 套接字接收缓冲区设置的越大,它发生溢出的可能性就越小
size = 60 * 1024; /* OK if setsockopt fails */
setsockopt(sockfd, SOL_SOCKET, SO_RCVBUF, &size, sizeof(size));
// 调用SIGALRM的信号处理函数发送第一个分组,并调度下一个SIGALRM信号在1秒后产生
// 如此调用信号处理函数不常见,但可以接受,它们通常是异步调用的
sig_alrm(SIGALRM); /* send first packet */
// 设置即将传递给recvmsg函数的msghdr结构和iovec结构中的恒定成员,它们在以下循环中不会被改变
iov.iov_base = recvbuf;
iov.iov_len = sizeof(recvbuf);
msg.msg_name = pr->sarecv;
msg.msg_iov = &iov;
msg.msg_iovlen = 1;
msg.msg_control = controlbuf;
for (; ; ) {
msg.msg_namelen = pr->salen;
msg.msg_controllen = sizeof(controlbuf);
// 读返回到原始ICMP套接字的每个分组
n = recvmsg(sockfd, &msg, 0);
if (n < 0) {
if (errno == EINTR) {
continue;
} else {
err_sys("recvmsg error");
}
}
// 获取分组收取时刻
Gettimeofday(&tval, NULL);
// 调用协议对应的函数(proc_v4或proc_v6)处理包含在该分组中的ICMP消息
(*pr->fproc)(recvbuf, n, &msg, &tval);
}
}
以下是tv_sub函数,它把两个timeval结构中存放的时间值相减,并把结果存入第一个timeval结构中:
#include "unp.h"
void tv_sub(struct timeval *out, struct timeval *in) {
if ((out->tv_usec -= in->tv_usec) < 0) { /* out -= in */
--out->tv_sec;
out->tv_usec += 1000000;
}
out->tv_sec -= in->tv_sec;
}
以下是proc_v4函数,它处理所有接收到的ICMPv4消息,需要知道的是,但一个ICMPv4消息由进程在原始套接字上收取时,内核已经证实它的IPv4首部和ICMPv4首部中的基本字段的有效性:
#include "ping.h"
void proc_v4(char *ptr, ssize_t len, struct msghdr *msg, struct timeval *tvrecv) {
int hlen1, icmplen;
double rtt;
struct ip *ip;
struct icmp *icmp;
struct timeval *tvsend;
ip = (struct ip *)ptr; /* start of IP header */
// IPv4首部长字段的单位是4字节,由于可能有选项字段,首部长字段的值是不确定的
hlen1 = ip->ip_hl << 2; /* length of IP header */
if (ip->ip_p != IPPROTO_ICMP) {
return; /* not ICMP */
}
// 根据IPv4首部长字段的值找到ICMP首部的开始位置
icmp = (struct icmp *)(ptr + hlen1); /* start of ICMP header */
// icmp首部长8字节,我们还需要查看ICMP数据字段中的时间戳
if ((icmplen = len - hlen1) < 8) {
return; /* malformed packet */
}
if (icmp->icmp_type == ICMP_ECHOREPLY) {
// 检查ICMP标识符字段,判断是否是本进程发出的请求对应的应答
// 如果本主机上运行着多个ping进程,那么每个进程都会得到内核接收到的所有ICMP消息的一个副本
if (icmp->icmp_id != pid) {
return; /* not a response to our ECHO_REQUEST */
}
if (icmplen < 16) {
return; /* not enough data to use */
}
// 获取收到的ICMP应答的可选数据字段中的时间戳
tvsend = (struct timeval *)icmp->icmp_data;
// 计算RTT
tv_sub(tvrecv, tvsend);
// 将RTT转换为毫秒
rtt = tvrecv->tv_sec * 1000.0 + tvrecv->tv_usec / 1000.0;
// 输出内容中有序列号,能使用户查看是否发生过分组丢失、错序、重复
printf("%d bytes from %s: seq=%u, ttl=$d, rtt=%.3f ms\n", icmplen,
Sock_ntop_host(pr->sarecv, pr->salen), icmp->icmp_seq, ip->ip_ttl, rtt);
// 如果用户指定了-v选项,则显示接收到的所有ICMP消息的类型字段和代码字段
} else if (verbose) {
printf(" %d bytes from %s: type = %d, code = %d\n", icmplen,
Sock_ntop_host(pr->sarecv, pr->salen), icmp->icmp_type, icmp->icmp_code);
}
}
下图是ICMPv4数据报结构:
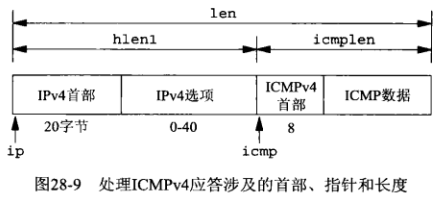
ICMPv6消息的处理由proc_v6函数完成,它类似于proc_v4函数,但由于IPv6原始套接字不返回IPv6首部,它就以辅助数据形式接收ICMPv6分组的跳限,接收这个辅助数据要求预先为所用的原始套接字开启相关套接字选项,这是由init_v6函数完成的。init_v6函数代码如下:
void init_v6() {
#ifdef IPV6
int on = 1;
// 如果用户没有指定-v选项,则在所用的原始ICMPv6套接字上安装一个过滤器
// 阻止除回射应答外的所有ICMPv6消息,这样可以缩减该套接字上收取的分组数
if (verbose == 0) {
/* install a filter that only passes ICMP6_ECHO_REPLY unless verbose */
struct icmp6_filter myfilt;
ICMP6_FILTER_SETBLOCKALL(&myfilt);
ICMP6_FILTER_SETPASS(ICMP6_ECHO_REPLY, &myfilt);
setsockopt(sockfd, IPPROTO_IPV6, ICMP6_FILTER, &myfilt, sizeof(myfilt));
/* ignore error return; the filter is an optimization */
}
/* ignore error returned below; we just won't receive the hop limit */
// 我们不检查setsockopt函数的返回值,因为是否接收跳限无关紧要
// 收取外来分组的跳限字段的API发生过变动,但它们都是通过开启某套接字选项来完成
#ifdef IPV6_RECVHOPLIMIT
/* RFC 3542,我们首选较新版本 */
setsockopt(sockfd, IPPROTO_IPV6, IPV6_RECVHOPLIMIT, &on, sizeof(on));
#else
/* RFC 2292,如果没有定义较新版本相应常值,就尝试旧版本 */
setsockopt(sockfd, IPPROTO_IPV6, IPV6_HOPLIMIT, &on, sizeof(on));
#endif
#endif
}
proc_v6函数代码如下:
#include "ping.h"
void proc_v6(char *ptr, ssize_t len, struct msghdr *msg, struct timeval *tvrecv) {
#ifdef IPV6
double rtt;
struct icmp6_hdr *icmp6;
struct timeval *tvsend;
struct cmsghdr *cmsg;
int hlim;
// 从原始ICMPv6套接字接收的仅仅是ICMPv6首部和跟在该首部后的ICMP数据
// IPv6首部及扩展首部(如果有的话)不会被当作普通数据返回,它们只能通过辅助数据返回
icmp6 = (struct icmp6_hdr *)ptr;
if (len < 8) {
return; /* malformed packet */
}
if (icmp6->icmp6_type == ICMP6_ECHO_REPLY) {
// 查看回射应答的标识符字段,判断是否是本进程的应答
if (icmp6->icmp6_id != pid) {
return; /* not a response to our ECHO_REQUEST */
}
if (len < 16) {
return; /* not enough data to use */
}
tvsend = (struct timeval *)(icmp6 + 1);
tv_sub(tvrecv, tvsend);
rtt = tvrecv->tv_sec * 1000.0 + tvrecv->tv_usec / 1000.0;
hlim = -1;
for (cmsg = CMSG_FIRSTHDR(msg); cmsg != NULL; cmsg = CMSG_NXTHDR(msg, cmsg)) {
if (cmsg->cmsg_level == IPPROTO_IPV6 && cmsg->cmsg_type == IPV6_HOPLIMIT) {
hlim = *(u_int32_t *)CMSG_DATA(cmsg);
break;
}
}
printf("%d bytes from %s: seq=%u, hlim=", len,
Sock_ntop_host(pr->sarecv, pr->salen), icmp6->icmp6_seq);
if (hlim == -1) {
printf("???"); /* anciliary data missing */
} else {
printf("%d", hlim);
}
printf(", rtt=%.3f ms\n", rtt);
} else if (verbose) {
printf(" %d bytes from %s: type = %d, code = %d\n", len,
Sock_ntop_host(pr->sarecv, pr->salen), icmp6->icmp6_type, icmp6->icmp6_code);
}
#endif /* IPV6 */
}
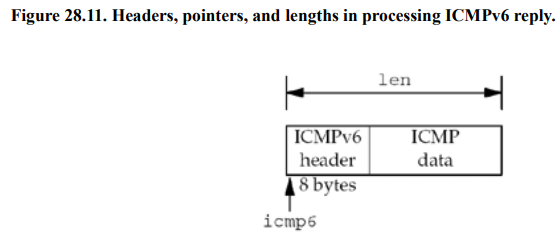
以下是SIGALRM信号的处理函数sig_alrm:
#include "ping.h"
void sig_alrm(int signo) {
(*pr->fsend)();
alarm(1);
return;
}
以上函数在readloop函数中被调用过一次,从而发送出第一个分组。该函数仅仅调用相关协议的发送函数(send_v4或send_v6)发送一个ICMP回射请求,然后调度下一个SIGALRM在1秒后产生。
以下send_v4函数构造一个ICMPv4回射请求消息并把它写出到原始套接字:
#include "ping.h"
void send_v4(void) {
int len;
struct icmp *icmp;
icmp = (struct icmp *)sendbuf;
// 指定ICMP消息类型为ICMP_ECHO
icmp->icmp_type = ICMP_ECHO;
// 代码字段用于进一步细化ICMP消息类型
icmp->icmp_code = 0;
// 标识符字段设为本进程id
icmp->icmp_id = pid;
// 序列号字段设为全局变量nsent,然后为下一个分组递增nsent
icmp->icmp_seq = nsent++;
// 将56字节的ICMP消息的数据部分填充为0xa5和时间戳,这样收到应答时可以验证是否与发送的数据相同
memset(icmp->icmp_data, 0xa5, datalen); /* fill with pattern */
Gettimeofday((struct timeval *)icmp->icmp_data, NULL);
// len为整个ICMP消息的长度,包括首部和数据部分
len = 8 + datalen; /* checksum ICMP header and data */
// 为计算校验和,先把校验和字段置0,再调用自编写的in_cksum计算校验和并存入校验和字段
// ICMPv4校验和的计算涵盖ICMPv4首部和后跟的数据部分
icmp->icmp_cksum = 0;
icmp->icmp_cksum = in_cksum((u_short *)icmp, len);
// 通过原始套接字发送我们构造的ICMP消息,由于我们没有开启IP_HDRINCL套接字选项,内核会为我们构造IPv4首部
Sendto(sockfd, sendbuf, len, 0, pr->sasend, pr->salen);
}
计算校验和时,如果数据长度为奇数个字节,需要在数据末尾逻辑地添加一个值为0的字节,在计算校验和前,需要将校验和字段置0。以下是in_cksum函数的代码:
uint16_t in_cksum(uint16_t *addr, int len) {
int nleft = len;
uint32_t sum = 0;
uint16_t *w = addr;
uint16_t answer = 0;
/*
* Our algorithm is simple. using a 32 bit accumulator (sum), we add
* sequential 16 bit words to it, and at the end, fold back all the
* carry bits from the top 16 bits into the lower 16 bits.
*/
// 计算所有16位值的和
while (nleft > 1) {
sum += *w++;
nleft -= 2;
}
/* mop up an odd byte, if necessary */
// 如果长度为奇数,就把最后一个字节也加到总和中
if (nleft == 1) {
*(unsigned char *)(&answer) = *(unsigned char *)w;
sum += answer;
}
/* add back carry outs from top 16 bits to low 16 bits */
sum = (sum >> 16) + (sum & 0xffff); /* add hi 16 to low 16 */
sum += (sum >> 16); /* add carry */
answer = ~sum; /* truncate to 16 bits */
return answer;
}
以上函数用于计算校验和,适用于IPv4、ICMPv4、IGMPv4、ICMPv6、UDP、TCP等首部的校验和字段,RFC 1071有关于此校验和算法的额外信息和数值例子,TCPv2的8.7节更详细地讨论了此算法,并给出了一个效率更好的实现。以上函数只是一个简单的算法, 对于我们的ping程序确实够用了,但对于内核要执行的大量校验和计算来说显然不够用,因此内核通常有特别优化过的校验和算法。
以上函数取自Mike Muuss编写的ping程序的公开域(public domain,指一种知识产权状态,其中作品、内容、创意或知识没有版权保护,任何人都可以自由使用、复制、分发和修改这些作品,无需事先获得许可或支付费用)版本。
send_v6函数构造并发送一个ICMPv6回射请求,它类似于send_v4函数,但它不计算ICMPv6校验和,如早先所提,由于ICMPv6校验和的计算涉及IPv6首部中的源IP地址,该校验和就由内核在选取源地址后替我们计算并设置:
#include "ping.h"
void send_v6() {
#ifdef IPV6
int len;
struct icmp6_hdr *icmp6;
icmp6 = (struct icmp6_hdr *)sendbuf;
icmp6->icmp6_type = ICMP6_ECHO_REQUEST;
icmp6->icmp6_code = 0;
icmp6->icmp6_id = pid;
icmp6->icmp6_seq = nsent++;
memset((icmp6 + 1), 0xa5, datalen); /* fill with pattern */
Gettimeofday((struct timeval *)(icmp6 + 1), NULL);
len = 8 + datalen; /* 8-byte ICMPv6 header */
Sendto(sockfd, sendbuf, len, 0, pr->sasend, pr->salen);
/* kernel calculates and stores checksum for us */
#endif /* IPV6 */
}
接下来开发一个自己的traceroute程序,与上面开发的ping程序一样,我们开发自己的版本,而非给出公开可得的版本,理由仍然是我们既需要一个同时支持IPv4和IPv6的版本,又不希望被与网络编程的讨论无多大关系的众多选项分散了注意力。
traceroute允许我们确定IP数据报从本地主机游历到某个远程主机所经过的路径。traceroute使用IPv4的TTL字段或IPv6的跳限字段以及两种ICMP消息,它一开始向目的地发送一个TTL(或跳限)为1的UDP数据报,这个数据报将导致第一跳路由器返送一个ICMP time exceeded in trasmit(传输中超时)错误,接着它每递增TTL一次发送一个UDP数据报,从而逐步确定下一跳路由器。当某个UDP数据报到达最终目的地时,目标是由目的地主机返送一个ICMP port unreachable(端口不可达)错误,我们选取的目的端口是随机选的,可能该端口正在被目的地主机使用,我们只能希望该端口未被使用。
早期版本的traceroute程序只能通过设置IP_HDRINCL套接字选项直接构造自己的IPv4首部来设置TTL字段,但如今的系统提供了IP_TTL套接字选项(随4.3 BSD Reno版本引入),它允许我们指定外出数据报所用的TTL。使用这个套接字选项比自己构造完整的IPv4首部容易得多。IPv6的IPV6_UNICAST_HOPS套接字选项允许我们控制IPv6数据报的跳限字段。
以下是所有traceroute程序相关文件都包含的trace.h头文件:
#include "unp.h"
#include <netinet/in_systm.h>
#include <netinet/ip.h>
#include <netinet/ip_icmp.h>
#include <netinet/udp.h>
#define BUFSIZE 1500
// 定义我们发送的UDP数据报的数据部分,但我们无需查看这些数据,发送它们主要是为了调试目的
struct rec { /* format of outgoing UDP data */
u_short rec_seq; /* sequence number */
u_short rec_ttl; /* TTL packet left with */
struct timeval rec_tv; /* time packet left */
};
/* globals */
char recvbuf[BUFSIZE];
char sendbuf[BUFSIZE];
int datalen; /* # bytes of data following ICMP header */
char *host;
u_short sport, dport;
int nsent; /* add 1 for each sendto() */
pid_t pid; /* our PID */
int probe, nprobes;
int sendfd, recvfd; /* send on UDP sock, read on raw ICMP sock */
int ttl, max_ttl;
int verbose;
/* function prototypes */
const char *icmpcode_v4(int);
const char *icmpcode_v6(int);
int recv_v4(int, struct timeval *);
int recv_v6(int, struct timeval *);
void sig_alrm(int);
void traceloop(void);
void tv_sub(struct timeval *, struct timeval *);
// 通过定义一个proto结构来处理IPv4和IPv6之间的差异
struct proto {
const char *(*icmpcode)(int);
int (*recv)(int, struct timeval *);
struct sockaddr *sasend; /* sockaddr{} for send, from getaddrinfo */
struct sockaddr *sarecv; /* sockaddr{} for receiving */
struct sockaddr *salast; /* last sockaddr{} for receiving */
struct sockaddr *sabind; /* sockaddr{} for binding source port */
socklen_t salen; /* length of sockaddr{}s */
int icmpproto; /* IPPROTO_xxx value for ICMP */
int ttllevel; /* setsockopt() level to set TTL */
int ttloptname; /* setsockopt() name to set TTL */
} *pr;
#ifdef IPV6
#include <netinet/ip6.h>
#include <netinet/icmp6.h>
#endif
以下是traceroute的main函数,它处理命令行参数,为IPv4或IPv6初始化pr指针,并调用traceloop函数:
#include "trace.h"
// 分别为IPv4和IPv6定义一个proto结构,在main函数末尾再分配指向套接字地址结构的指针
struct proto proto_v4 = { icmpcode_v4, recv_v4, NULL, NULL, NULL, NULL, 0,
IPPROTO_ICMP, IPPROTO_IP, IP_TTL };
#ifdef IPV6
struct proto proto_v6 = { icmpcode_v6, recv_v6, NULL, NULL, NULL, NULL, 0,
IPPROTO_ICMPV6, IPPROTO_IPV6, IPV6_UNICAST_HOPS };
#endif
int datalen = sizeof(struct rec); /* defaults */
// 默认最大TTL或跳限为30,用户可通过-m选项修改此值
int max_ttl = 30;
// 对每个TTL,我们发送3个测试分组,我们也可改为让用户用某选项改变该默认值
int nprobes = 3;
// 目的端口初始值为32768+666,此后每发送一个UDP数据报其值就增加1
// 我们但愿数据报到达目的地时,目的主机上没有使用此端口,但无法保证
u_short dport = 32768 + 666;
int main(int argc, char **argv) {
int c;
struct addrinfo *ai;
char *h;
opterr = 0; /* don't want getopt() writing to stderr */
while ((c = getopt(argc, argv, "m:v")) != 1) {
switch (c) {
case 'm':
if ((max_ttl = atoi(optarg)) <= 1) {
err_quit("invalid -m value");
}
break;
// -v选项使程序显示收到的所有ICMP消息
case 'v':
++verbose;
break;
case '?':
err_quit("unrecognized option: %c", c);
}
}
if (optind != argc - 1) {
err_quit("usage: traceroute [ -m <maxttl> -v ] <hostname>");
}
host = argv[optind];
pid = getpid();
Signal(SIGALRM, sig_alrm);
// 调用我们的host_serv处理目的主机名或IP地址,它返回指向某个addrinfo结构的指针
ai = Host_serv(host, NULL, 0, 0);
h = Sock_ntop_host(ai->ai_addr, ai->ai_addrlen);
printf("traceroute to %s (%s): %d hops max, %d data bytes\n",
ai->ai_canonname ? ai->ai_canonname : h, h, max_ttl, datalen);
/* initialize according to protocol */
if (ai->ai_family == AF_INET) {
pr = &proto_v4;
#ifdef IPV6
} else if (ai->ai_family == AF_INET6) {
pr = &proto_v6;
if (IN6_IS_ADDR_V4MAPPED(&(((struct sockaddr_in6 *)ai->ai_addr)->sin6_addr))) {
err_quit("connot traceroute IPV4-mapped IPv6 address");
}
#endif
} else {
err_quit("unknown address family %d", ai->ai_family);
}
pr->sasend = ai->ai_addr; /* contains destination address */
pr->sarecv = Calloc(1, ai->ai_addrlen);
pr->salast = Calloc(1, ai->ai_addrlen);
pr->sabind = Calloc(1, ai->ai_addrlen);
pr->salen = ai->ai_addrlen;
// traceloop函数发送UDP数据报并读取返回的ICMP出错消息
traceloop();
exit(0);
}
以下是traceloop函数:
#include "trace.h"
void traceloop(void) {
int seq, code, done;
double rtt;
struct rec *rec;
struct timeval tvrecv;
// 创建原始套接字,读取由UDP探测分组导致的ICMP消息
recvfd = Socket(pr->sasend->sa_family, SOCK_RAW, pr->icmpproto);
// 已创建完原始套接字,不再需要超级用户权限,把有效用户id设为实际用户id
setuid(getuid()); /* don't need special permissions anymore */
#ifdef IPV6
// 如果是IPv6原始套接字,且用户没有指定-v命令行选项,就过滤收到的ICMPv6消息,从而减少套接字上收到的分组数
// 只接收"time exceeded"和"destination unreachable"两类ICMPv6出错消息
if (pr->sasend->sa_family == AF_INET6 && verbose == 0) {
struct icmp6_filter myfilt;
ICMP6_FILTER_SETBLOCKALL(&myfilt);
ICMP6_FILTER_SETPASS(ICMP6_TIME_EXCEEDED, &myfilt);
ICMP6_FILTER_SETPASS(ICMP6_DST_UNREACH, &myfilt);
setsockopt(recvfd, IPPROTO_IPV6, ICMP6_FILTER, &myfilt, sizeof(myfilt));
}
#endif
sendfd = Socket(pr->sasend->sa_family, SOCK_DGRAM, 0);
pr->sabind->sa_family = pr->sasend->sa_family;
// 在UDP套接字上捆绑一个用于发送的源端口,所用值为本进程id的低序16位,但最高位总是置1
// 本地主机上可能有多个本程序副本正在运行,我们根据UDP首部中的源端口号区分收到的ICMP消息是否对应本进程
// ICMP出错消息中会包含引发该ICMP错误的那个UDP数据报的首部
sport = (getpid() & 0xffff) | 0x8000; /* our source UDP port # */
sock_set_port(pr->sabind, pr->salen, htons(sport));
Bind(sendfd, pr->sabind, pr->salen);
sig_alrm(SIGALRM);
seq = 0;
done = 0;
for (ttl = 1; ttl <= max_ttl && done == 0; ++ttl) {
// 每当循环到一个新的TTL值,我们就使用ttloptname成员指定的套接字选项为探测分组设置新值
// ttloptname成员的值根据协议的不同取IP_TTL或IPV6_UNICAST_HOPS
Setsockopt(sendfd, pr->ttllevel, pr->ttloptname, &ttl, sizeof(int));
// 首先将salast成员初始化为0,每次recvfrom函数返回时,将返回的地址与该地址对比
// 如果不同就显示salast成员中的地址,再把新地址复制到salast成员
// 将其初始化为0可以保证第一个recvfrom函数返回时能显示出其返回的地址
// 且对于给定的TTL,这个返回的地址发生变化时(如运行本程序期间某个地址发生变化),新的IP地址也能显示出来
bzero(pr->salast, pr->salen);
printf("%2d ", ttl);
fflush(stdout);
for (probe = 0; probe < nprobes; ++probe) {
rec = (struct rec *)sendbuf;
rec->rec_seq = ++seq;
rec->rec_ttl = ttl;
Gettimeofday(&rec->rec_tv, NULL);
// 发送每个探测分组前,调用我们的sock_set_port修改sasend成员指向的套接字地址结构中的目的端口
// 我们为每个探测分组都修改目的端口,当这些分组到达最终目的地时,所有3个探测分组将发送到不同端口
// 我们但愿其中至少有一个未在使用中
sock_set_port(pr->sasend, pr->salen, htons(dport + seq));
Sendto(sendfd, sendbuf, datalen, 0, pr->sasend, pr->salen);
// 调用recv_v4和recv_v6其中之一,该函数中会调用recvfrom读入并处理ICMP消息
// 这两个函数在发生超时时返回-3,此时如果还没发送完3个探测分组,则需要为该TTL发送另一个探测分组
// 在收到"time exceeded in transit"ICMP错误时返回-2
// 在收到"port unreachable"错误时返回-1,这意味着探测分组已到达目的地
// 收到其他代码的目的地不可达错误时返回某个非负的ICMP代码值
if ((code = (*pr->recv)(seq, &tvrecv)) == -3) {
printf(" *"); /* timeout, no reply */
} else {
char str[NI_MAXHOST];
// 如果所读入的ICMP消息是某个给定TTL值的第一个应答,或当前TTL值对应的ICMP消息发送节点IP发生变化
if (sock_cmp_addr(pr->sarecv, pr->salast, pr->salen) != 0) {
// 获取ICMP消息发送主机的主机名,然后打印主机名和IP地址
if (getnameinfo(pr->sarecv, pr->salen, str, sizeof(str), NULL, 0, 0) == 0) {
printf(" %s (%s)", str, Sock_ntop_host(pr->sarecv, pr->salen));
// 如果getnameinfo函数没有返回主机名,则只打印IP地址
} else {
printf(" %s", Sock_ntop_host(pr->sarecv, pr->salen));
}
memcpy(pr->salast, pr->sarecv, pr->salen);
}
// 根据探测分组发送时刻和ICMP消息收取时刻计算时间差并显示RTT
tv_sub(&tvrecv, &rec->rec_tv);
rtt = tvrecv.tv_sec * 1000.0 + tvrecv.tv_usec / 1000.0;
printf(" %.3f ms", rtt);
if (code == -1) { /* port unreachable; at destination */
++done;
} else if (code >= 0) {
// icmpcode成员指向的是函数icmpcode_v4或icmpcode_v6
// 这2个函数返回ICMP目的地不可达错误码对应的描述串
printf(" (ICMP %s)", (*pr->icmpcode)(code));
}
}
fflush(stdout);
}
printf("\n");
}
}
以下是recv_v4函数:
#include "trace.h"
extern int gotalarm;
/*
* Return: -3 on timeout
* -2 on ICMP time exceeded in transit (caller keeps going)
* -1 on ICMP port unreachable (caller is done)
* >= 0 return value is some other ICMP unreachable code
*/
int recv_v4(int seq, struct timeval *tv) {
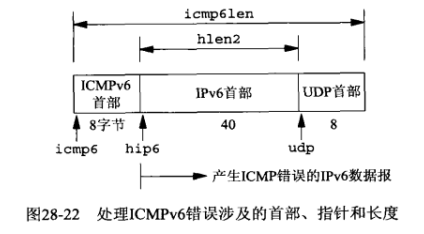
int hlen1, hlen2, icmplen, ret;
socklen_t len;
ssize_t n;
struct ip *ip, *hip;
struct icmp *icmp;
struct udphdr *udp;
// 使用gotalarm全局变量,从而一定程度上避免了竞争状态,但没有完全避免
// 比如在检查gotalarm和调用recvfrom之间信号到来,解决方法可查看第20章
gotalarm = 0;
// 设置一个3秒钟的报警时钟后进入一个调用recvfrom的循环,以读入返送到原始套接字的所有ICMPv4消息
alarm(3);
for (; ; ) {
if (gotalarm) {
return -3; /* alarm expired */
}
len = pr->salen;
n = recvfrom(recvfd, recvbuf, sizeof(recvbuf), 0, pr->sarecv, &len);
if (n < 0) {
if (errno == EINTR) {
continue;
} else {
err_sys("recvfrom error");
}
}
// ip指向IPv4首部的开始位置,在IPv4原始套接字上的读入操作总是返回IP首部
ip = (struct ip *)recvbuf; /* start of IP header */
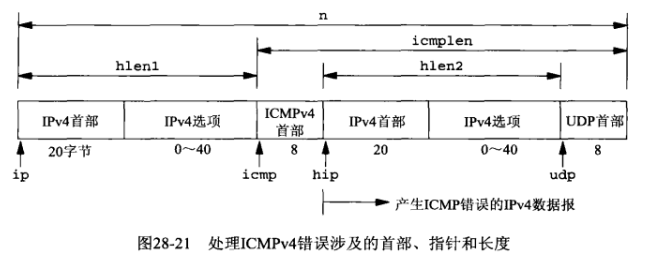
// hlen1等长度的图示见下图
hlen1 = ip->ip_hl << 2; /* length of IP header */
// icmp指向ICMP首部的开始位置
icmp = (struct icmp *)(recvbuf + hlen1); /* start of ICMP header */
if ((icmplen = n - hlen1) < 8) {
continue; /* not enough to look at ICMP header */
}
// 如果是"time exceeded in transmit"出错消息,则它可能是响应本进程某个探测分组的应答
if (icmp->icmp_type == ICMP_TIMXCEED &&
icmp->icmp_code == ICMP_TIMXCEED_INTRANS) {
if (icmplen < 8 + sizeof(struct ip)) {
continue; /* not enough data to look at inner IP */
}
// hip指向ICMP消息中的IPv4首部,它跟在8字节的ICMP首部之后
hip = (struct ip *)(recvbuf + hlen1 + 8);
hlen2 = hip->ip_hl << 2;
if (icmplen < 8 + hlen2 + 4) {
continue; /* not enough data to look at UDP ports */
}
// udp指向跟在ICMP消息中的IPv4首部之后
udp = (struct udphdr *)(recvbuf + hlen1 + 8 + hlen2);
// 如果该ICMP消息是由某个UDP数据报引起,且该数据报的源端口与目的端口是本进程发送的值
if (hip->ip_p == IPPROTO_UDP &&
udp->uh_sport == htons(sport) &&
udp->uh_dport == htons(dport + seq)) {
// 此ICMP应答是某个中间路由器响应我们探测分组的一个应答
ret = -2; /* we hit an intermediate router */
break;
}
// 如果读入的ICMP消息是"destination unreachable"出错消息
} else if (icmp->icmp_type == ICMP_UNREACH) {
if (icmplen < 8 + sizeof(struct ip)) {
continue; /* not enough data to look at inner IP */
}
hip = (struct ip *)(recvbuf + hlen1 + 8);
hlen2 = hip->ip_hl << 2;
if (icmplen < 8 + hlen2 + 4) {
continue; /* not enough data to look at UDP ports */
}
// 查看其中的UDP首部,判断是否是本进程某个探测分组的应答
udp = (struct udphdr *)(recvbuf + hlen1 + 8 + hlen2);
// 如果是本进程探测分组的应答
if (hip->ip_p == IPPROTO_UDP &&
udp->uh_sport == htons(sport) &&
udp->uh_dport == htons(dport + seq)) {
// 如果ICMP代码是"port unreachable",返回-1
if (icmp->icmp_code == ICMP_UNREACH_PORT) {
ret = -1; /* have reached destination */
// 否则返回它的ICMP代码值,常见的例子是防火墙为我们探测的目的主机返回了其他不可达代码
} else {
ret = icmp->icmp_code; /* 0, 1, 2, ... */
}
break;
}
}
// 如果用户指定了-v选项,则显示所有其他ICMP消息
else if (verbose) {
printf(" (from %s: type = %d, code = %d)\n", Sock_ntop_host(pr->sarecv, pr->salen),
icmp->icmp_type, icmp->icmp_code);
}
/* Some other ICMP error, recvfrom() again */
}
alarm(0); /* don't leave alarm running */
Gettimeofday(tv, NULL); /* get time of packet arrival */
return ret;
}
recv_v6函数是recv_v4函数的等价函数,与recv_v4函数几乎相同,但使用不同的常值名和结构成员名,且从IPv6原始套接字收取的数据不包括IPv6首部和扩展首部,对于ICMPv6原始套接字而言,所收取的数据一开始就是ICMPv6首部:
以下是recv_v6函数:
#include "trace.h"
extern int gotalarm;
/*
* Return: -3 on timeout
* -2 on ICMP time exceeded in transit (caller keeps going)
* -1 on ICMP port unreachable (caller is done)
* >= 0 return value is some other ICMP unreachable code
*/
int recv_v6(int seq, struct timeval *tv) {
#ifdef IPV6
int hlen2, icmp6len, ret;
ssize_t n;
socklen_t len;
struct ip6_hdr *hip6;
struct icmp6_hdr *icmp6;
struct udphdr *udp;
gotalarm = 0;
alarm(3);
for (; ; ) {
if (gotalarm) {
return -3; /* alarm expired */
}
len = pr->salen;
n = recvfrom(recvfd, recvbuf, sizeof(recvbuf), 0, pr->sarecv, &len);
if (n < 0) {
if (errno == EINTR) {
continue;
} else {
err_sys("recvfrom error");
}
}
icmp6 = (struct icmp6_hdr *)recvbuf; /* ICMP header */
if ((icmp6len = n) < 8) {
continue; /* not enough to look at ICMP header */
}
if (icmp6->icmp6_type == ICMP6_TIME_EXCEEDED &&
icmp6->icmp6_code == ICMP6_TIME_EXCEED_TRANSIT) {
if (icmp6len < 8 + sizeof(struct ip6_hdr) + 4) {
continue; /* not enough data to look at inner header */
}
hip6 = (struct ip6_hdr *)(recvbuf + 8);
hlen2 = sizeof(struct ip6_hdr);
udp = (struct udphdr *)(recvbuf + 8 + hlen2);
if (hip6->ip6_nxt == IPPROTO_UDP &&
udp->uh_sport == htons(sport) &&
udp->uh_dport == htons(dport + seq)) {
ret = -2; /* we hit an intermediate router */
break;
}
} else if (icmp6->icmp6_type == ICMP6_DST_UNREACH) {
if (icmp6len < 8 + sizeof(struct ip6_hdr) + 4) {
continue; /* not enough data to look at inner header */
}
hip6 = (struct ip6_hdr *)(recvbuf + 8);
hlen2 = sizeof(struct ip6_hdr);
udp = (struct udphdr *)(recvbuf + 8 + hlen2);
if (hip6->ip6_nxt == IPPROTO_UDP &&
udp->uh_sport == htons(sport) &&
udp->uh_dport == htons(dport + seq)) {
if (icmp6->icmp6_code == ICMP6_DST_UNREACH_NOPORT) {
ret = -1; /* have reached destination */
} else {
ret = icmp6->icmp6_code; /* 0, 1, 2, ... */
}
break;
}
} else if (verbose) {
printf(" (from %s: type = %d, code = %d)\n", Sock_ntop_host(pr->sarecv, pr->salen),
icmp6->icmp6_type, icmp6->icmp6_code);
}
/* Some other ICMP error, recvfrom() again */
}
alarm(0); /* don't leave alarm running */
Gettimeofday(tv, NULL); /* get time of packet arrival */
return ret;
#endif
}
以下是icmpcode_v6函数,它将ICMPv6不可达状态码转换为描述串:
#include "trace.h"
const char *icmpcode_v6(int code) {
#ifdef IPV6
static char errbuf[100];
switch (code) {
case ICMP6_DST_UNREACH_NOROUTE:
return "no route to host";
case ICMP6_DST_UNREACH_ADMIN:
return "administratively prohibited";
case ICMP6_DST_UNREACH_NOTNEIGHBOR:
return "not a neighbor";
case ICMP6_DST_UNREACH_ADDR:
return "address unreachable";
case ICMP6_DST_UNREACH_NOPORT:
return "port unreachable";
default:
sprintf(errbuf, "[unknown code %d]", code);
return errbuf;
}
#endif
}
IPv4的icmpcode_v4函数与以上函数类似,但ICMPv4目的地不可达类型错误有更多。
以下是我们的traceroute程序的SIGALRM信号的处理函数sig_alrm,该函数仅仅是返回,目的是使recv_v4或recv_v6函数中已阻塞的recvfrom调用被中断,从而返回EINTR错误:
#include "trace.h"
int gotalarm;
void sig_alrm(int signo) {
gotalarm = 1; /* set flag to note that alarm occurred */
return; /* and interrupt the recvfrom() */
}
运行我们的traceroute程序,以下是使用IPv4的例子,其中对过长的输出行进行了折行处理:
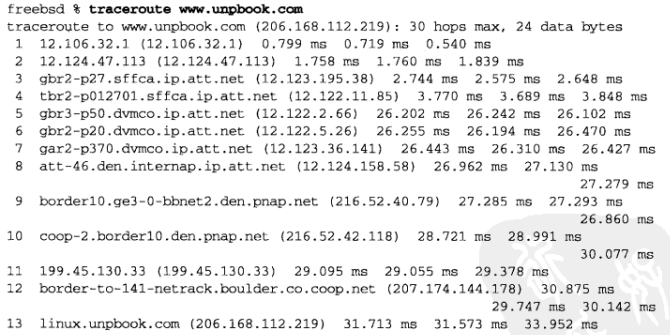
以下是使用IPv6的例子,同样对过长的输出行进行了折行处理:

在UDP套接字上接收异步ICMP错误向来是个问题,ICMP错误由内核收取后很少被地送到需要了解它们的应用进程,在套接字API中,收取这些错误要求把UDP套接字connect到某个IP地址,这样限制的原因在于,recvfrom函数返回的错误仅仅是一个errno整数码,如果一个应用进程向多个目的地发送数据报后调用recvfrom,那么该函数难以告知应用进程哪个数据报引发了错误。
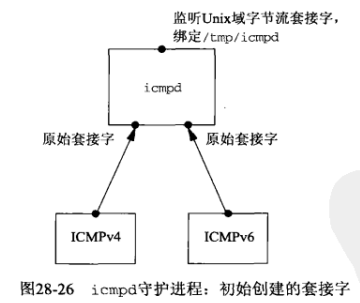
下面给出无需改动内核的另一个解决办法,我们将提供一个名为icmpd的ICMP消息守护程序,它创建一个ICMPv4原始套接字和一个ICMPv6原始套接字,接收内核传递给这2个原始套接字的所有ICMP消息,它还创建一个Unix域字节流套接字,把路径名/tmp/icmpd捆绑在其上,然后在这个套接字上监听针对该路径名的外来客户连接:
作为icmpd守护进程的客户,一个UDP应用进程首先创建它自身的UDP套接字,该套接字也是希望为之接收异步错误的套接字。该应用进程必须显式bind一个临时端口到这个UDP套接字,接着它创建一个Unix域字节流套接字,并把该套接字连接到icmpd的众所周知路径名/tmp/icmpd:
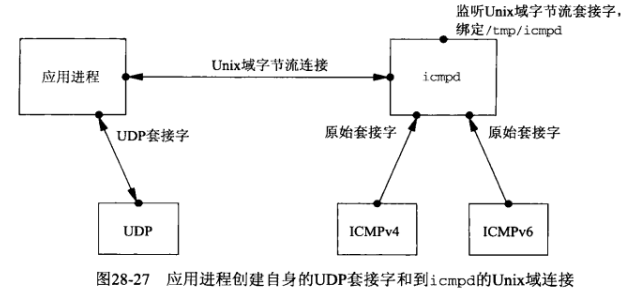
该应用进程随后使用描述符传递机制通过这个Unix域连接把它的UDP套接字传递给icmpd,icmpd于是得到这个套接字的一个副本,从而可以调用getsockname获取bind到这个套接字上的端口号:
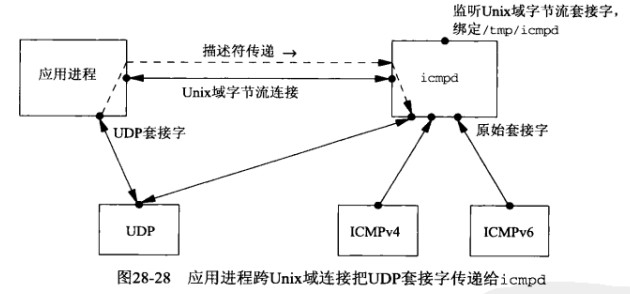
icmpd获取绑定在那个UDP套接字上的端口号后就关闭该套接字的本地副本,它和应用进程的关系于是恢复到图28-27所示的情形。
如果主机支持凭证传递,该应用也可把它的凭证发送给icmpd,以便icmpd检查是否允许该进程的属主用户访问本异步错误返回机制。
从此时起,icmpd一旦收取由该应用进程的UDP套接字上的端口发送的数据报所引发的任何ICMP错误,就通过Unix域连接向该应用进程发送一个消息,该应用进程因此必须使用select或poll函数,等待它的UDP套接字和Unix域套接字中任何一个有数据到达而变为可读。
以下是使用icmpd的应用程序和icmpd守护程序都包含的头文件:
#ifndef __unpicmp_h
#define __unpicmp_h
#include "unp.h"
// icmpd的众所周知路径名
#define ICMPD_PATH "/tmp/icmpd" /* server's well-known pathname */
// icmpd一旦收到一个传给某应用进程的ICMP消息就传递一个icmpd_err结构给这个应用进程
struct icmpd_err {
// ICMPv4和ICMPv6在数值上(有些甚至在概念上)存在差异
// 因此除了返回真正的ICMP类型值和代码值外,我们还把它映射为一个errno值(icmpd_errno成员)
// 应用可以直接处理这个errno值,以取代协议相关的ICMPv4或ICMPv6值
int icmpd_errno; /* EHOSTUNREACH, EMSGSIZE, ECONNREFUSED */
char icmpd_type; /* actual ICMPv[46] type */
char icmpd_code; /* actual ICMPv[46] code */
socklen_t icmpd_len; /* length of sockaddr{} that follows */
// icmpd_dest成员存放引发本ICMP错误的UDP数据报的目的IP地址和目的端口
// 该成员可能是IPv4的sockaddr_in结构,也可能是IPv6的sockaddr_in6结构
// 如果应用往多个目的地发送数据报,则每个目的地都有一个这样的套接字地址结构
// 通过以一个套接字地址结构返回目的IP地址和端口信息,应用可将它和自己的各个结构比较
// 从而找出导致错误的那个结构,sockaddr_storage结构能容纳系统支持的任何套接字地址结构
struct sockaddr_storage icmpd_dest; /* sockaddr_storage handles any size */
};
#endif /* __unpicmp_h */
下图是icmpd处理的ICMP消息类型对应的errno映射值:

icmpd返回上图5种类型的ICMP错误,以下是它们的解释:
1.端口不可达(port unreachable):目的IP地址上没有绑定目的端口的套接字。
2.分组过大(packet too big):用于MTU发现。目前尚未定义允许UDP应用进程执行路径MTU发现的API。在为UDP提供路径MTU发现的内核上通常发生以下情形,该ICMP错误的收取导致内核把其中携带的路径MTU新值记录在自身的路由表中,但不通知所发送数据报因分组过大被网络丢弃的那个UDP应用进程,该应用进程必须超时并重传该数据报,此时内核将在自身路由表中找到新的(而且是更小的)MTU值,于是照此对该数据报执行分片。如果内核把这个ICMP错误传递回该应用进程,它就能更早地重传这个被网络而非目的地丢弃的数据报,且有可能使用ICMP错误中携带的路径MTU新值自行降低待发送数据报的大小。
3.超时(time exceeded):本ICP错误类型常见的代码为0,表示IPv4的TTL或IPv6的跳限已到达0值,本错误往往表示出现路由循环,因此可能是一个暂时性的错误。
4.ICMPv4源熄灭(source quench,源端抑制):尽管RFC 1812返回使用本ICMP错误,路由器(或配成用作路由器的主机)仍可能发送它们。本ICMP错误指示某个分组已被丢弃,因此上图中我们像处理目的地不可达错误那样处理它们。IPv6没有源熄灭错误。
5.所有其他目的地不可达错误指示某个分组已被丢弃。
把UDP回射客户程序的dg_cli函数改为使用我们的icmpd守护程序:
#include "unpicmpd.h"
// dg_cli函数的参数不变
void dg_cli(FILE *fp, int sockfd, const SA *pservaddr, socklen_t servlen) {
int icmpfd, maxfdp1;
char sendline[MAXLINE], recvline[MAXLINE + 1];
fd_set rset;
ssize_t n;
struct timeval tv;
struct icmpd_err icmpd_err;
struct sockaddr_un sun;
// 调用我们的sock_bind_wild把通配IP地址和一个临时端口绑定到UDP套接字
// 这么做使得稍后传递给icmpd的本套接字的副本有一个绑定的端口
// 如果icmpd收取的套接字副本没有绑定一个本地端口,该守护进程也可以执行这样的捆绑
// 但这样做并非在所有环境都行之有效,在SVR 4实现(如Solaris 2.5)中套接字并非内核的一部分
// 在一个进程把一个端口绑定到某个共享的套接字后,拥有这个套接字副本的其他进程会在使用该套接字时出错
// 最简单的解决方法是要求应用进程把本套接字传递给icmpd之前绑定本地端口
Sock_bind_wild(sockfd, pservaddr->sa_family);
// 创建一个AF_LOCAL套接字,并connect到众所周知路径名
icmpfd = Socket(AF_LOCAL, SOCK_STREAM, 0);
sun.sun_family = AF_LOCAL;
strcpy(sun.sun_path, ICMPD_PATH);
Connect(icmpfd, (SA *)&sun, sizeof(sun));
// 调用我们的write_fd函数把本UDP套接字发送给icmpd,我们还发送1个值为1的单字节普通数据
// 因为有些实现在没有普通数据时不会以辅助数据的形式传递描述符
// icmpd通过发送回1个值为1的单字节数据表示成功,其他应答表示发生某个错误
Write_fd(icmpfd, "1", 1, sockfd);
n = Read(icmpfd, recvline, 1);
if (n != 1 || recvline[0] != '1') {
err_quit("error creating icmp socket, n = %d, char = %c", n, recvline[0]);
}
// 初始化一个描述符集,并计算select函数的第一个参数(两个套接字描述符较大值加1)
FD_ZERO(&rset);
maxfdp1 = max(sockfd, icmpfd) + 1;
while (Fgets(sendline, MAXLINE, fp) != NULL) {
Sendto(sockfd, sendline, strlen(sendline), 0, pservaddr, servlen);
tv.tv_sec = 5;
tv.tv_usec = 0;
FD_SET(sockfd, &rset);
FD_SET(icmpfd, &rset);
// 如果超时,显示一个消息并跳转到循环开始处
if ((n = Select(maxfdp1, &rset, NULL, NULL, &tv)) == 0) {
fprintf(stderr, "socket timeout\n");
continue;
}
// 将服务器返回的数据报显示到标准输出
if (FD_ISSET(sockfd, &rset)) {
n = Recvfrom(sockfd, recvline, MAXLINE, 0, NULL, NULL);
recvline[n] = 0; /* null terminate */
Fputs(recvline, stdout);
}
// 如果到icmpd的Unix域连接变为可读,就试图读入一个icmpd_err结构
if (FD_ISSET(icmpfd, &rset)) {
if ((n = Read(icmpfd, &icmpd_err, sizeof(icmpd_err))) == 0) {
err_quit("ICMP daemon terminated");
} else if (n != sizeof(icmpd_err)) {
err_quit("n = %d, expected %d", n, sizeof(icmpd_err));
}
// 如果读入成功,显示由icmpd返回的相关信息
printf("ICMP error: dest = %s, %s, type = %d, code = %d\n",
Sock_ntop(&icmpd_err.icmpd_dest, icmpd_err.icmpd_len),
strerror(icmpd_err.icmpd_errno), icmpd_err.icmpd_type, icmpd_err.icmpd_code);
}
}
}
以上函数中的strerror函数是移植性本该更好的简单函数的一个例子,ANSI C没有就函数如何返回错误给出说明,Solaris手册页面上说,如果参数超出有效范围,就返回一个空指针,但这意味着以下代码是不正确的:
printf("%s", strerror(arg));
因为strerror函数可能返回空指针。但FreeBSD的实现和本书作者们能找到的其他源码实现都把无效参数返回成一个指向诸如"Unknown error"等字符串的指针,这样含义清楚,也不会使上述代码出错。但POSIX又做了改动,指出由于没有任何返回值保留用于指示错误,如果参数超出有效范围,该函数就把errno设为EINVAL(但未就出错情况下返回的指针给出说明),这意味着符合POSIX的代码必须先把errno置0,再调用strerror,然后测试errno的值是否等于EINVAL,如果出错就显示另外的消息。
运行使用以上dg_cli函数的UDP回射客户程序,首先往一个未接入因特网的IP发送数据报:

icmpd程序正在运行,我们期望某个路由器返送ICMP“host unreachable”错误,但没有收到任何ICMP错误,且我们的应用发生超时,给出上例是为了强调超时仍是必需的,诸如"host unreachable"等ICMP出错消息可能不会产生。
往一个没有运行标准echo服务器的主机发送目的端口为标准echo服务器的数据报,我们会收到一个ICMPv4“port unreachable”错误:

然后使用IPv6再次尝试,也收到了一个ICMPv6“port unreachable”错误,我们对过长的输出做了折行处理:

以下是icmpd守护进程额头文件icmpd.h:
#include "unpicmpd.h"
// icmpd能处理任意数量的客户,我们使用一个client结构数组保存每个客户的信息
struct client {
int connfd; /* Unix domain stream socket to client */
int family; /* AF_INET or AF_INET6 */
int lport; /* local port bound to client's UDP socket */
/* network byte ordered */
// FD_SETSIZE是select函数所用的fd_set数据结构的描述符集的大小
} client [FD_SETSIZE];
/* globals */
int fd4, fd6, listenfd, maxi, maxfd, nready;
fd_set rset, allset;
struct sockaddr_un cliaddr;
/* funciton prototypes */
int readable_conn(int);
int readable_listen(void);
int readable_v4(void);
int readable_v6(void);
以下是icmpd程序的main函数:
#include "icmpd.h"
int main(int argc, char **argv) {
int i, sockfd;
struct sockaddr_un sun;
if (argc != 1) {
err_quit("usage: icmpd");
}
maxi = -1; /* index into client[] array */
// 通过把已连接套接字成员connfd设为-1初始化client数组
for (i = 0; i < FD_SETSIZE; ++i) {
client[i].connfd = -1; /* -1 indicates available entry */
}
FD_ZERO(&allset);
// 创建原始ICMPv4套接字
fd4 = Socket(AF_INET, SOCK_RAW, IPPROTO_ICMP);
FD_SET(fd4, &allset);
maxfd = fd4;
#ifdef IPV6
// 创建原始ICMPv6套接字
fd6 = Socket(AF_INET6, SOCK_RAW, IPPROTO_ICMPV6);
FD_SET(fd6, &allset);
maxfd = max(fd4, fd6);
#endif
// 创建Unix域字节流套接字
listenfd = Socket(AF_UNIX, SOCK_STREAM, 0);
sun.sun_family = AF_LOCAL;
strcpy(sun.sun_path, ICMPD_PATH);
// unlink最近一次运行icmpd可能遗留的Unix域套接字路径名
unlink(ICMPD_PATH);
// bind它的众所周知路径名到这个Unix域套接字
Bind(listenfd, (SA *)&sun, sizeof(sun));
// listen外来连接
Listen(listenfd, LISTENQ);
FD_SET(listenfd, &allset);
// 为select函数计算最大描述符值
maxfd = max(maxfd, listenfd);
for (; ; ) {
rset = allset;
nready = Select(maxfd + 1, &rset, NULL, NULL, NULL);
// 首先测试Unix域监听套接字,若已就绪则调用readable_listen
// 存放select函数返回的可读描述符数nready是一个全局变量,每个readable_XXX的函数都递减该变量
// 并作为函数返回值返回nready的新值,当该值到达0时,所有可读描述符都已被处理,于是再次调用select
if (FD_ISSET(listenfd, &rset)) {
if (readable_listen() <= 0) {
continue;
}
}
if (FD_ISSET(fd4, &rset)) {
if (readable_v4() <= 0) {
continue;
}
}
#ifdef IPV6
if (FD_ISSET(fd6, &rset)) {
if (readable_v6() <= 0) {
continue;
}
}
#endif
// 测试每个已连接Unix域套接字,其中任一变为可读意味着相应客户已发送一个描述符或已终止
for (i = 0; i < maxi; ++i) { /* check all clients for data */
if ((sockfd = client[i].connfd) < 0) {
continue;
}
if (FD_ISSET(sockfd, &rset)) {
if (readable_conn(i) <= 0) {
break; /* no more readable descriptors */
}
}
}
}
exit(0);
}
以下是readable_listen函数,它在icmpd的监听套接字变为可读时被调用,表示出现一个新的客户连接:
#include "icmpd.h"
int readable_listen(void) {
int i, connfd;
socklen_t clilen;
clilen = sizeof(cliaddr);
// 接受新的客户连接
connfd = Accept(listenfd, (SA *)&cliaddr, &clilen);
/* find first available client[] structure */
// 找到client数组里第一个可用元素
for (i = 0; i < FD_SETSIZE; ++i) {
if (client[i].connfd < 0) {
client[i].connfd = connfd; /* save descriptor */
break;
}
}
// 如果客户数组中没有可用元素,就直接关闭客户连接
if (i == FD_SETSIZE) {
close(connfd); /* can't handle new client */
return --nready; /* rudely close the new connection */
}
printf("new connection, i = %d, connfd = %d\n", i, connfd);
FD_SET(connfd, &allset); /* add new descriptor to set */
if (connfd > maxfd) {
maxfd = connfd; /* for select() */
}
if (i > maxi) {
maxi = i; /* max index in client[] array */
}
return --nready;
}
以下是readable_conn函数,它在某个已连接套接字变为可读时被调用,其参数为对应客户在client数组中的下标:
#include "icmpd.h"
int readable_conn(int i) {
int unixfd, recvfd;
char c;
ssize_t n;
socklen_t len;
struct sockaddr_storage ss;
unixfd = client[i].connfd;
recvfd = -1;
// 调用自己的read_fd函数读入来自客户的数据和可能有的描述符
// 如果返回值为0,表示相应客户已关闭连接,这可能由进程终止引起
if ((n = Read_fd(unixfd, &c, 1, &recvfd)) == 0) {
err_msg("client %d terminated, recvfd = %d", i , recvfd);
goto clientdone; /* client probably terminated */
}
// 如果客户未关闭本连接,那么我们期待收到一个描述符
/* data from client; should be descriptor */
if (recvfd < 0) {
err_msg("read_fd did not return descriptor");
goto clienterr;
}
// icmpd调用getsockname获取客户绑定在它的UDP套接字上的端口号
// 既然我们不知道为这个套接字地址结构分配多大的缓冲区,于是我们就使用sockaddr_storage结构
// 该结构既足够大又适当地对齐,适合存放系统支持的任何套接字地址结构
len = sizeof(ss);
if (getsockname(recvfd, (SA *)&ss, &len) < 0) {
err_ret("getsockname error");
goto clienterr;
}
// 把客户UDP套接字的地址族和端口号存放在该客户的client结构中
client[i].family = ss.ss_family;
// 如果端口号为0,就调用我们的sock_bind_wild函数把通配地址和一个临时端口捆绑到这个套接字
// 但捆绑操作在SVR 4上行不通
if ((client[i].lport = sock_get_port((SA *)&ss, len)) == 0) {
client[i].lport = sock_bind_wild(recvfd, client[i].family);
if (client[i].lport <= 0) {
err_ret("error binding ephemeral port");
goto clienterr;
}
}
// 通知客户操作成功
Write(unixfd, "1", 1); /* tell client all OK */
// 关闭recvfd,recvfd只是一个副本,该UDP套接字在客户中仍然是打开着的
Close(recvfd); /* all done with client's UDP socket */
return --nready;
clienterr:
// 如果发生错误,就把字符0的单字节数据发送回客户
Write(unixfd, "0", 1); /* tell client error occurred */
clientdone:
// 如果客户终止,就关闭本Unix域连接的服务器端,并从select的描述符中清除该描述符
Close(unixfd);
if (recvfd >= 0) {
Close(recvfd);
}
FD_CLR(unixfd, &allset);
// 把该客户的client结构中的connfd成员设为-1,表示这个client结构又可用
client[i].connfd = -1;
return --nready;
}
为了在应用和icmpd之间传递描述符,我们可以用Unix域字节流套接字,也可用Unix域数据报套接字,应用进程的UDP套接字可经由任一类型的Unix域套接字传递。之所以采用字节流套接字是为了检测客户何时终止,当一个客户终止时,它的所有描述符(包括它到icmpd的Unix域连接)都被自动关闭,这就告知icmpd从client数组中清除关于这个客户的信息,如果使用数据报套接字,我们就无法得知客户何时终止。
readable_v4函数在原始ICMPv4套接字变为可读时被调用:
#include "icmpd.h"
#include <netinet/in_systm.h>
#include <netinet/ip.h>
#include <netinet/ip_icmp.h>
#include <netinet/udp.h>
int readable_v4(void) {
int i, hlen1, hlen2, icmplen, sport;
char buf[MAXLINE];
// INET_ADDRSTRLEN是IPv4点分十进制表示的最长长度
char srcstr[INET_ADDRSTRLEN], dststr[INET_ADDRSTRLEN];
ssize_t n;
socklen_t len;
struct ip *ip, *hip;
struct icmp *icmp;
struct udphdr *udp;
struct sockaddr_in from, dest;
struct icmpd_err icmpd_err;
len = sizeof(from);
n = Recvfrom(fd4, buf, MAXLINE, 0, (SA *)&from, &len);
printf("%d bytes IMCPv4 from %s:", n, Sock_ntop_host((SA *)&from, len));
ip = (struct ip *)buf; /* start of IP header */
hlen1 = ip->ip_hl << 2; /* length of IP header */
icmp = (struct icmp *)(buf + hlen1); /* start of ICMP header */
if ((icmplen = n - hlen1) < 8) {
err_quit("icmplen (%d) < 8", icmplen);
}
// 显示每个接收到的ICMPv4消息的有关信息,这是为了调试而增加的
printf(" type = %d, code = %d\n", icmp->icmp_type, icmp->icmp_code);
// 我们只把目的地不可达、超时、源熄灭的ICMPv4信息传给相应的应用进程
if (icmp->icmp_type == ICMP_UNREACH ||
icmp->icmp_type == ICMP_TIMEXCEED ||
icmp->icmp_type == ICMP_SOURCEQUENCH) {
if (icmplen < 8 + 20 + 8) {
err_quit("icmplen (%d) < 8 + 20 + 8", icmplen);
}
// hip指向ICMP消息中,跟在IMCP首部后的IP首部,它是引发本ICMP错误的那个数据报的IP首部
hip = (struct ip *)(buf + hlen1 + 8);
hlen2 = hip->ip_hl << 2;
printf("\tsrcip = %s, dstip = %s, proto = %d\n",
Inet_ntop(AF_INET, &hip->ip_src, srcstr, sizeof(srcstr)),
Inet_ntop(AF_INET, &hip->ip_dst, dststr, sizeof(dststr)), hip->ip_p);
// 验证引发本ICMP错误的IP数据报是否是一个UDP数据报
if (hip->ip_p == IPPROTO_UDP) {
// udp是引发本ICMP错误的UDP数据报的UDP首部
udp = (struct udphdr *)(buf + hlen1 + 8 + hlen2);
// 获取该UDP首部中的源端口号
sport = udp->uh_sport;
/* find client's Unix domain socket, send headers */
for (i = 0; i <= maxi; ++i) {
// 寻找地址族和端口号都与本ICMP错误匹配的客户
if (client[i].connfd >= 0 &&
client[i].family == AF_INET &&
client[i].lport == sport) {
// 构造一个IPv4套接字地址结构,存放引发本错误的那个UDP数据报的目的IP和目的端口号
bzero(&dest, sizeof(dest));
dest.sin_family = AF_INET;
#ifdef HAVE_SOCKADDR_SA_LEN
dest.sin_len = sizeof(dest);
#endif
memcpy(&dest.sin_addr, &hip->ip_dst, sizeof(struct in_addr));
dest.sin_port = udp->uh_dport;
// 构造icmpd_err结构,并通过相应客户的Unix域连接把它发送出去
icmpd_err.icmpd_type = icmp->icmp_type;
icmpd_err.icmpd_code = icmp->icmp_code;
icmpd_err.icmpd_len = sizeof(struct sockaddr_in);
memcpy(&icmpd_err.icmpd_dest, &dest, sizeof(dest));
/* convert type & code to reasonable errno value */
// 我们把ICMPv4消息类型和代码映射成某个errno值
icmpd_err.icmpd_errno = EHOSTUNREACH; /* default */
if (icmp->icmp_type == ICMP_UNREACH) {
if (icmp->icmp_code == ICMP_UNREACH_PORT) {
icmpd_err.icmpd_errno = ECONNREFUSED;
} else if (icmp->icmp_code == ICMP_UNREACH_NEEDFRAG) {
icmpd_err.icmpd_errno = EMSGSIZE;
}
}
Write(client[i].connfd, &icmpd_err, sizeof(icmpd_err));
}
}
}
}
return --nready;
}
以下处理ICMPv6错误的readable_v6函数:
#include "icmpd.h"
#include <netinet/in_systm.h>
#include <netinet/ip.h>
#include <netinet/ip_icmp.h>
#include <netinet/udp.h>
#ifdef IPV6
#include <netinet/ip6.h>
#include <netinet/icmp6.h>
#endif
int readable_v6(void) {
#ifdef IPV6
int i, hlen2, icmp6len, sport;
char buf[MAXLINE];
char srcstr[INET6_ADDRSTRLEN], dststr[INET6_ADDRSTRLEN];
ssize_t n;
socklen_t len;
struct ip6_hdr *ip6, *hip6;
struct icmp6_hdr *icmp6;
struct udphdr *udp;
struct sockaddr_in6 from, dest;
struct icmpd_err icmpd_err;
len = sizeof(from);
n = Recvfrom(fd6, buf, MAXLINE, 0, (SA *)&from, &len);
printf("%d bytes ICMPv6 from %s:", n, Sock_ntop_host((SA *)&from, len));
icmp6 = (struct icmp6_hdr *)buf; /* start of ICMPv6 header */
if ((icmp6len = n) < 8) {
err_quit("icmp6len (%d) < 8", icmp6len);
}
printf(" type = %d, code = %d\n", icmp6->icmp6_type, icmp6->icmp6_code);
if (icmp6->icmp6_type == ICMP6_DST_UNREACH ||
icmp6->icmp6_type == ICMP6_PACKET_TOO_BIG ||
icmp6->icmp6_type == ICMP6_TIME_EXCEEDED) {
if (icmp6len < 8 + 8) {
err_quit(" icmp6len (%d) < 8 + 8", icmp6len);
}
hip6 = (struct ip_hdr *)(buf + 8);
hlen2 = sizeof(struct ip6_hdr);
printf("\tsrcip = %s, dstip = %s, next hdr = %d\n",
Inet_ntop(AF_INET6, &hip6->ip6_src, srcstr, sizeof(srcstr)),
Inet_ntop(AF_INET6, &hip6->ip6_dst, dststr, sizeof(dststr)), hip6->ip6_nxt);
// 引发本ICMP错误的是否是一个UDP数据报
if (hip6->ip6_nxt == IPPROTO_UDP) {
udp = (struct udphdr *)(buf + 8 + hlen2);
sport = udp->uh_sport;
}
/* find client's Unix domain socket, send headers */
for (i = 0; i <= maxi; ++i) {
if (client[i].connfd >= 0 &&
client[i].family == AF_INET6 &&
client[i].lport == sport) {
bzero(&dest, sizeof(dest));
dest.sin6_family = AF_INET6;
#ifdef HAVE_SOCKADDR_SA_LEN
dest.sin6_len = sizeof(dest);
#endif
memcpy(&dest.sin6_addr, &hip6->ip6_dst, sizeof(struct in6_addr));
dest.sin6_port = udp->uh_dport;
icmpd_err.icmpd_type = icmp6->icmp6_type;
icmpd_err.icmpd_code = icmp6->icmp6_code;
icmpd_err.icmpd_len = sizeof(struct sockddr_in6);
memcpy(&icmpd_err.icmpd_dest, &dest, sizeof(dest));
/* convert type & code to reasonable errno value */
icmpd_err.icmpd_errno = EHOSTUNREACH; /* default */
if (icmp6->icmp6_type == ICMP6_DST_UNREACH &&
icmp6->icmp6_code == ICMP6_DST_UNREACH_NOPORT) {
icmpd_err.icmpd_errno = ICMP6_PACKET_TOO_BIG;
}
if (icmp6->icmp6_type == ICMP6_PACKET_TOO_BIG) {
icmpd_err.icmpd_errno = EMSGSIZE;
}
Write(client[i].connfd, &icmpd_err, sizeof(icmpd_err));
}
}
}
return --nready;
#endif
}
原始套接字提供以下3个能力:
1.进程可读写ICMPv4、ICMPv6、IGMPv4等分组。
2.进程可读写内核不处理其协议字段的IP数据报。
3.进程可以自行构造IPv4首部,通常用于诊断目的(或不幸地被黑客们利用)。
IPv6首部的几乎所有字段及所有扩展首部都能通过套接字选项或辅助数据由应用进程指定或获取,净荷长度字段或者作为某个输出函数的一个参数,或作为来自某个输入函数的返回值总是可以得到,但如果需要特大净荷选项,那么真正的选项本身应用进程是得不到的。分片的首部应用进程也得不到。
如果以上icmpd守护进程的某个客户停止从Unix域连接读入数据,但来自icmpd的ICMP错误却大量到达,最终客户的接收缓冲区会被填满,导致icmpd守护进程的write调用阻塞,此时icmpd会停止处理任何套接字上的新数据。最容易的解决办法是让icmpd把它跟客户的Unix域连接的本地端设置成非阻塞式,然后icmpd改为调用write以取代它的包裹函数Write,并仅仅忽略EWOULDBLOCK错误。
如果我们指定本地子网的子网定向广播地址运行我们的ping程序(路由器通常不转发子网定向广播地址),它将正常工作,也就是说,即使我们不设置SO_BROADCAST套接字选项,广播的ICMP回射请求也作为一个链路层广播帧发送,这是因为源自Berkeley的内核默认允许在原始套接字上的广播,SO_BROADCAST套接字选项只有UDP套接字才需要指定。
如果我们的ping程序在一个多宿主机上ping所有主机多播组224.0.0.1,由于我们的程序没有检查多播地址,也没有设置IP_MULTICAST_IF套接字选项,因此内核可能通过搜索224.0.0.1的路由表项选定外出接口。我们也没有设置IP_MULTICAST_TTL套接字选项,因此它默认成1,这是合理的。


![Java IO流(四)Netty理论[模型|核心组件]](https://img-blog.csdnimg.cn/19e6ae2d19994e52ab414afd97144c2b.png)



![[docker][WARNING]: Empty continuation line found in:](https://img-blog.csdnimg.cn/7fbcd528bf0a45a5b718f663588caf9f.png)