CUML库
最近在做机器学习任务的时候发现我自己的数据集太大,直接用sklearn 跑起来时间很长,然后问GPT得知了有CUML库,后来去研究了一下,发现这个库只支持linux系统,从官网直接获取下载命令基本上也实现不了最后,选择使用AutoDL租了一个GPU来安装这个库。具体步骤如下。
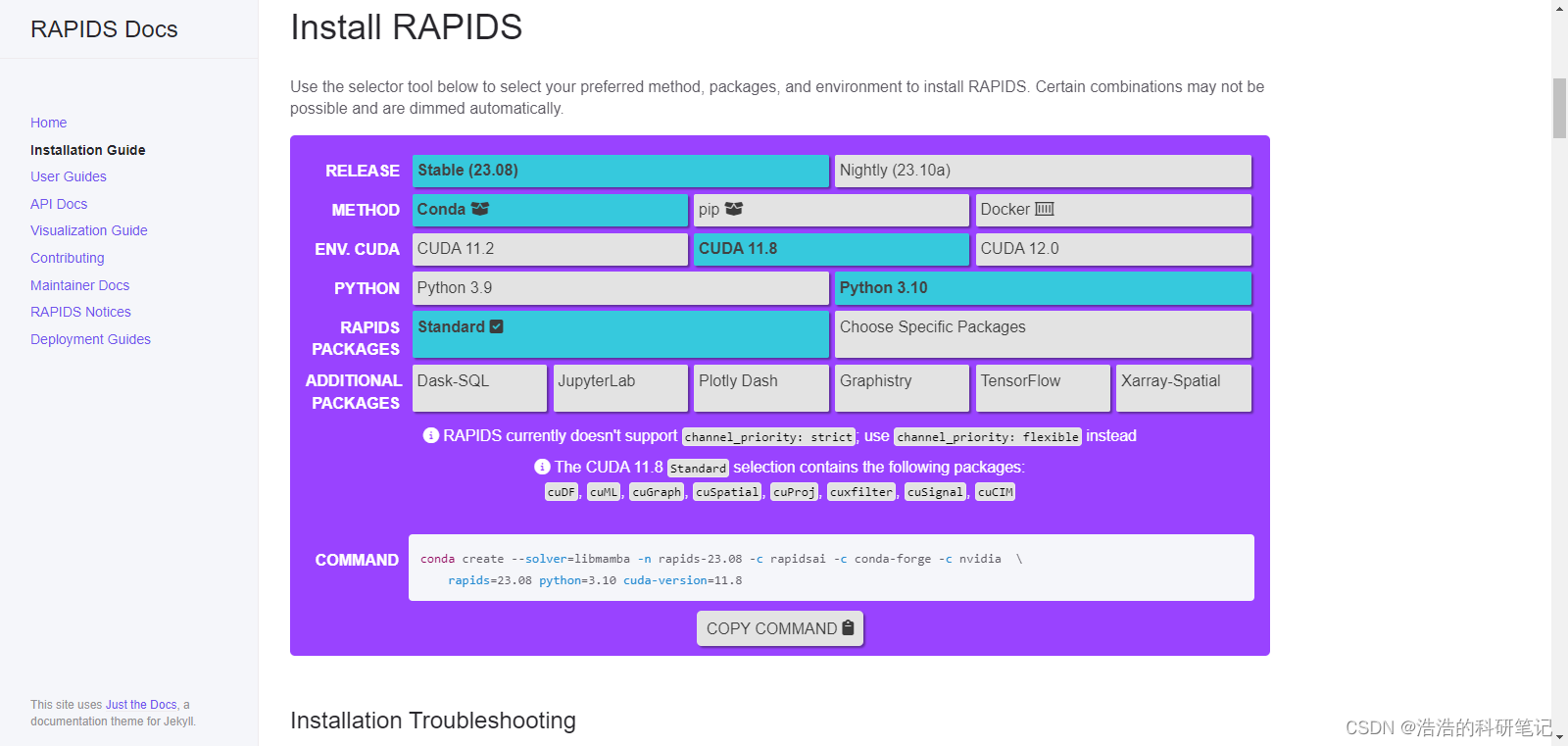
如果是正常讨论的话本身电脑就是liunx系统,按照道理说,直接去下面的官网链接去过去下载指令就可以了。进去之后的界面如下,反正我是没有成功,单我看似乎别人都是这吗做的,所以姑且把链接贴上。
链接: https://docs.rapids.ai/install#prerequisites
安装
接下啦是我的方法,首先进入AutoDL官网
链接: https://www.autodl.com/home
点击右上角的控制台
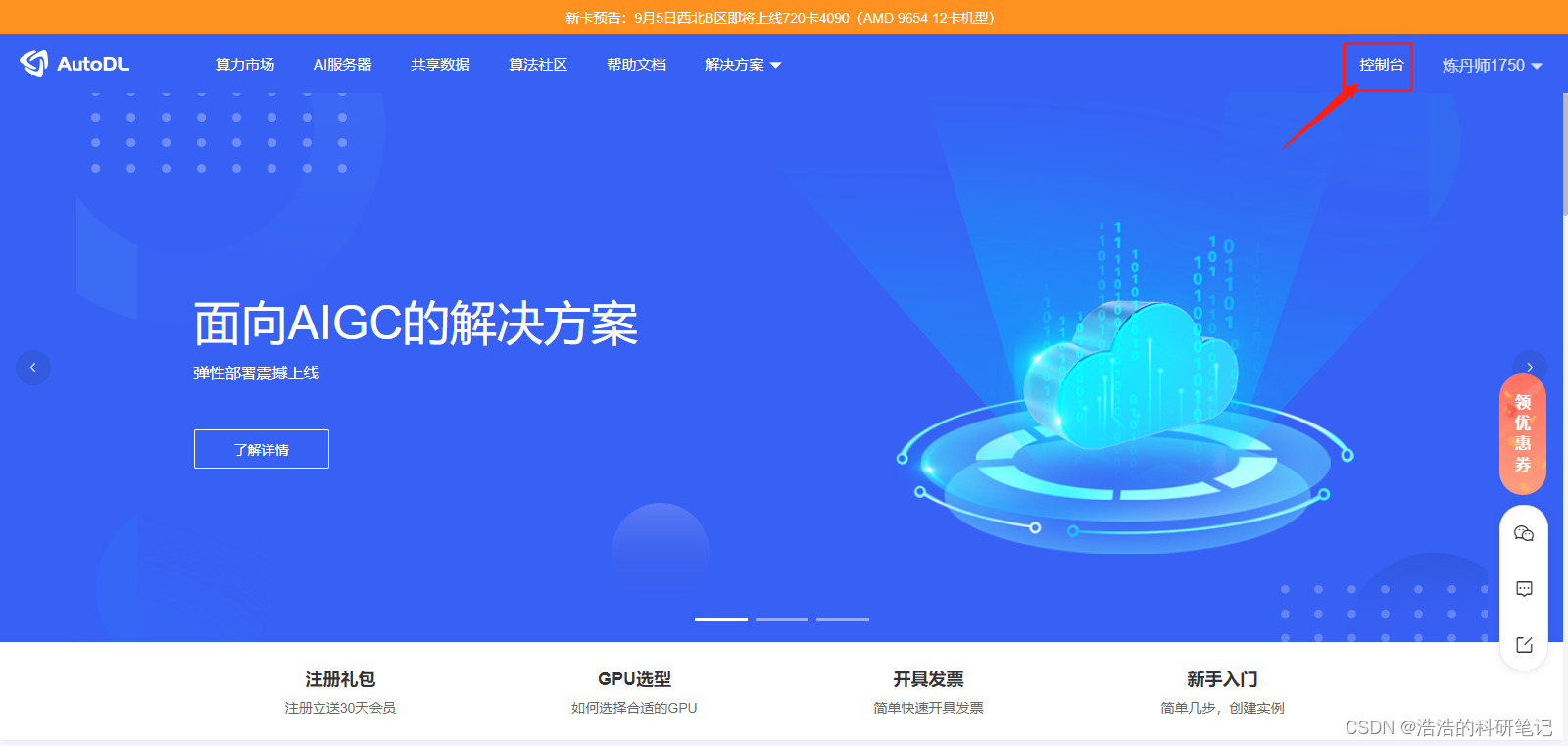
点击左侧的实例容器
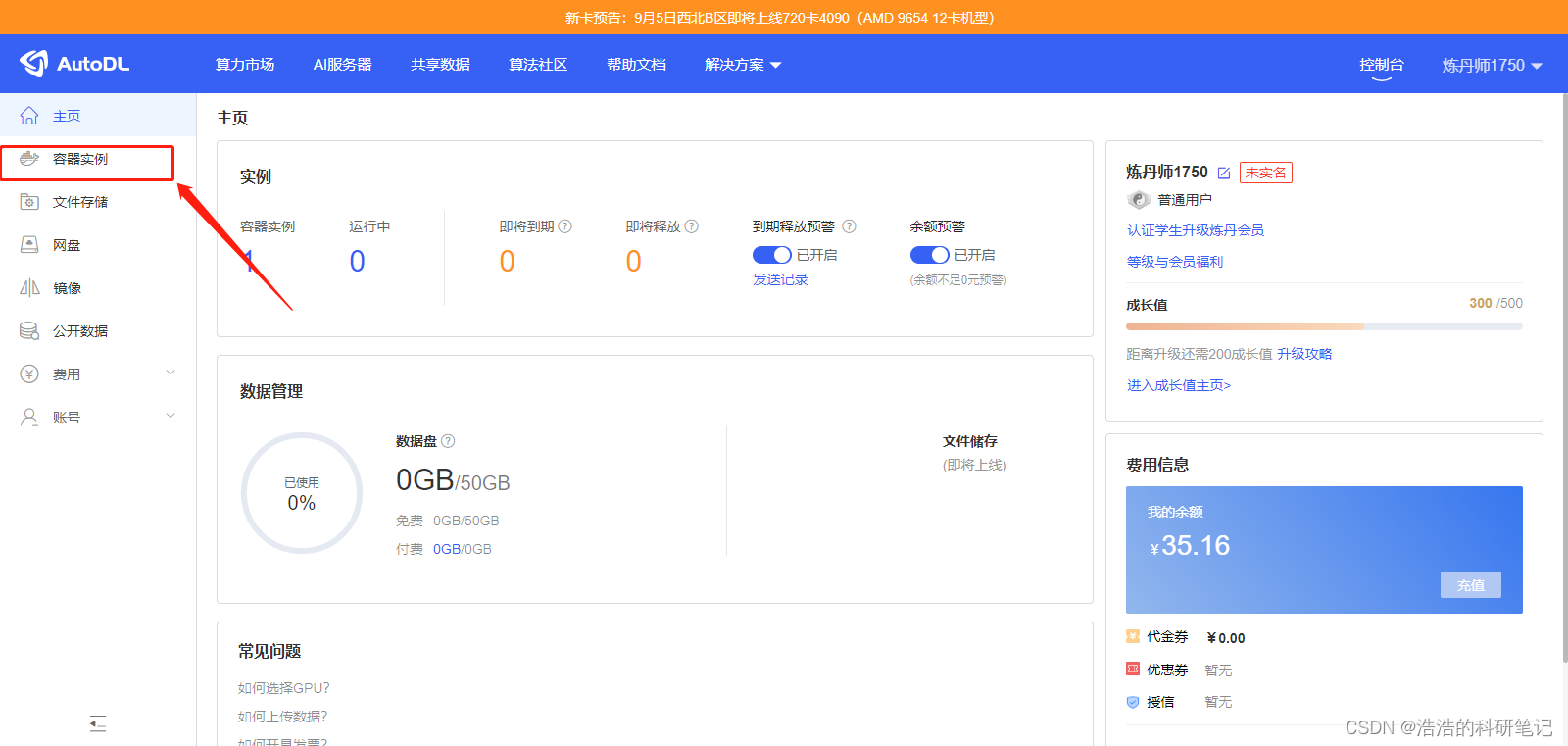
点击租用新的实例
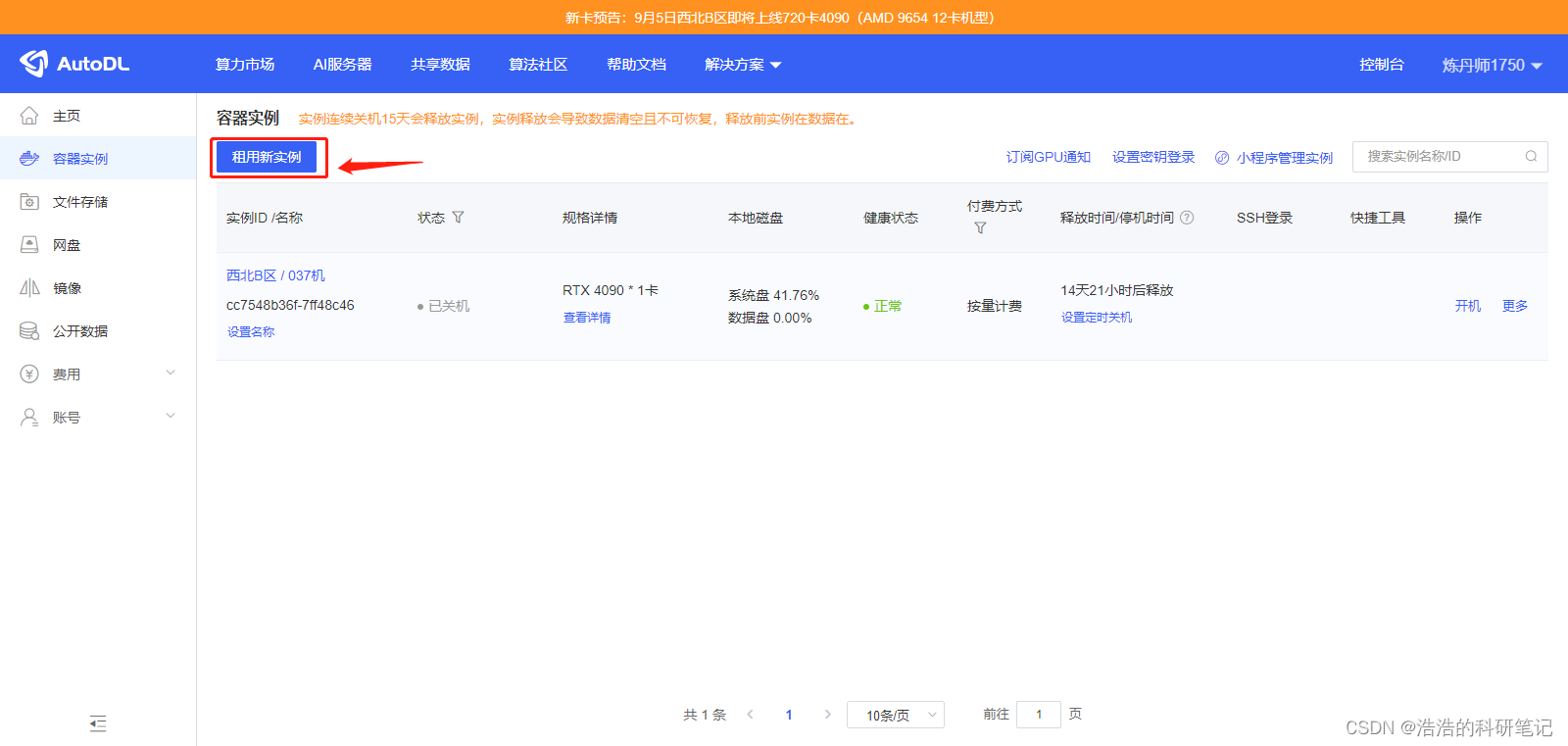
选择一个带GPU的设备
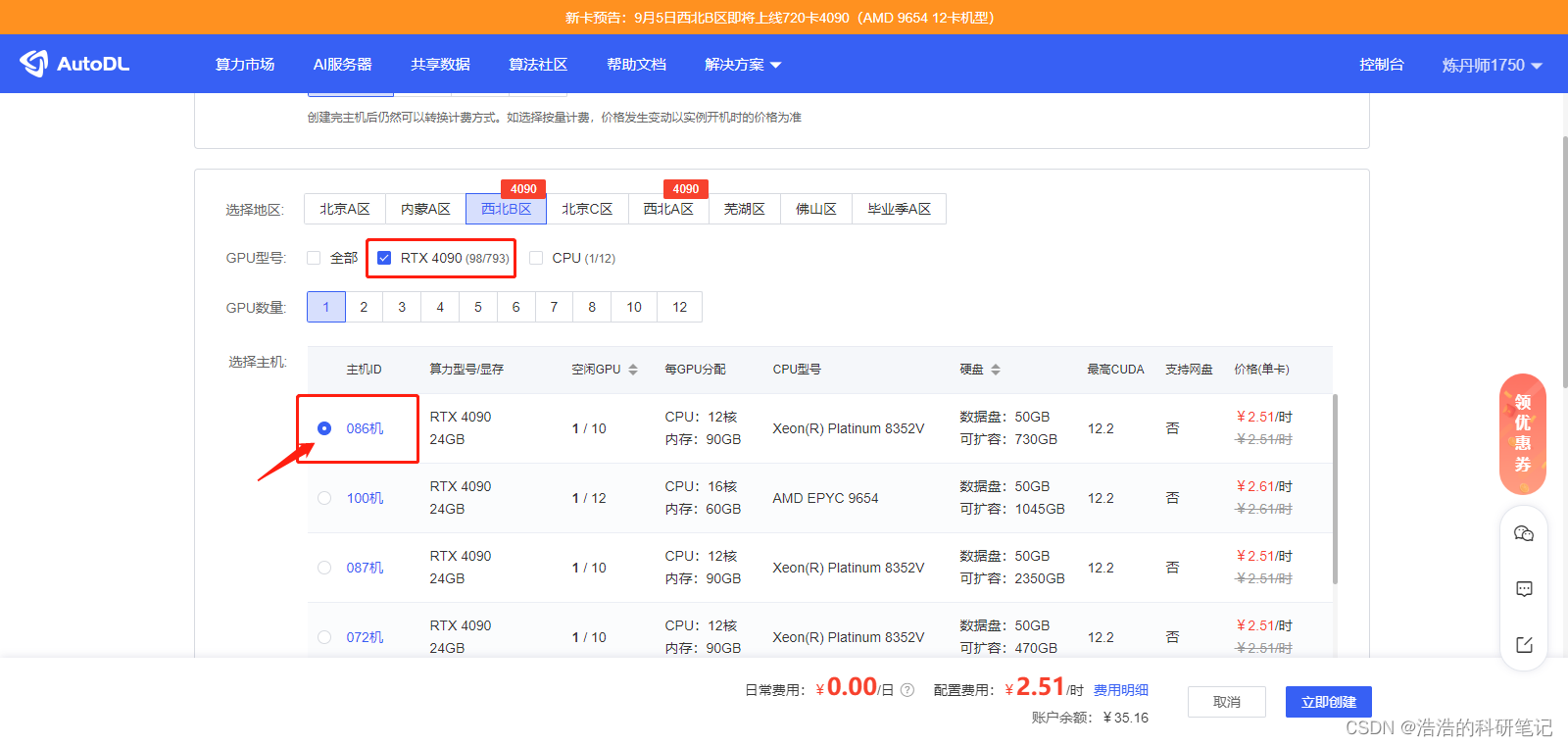
滑到最底部然后选择框架,以及cuda版本

点击立即创建
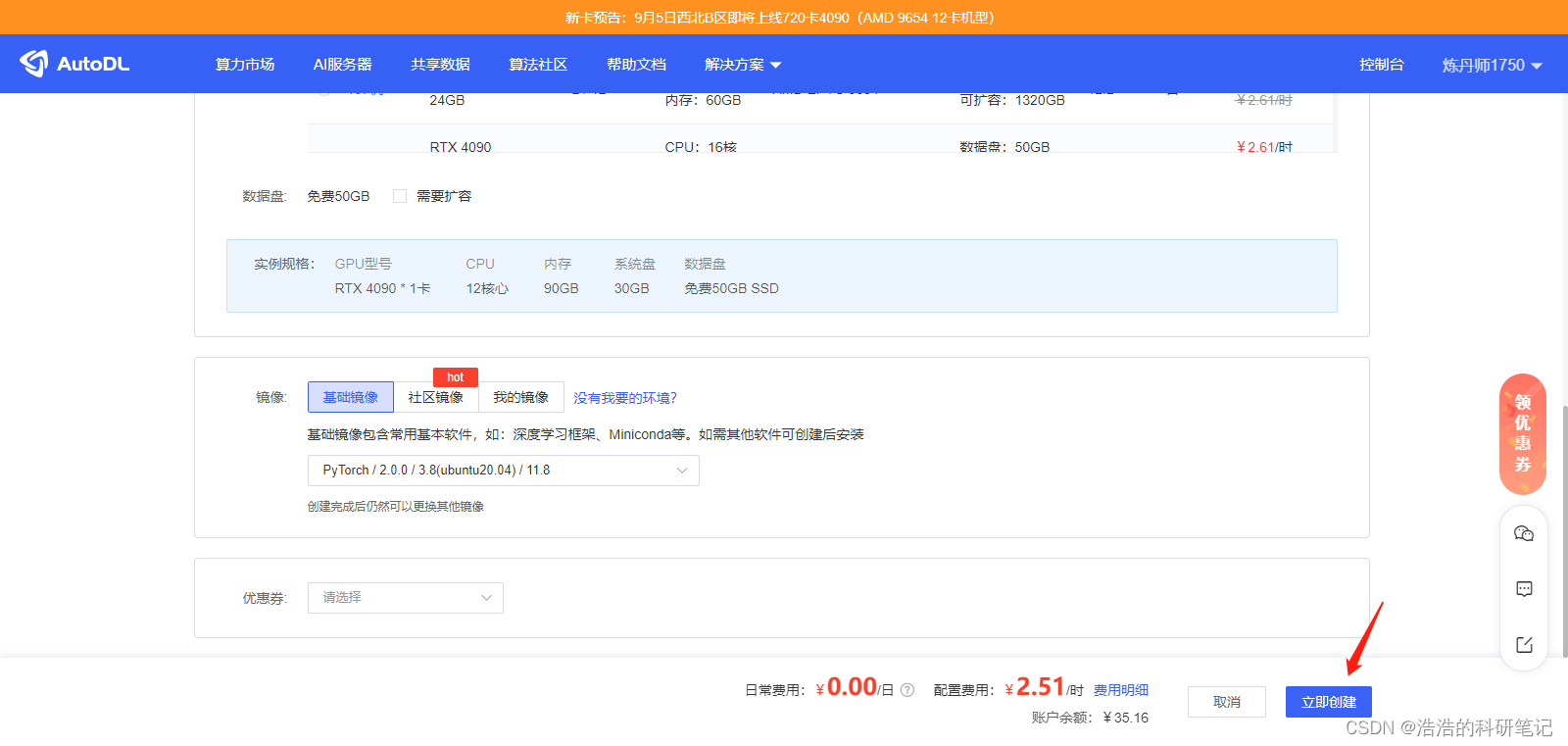
创建成功之后点击右侧的jupterlab
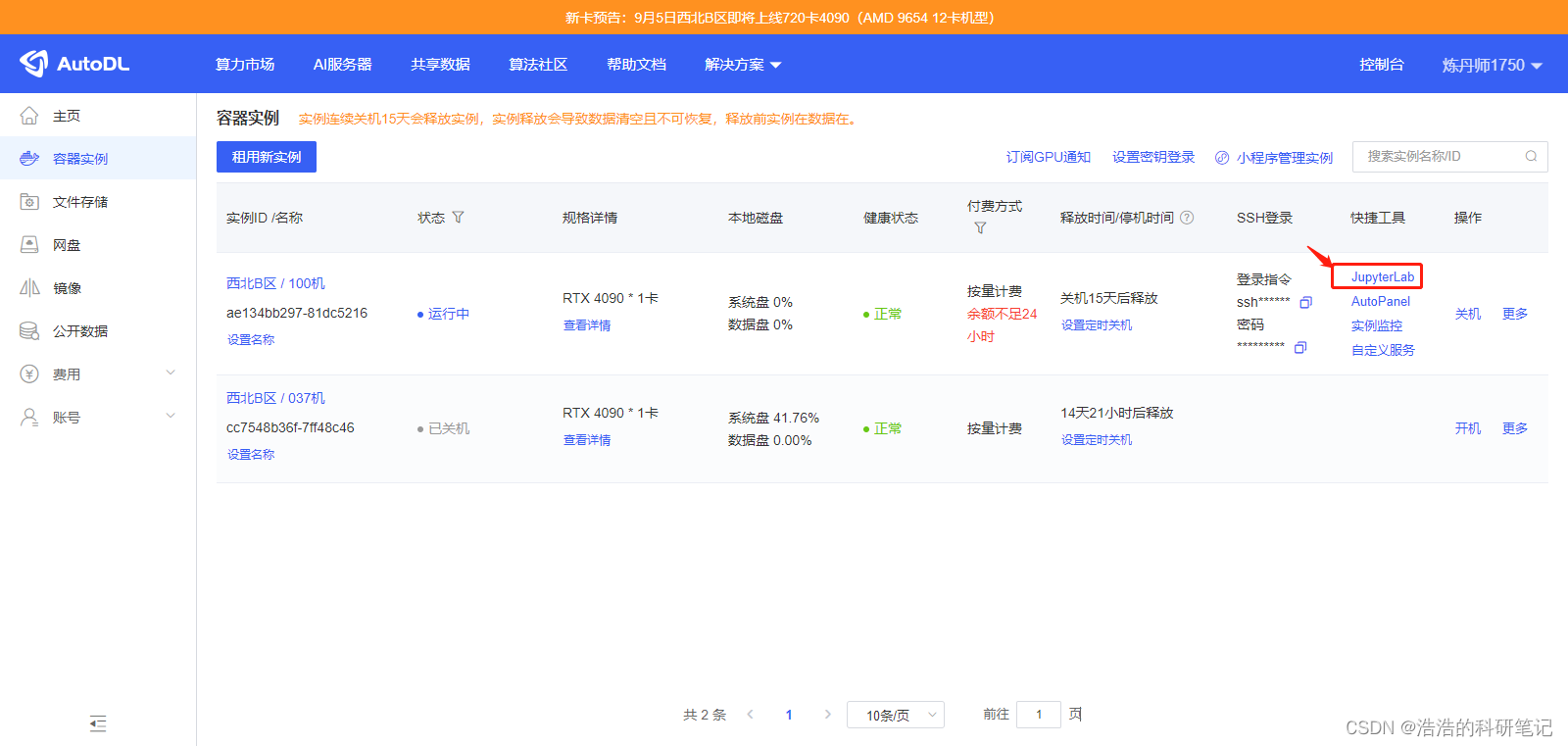
点击下面的终端创建一个终端窗口
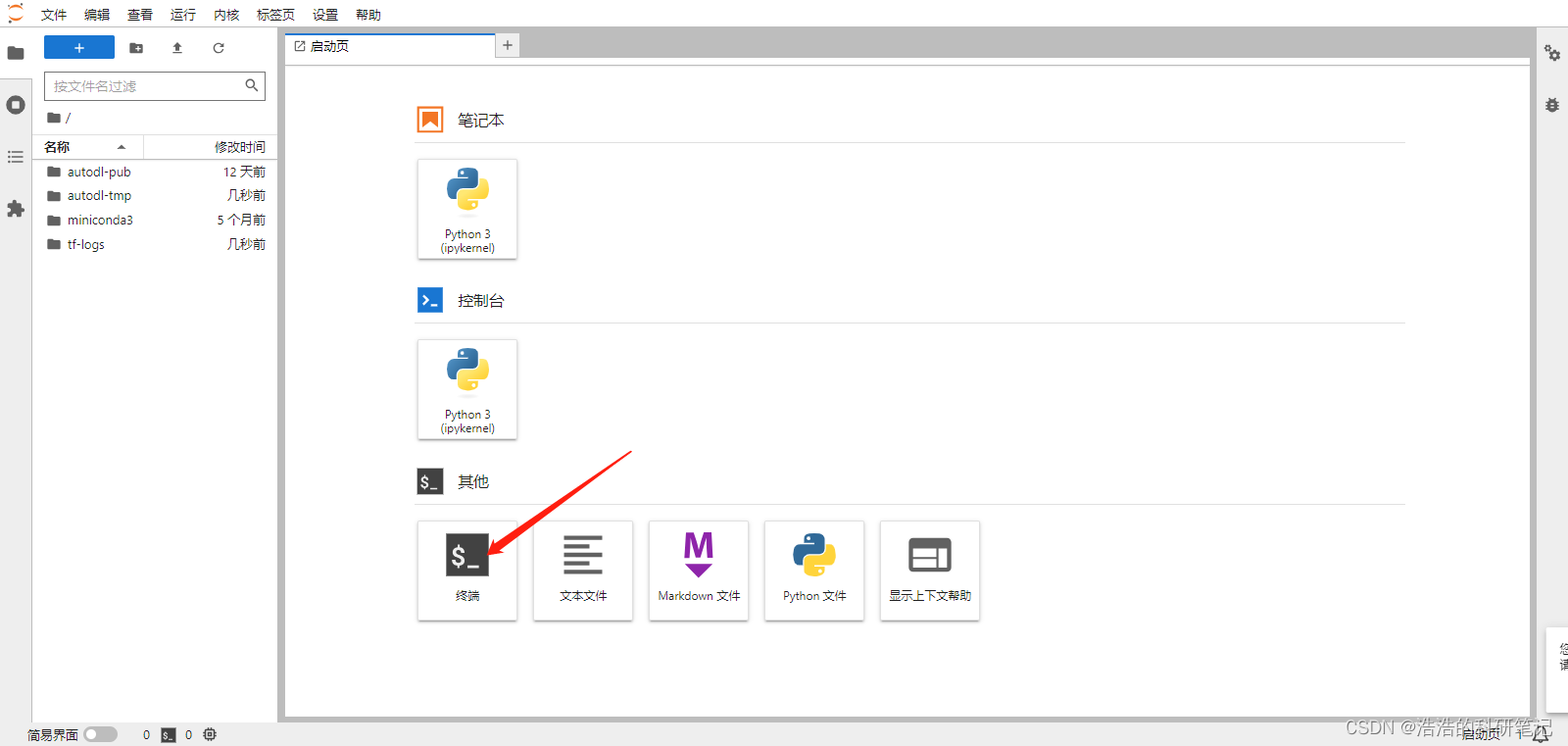
然后再里面我们需要建立一个新的解释器环境,来保证与cuml库适配,不会因为python版本问题导致安装失败。
我们先输入如下指令
conda create -n rapids python=3.9
然后输入y敲回车进入安装
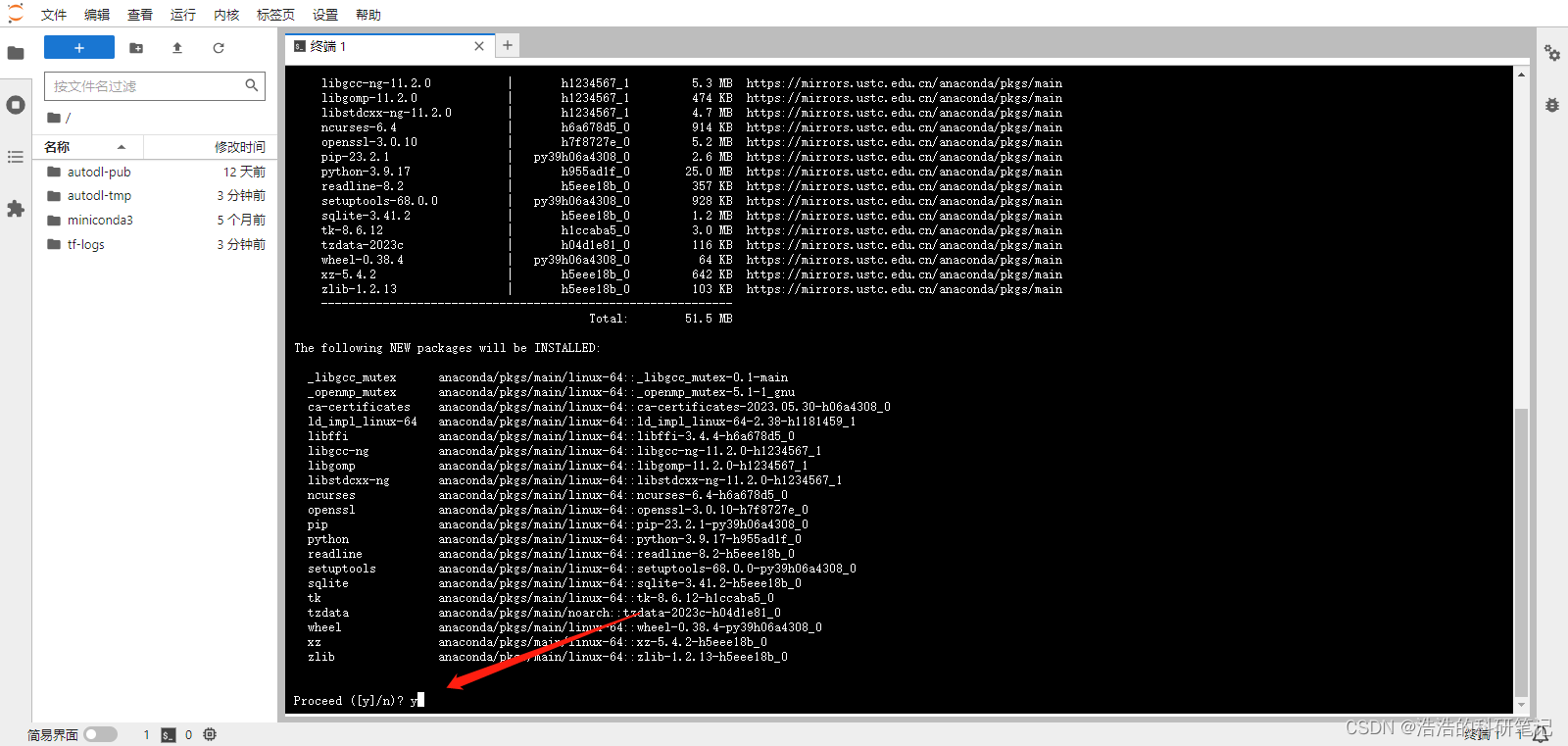
然后输入如下指令
source activate rapids
进入我们刚刚安装好的环境
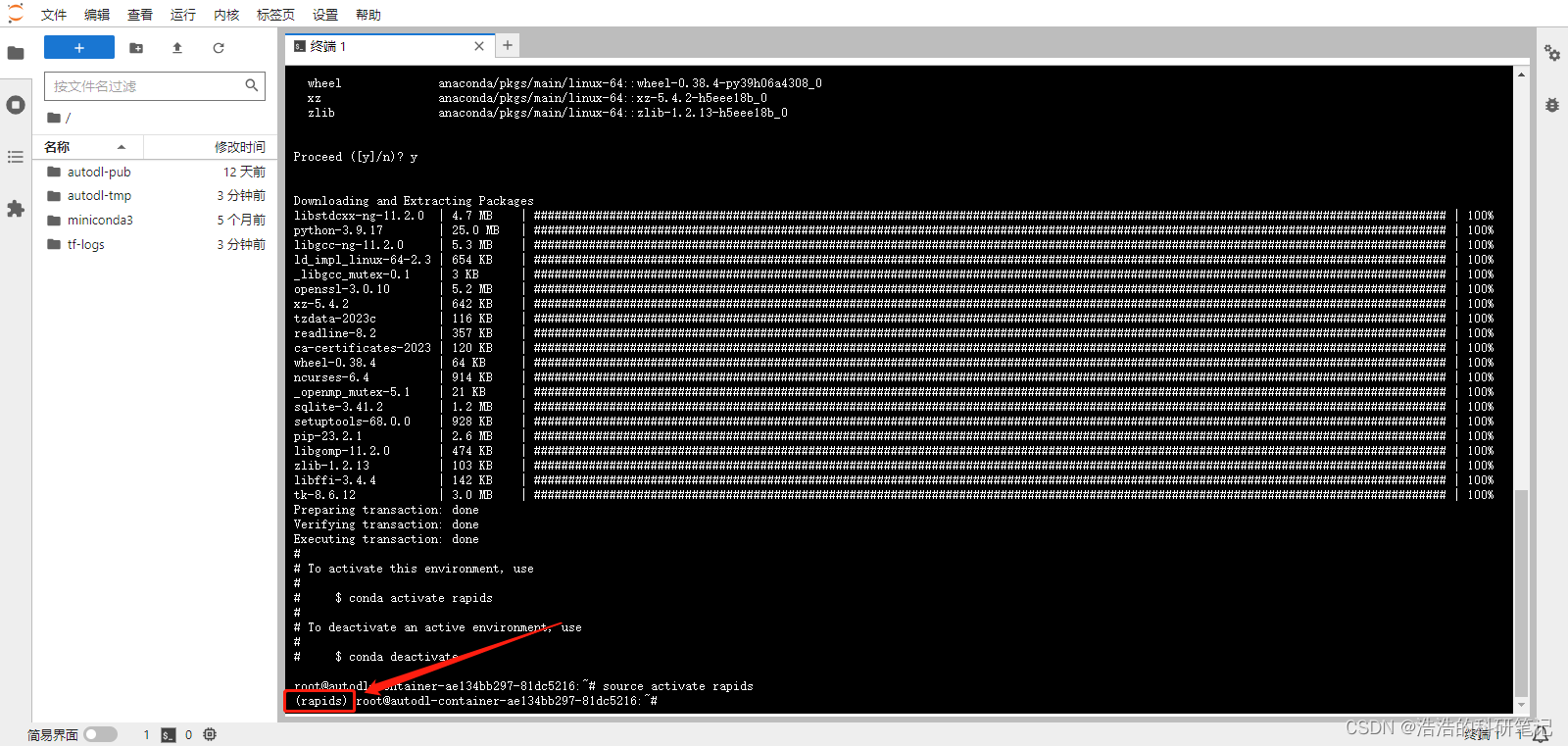
最关键的部分来了请运行如下命令,从这个源安装cuml库
pip install --default-time=300 --extra-index-url=https://pypi.nvidia.com cuml-cu11
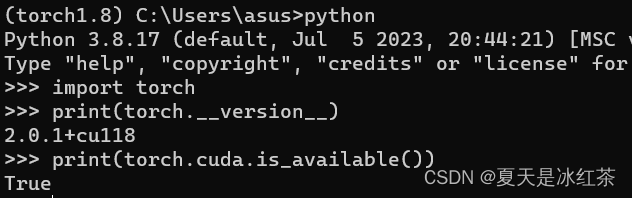
等待安装成功之后,在命令行输入python,然后再输入import cuml
OK 没问题
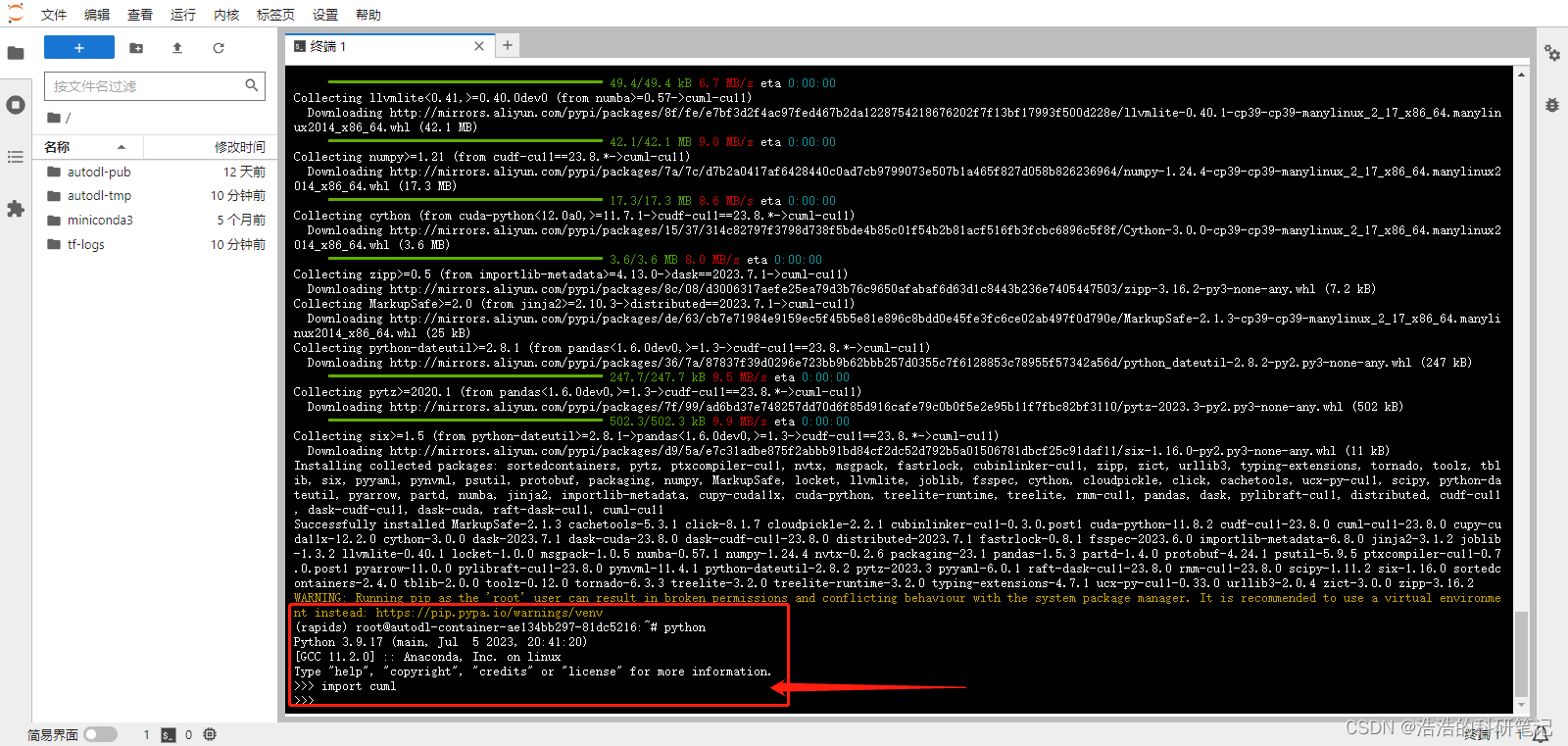
然后我们要在jupter上使用所以需要配置一下新的内核,我们先输入exit()退出python,然后再命令行输入如下命令
python -m ipykernel install --name rapids
如果遇到如下情况我们先安装ipykernel
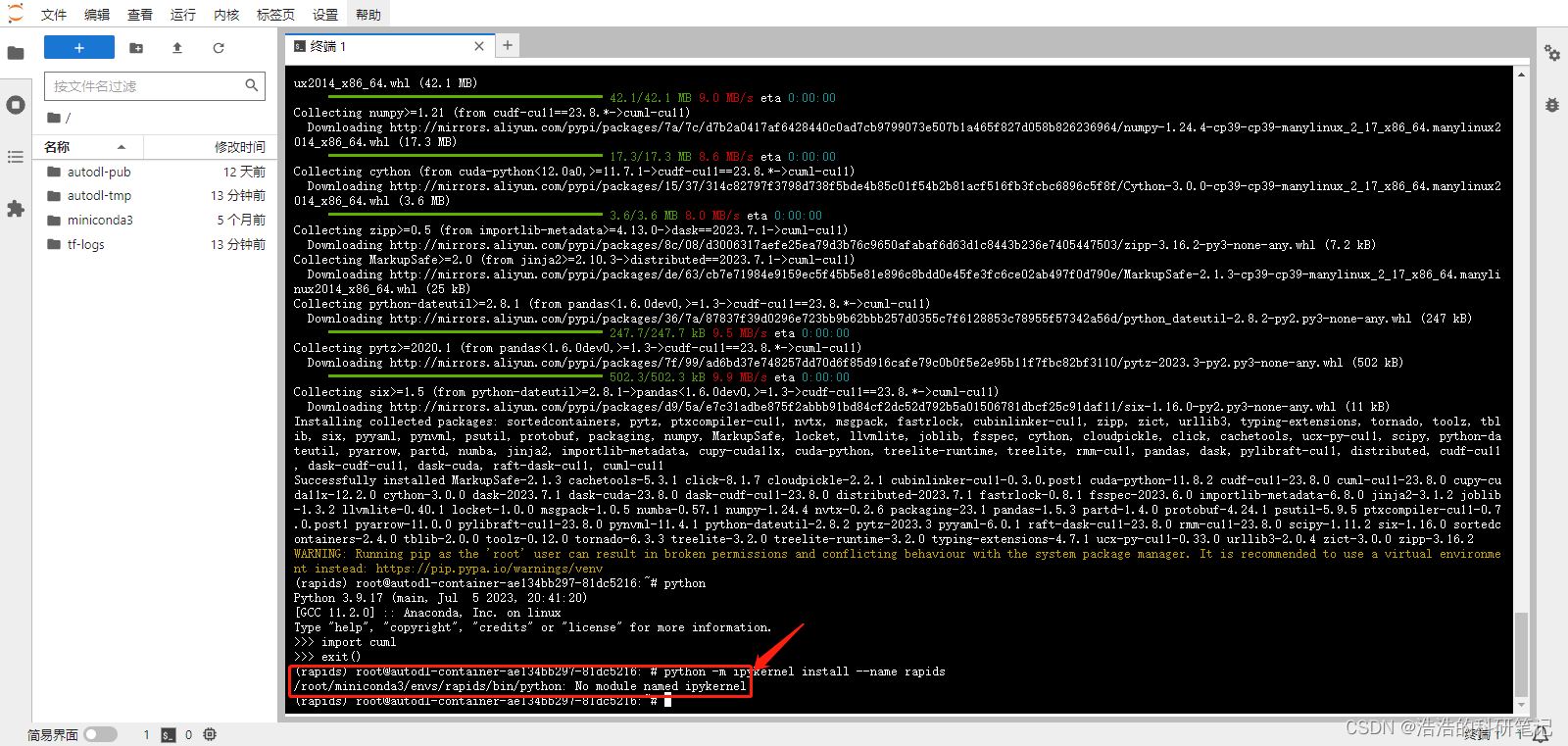
输入如下指令安装
pip install ipykernel
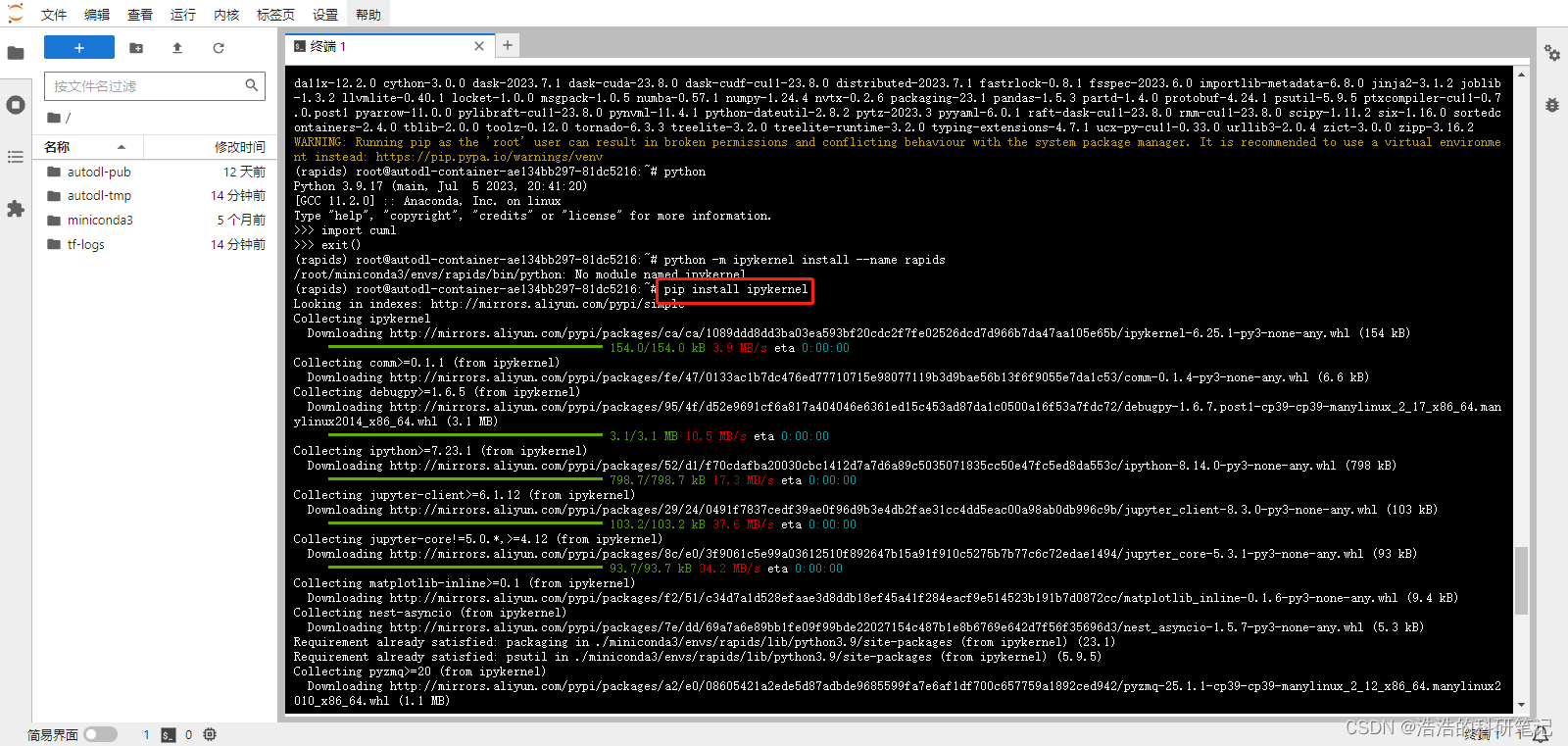
之后输入
python -m ipykernel install --name rapids
注意一定要在新建的环境下输入该命令
如果安装错了运行如下命令删除内核
jupyter kernelspec remove rapids
之后点击一下浏览器的页面刷新
再点击右侧加号
即可以看到新的内核的jupter笔记本,点开笔记本。
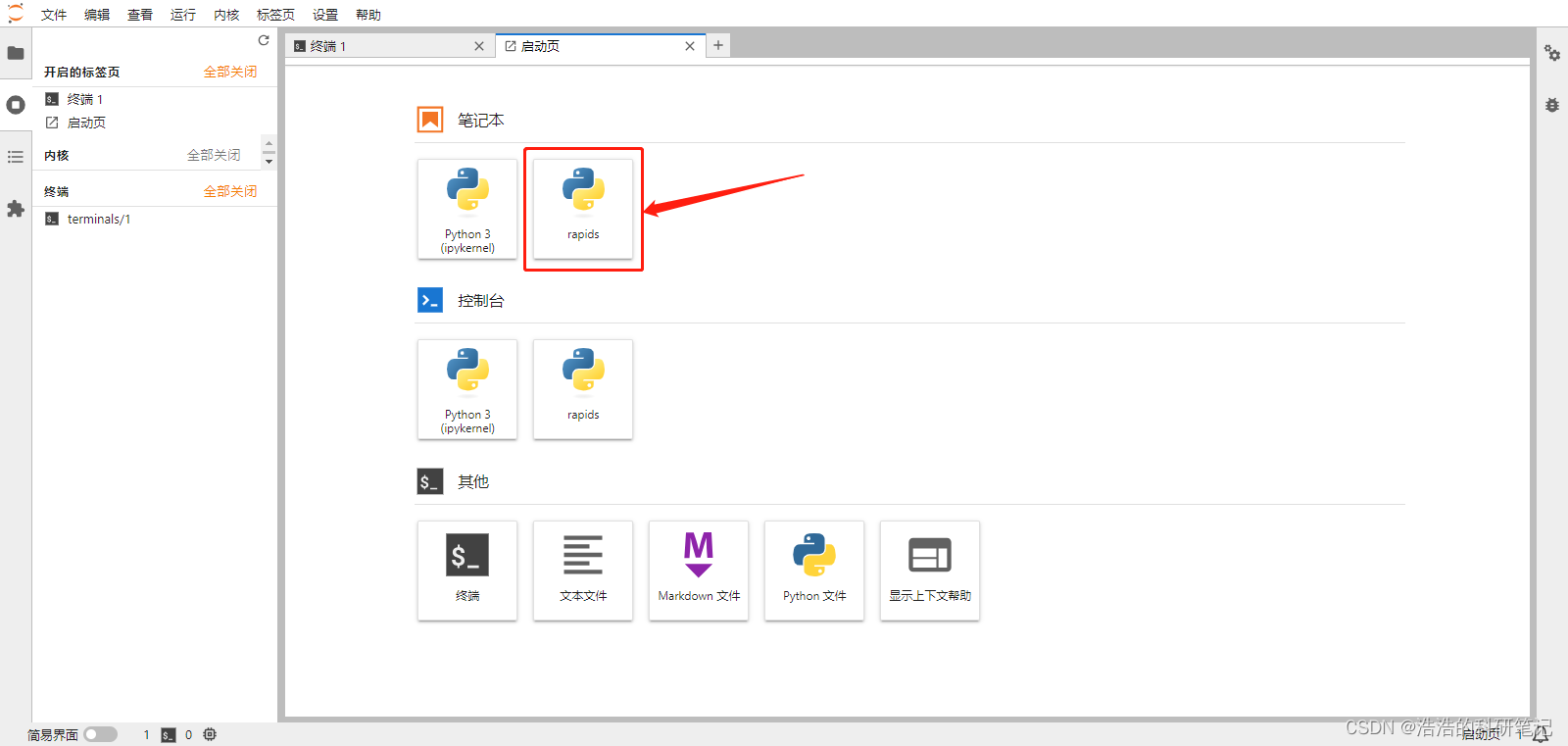
输入
import cuml
然后点击上方小三角,没有报错运行成功
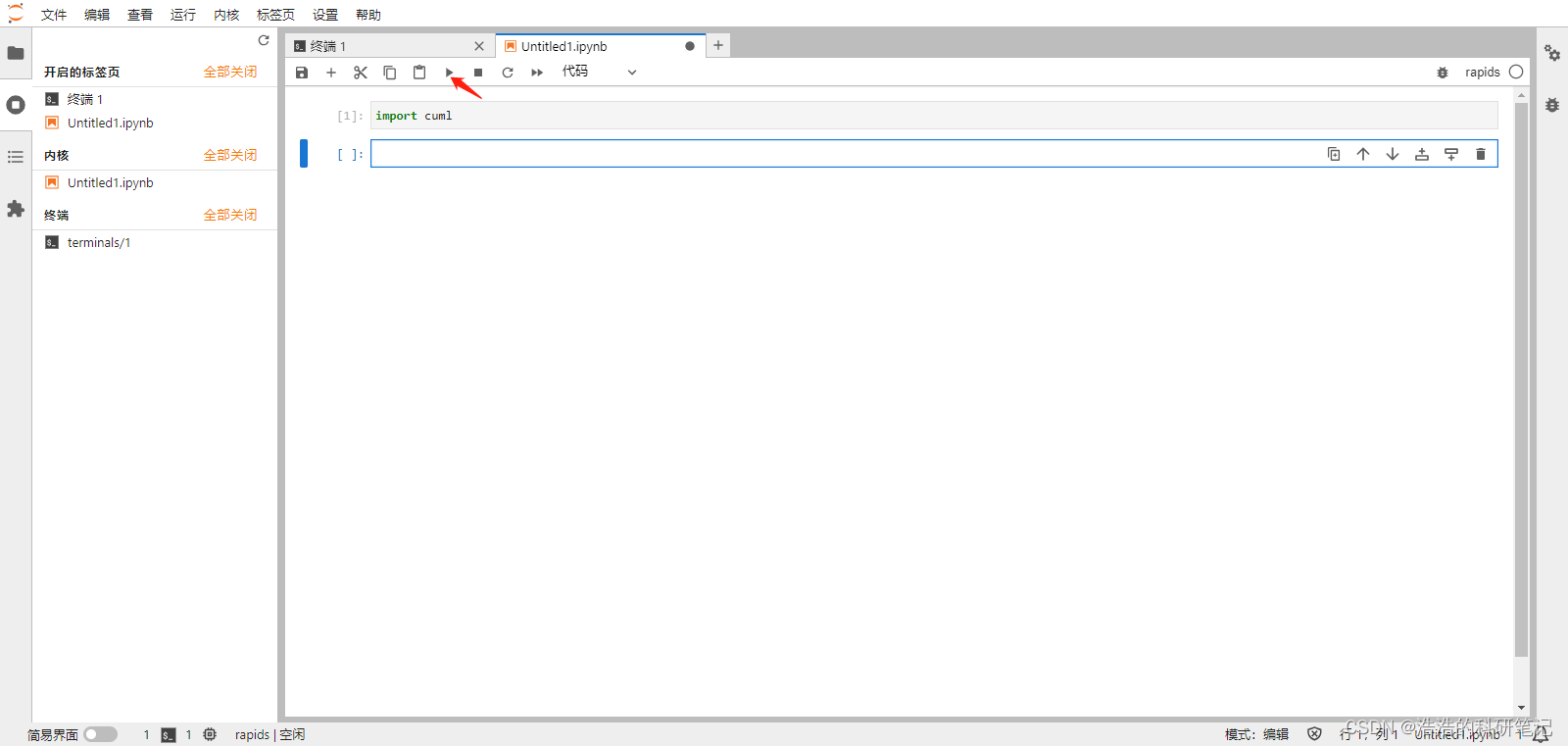
对比实验
为了对比我们也要安装sklearn库做一下时间的对比
回到启动页点击终端
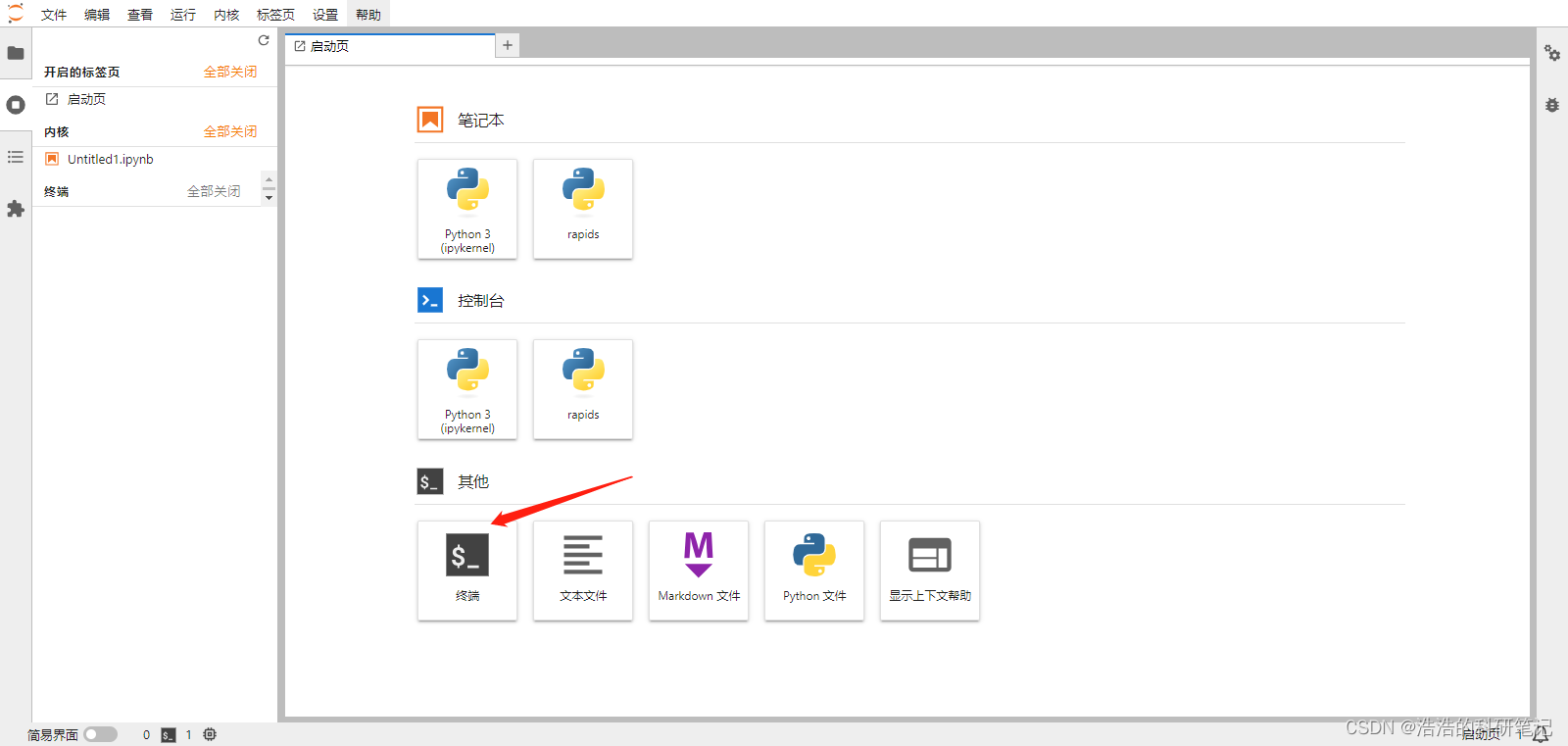
进入终端依次输入以下两个指令
source activate rapids
清华园 sklearn安装命令
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple scikit-learn
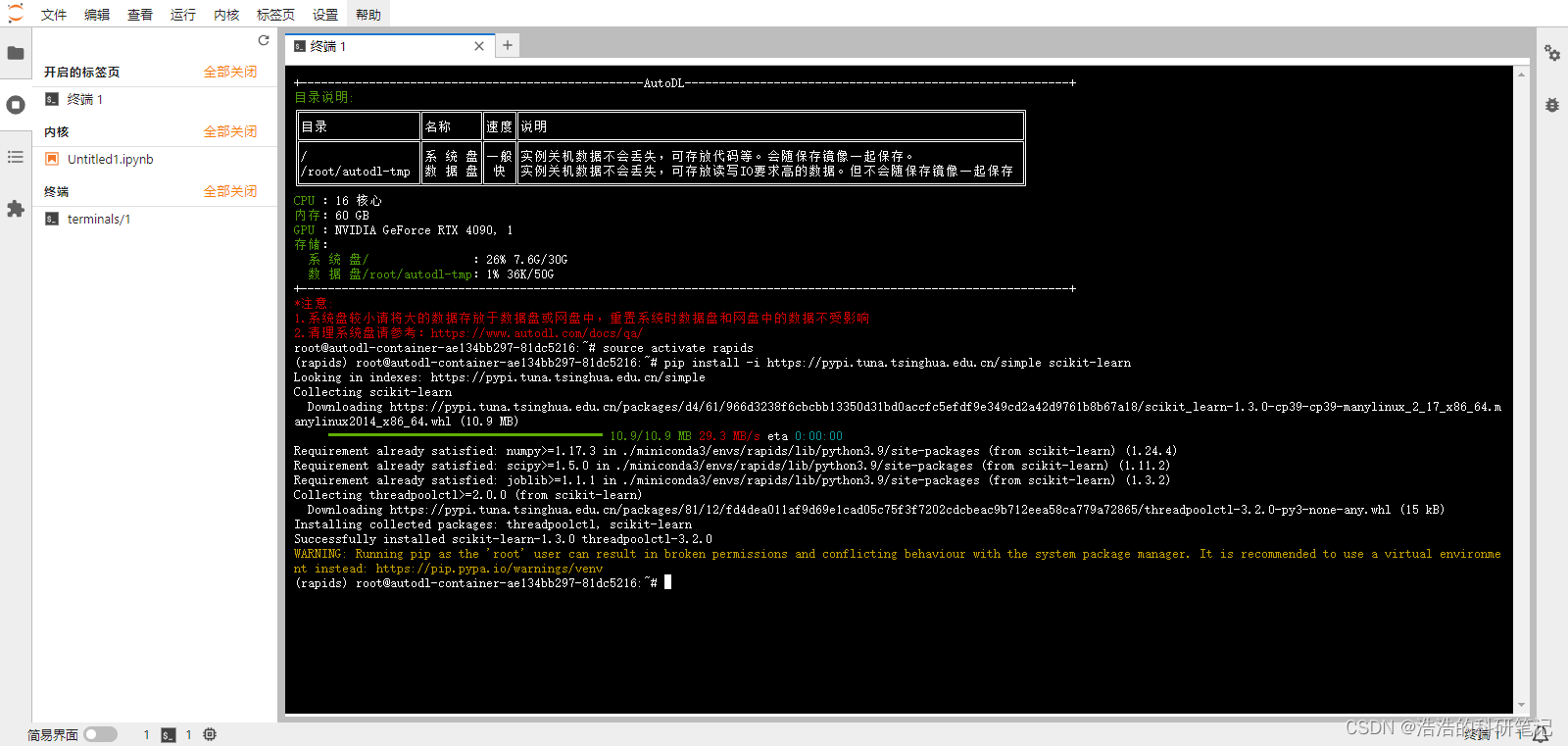
看到安装成功
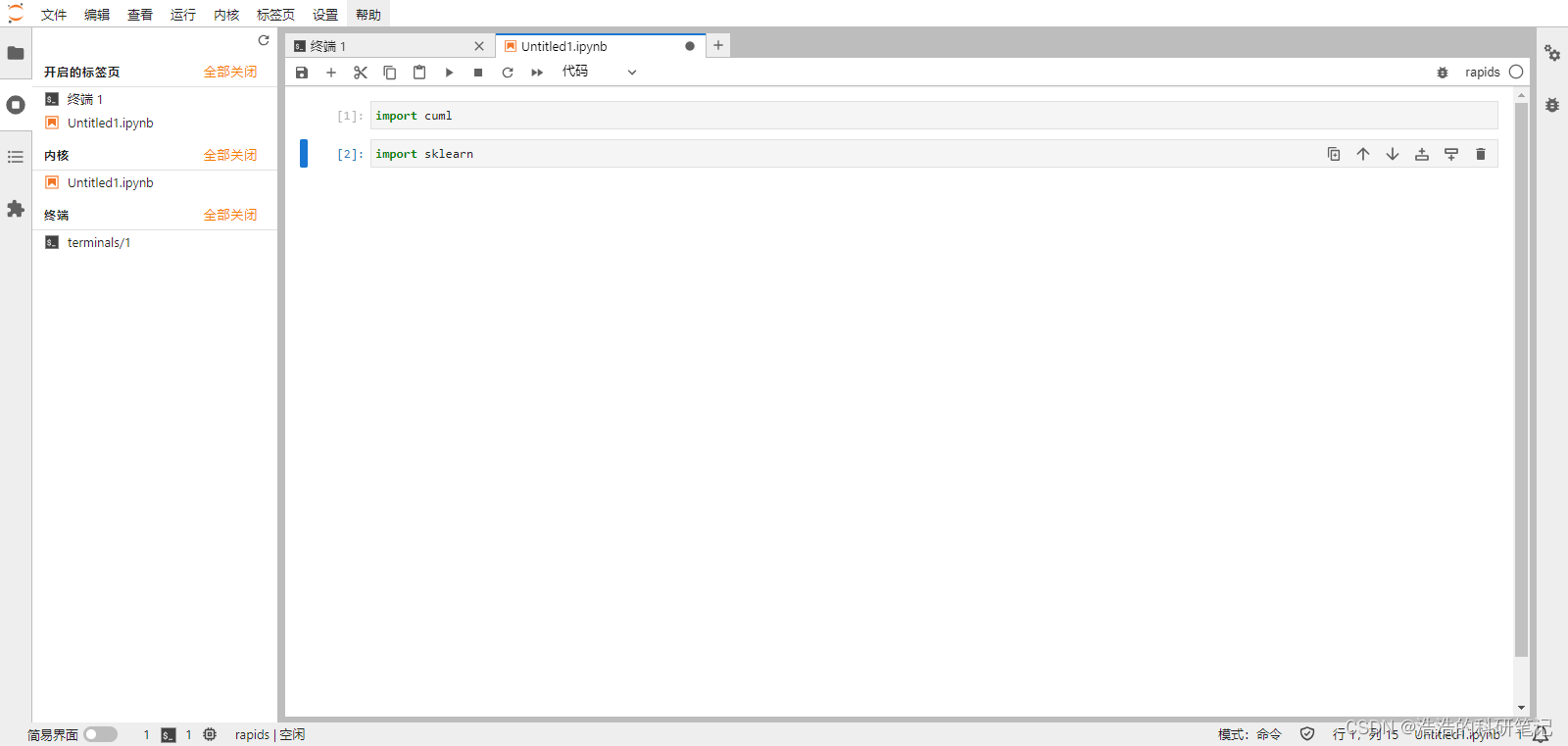
回到刚才建好的ipynb文件,输入
import sklearn
运行没报错
接下来我们用KNN算法进行以下对比
首先运行sklearn的KNN算法如下,运行时间1分11秒

from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
import numpy as np
import time
X = np.random.random((1000000,70))
y = np.random.randint(0,2,1000000)
# 分割数据为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 初始化KNN分类器。这里选择邻居数为3。
knn = KNeighborsClassifier(n_neighbors=20)
# 使用训练数据拟合模型
start_time = time.time() # 记录开始时间
knn.fit(X_train, y_train)
# 进行预测
y_pred = knn.predict(X_test)
end_time = time.time() # 记录结束时间
elapsed_time = end_time - start_time # 计算程序运行时间,单位为秒
# 将秒数转换为小时、分钟和秒数
hours = int(elapsed_time // 3600)
minutes = int((elapsed_time % 3600) // 60)
seconds = int(elapsed_time % 60)
print(f"程序运行时间:{hours}小时 {minutes}分钟 {seconds}秒\n")
# 评估预测的准确性
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
接下来我们查找cuml库中KNN算法的API
cuml库API用法查询
链接: https://docs.rapids.ai/api/cuml/stable/
点击右上角小放大镜
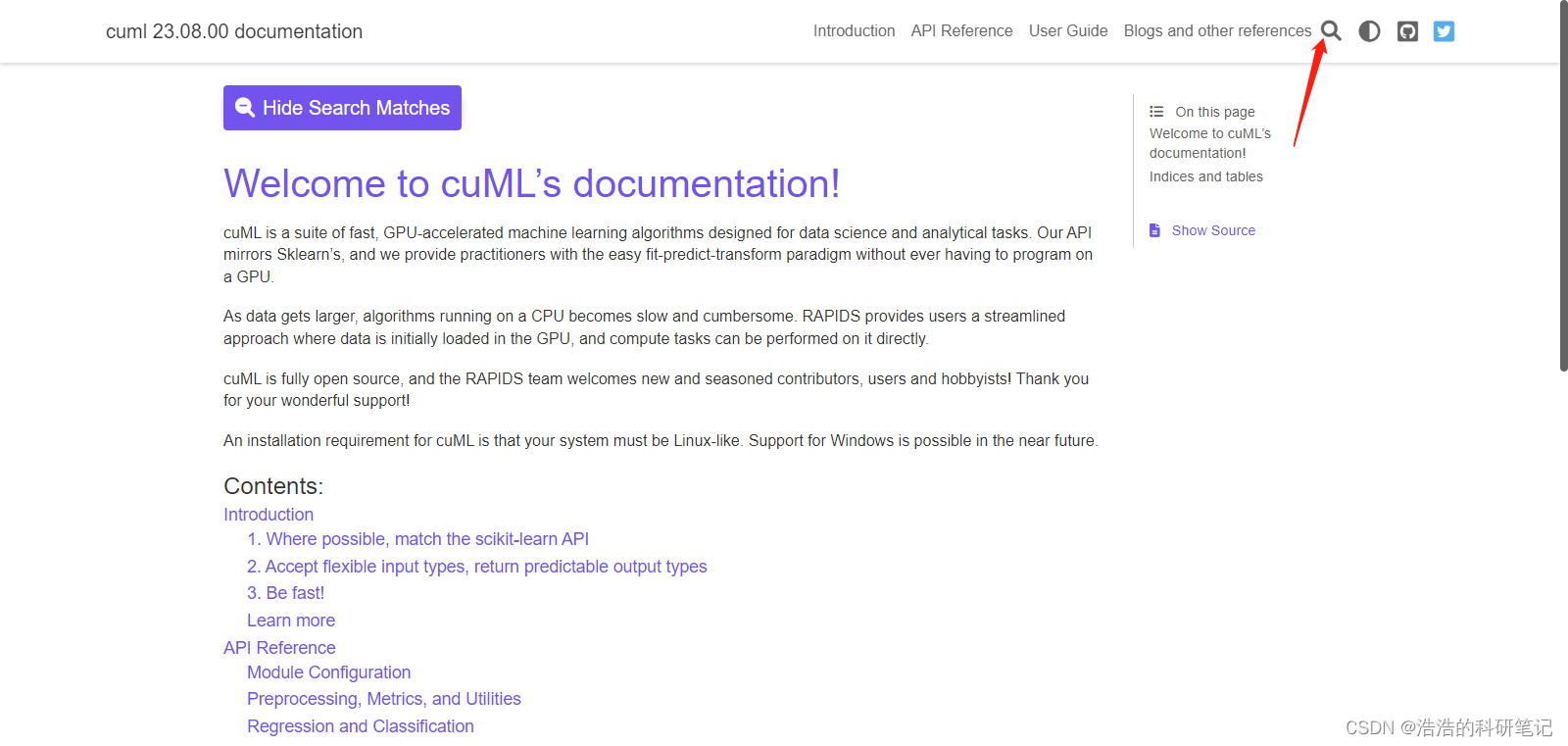
然后输入sklearn中KNN算法的API名称
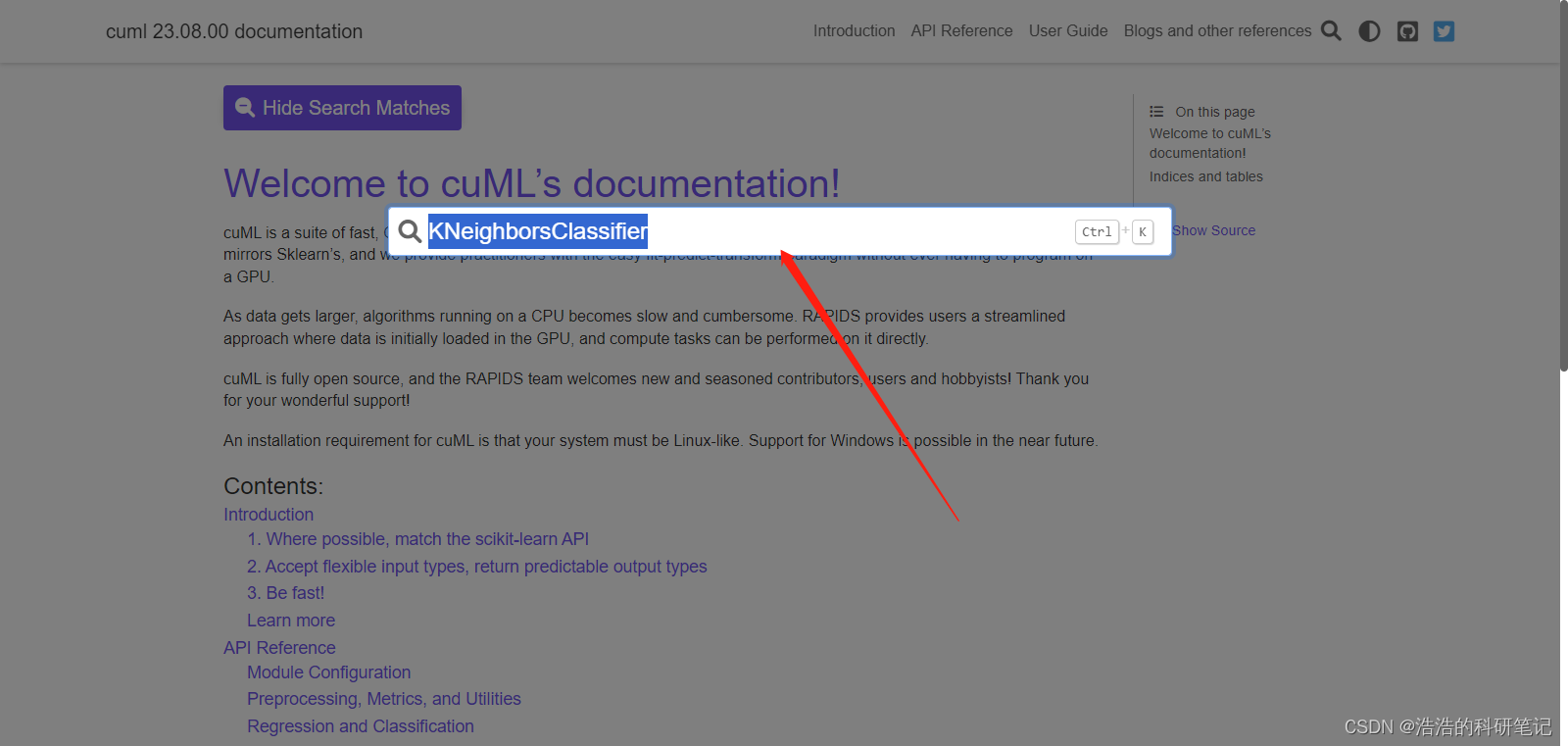
我研究了一下用的是这个
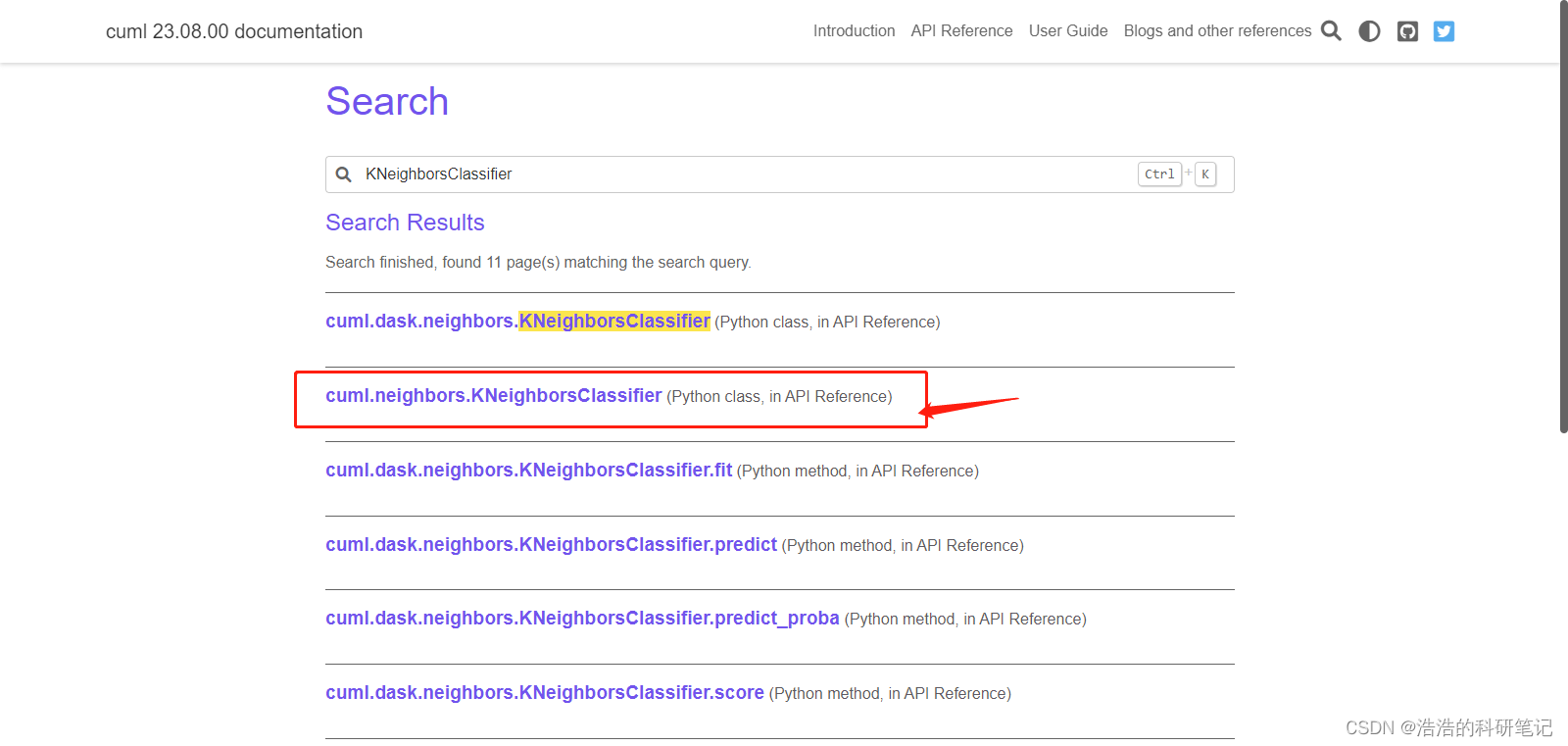
然后我们用
from cuml.neighbors import KNeighborsClassifier
替换
from sklearn.neighbors import KNeighborsClassifier
运行,使用时间从1分11秒缩短为5秒
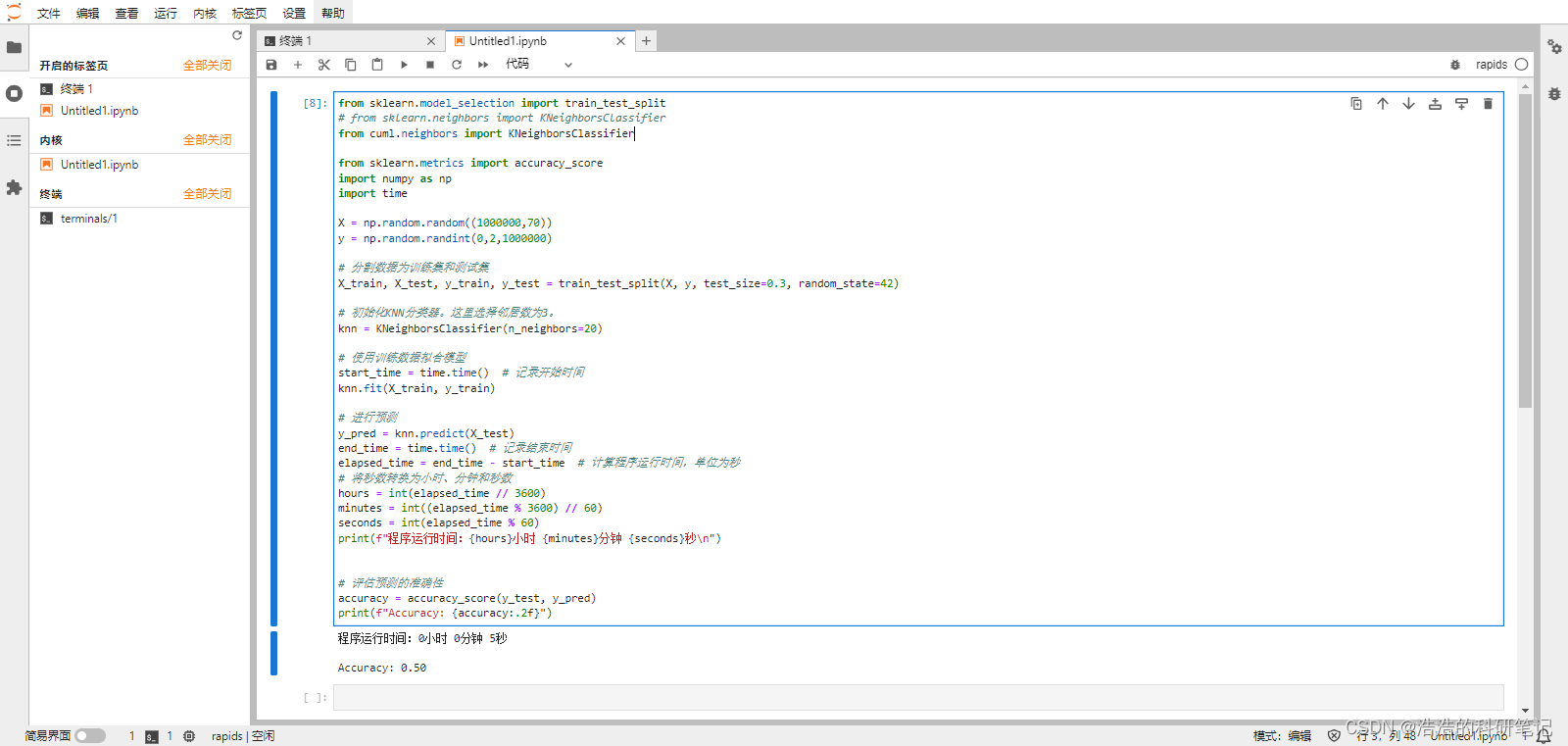
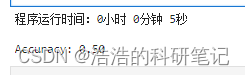
from sklearn.model_selection import train_test_split
# from sklearn.neighbors import KNeighborsClassifier
from cuml.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
import numpy as np
import time
X = np.random.random((1000000,70))
y = np.random.randint(0,2,1000000)
# 分割数据为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 初始化KNN分类器。这里选择邻居数为3。
knn = KNeighborsClassifier(n_neighbors=20)
# 使用训练数据拟合模型
start_time = time.time() # 记录开始时间
knn.fit(X_train, y_train)
# 进行预测
y_pred = knn.predict(X_test)
end_time = time.time() # 记录结束时间
elapsed_time = end_time - start_time # 计算程序运行时间,单位为秒
# 将秒数转换为小时、分钟和秒数
hours = int(elapsed_time // 3600)
minutes = int((elapsed_time % 3600) // 60)
seconds = int(elapsed_time % 60)
print(f"程序运行时间:{hours}小时 {minutes}分钟 {seconds}秒\n")
# 评估预测的准确性
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
完结撒花