机器学习的五个步骤:
数据模块——模型——损失函数——优化器——训练

在实际项目中,如果数据量很大,考虑到内存有限、I/O 速度等问题,在训练过程中不可能一次性的将所有数据全部加载到内存中,也不能只用一个进程去加载,所以就需要多进程、迭代加载,而 DataLoader 就是基于这些需要被设计出来的。DataLoader 是一个迭代器,最基本的使用方法就是传入一个 Dataset 对象,它会根据参数 batch_size 的值生成一个 batch 的数据,节省内存的同时,它还可以实现多进程、数据打乱等处理。
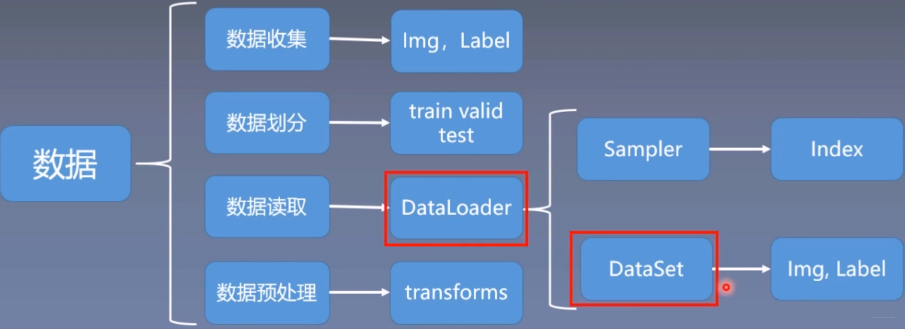
pytorch的数据读取机制DataLoader包括两个子模块,Sampler模块,主要是生成索引index,DataSet模块,主要是根据索引读取数据。
Dataset是用来解决数据从哪里读取以及如何读取的问题。pytorch给定的Dataset是一个抽象类,所有自定义的Dataset都要继承它,并且复写__getitem__()和__len__()类方法,getitem()的作用是接受一个索引,返回一个样本或者标签。
系统学习Pytorch笔记三:Pytorch数据读取机制(DataLoader)与图像预处理模块(transforms)
pytorch笔记-数据读取机制DataLoader