文章目录
- 0.卷积操作
- 1.注意力
-
- 1.1 注意力概述(Attention)
-
- 1.1.1 Encoder-Decoder
- 1.1.2 查询、键和值
- 1.1.3 注意力汇聚: Nadaraya-Watson 核回归
- 1.2 注意力评分函数
-
- 1.2.1 加性注意力
- 1.2.2 缩放点积注意力
- 1.3 自注意力(Self-Attention)
-
- 1.3.1 自注意力的定义和计算
- 1.3.2 自注意力的应用
- 1.3.3 Self-Attention 与 CNN 与 RNN
- 1.4 多头自注意力 (Multihead Attention)
- 2. Transformer
-
- 2.1 Transformer的整体结构
- 2.2 Transformer的输入
-
- 2.2.1 单词Embedding
- 2.2.2 位置Encoding
- 2.3 Transformer的Encoder-Decoder
-
- 2.3.1 Encoder block
- 2.3.2 Decoder block
- 2.4 Transformer的输出
- 2.5 Transformer的训练过程和损失函数
-
- 2.5.1 训练过程
- 2.5.2 损失函数
- 2.6 Transformer的代码实现
-
- 2.6.1 基于位置的前馈神经网络
- 2.6.2 残差连接和层规范化
- 2.6.3 编码器
- 2.6.4 解码器
- 2.6.5 训练
- 3. pytorch中的注意力机制类
-
- 3.1 torch.nn.MultiheadAttention
- 4. Transformer 在计算机视觉领域的应用
-
- 4.1 Vision Transformer
-
- 4.1.1 ViT的总体结构
- 4.1.2 Embedding层结构详解
- 4.1.3 Transformer Encoder详解
- 4.1.4 MLP Head详解
- 4.2 Swin Transformer
-
- 4.2.1 网络的整体框架
- 4.2.2 Patch Mering
- 4.2.3 W-MSA
- 4.2.4 SW-MSA
- 参考文献
0.卷积操作
深度学习中的卷积操作:https://blog.csdn.net/zyw2002/article/details/128306697
1.注意力
1.1 注意力概述(Attention)
1.1.1 Encoder-Decoder
Encoder-Decoder框架顾名思义也就是编码-解码框架,在NLP中Encoder-Decoder框架主要被用来处理序列-序列问题。也就是输入一个序列,生成一个序列的问题。这两个序列可以分别是任意长度。
具体到NLP中的任务比如:
- 文本摘要,输入一篇文章(序列数据),生成文章的摘要(序列数据)
- 文本翻译,输入一句或一篇英文(序列数据),生成翻译后的中文(序列数据)
- 问答系统,输入一个question(序列数据),生成一个answer(序列数据)
基于Encoder-Decoder框架具体使用什么模型实现,用的较多的应该就是seq2seq模型和Transformer了。
Encoder-Decoder中的输入和输出
输入
1)输入是一个向量
2)输入是一组向量
输出
1)每一个向量对应一个输出
2)整个序列只输出一个标签
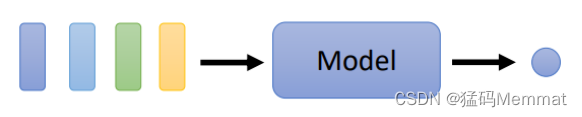
3)模型自己决定输出序列的长度
Encoder-Decoder中的结构原理
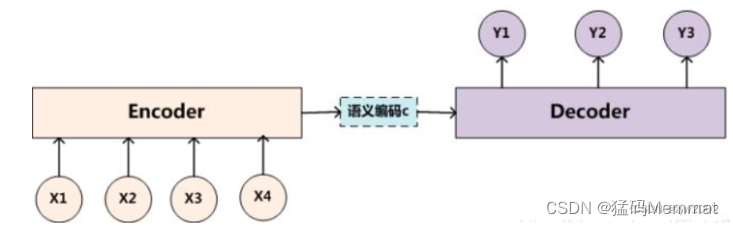
Encoder:编码器,对于输入的序列<x1,x2,x3…xn>进行编码,使其转化为一个语义编码C,这个C中就储存了序列<x1,x2,x3…xn>的信息。
Encoder 是怎么编码的呢?
编码方式有很多种,在文本处理领域主要有RNN/LSTM/GRU/BiRNN/BiLSTM/BiGRU,可以依照自己的喜好来选择编码方式
以RNN为例来具体说明一下:
以上图为例,输入<x1,x2,x3,x4>,通过RNN生成隐藏层的状态值<h1,h2,h3,h4>,如何确定语义编码C呢?最简单的办法直接用最后时刻输出的ht作为C的状态值,这里也就是可以用h4直接作为语义编码C的值,也可以将所有时刻的隐藏层的值进行汇总,然后生成语义编码C的值,这里就是C=q(h1,h2,h3,h4),q是非线性激活函数。
得到了语义编码C之后,接下来就是要在Decoder中对语义编码C进行解码了。
Decoder:解码器,根据输入的语义编码C,然后将其解码成序列数据,解码方式也可以采用RNN/LSTM/GRU/BiRNN/BiLSTM/BiGRU。
Decoder和Encoder的编码解码方式可以任意组合。
Decoder 是怎么解码的呢?
基于
seq2seq模型有两种解码方式:
解码方法1:《Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation》
该方法指出,因为语义编码C包含了整个输入序列的信息,所以在解码的每一步都引入C。文中Ecoder-Decoder均是使用RNN,在计算每一时刻的输出yt时,都应该输入语义编码C,即
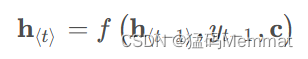
类似的,下一个符号的条件分布是:
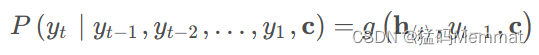
其中 h t h_t ht为当前t时刻的隐藏层的值, y t − 1 y_{t-1} yt−1为上一时刻的预测输出,作为t时刻的输入,每一时刻的语义编码C是相同地。
解码方法2:《Sequence to Sequence Learning with Neural Networks》
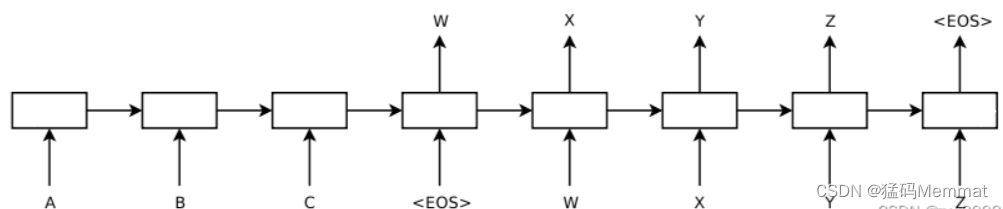
这个编码方式相对简单,只在Decoder的初始输入引入语义编码C,将语义编码C作为隐藏层状态值 h 0 h_0 h0的初始值,
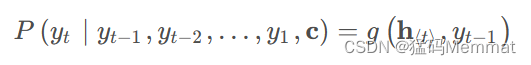
如上图,该模型读取一个输入句子“ABC”,并产生“WXYZ”作为输出句子。模型在输出句尾标记后停止进行预测。注意,LSTM读取反向输入句子,因为这样做会在数据中引入许多短期依赖关系
基于
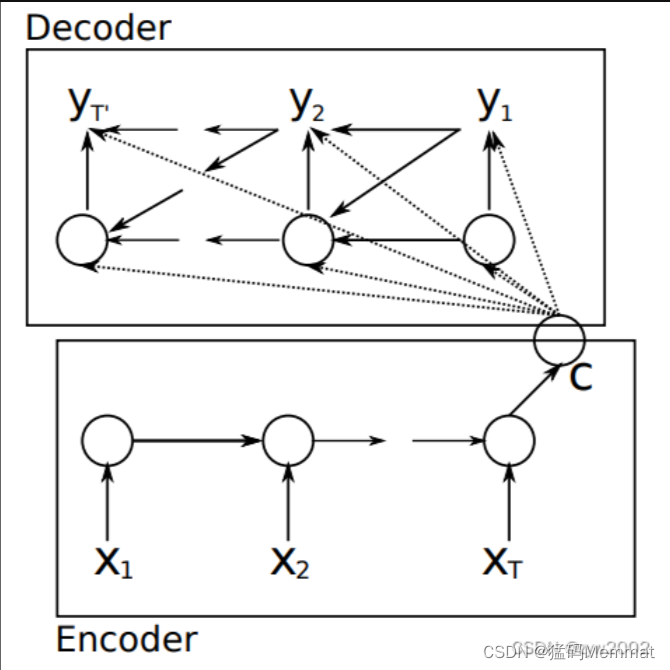
seq2seq模型有两种解码方式都不太好(两种解码方式都只采用了一个语义编码C),而基于attention模型的编码方式中采用了多个C
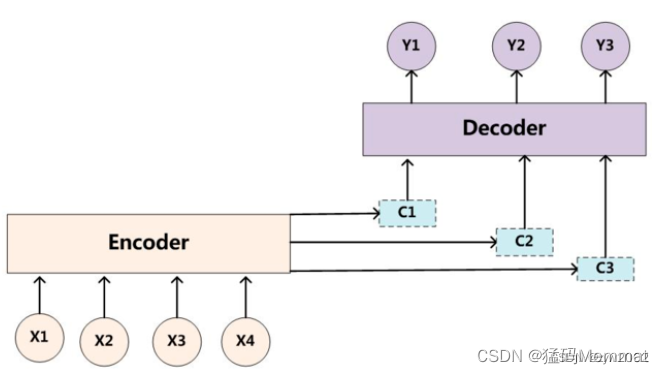
上图就是引入了Attention 机制的Encoder-Decoder框架。咱们一眼就能看出上图不再只有一个单一的语义编码C,而是有多个C1,C2,C3这样的编码。当我们在预测Y1时,可能Y1的注意力是放在C1上,那咱们就用C1作为语义编码,当预测Y2时,Y2的注意力集中在C2上,那咱们就用C2作为语义编码,以此类推,就模拟了人类的注意力机制。
以机器翻译例子"Tom chase Jerry" - "汤姆追逐杰瑞"来说明注意力机制:
当我们在翻译"杰瑞"的时候,为了体现出输入序列中英文单词对于翻译当前中文单词不同的影响程度,比如给出类似下面一个概率分布值:
(Tom,0.3)(Chase,0.2)(Jerry,0.5)
每个英文单词的概率代表了翻译当前单词“杰瑞”时,注意力分配模型分配给不同英文单词的注意力大小。这对于正确翻译目标语单词肯定是有帮助的,因为引入了新的信息。同理,目标句子中的每个单词都应该学会其对应的源语句子中单词的注意力分配概率信息。这意味着在生成每个单词Yi的时候,原先都是相同的中间语义表示C会替换成根据当前生成单词而不断变化的Ci。理解AM模型的关键就是这里,即由固定的中间语义表示C换成了根据当前输出单词来调整成加入注意力模型的变化的Ci。
每个Ci 对应这不同源语句子单词的注意力分配概率,比如对于上面的英汉翻译来说,对应的信息可能如下:
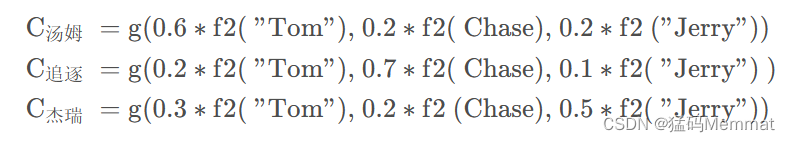
f2(“Tom”),f2(“Chase”),f2(“Jerry”)就是对应的隐藏层的值h(“Tom”),h(“Chase”),h(“Jerry”)。g函数就是加权求和。αi表示权值分布。因此Ci的公式就可以写成:
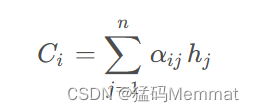
怎么知道attention模型所需要的输入句子单词注意力分配概率分布值 a i j a_{ij} aij呢? 我们可以通过下文介绍的注意力评分函数求得
1.1.2 查询、键和值
下面来看看如何通过自主性的与非自主性的注意力提示, 用神经网络来设计注意力机制的框架。
首先,考虑一个相对简单的状况, 即只使用非自主性提示。 要想将选择偏向于感官输入, 则可以简单地使用参数化的全连接层, 甚至是非参数化的最大汇聚层或平均汇聚层。
在注意力机制的背景下,自主性提示被称为查询(query)。 给定任何查询,注意力机制通过注意力汇聚(attention pooling)将选择引导至感官输入(sensory inputs,例如中间特征表示)。在注意力机制中,这些感官输入被称为值(value)。 更通俗的解释,每个值都与一个键(key)配对, 这可以想象为感官输入的非自主提示。
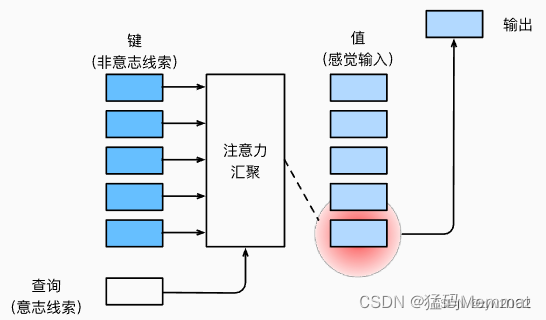
如上图: 注意力机制通过注意力汇聚(注意力的分配方法)将查询(自主性提示)和键(非自主性提示)结合在一起,实现对值(感官输入)的选择倾向。
1.1.3 注意力汇聚: Nadaraya-Watson 核回归
上图中的注意力汇聚是怎么实现的呢?
可通过Nadaraya-Watson核回归模型来了解常见的注意力汇聚模型(平均汇聚、非参数注意力汇聚、带参数注意力汇聚)。
为什么要在机器学习中引入注意力机制呢?
在全连接层,FC只能考虑相邻的几个数据,但是无法考虑到整个序列。
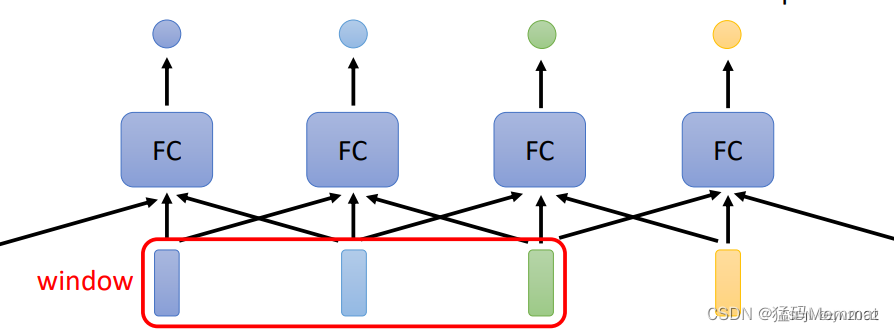
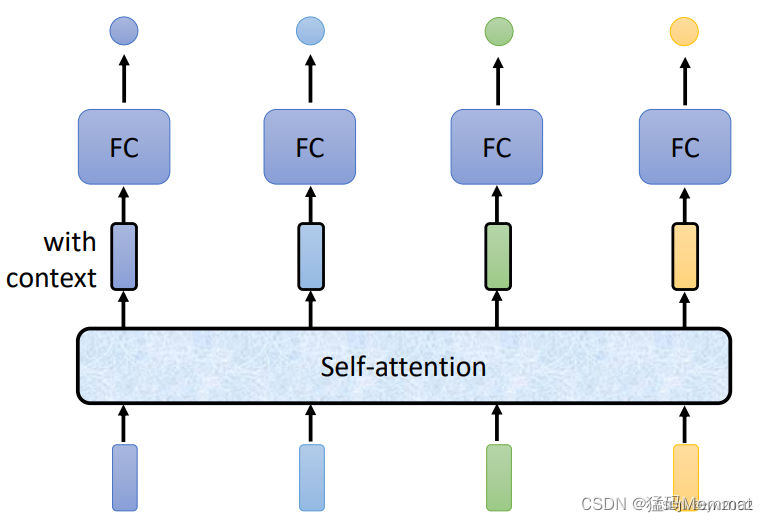
注意力机制(self-attention)可以考虑到整个序列的信息。因此,输出的向量带有全局的上下文信息。
1.2 注意力评分函数
接下来,我们讲解如何通过注意力评分函数来分配注意力。
我们使用高斯核来对查询(query)和键(key)之间的关系建模。 我们可以将高斯核指数部分视为注意力评分函数(attention scoring function), 简称评分函数(scoring function),然后把这个函数的输出结果输入到softmax函数中进行运算。 通过上述步骤,我们将得到与键对应的值的概率分布(即注意力权重)。最后,注意力汇聚的输出就是基于这些注意力权重的值的加权和。
下图说明了如何将注意力汇聚的输出计算成为值的加权和, 其中a表示注意力评分函数。 由于注意力权重是概率分布, 因此加权和其本质上是加权平均值。
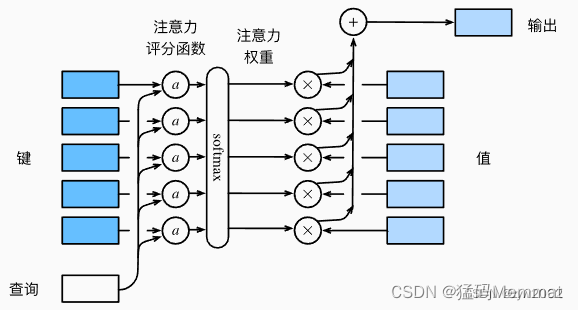

正如我们所看到的,选择不同的注意力评分函数a会导致不同的注意力汇聚操作。 在本节中,我们将介绍两个流行的评分函数(加性注意力、缩放点积注意力),稍后将用他们来实现更复杂的注意力机制。
掩蔽softmax操作
掩蔽softmax操作, 是为实现下文的评分函数做铺垫。
正如上面提到的,softmax操作用于输出一个概率分布作为注意力权重。 在某些情况下,并非所有的值都应该被纳入到注意力汇聚中。 例如,为了高效处理小批量数据集, 某些文本序列被填充了没有意义的特殊词元。 为了仅将有意义的词元作为值来获取注意力汇聚, 我们可以指定一个有效序列长度(即词元的个数), 以便在计算softmax时过滤掉超出指定范围的位置。 通过这种方式,我们可以在下面的masked_softmax函数中 实现这样的掩蔽softmax操作(masked softmax operation), 其中任何超出有效长度的位置都被掩蔽并置为0。
#@save
def masked_softmax(X, valid_lens):
"""通过在最后一个轴上掩蔽元素来执行softmax操作"""
# X:3D张量,valid_lens:1D或2D张量
if valid_lens is None:
return nn.functional.softmax(X, dim=-1)
else:
shape = X.shape
if valid_lens.dim() == 1:
valid_lens = torch.repeat_interleave(valid_lens, shape[1])
else:
valid_lens = valid_lens.reshape(-1)
# 最后一轴上被掩蔽的元素使用一个非常大的负值替换,从而其softmax输出为0
X = d2l.sequence_mask(X.reshape(-1, shape[-1]), valid_lens,
value=-1e6)
return nn.functional.softmax(X.reshape(shape), dim=-1)
为了演示此函数是如何工作的, 考虑由两个2×4矩阵表示的样本, 这两个样本的有效长度分别为2和3。 经过掩蔽softmax操作,超出有效长度的值都被掩蔽为0。
masked_softmax(torch.rand(2, 2, 4), torch.tensor([2, 3]))
tensor([[[0.5423, 0.4577, 0.0000, 0.0000],
[0.6133, 0.3867, 0.0000, 0.0000]],
[[0.3324, 0.2348, 0.4329, 0.0000],
[0.2444, 0.3943, 0.3613, 0.0000]]])
同样,我们也可以使用二维张量,为矩阵样本中的每一行指定有效长度。
masked_softmax(torch.rand(2, 2, 4), torch.tensor([[1, 3], [2, 4]]))
tensor([[[1.0000, 0.0000, 0.0000, 0.0000],
[0.4142, 0.3582, 0.2275, 0.0000]],
[[0.5565, 0.4435, 0.0000, 0.0000],
[0.3305, 0.2070, 0.2827, 0.1798]]])
1.2.1 加性注意力
#@save
class AdditiveAttention(nn.Module):
"""加性注意力"""
def __init__(self, key_size, query_size, num_hiddens, dropout, **kwargs):
super(AdditiveAttention, self).__init__(**kwargs)
self.W_k = nn.Linear(key_size, num_hiddens, bias=False)
self.W_q = nn.Linear(query_size, num_hiddens, bias=False)
self.w_v = nn.Linear(num_hiddens, 1, bias=False)
self.dropout = nn.Dropout(dropout)
def forward(self, queries, keys, values, valid_lens):
queries, keys = self.W_q(queries), self.W_k(keys)
# 在维度扩展后,
# queries的形状:(batch_size,查询的个数,1,num_hidden)
# key的形状:(batch_size,1,“键-值”对的个数,num_hiddens)
# 使用广播方式进行求和
features = queries.unsqueeze(2) + keys.unsqueeze(1)
features = torch.tanh(features)
# self.w_v仅有一个输出,因此从形状中移除最后那个维度。
# scores的形状:(batch_size,查询的个数,“键-值”对的个数)
scores = self.w_v(features).squeeze(-1)
self.attention_weights = masked_softmax(scores, valid_lens)
# values的形状:(batch_size,“键-值”对的个数,值的维度)
return torch.bmm(self.dropout(self.attention_weights), values)
我们用一个小例子来演示上面的AdditiveAttention类, 其中查询、键和值的形状为(批量大小,步数或词元序列长度,特征大小), 实际输出为(2,1,20)、(2,10,2)和(2,10,4)。 注意力汇聚输出的形状为(批量大小,查询的步数,值的维度)。
queries, keys = torch.normal(0, 1, (2, 1, 20)), torch.ones((2, 10, 2))
# values的小批量,两个值矩阵是相同的
values =