前言
在之前的章节中,我们已经成功地将Dubbo项目迁移到了云环境。在这个过程中,我们选择了单机ZooKeeper作为注册中心。接下来,我们将探讨如何将单机ZooKeeper部署到云端,以及在上云过程中可能遇到的问题及解决方案。
ZooKeeper是一个开源的分布式协调服务,由Apache软件基金会开发。它主要用于实现分布式系统中的配置管理、命名服务、分布式同步和组服务等,是一个功能强大、高性能、高可用性和可扩展性的分布式协调服务,广泛应用于各种分布式系统和微服务架构中。ZooKeeper的主要特点如下:
-
高可用性:ZooKeeper通过在集群中选举领导者来确保系统的可用性。当领导者不可用时,其他服务器可以自动选举出新的领导者,从而保证了系统的持续运行。
-
数据一致性:ZooKeeper使用一种称为“原子广播”的数据同步机制,确保所有节点上的数据保持一致。这对于需要高度一致性的分布式应用(如金融交易系统)非常重要。
-
高性能:ZooKeeper具有低延迟和高吞吐量的特点,适用于处理大量并发请求。它使用了多种优化技术,如内存管理和多线程,以提高性能。
-
可扩展性:ZooKeeper支持水平扩展,可以通过增加服务器节点来提高系统的容量。此外,ZooKeeper还提供了负载均衡功能,可以根据服务器的负载情况自动分配客户端请求。
-
灵活性:ZooKeeper提供了丰富的API和工具,方便开发者进行集成和定制。同时,它还支持多种编程语言,如Java、C++、Python等。
ZooKeeper的云端迁移
由于我们还有一些Dubbo服务并未部署在Kubernetes集群内,因此我们需要在Zookeeper中采用NodePort方式来暴露相关端口。这样一来,外部的Dubbo服务便可以通过访问Zookeeper节点的IP地址和NodePort号来建立连接,从而实现对其他Dubbo服务的访问。
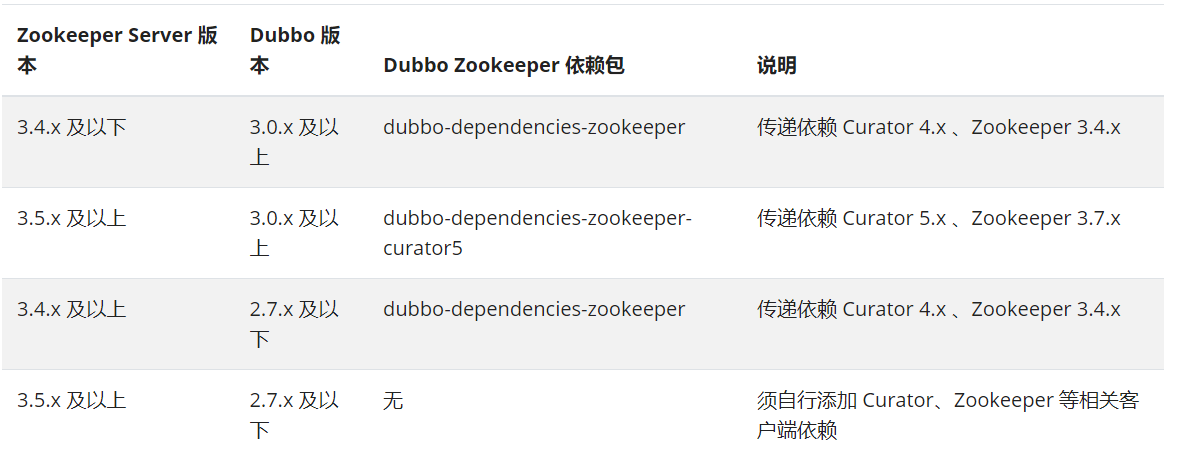
在之前的文章中,我们提到了我们的Dubbo版本为2.7.22。因此,在查阅了Dubbo官方文档中关于Dubbo版本与ZooKeeper版本之间的依赖关系后,我们选择的ZooKeeper官方镜像为zookeeper:3.4.9。
基于以上的历史原因,我们最终的部署文件如下所示:
apiVersion: v1
kind: Service
metadata:
name: zookeeper
namespace: your-namespace
spec:
selector:
app: zookeeper
type: NodePort
ports:
- name: client
port: 2181
targetPort: 2181
nodePort: 30000
- name: follower
port: 2888
targetPort: 2888
nodePort: 30001
- name: leader
port: 3888
targetPort: 3888
nodePort: 30002
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: zookeeper
namespace: your-namespace
spec:
replicas: 1
selector:
matchLabels:
app: zookeeper
template:
metadata:
labels:
app: zookeeper
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: project.node
operator: In
values:
- your-namespace
containers:
- name: zookeeper
image: zookeeper:3.4.9
imagePullPolicy: IfNotPresent
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
ports:
- containerPort: 2181
- containerPort: 2888
- containerPort: 3888
volumeMounts:
- name: data
mountPath: /data
volumes:
- name: data
hostPath:
path: /var/lib/docker/zookeeper
在这个配置文件中,我们使用了一个名为zookeeper的Deployment来部署单机ZooKeeper,并使用了一个名为zookeeper的Service来暴露端口。Service的类型被设置为NodePort,这样可以在集群外部链接ZooKeeper。Service的选择器指定了要暴露的Pod,这里使用了一个名为zookeeper的标签。Service的端口被设置为2181、2888和3888,分别对应ZooKeeper的客户端端口、跟随者端口和领导者端口。targetPort字段指定了要转发到Pod的端口,这里使用了相同的端口号。nodePort字段指定了要暴露的端口号,这里分别使用了30000、30001和30002端口。我们将/data目录挂载到了宿主机的/var/lib/docker/zookeeper目录。这个目录用于存储ZooKeeper的数据和日志。
启动一个Dubbo服务,我们使用刚刚部署的Zookeeper作为注册中心。同时,我们也部署了一个Dubbo-Admin,它同样链接到刚刚部署的Zookeeper上。登录到Dubbo-Admin前端页面,我们发现服务已经成功注册。至此,Zookeeper已成功迁移到云端。
ZooKeeper的平滑迁移
根据上述步骤,我们已经成功部署了一个可用的单机ZooKeeper。那么,如何将线上存量服务在不停机的情况下优雅的平滑迁移过来呢?
其实,在Dubbo官方文档中,已经给了我们答案:多注册中心地址不聚合。
Dubbo 注册中心和服务是独立配置的,通常开发者不用设置服务和注册中心组件之间的关联关系,Dubbo 框架会将自动执行以下动作:
- 对于所有的 Service 服务,向所有全局默认注册中心注册服务地址。
- 对于所有的 Reference 服务,从所有全局默认注册中心订阅服务地址。
<dubbo:registry id="one" address="zookeeper://127.0.0.1:9090" />
<dubbo:registry id="two" address="zookeeper://127.0.0.2:9010" />
因此,当我们配置如上所示独立配置的注册中心组件时,Dubbo会将所有的Service服务同时注册到这两个ZooKeeper上,并且所有的Reference服务也会同时订阅这两个ZooKeeper。地址列表在消费端默认是完全隔离的,负载均衡选址要经过两步:
- 注册中心集群间选址,选定一个集群
- 注册中心集群内选址,在集群内进行地址筛选
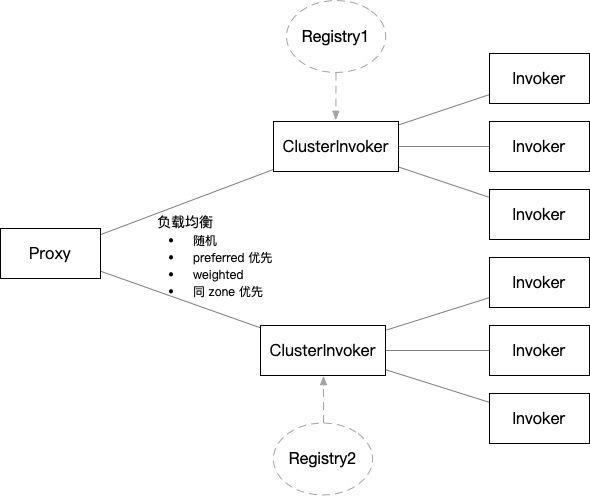
注册中心集群间选址策略有如下几种:
-
随机:默认策略,每次请求都随机的分配到一个注册中心集群。随机的过程中会有可用性检查,即每个集群要确保至少有一个地址可用才有可能被选到。
-
preferred 优先:如果有注册中心集群配置了
preferred="true",则所有流量都会被路由到这个集群。<dubbo:registry id="one" address="zookeeper://127.0.0.1:9090" preferred="true"/> <dubbo:registry id="two" address="zookeeper://127.0.0.2:9010" /> -
weighted:基于权重的随机负载均衡,以下集群间会有大概 10:1 的流量分布。
<dubbo:registry id="one" address="zookeeper://127.0.0.1:9090" weight="100"/> <dubbo:registry id="two" address="zookeeper://127.0.0.2:9010" weight="10"/> -
同 zone 优先:根据 Invocation 中带的流量参数或者在当前节点通过 context 上下文设置的参数,流量会被精确的引导到对应的集群。
<dubbo:registry id="one" address="zookeeper://127.0.0.1:9090" zone="one"/> <dubbo:registry id="two" address="zookeeper://127.0.0.2:9010" zone="two"/>RpcContext.getContext().setAttachment("registry_zone", "one");
在这里,我们采用默认的随机策略,因为在随机的过程中会有可用性检查,这确保了我们的消费者服务始终能够连接到可用的提供者服务,为我们不停机迁移提供了基础。
接下来,我们需要对代码进行修改,具体操作如下:
-
dubbo.xml:
-
删除以下部分:
<!-- zookeeper注册中心 --> <dubbo:registry address="${dubbox.registry.address}"/> -
新增以下部分:
<!-- 老zookeeper注册中心 --> <dubbo:registry id="oldZkRegistry" address="${dubbox.registry.address}"/> <!-- 新k8s上zk注册中心 --> <dubbo:registry id="newZkRegistry" address="${dubbox.registry.address.new}"/>
-
-
配置文件:在配置文件中,新增以下配置:
# 新k8s上zk注册中心地址,ip为宿主机的ip,端口为nodeport暴露的client的端口 dubbox.registry.address.new = zookeeper://xx.xx.xx.xx:30000
在经过改造后,我们的服务将同时注册到新的和旧的ZooKeeper上,这就相当于我们搭建了一个ZooKeeper集群。当所有的存量服务都完成改造并成功部署上线后,我们还需要对我们的代码进行进一步的改造。具体的步骤如下:
-
dubbo.xml:
-
删除以下部分:
<!-- 老zookeeper注册中心 --> <dubbo:registry id="oldZkRegistry" address="${dubbox.registry.address}"/> <!-- 新k8s上zk注册中心 --> <dubbo:registry id="newZkRegistry" address="${dubbox.registry.address.new}"/> -
新增以下部分:
<!-- 新k8s上zk注册中心 --> <dubbo:registry address="${dubbox.registry.address.new}"/>
-
-
配置文件:在配置文件中,删除以下配置:
# 老zk注册中心地址 dubbox.registry.address = zookeeper://xx.xx.xx.xx:2181
当我们的存量服务全部经过改造并成功部署上线后,我们的老ZooKeeper才能够进行停机下线。至此,ZooKeeper的平滑替换便顺利完成了。
小结
经过以上的阐述,我们可以明确地认识到,在决定ZooKeeper的部署版本时,我们需要进行深入细致的分析,充分考虑外部环境因素的影响,例如Duboo版本之间的兼容性问题。为了确保ZooKeeper的平稳迁移并维持服务的连续性,我们需要采取一系列策略,如逐步升级、严格的功能测试和版本兼容性检查等。要在生产环境中实现ZooKeeper的平滑迁移并保持服务不间断,这将需要投入大量的时间和精力。因此,在我们正式上线生产环境之前,必须进行详尽的规划,全面预见未来可能出现的情况,以最大程度地避免不必要的麻烦。只有这样,我们才能确保项目的长期稳定运行。