1.优化背景
用户提交一个 SQL 作业后,一方面是希望作业能够成功运行,另一方面,对于成功完成的作业,需要进一步分析作业瓶颈,进行性能调优。针对这两个方面的需求,本文将介绍如何解决作业运行时的常见问题、如何进一步优化 SQL 作业性能。本文以阿里Maxcompute开发工具来举例说明,对于其他使用开源组件搭建的数据平台SQL优化一样具有通用性。
2.诊断篇
作业提交上去之后,包括预处理,编译,执行,结果返回四个步骤。对于比较复杂的编译和执行阶段,又存在若干子阶段。预处理阶段一般不会卡住,下面会分别说明编译,执行,结束阶段的特征,停滞在这些阶段的可能原因,以及可以考虑的解决思路。
2.1 编译阶段
作业处于编译阶段的特征是有 logview,但还没有执行计划。根据 logview 的子状态(SubStatusHistory)可以进一步细分为调度、优化、生成物理执行计划、数据跨集群复制等子阶段。
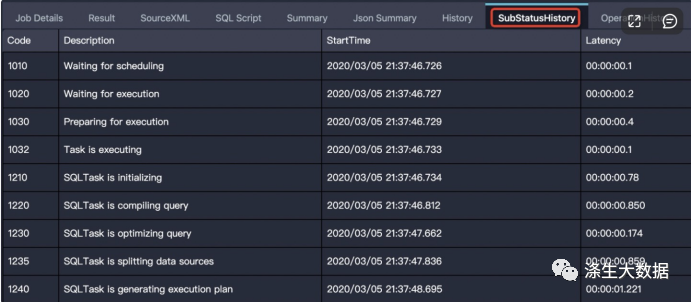
编译阶段的问题主要表现为在某个子阶段卡住,即作业长时间停留在某一个子阶段。下面将介绍作业停留在每个子阶段的可能原因和解决方法。
2.1.1 调度阶段
【特征】子状态为“Waiting for cluster resource”,作业排队等待被编译。
【该阶段作业卡住的可能原因 1 】计算集群资源紧缺。
【解决方法】查看计算集群的状态,需要等待计算集群的资源。
【该阶段作业卡住的可能原因 2 】编译资源池资源不够:可能有人不小心用脚本一次提交太多作业,把编译资源池占满了。
【解决方法】请联系集群运维值班同学,把这些无效作业kill掉;
2.1.2 优化阶段
【特征】子状态为“SQLTask is optimizing query”,优化器正在优化执行计划。
【该阶段作业卡住的可能原因】执行计划复杂,需要等待较长时间做优化。
【解决方法】一般可接受的时间是10分钟以内,如果真的太长时间不退出,基本上可以认为是集群的bug,请进找集群运维值班同学咨询。
2.1.3 生成物理计划执行阶段
【特征】子状态为“SQLTask is generating execution plan”。
【该阶段作业卡住的可能原因 1 】读取的分区太多。每个分区需要去根据分区信息来决定处理方式,决定 split,并且会写到生成的执行计划中。
【解决方法】需要好好设计 SQL,减少分区的数量,包括:分区裁剪、筛除不需要读的分区、把大作业拆成小作业。如何判断 SQL 中分区剪裁是否生效,以及分区裁剪失效的常见场景,更多内容请参考后续文章,敬请关注公众号"涤生大数据" :分区裁剪合理性评估介绍;
【该阶段作业卡住的可能原因 2 】小文件太多。ODPS 会根据文件大小决定 split,小文件多了会导致计算 split 的过程耗时增加。产生小文件的原因主要有两个:
1.对分区表进行 insert into 操作的时候,会在 partition 目录下面生成一个新文件;
2.采用客户端工具上传文件,参数设置不合理,导致生成了很多小文件;
【解决方法】
1. 使用集群提供的接口,可以更简单的进行上传功能,同时避免小文件。
2.执行一次 alter table merge smallfiles; 让 odps 把小文件 merge 起来。
更多内容请参考后续文章,敬请关注公众号"涤生大数据" :合并小文件优化介绍。
【注意】上面提到的“太多”不是指几十、几百个。基本都是要上万,上十万才会对生成物理执行计划的时间产生较大影响。
2.1.4 数据跨集群复制阶段
【特征】子状态列表里面出现多次“Task rerun”,result 里有错误信息“FAILED: ODPS-0110141:Data version exception”。作业看似失败了,实际还在执行,说明作业正在做数据的跨集群复制。
【该阶段作业卡住的可能原因 1 】project 刚做集群迁移,往往前一两天有大量需要跨集群复制的作业。
【解决方法】这种情况是预期中的跨集群复制,需要用户等待。
【该阶段作业卡住的可能原因 2 】可能是作业提交错集群,或者是中间 project 做过迁移,分区过滤没做好,读取了一些比较老的分区。
【解决方法】
1. 检查作业提交的集群是否正确:用户可以通过 Logview1.0 点击 Status->System Info,或 Logview2.0 任务详情页左侧的 BasicInfo 查看作业提交的集群。
2.过滤掉不必要读取的老分区(从这里看出,不限制日期读取全部增量分区表是有风险的)。
2.2 执行阶段
【特征】logview 的 detail 界面有执行计划(执行计划没有全都绿掉),且作业状态还是 Running。
执行阶段卡住或执行时间比预期长的主要原因有等待资源,数据倾斜,UDF 执行低效,数据膨胀等等,下面将具体介绍每种情况的特征和解决思路。
2.2.1 等待资源
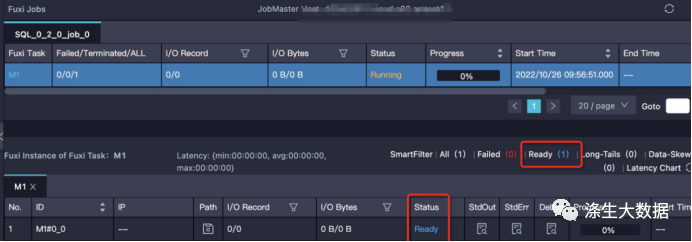
【特征】instance 处于 Ready 状态,或部分 instance 是 Running,部分是 Ready 状态。需要注意的是,如果 instance 状态是 Ready 但有 debug 历史信息,那么可能是 instance fail 触发重试,而不是在等待资源。
【解决思路】
1.确定排队状态是否正常:可以通过 logview 的排队信息“Queue”看作业在队列的位置。
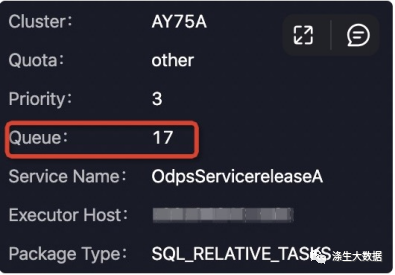
或着通过查看作业 project 当前的 quota 组作业信息、系统资源使用情况和历史曲线等等,查看当前作业所在 quota 组的资源使用情况:
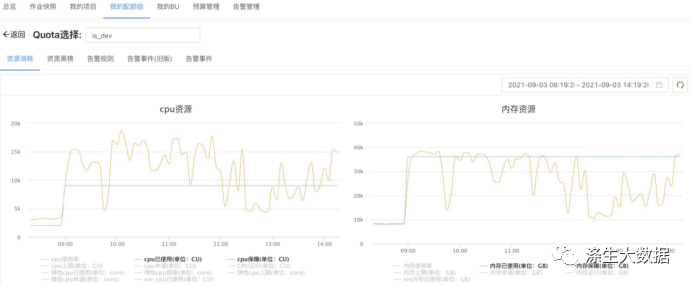
如果某项资源的使用率已经接近甚至超过配额了,那么证明 quota 组资源紧张,作业有排队是正常的。作业的调度顺序不仅与作业提交时间、优先级有关,还和作业所需内存或CPU资源大小能否被满足有关,因此合理设置作业的参数很重要。更多内容请看合理设置资源参数介绍。
2.查看 quota 组中运行的作业。
可能会有人不小心提交了低优先级的大作业(或批量提交了很多小作业),占用了太多的资源,可以和作业的 owner 协商,让他先把作业 kill 掉,把资源让出来。
3.考虑去其他 quota 组的 project 跑。
只要有权限,是可以在别的 project 下访问另一个 project 的表的。当然,有可能会存在跨集群复制;
2.2.2 数据倾斜
【特征】task 中大多数 instance 都已经结束了,但是有某几个 instance 却迟迟不结束(长尾)。如下图中大多数(358个)instance 都结束了,但是还有 18 个的状态是 Running,这些 instance 运行的慢,可能是因为处理的数据多。
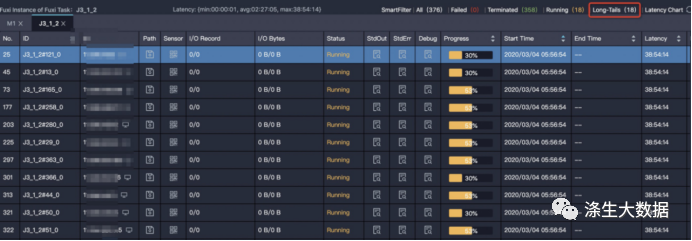
【解决方法】需要找到造成数据倾斜的具体位置,对症下药。下面列出了定位长尾实例的常用方法:
1.利用作业执行图及作业详情功能来分析作业运行情况,定位到长尾实例,找到导致长尾的数据来源。
2.利用 Logveiw查看任务执行图和 instance 运行情况来定位长尾实例。
3.在确定造成数据倾斜的实例、数据来源等信息后,用户需要针对性的对代码甚至算法做一定的修改。后文优化篇:数据倾斜中介绍了一些导致数据倾斜的常见原因及对应的优化思路。
2.2.3 UDF执行低效
这里的 UDF 泛指各种用户自定义的扩展,包括UDF,UDAF,UDTF等。
【特征】某个 task 执行效率低,且该 task 中有用户自定义的扩展。甚至是 UDF 的执行超时报错:“Fuxi job failed - WorkerRestart errCode:252,errMsg:kInstanceMonitorTimeout, usually caused by bad udf performance”。
【排查方法】任务报错时,可以在快速通过 DAG 图判断报错的 task 中是否包含 UDF。如下左图,可以看到报错的task R4_3 包含用户使用 Java 语言编写的 UDF。双击 R4_3,展开 operator 视图如下右图,可以看到该 task 包含的所有 UDF 名称。
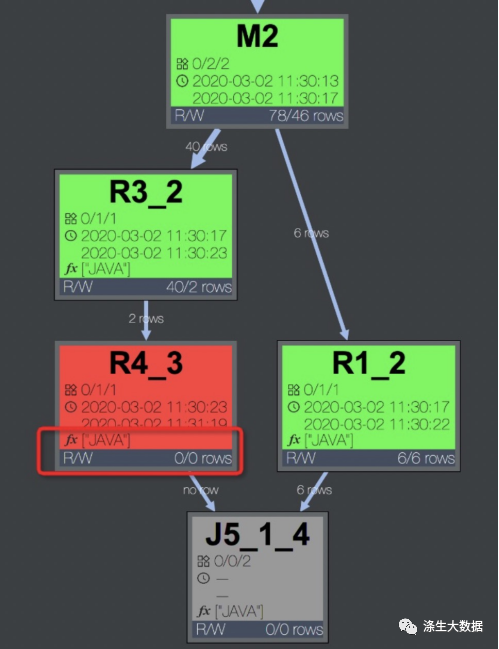
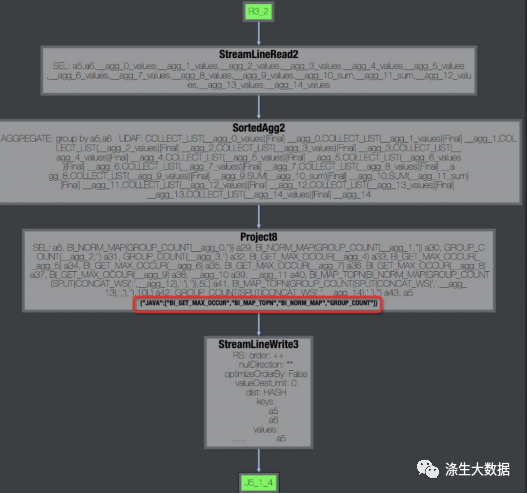
此外,在 task 的 stdout 日志里,UDF 框架会打印 UDF 输入的记录数、输出记录数、以及处理时间,如下图。通过这些数据可以看出 UDF 是否有性能问题。一般来讲,正常情况 Speed(records/s) 在百万或者十万级别,如果降到万级别,那么基本上就有性能问题了。

【解决思路】当有性能问题时,可以按照下面这些方法进行排查和优化:
1.检查 UDF 是否有 bug:有时候 bug 是由于某些特定的数据值引起的,比如出现某个值的时候会引起死循环。
2.检查 UDF 函数是否与内置函数同名:内置函数是有可能被同名 UDF 覆盖的,当看到一个函数像是内置函数时,需要确定是否有同名 UDF 覆盖了内置函数。
3.使用内置函数代替 UDF:有相似功能的内置函数的情况下,尽可能不要使用 UDF。内置函数一般经过验证,实现比较高效,并且内置函数对优化器而言是白盒,能够做更多的优化。更多内置函数的用法请参考官方文档。
4.将 UDF 函数进行功能拆分,部分用内置函数替换,内置函数无法实现的再用 UDF。
5.优化 UDF 的 evaluate 方法:evaluate 中只做与参数相关的必要操作。因为 evaluate 方法会被反复执行,所以尽可能将一些初始化的操作,或者一些重复的计算事先计算好。
6.预估 UDF 的执行时间:先在本地模拟 1 个 instance 处理的数据量测试 UDF 的运行时间,优化 UDF 的实现。默认 UDF 运行时限是 10 分钟,也就是 10 分钟内 UDF 必须要返回数据,或者用 context.progress() 来报告心跳。如果 UDF 预计运行时间本身就大于 10 分钟,可以通过参数设置 UDF 超时时间:
set xxx.sql.udf.timeout=
-- 设置UDF超时时间,单位秒,默认为600秒
-- 可手动调整区间[0,3600]7.调整内存参数:UDF效率低的原因并不一定是计算复杂度,有可能是受存储复杂度影响。比如:
1.某些UDF在内存计算、排序的数据量比较大时,会报内存溢出错误;
2.内存不足引起gc频率过高。这时可以尝试调整内存参数,不过这个方法只能暂时缓解,还是需要从业务上去优化。
set xxx.sql.udf.jvm.memory=
-- 设定UDF JVM Heap使用的最大内存,单位M,默认1024M
-- 可手动调整区间[256,12288]需要注意的是,目前如果使用了 UDF 可能会导致分区剪裁失效。查看官网是否支持 UdfProperty 注解。在定义 UDF 时,可以指定这个注解,让编译器知道这个函数是确定性的。
2.2.4 数据膨胀
【特征】task 的输出数据量比输入数据量大很多。
比如 1G 的数据经过处理,变成了 1T,在一个 instance 下处理 1T 的数据,运行效率肯定会大大降低。
作业运行完成后输入输出数据量体现在 Task 的 I/O Record 和 I/O Bytes 这两项:
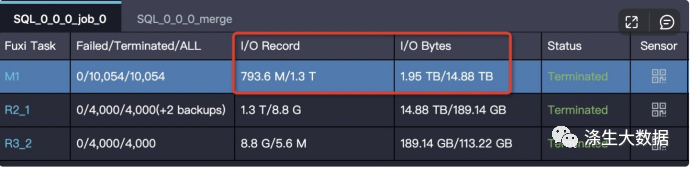
如果作业在 Join 阶段长时间不结束,可以选择几个 Running 状态的 Fuxi Instance 查看 StdOut 里的日志:
StdOut 里一直在打印 Merge join 的日志,说明对应的单个 worker 一直执行 merge join,红框中 Merge join 输出的数据条数已经超过 1433 亿条,有严重的数据膨胀,需要检查 JOIN 条件和 JOIN key 是否合理。
【解决思路】
1.检查代码是否有 bug:
1.JOIN 条件是不是写错了,变成笛卡尔积了;
2.UDTF 是不是有问题,输出了太多数据。2.检查 Aggregation 引起的数据膨胀。
因为大多数 aggregator 是 recursive 的,中间结果先做了一层 merge,中间结果不大,而且大多数 aggregator 的计算复杂度比较低,即使数据量不小,也能较快完成。所以通常情况下这些操作问题不大,如:
1.select 中使用 aggregation 按照不同维度做 distinct,每一次 distinct 都会使数据做一次膨胀;
2.使用 Grouping Sets (CUBE and ROLLUP) ,中间数据可能会扩展很多倍。
但是,有些操作如 collect_list、median 操作需要把全量中间数据都保留下来,可能会产生问题。
3.避免join引起的数据膨胀。
比如:两个表 join,左表是事件上报数据,数据量很大,但是由于并行度足够,效率可观。右表是个维表,记录每个国家对应的一些券信息,虽然只有几个国家,但是每个国家都包含数百行。那么如果直接按照国家来 join,可能会让左表膨胀数百倍。要解决这个问题,可以考虑先将右表的行转列,变成几行数据,这样 join 的结果就不会膨胀了。
4.由于grouping set 导致的数据膨胀。
grouping set 操作会有一个expand 过程,输出数据会按照group 数倍增。目前的plan没有能力适配grouping set并做下游task 实例数的调整,用户可以手动设置下游task的实例调整。
set xxx.sql.reducer.instances=xxx;
set xxx.sql.joiner.instances=xxx;2.3 结束阶段
2.3.1 过多小文件
小文件主要带来存储和计算两方面问题。存储方面,小文件过多会给 Pangu 文件系统带来一定的压力,且影响空间的有效利用;计算方面,ODPS 处理单个大文件比处理多个小文件更有效率,小文件过多会影响整体的计算执行性能。因此,为了避免系统产生过多小文件,SQL 作业在结束时会针对一定条件自动触发合并小文件的操作。小文件的判定,是通过参数
xxx.merge.smallfile.filesize.threshold
来设置的,该配置默认为 32MB,小于这个阈值的文件都会被判定为小文件。
自动合并小文件多出来的 merge task,虽然会增加当前作业整体执行时间,但是会让结果表在合并后产生的文件数和文件大小更合理,从而避免对文件系统产生过大压力,也使得表被后续的作业使用时,拥有更好的读取性能。
2.3.2 动态分区元数据更新
作业执行完后,有可能还有一些元数据操作。比如要把结果数据挪到特定目录去,然后把表的元数据更新。有可能动态分区输出了太多分区,那么还是可能会消耗一定的时间的。
例如,对分区表 sales 使用 insert overwrite ... values 命令新增 2000 个分区。
2.3.3 输出文件size变大
有时候在输入输出条数相差不大的情况,结果膨胀几倍
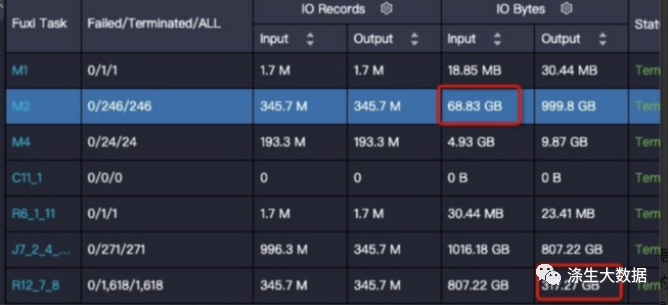
这种问题一般是数据分布变化导致的,我们在写表的过程中,会对数据进行压缩,而压缩算法对于重复数据的压缩率是最高的,所以如果写表的过程中,如果相同的数据都排布在一起,就可以获得很高的压缩率。写表的数据分布情况主要取决于写表的阶段(对应上图的R12)是如何shuffle和排序的,上图给出的SQL最后的操作是join,join key为on t1.query = t2.query and t1.item_id=t2.item_id
研究一下数据的特征,大部分列都是item的属性,也就是说相同的item_id其余的列都完全相同,按照query排序会把item完全打乱,导致压缩率降低非常多。这里调整一下join顺序,on t1.item_id=t2.item_id and t1.query = t2.query,调整后数据减小到原来的三分之一。